

AI爬虫速查卡:所有Bot一览
AI爬虫与机器人完整参考指南。识别GPTBot、ClaudeBot、Google-Extended及其他20+ AI爬虫,包含User Agent、爬取频率与屏蔽策略。
3 分钟阅读
像Googlebot和Bingbot这样的搜索引擎爬虫是传统搜索引擎运营的核心。这些自动化机器人系统性地浏览网络,发现并索引内容,以决定哪些内容会出现在搜索引擎结果页面(SERP)。由Google运营的Googlebot是最知名、最活跃的搜索爬虫,其次是微软的Bingbot和Yandex的YandexBot。这些爬虫具备复杂的能力,能够执行JavaScript,渲染动态内容,并理解复杂的网站结构。它们根据网站权威性、内容新鲜度和更新历史等因素频繁访问网站,高权重网站会被更频繁地抓取。搜索爬虫的主要目标是为排名索引内容,也就是根据相关性、质量和用户体验信号来评估页面。
| 爬虫类型 | 主要目的 | JavaScript支持 | 抓取频率 | 目标 |
|---|---|---|---|---|
| Googlebot | 用于搜索排名的索引 | 支持(有一定限制) | 频繁,基于权威性 | 排名与可见性 |
| Bingbot | 用于搜索排名的索引 | 支持(有一定限制) | 定期,基于内容更新 | 排名与可见性 |
| YandexBot | 用于搜索排名的索引 | 支持(有一定限制) | 定期,基于网站信号 | 排名与可见性 |
AI训练爬虫属于完全不同的一类网络机器人,它们的设计目标是为大语言模型(LLM)收集训练数据,而非用于搜索索引。由OpenAI运营的GPTBot是最著名的AI训练爬虫,还有Anthropic的ClaudeBot、华为的PetalBot和Common Crawl的CCBot。与以排名内容为目标的搜索爬虫不同,AI训练爬虫专注于收集高质量、上下文丰富的信息,以提升AI模型的知识库和回答生成能力。这些爬虫的抓取频率通常远低于搜索爬虫,往往几周甚至几个月才访问一次网站,并且更看重内容质量而非数量。这个区别至关重要:您的内容可能已被Googlebot彻底索引以获得搜索可见性,但GPTBot只做了部分或极少量的抓取用于AI模型训练。
| 爬虫类型 | 主要目的 | JavaScript支持 | 抓取频率 | 目标 |
|---|---|---|---|---|
| GPTBot | 为LLM训练收集数据 | 不支持 | 不频繁,有选择性 | 训练数据质量 |
| ClaudeBot | 为LLM训练收集数据 | 不支持 | 不频繁,有选择性 | 训练数据质量 |
| PetalBot | 为LLM训练收集数据 | 不支持 | 不频繁,有选择性 | 训练数据质量 |
| CCBot | 为Common Crawl收集数据 | 不支持 | 不频繁,有选择性 | 训练数据质量 |
搜索爬虫与AI训练爬虫之间的技术差异对内容可见性有重大影响。最重要的区别是JavaScript执行能力:像Googlebot这样的搜索爬虫能够执行JavaScript(虽然有限),因此可以看到动态渲染的内容。而AI训练爬虫则完全不执行JavaScript——它们只解析页面初始加载时的原始HTML。这一根本差异意味着,通过客户端脚本动态加载的内容对AI爬虫来说完全不可见。此外,搜索爬虫会遵循抓取预算,并根据网站结构和内部链接优先抓取页面,而AI爬虫则采用更有选择性、以质量为导向的抓取模式。搜索爬虫通常严格遵守robots.txt规则,而部分AI爬虫在合规性上历史上并不总是透明。抓取频率也有明显不同:搜索爬虫每周甚至每天多次访问活跃网站,而AI训练爬虫可能几周或几个月才访问一次。此外,搜索爬虫会理解排名信号和用户体验指标,而AI爬虫则专注于提取干净、结构化良好的文本内容用于模型训练。
| 特性 | 搜索爬虫 | AI训练爬虫 |
|---|---|---|
| JavaScript执行 | 支持(有一定限制) | 不支持 |
| 抓取频率 | 高(每周多次) | 低(每几周一次) |
| 内容解析 | 全页面渲染 | 仅原始HTML |
| Robots.txt合规性 | 严格 | 不一 |
| 抓取预算关注点 | 基于权威性优先 | 基于内容质量 |
| 动态内容处理 | 可渲染并索引 | 完全忽略 |
| 主要目标 | 排名与搜索可见性 | 训练数据采集 |
| 超时容忍度 | 较长(允许复杂渲染) | 很短(1-5秒) |
AI爬虫无法执行JavaScript,造成了严重的可见性鸿沟,影响了许多现代网站。当网站依赖JavaScript动态加载内容(如产品描述、客户评价、价格信息或图片)时,这些内容对AI爬虫来说就不可见了。这对于用React、Vue或Angular构建的单页应用(SPA)尤其严重,因为大部分内容都是初始HTML加载后由客户端渲染的。例如,某电商网站可能通过JavaScript展示产品库存和价格信息,这意味着GPTBot只能看到一个空白页面或基础的HTML框架。同样,使用图片懒加载或内容无限滚动的网站,其这些元素也会被AI爬虫完全忽略。其商业影响十分巨大:如果您的产品详情、客户评价或关键信息被JavaScript隐藏,像ChatGPT和Perplexity这样的AI系统在生成答案时无法获取这些信息。这就造成了您的内容在Google排名很好,但在AI生成的答复中却完全缺席,相当于在越来越多依赖AI获取信息的用户面前变得“隐形”。
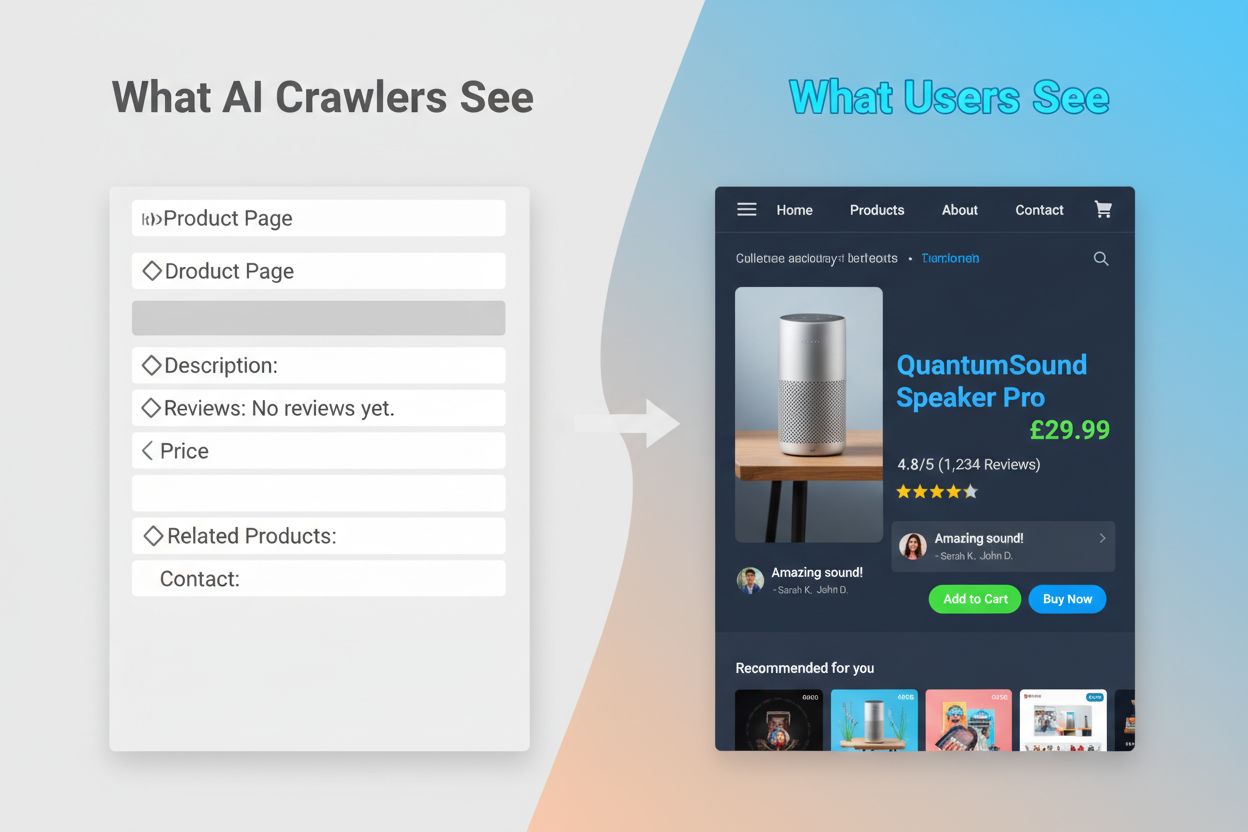
这些技术差异带来的实际后果深远,但网站所有者常常误解。您的网站可能在Google上排名极佳,却在ChatGPT、Perplexity等AI系统中几乎不可见。这造成了一个悖论:传统SEO的成功并不保证AI可见性。当用户向ChatGPT提问有关您的行业或产品时,AI系统可能引用您的竞争对手而非您,仅仅因为他们的内容对AI爬虫更易访问。训练数据与搜索引用之间的关系也增加了复杂性:曾用于训练AI模型的内容在该模型的搜索结果中可能享有优先待遇,这意味着屏蔽AI训练爬虫可能会降低您在AI驱动答案中的可见性。对于出版商和内容创作者来说,允许或屏蔽AI爬虫的战略决策将对未来流量产生实际影响。为保护内容而屏蔽GPTBot的网站,可能会降低自己在ChatGPT搜索结果中出现的机会。反之,允许AI爬虫抓取您的内容可以为AI模型提供训练数据,但不能保证获得引用或流量,这确实是一个没有完美解法的战略难题。
了解哪些爬虫访问了您的网站以及它们的访问频率,对于优化内容策略至关重要。日志文件分析是识别爬虫活动的主要方法,它可以让您对服务器日志进行分段和解析,查看哪些机器人访问了您的网站、访问频率以及优先抓取了哪些页面。通过分析服务器日志中的User-Agent字符串,您可以区分Googlebot、GPTBot、OAI-SearchBot及其他爬虫,发现它们的行为模式。需要重点监控的关键指标包括抓取频率(各爬虫访问频率)、抓取深度(爬虫抓取了您网站结构的多少层级)和抓取预算(一定时间内被抓取的总页面数)。Google Search Console和Bing Webmaster Tools等工具可以提供关于搜索爬虫活动的洞见,而像AmICited.com这样的专业解决方案则能全面监控AI爬虫在ChatGPT、Perplexity和Google AI Overviews等多个平台的行为。AmICited.com专门追踪AI系统如何引用您的品牌和内容,让您了解哪些AI平台在引用您以及引用的频率。理解这些模式有助于您及早发现技术问题,优化抓取预算分配,并据此做出有关爬虫访问与内容优化的明智决策。
针对传统搜索爬虫的优化,需要聚焦于确保内容可被发现和索引的技术SEO基础。以下策略对于保持强劲的搜索可见性至关重要:
Google等搜索引擎日益关注抓取效率,Google方面也表示未来Googlebot的抓取频率会降低。因此,您的网站应尽可能简洁明了,拥有清晰的层级和高效的内部链接,引导爬虫直达最重要的页面。
针对AI训练爬虫的优化,需要采取不同的思路,重在内容质量、清晰度和可访问性,而非排名信号。AI爬虫优先抓取结构良好、上下文丰富的内容,因此您的优化策略应强调内容的全面性和可读性。避免关键信息依赖JavaScript渲染,确保产品详情、价格、评价和关键数据都直接写在原始HTML中,AI爬虫才能抓取。创作全面、深入的内容,彻底覆盖相关话题,提供AI模型可借鉴的上下文。采用清晰的排版格式,使用标题、项目符号和编号列表分隔文本,让内容易于解析。语言表达要语义清晰,避免使用过多行业术语或晦涩表达,以免AI模型混淆。正确使用标题层级(H1、H2、H3),帮助AI爬虫理解内容结构和关联。添加相关元数据与结构化数据,为您的内容提供更多语境信息。确保页面加载速度快,因AI爬虫超时时限很短(通常1-5秒),慢页面可能被完全跳过。
与搜索优化的主要区别在于,AI爬虫不关心排名信号、外链或关键词密度。它们看重的是内容的清晰、结构良好和信息丰富。某些在Google上排名不高的页面,只要内容全面、结构清晰,就可能对AI模型极具价值。
网络爬虫领域正迅速发展,AI爬虫对内容可见性和品牌认知的重要性持续提升。随着ChatGPT、Perplexity和Google AI Overviews等AI驱动的搜索工具用户规模不断扩大,被这些系统发现和引用的能力将和传统搜索排名一样关键。训练爬虫与搜索爬虫的区分将变得更加细致,企业可能会像OpenAI区分GPTBot与OAI-SearchBot那样,逐步明确数据采集与搜索检索的边界。网站所有者需要制定兼顾传统SEO和AI可见性的策略,认识到两者是互补而非对立的目标。专业的爬虫监控工具和解决方案将使跨传统与AI平台的爬虫活动追踪变得更容易,从而支持数据驱动的爬虫访问和内容优化决策。现在就同时为搜索与AI爬虫优化的早期行动者,将获得竞争优势,使内容能够通过多种渠道被发现,顺应搜索生态的持续演变。内容可见性的未来,取决于您对发现和利用您内容的各类爬虫的理解与优化。
像Googlebot这样的搜索爬虫会索引内容用于搜索排名,并且能够执行JavaScript以查看动态内容。而像GPTBot这样的AI训练爬虫则收集数据用于训练大语言模型(LLM),通常无法执行JavaScript,因此会错过动态加载的内容。这一根本区别意味着您网站在Google上排名很好,但在ChatGPT中几乎不可见。
可以,您可以通过robots.txt屏蔽特定的AI爬虫(如GPTBot),同时允许搜索爬虫访问。然而,这可能会降低您在AI生成答案和摘要中的可见性。是否屏蔽的战略权衡取决于您是更重视内容保护还是AI推荐流量。
像GPTBot这样的AI爬虫只解析初始页面加载时的原始HTML,并不会执行JavaScript。通过脚本动态加载的内容(如产品详情、评论或图片)对它们来说完全不可见。对于依赖客户端渲染的现代网站来说,这是一个关键限制。
AI训练爬虫通常访问频率比搜索爬虫低,访问间隔更长。它们优先抓取高权威内容,可能几周或几个月才抓取一次页面。这种不频繁的抓取模式反映了它们对质量而非数量的关注。
产品详情、客户评论、懒加载图片、交互元素(标签、轮播、弹窗)、价格信息以及所有被JavaScript隐藏的内容最容易被忽略。对于电商和基于SPA的网站,这可能占据了大量核心内容。
确保关键信息存在于原始HTML中,提升网站速度,使用清晰的结构和适当的标题层级,实施结构化数据,避免依赖JavaScript的关键信息。目标是让您的内容对传统爬虫和AI爬虫都易于访问。
日志分析工具、Google Search Console、Bing Webmaster Tools以及像AmICited.com这样的专用爬虫监控工具都可以帮助您追踪爬虫行为。AmICited.com专门监控AI系统在ChatGPT、Perplexity和Google AI Overviews中如何引用您的品牌。
有可能会。虽然屏蔽训练爬虫可以保护您的内容,但也可能降低您在AI驱动搜索结果和摘要中的可见性。此外,屏蔽前已被抓取的内容仍会保留在已训练的模型中。这个决策需要在内容保护和可能损失AI推荐流量之间进行权衡。
AI爬虫与机器人完整参考指南。识别GPTBot、ClaudeBot、Google-Extended及其他20+ AI爬虫,包含User Agent、爬取频率与屏蔽策略。

学习如何在服务器日志中识别并监控如 GPTBot、ClaudeBot 和 PerplexityBot 等AI爬虫。完整指南涵盖 user-agent 字符串、IP 验证及实用监控策略。...

了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.