

AI 系统如何评估作者的专业能力与可信度
了解 ChatGPT、Perplexity 和 Gemini 等 AI 系统如何通过内容分析、知识图谱和可信度信号评估作者专业能力,而不是传统的域名指标。...
2 分钟阅读

多年来,内容创作者一直致力于优化传统SEO指标——字数、关键词密度、外链和页面速度。然而,这些表层指标只能反映AI系统如何评估内容质量的一部分。现代大型语言模型(LLM)如GPT-4、Claude和Perplexity,从根本上以不同的视角评估内容:语义理解、事实准确性和上下文相关性。AI模型不再单纯计算关键词数量,而是分析内容是否真正传递了意义,主张是否可验证,信息是否直接回应了用户意图。这一转变标志着在AI驱动的世界中,我们应重新思考内容质量的范式。
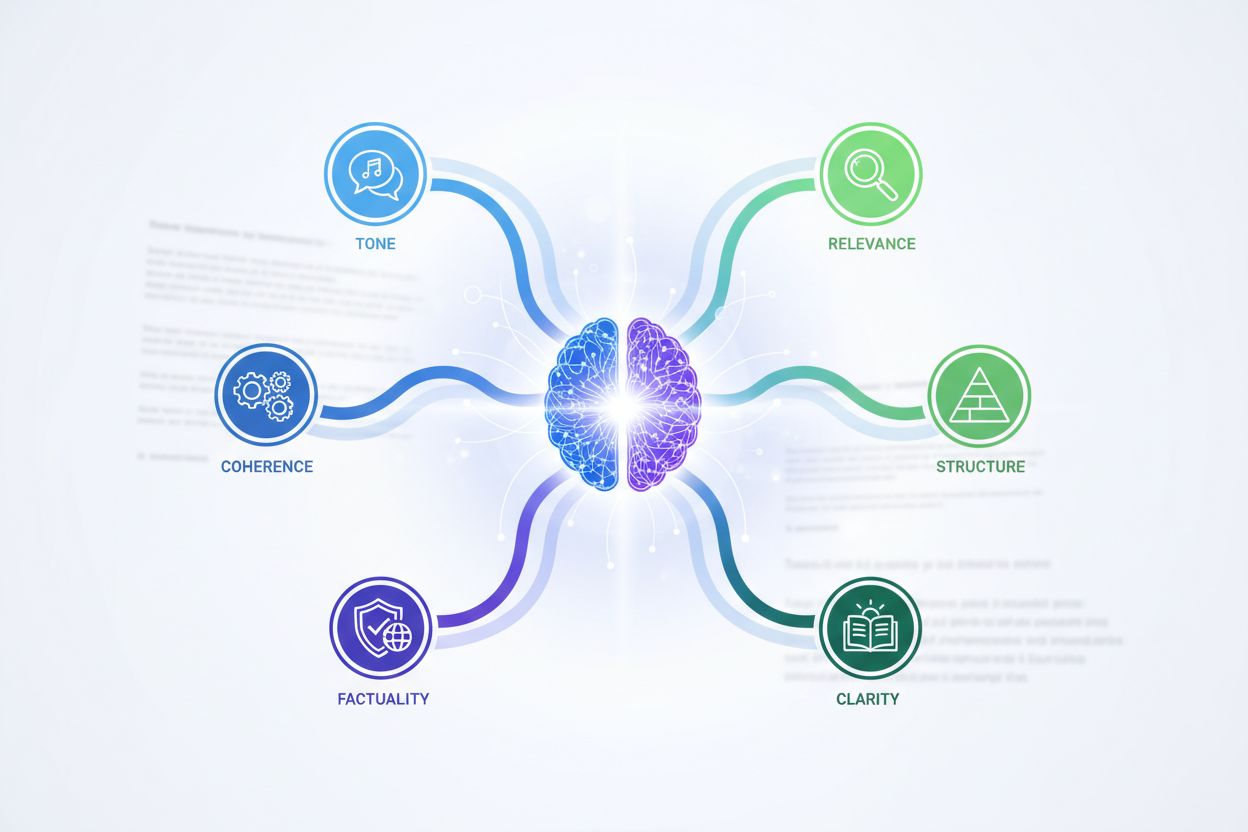
大型语言模型采用远超传统指标的复杂评估框架。这些系统从多个维度评估内容质量,每个维度都反映了内容质量的不同方面。理解这些维度,有助于内容创作者将工作与AI系统的实际感知和排名逻辑保持一致。
| 质量维度 | 传统指标 | AI评估方法 | 重要性 |
|---|---|---|---|
| 语义含义 | 关键词频率 | 嵌入相似度、上下文理解 | 关键 |
| 事实准确性 | 引用数量 | 忠实性指标、幻觉检测 | 关键 |
| 相关性 | 关键词匹配 | 答案相关性评分、任务对齐 | 关键 |
| 连贯性 | 可读性得分 | 逻辑流分析、一致性检查 | 高 |
| 结构 | 标题数量 | 论证结构评估 | 高 |
| 来源质量 | 域名权威 | 归属验证、来源锚定 | 高 |
| 语气对齐 | 情感分析 | 意图匹配、风格一致性 | 中 |
这些评估方法,包括BLEU、ROUGE、BERTScore及基于嵌入的指标,使AI系统能够极为精确地评估内容质量。现代AI评估不仅依赖于简单的词汇重叠,而是通过语义相似度理解不同表达是否传达相同意义,通过无参考评估考察文本内在质量,并采用LLM-as-a-Judge(LLM判官)方法,依据详细评分标准对输出进行评价。
传统与AI评估最大差异之一,在于对语义含义的考量。传统指标惩罚同义改写和同义词使用,将“迅速离开”与“匆忙离开”当作完全不同的短语。而AI系统能通过基于嵌入的评估识别其语义等价。这些系统将文本转化为高维向量以捕捉意义,使AI能理解表达同一思想的句子无论用词如何都应得分相近。
这种语义理解进一步延伸到上下文相关性。AI系统会判断内容是否适合对话或主题的更大语境。回答可能完全换用不同词汇,但只要回应了根本意图,就高度相关。AI模型通过语义相似度指标衡量答案含义与问题的贴合度,而不是简单比对关键词。具备这种能力,意味着结构良好、自然流畅且全面回应主题的内容,会比仅堆砌关键词却缺乏连贯性的内容得分更高。
对于AI系统而言,事实准确性或许是最关键的质量信号。区别于传统SEO指标对真实性的忽视,现代AI评估框架专门考查内容是否包含可验证的事实或无依据的主张。AI系统采用忠实性指标判断陈述是否基于已提供的源材料,并通过幻觉检测识别模型或内容创作者是否捏造信息。
这些方法通过将内容中的主张与权威来源或知识库比对来实现。例如,若内容声明“法国首都是巴黎”,AI会将这一说法与其训练数据及外部来源核对。更重要的是,AI还评估锚定性——即主张是否有所依据。一份摘要若包含原始材料中未出现的信息,即便信息本身正确,也会在忠实性指标上得分较低。这种强调事实准确性的机制要求内容创作者确保每一主张要么为常识,要么有明确引用,或清晰标注为观点或推测。
AI系统还会评估内容中观点的联系与推进是否逻辑清晰。连贯性评估关注句子是否自然衔接,论点是否层层递进,整体结构是否合理。清晰的主题句、逻辑分段和观点间平滑过渡的内容,在连贯性指标上得分高于杂乱无章的内容。
逻辑流对于复杂主题尤为重要。AI系统会检查解释是否由浅入深,是否先介绍前置知识再引入高级概念,结论是否合乎推理。结构良好、能引导读者循序渐进理解思路的内容,在AI评估中远胜于跳跃杂乱、重复堆砌的信息。
AI系统会判断内容是否真正回答了问题或完成了设定任务。答案相关性指标衡量回复与用户提问的贴合度,聚焦且不偏题的内容得分更高。例如,有人问“如何修理漏水水龙头?”,若回复讲述管道历史,即便写得好且事实准确,相关性测试也不及格。
任务对齐进一步扩展了这一理念——AI会考查内容是否符合预期用途和用户意图。技术教程应详细准确,速查指南要简明易读,劝说型文章需有力论证。符合这些预期的内容,无论其他质量如何,都比未击中要点的内容得分更高。这意味着理解受众与内容目的,与写作质量一样重要。
AI系统高度重视知识锚定——即将主张建立在权威来源之上。引用有信誉的来源、恰当归属、清楚区分已确立事实与个人解读的内容,在质量指标上得分更高。上下文精确性衡量所引用/检索的来源是否确实支撑主张,上下文召回率则考查所有相关支持信息是否被涵盖。
透明归属在AI评估中具有多重意义。它表明内容创作者进行了研究,便于读者独立验证主张,也帮助AI系统评估信息可靠性。笼统说“研究显示”而不给出细节的内容,比直接引用作者、日期和结论的内容得分更低。这种对来源质量的重视,意味着内容创作者应投入时间寻找权威来源并规范归属。
除事实内容外,AI系统还会评估语气和风格是否符合用户预期及意图。客服回复应友好且专业,创意写作应合乎体裁,技术文档要严谨正式。AI采用LLM判官方法,由高级模型判断语气是否适合语境,风格选择是否增强或削弱了信息传递。
一致性也是重要因素——AI会考查内容中语气、术语和风格是否始终如一。随意在正式与口语间切换、同一概念用不同术语、视角突变等,都会让AI判定质量较低。始终保持统一声音与风格的内容,远优于风格割裂、表达混乱的内容。
理解AI如何评估内容质量,对内容创作有切实影响。以下是使内容被AI系统认定为高质量的实用策略:
随着AI系统在内容发现与引用中的作用日益突出,了解品牌与内容在这些系统中的识别情况至关重要。AmICited.com为您监测AI系统(包括GPT、Perplexity、Google AI摘要及其他基于LLM的平台)如何引用和提及您的内容与品牌。
AmICited不依赖于无法反映AI识别度的传统指标,而是跟踪现代AI系统看重的特定质量信号。平台监控您的内容是否被视为权威,AI系统提及品牌的频率,以及在不同AI平台中出现的语境。这种可见性对于判断内容是否达到AI实际采用的质量标准及被引用情况极为有价值。
通过使用AmICited,您可以洞察AI如何感知您的内容质量、品牌在哪些主题上被认可,以及在哪些方面可以提升AI引用率。这种以数据为驱动的AI质量信号理解方式,有助于优化内容策略,使之更贴近现代AI系统的评估与推荐逻辑。在AI主导的搜索与发现时代,监控在这些系统中的表现,已和传统SEO监测同等重要。
AI系统侧重于语义理解、事实准确性和上下文相关性,而不是关键词频率和外链。它们通过基于嵌入的指标理解内容含义,通过忠实性指标验证事实,通过相关性评分确保内容符合用户意图。因此,结构良好、全面、充分回应主题的内容,比堆砌关键词的内容得分更高。
语义相似性衡量不同表达是否传达相同含义。AI系统使用基于嵌入的评估来识别“迅速离开”和“匆忙离开”虽然用词不同,但语义等价。这很重要,因为AI更倾向于自然、多样化的写作,而非重复关键词,并将同义改写视为高质量内容。
AI系统使用忠实性指标,将内容中的主张与权威来源和知识库进行比对。它们评估陈述是否基于提供的源材料,信息是否有证据支持。包含无依据主张或源材料中未出现的信息的内容,在事实准确性指标上得分较低。
AI系统重视知识锚定——即将主张植根于权威来源。引用有信誉的来源并适当归属的内容展现了研究质量,也便于AI系统评估可靠性。透明的归属还帮助读者独立验证主张,并向AI表明内容创作者进行了充分研究。
AI系统通过评估观点是否自然衔接、论据是否层层递进以及整体结构是否合理来评估逻辑流畅和连贯性。请使用清晰的主题句,逻辑分段,观点间平滑过渡,并从简单到复杂递进。结构清晰、有明确推进的内容比杂乱无章的内容得分更高。
AI系统评估语气和风格是否符合用户预期和意图。一致性至关重要——在内容中始终保持相同的语态、术语和风格,可提升质量评分。随意在正式与口语间切换、同一概念用不同术语或视角突变,都会降低AI评估的质量分。
AmICited监测GPT、Perplexity和Google AI摘要等AI系统如何引用和提及您的内容与品牌。该平台追踪您的内容是否被视为权威,AI系统引用品牌的频率,以及您的内容在何种语境下出现。这些可见性帮助您了解内容是否达到AI质量标准,以及需要改进的地方。
基于参考的评估将内容与预设标准答案对比,适用于有确定正确答案的任务。无参考评估则在不对比具体参考的情况下评估文本内在质量,适用于开放式任务。现代AI系统根据任务需要两种方法并用,其中无参考评估对创意和对话性内容日益重要。
了解 ChatGPT、Perplexity 和 Gemini 等 AI 系统如何通过内容分析、知识图谱和可信度信号评估作者专业能力,而不是传统的域名指标。...
了解AI内容质量阈值是什么、如何衡量,以及它为何对于监控ChatGPT、Perplexity等AI答案生成器中的AI生成内容至关重要。

了解如何识别并弥补ChatGPT、Perplexity和Google AI Overviews中的AI可见性内容差距。发现分析方法和工具,提升品牌在AI搜索中的可见性。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.