
AI专用的Robots.txt:如何控制哪些机器人访问您的内容
了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...
2 分钟阅读
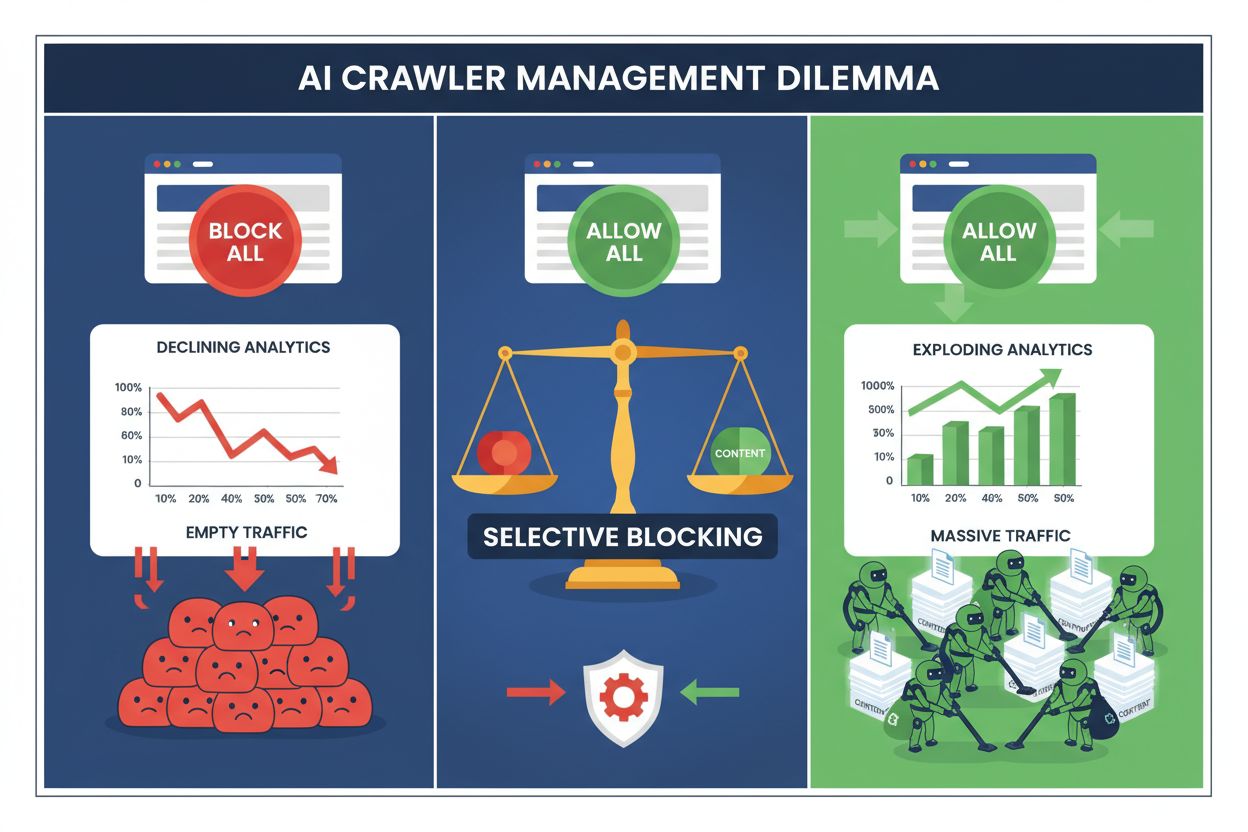
如今,出版方面临两难选择:屏蔽所有AI爬虫而失去宝贵的搜索引擎流量,或全部允许,结果内容被用作训练数据却得不到补偿。生成式AI的兴起催生了分化的爬虫生态系统,在这里,同一份robots.txt规则无差别地适用于既能带来收入的搜索引擎,也适用于只会榨取价值的训练爬虫。这一悖论促使有远见的出版方开发出选择性爬虫控制策略,根据不同AI机器人的实际业务影响加以区分。
AI爬虫格局分为两大类别,目的和业务影响截然不同。训练爬虫(由OpenAI、Anthropic和Google等公司运营)专为大量抓取文本数据以构建和改进大型语言模型,而搜索爬虫则负责索引内容以便检索与发现。训练机器人约占所有AI相关爬虫活动的80%,却为出版方带来零直接收益,而像Googlebot和Bingbot这样的搜索爬虫则每年为网站带来数百万访问和广告展示。区别在于,单个训练爬虫消耗的带宽可与数千名真人用户相当,而搜索爬虫则为效率而优化,并通常遵守抓取速率限制。
| Bot Name | Operator | Primary Purpose | Traffic Potential |
|---|---|---|---|
| GPTBot | OpenAI | Model training | None (data extraction) |
| Claude Web Crawler | Anthropic | Model training | None (data extraction) |
| Googlebot | Search indexing | 243.8M visits (April 2025) | |
| Bingbot | Microsoft | Search indexing | 45.2M visits (April 2025) |
| Perplexity Bot | Perplexity AI | Search + training | 12.1M visits (April 2025) |
数据非常鲜明:仅ChatGPT的爬虫在2025年4月就向出版方带来2.438亿访问,但这些访问没有任何点击、广告展示或收入。而与此同时,Googlebot的流量却转化为实际的用户参与和变现机会。理解这种区别,是实施选择性屏蔽策略、在保护内容的同时保留搜索可见性的第一步。
对大多数出版方而言,全面屏蔽所有AI爬虫在经济上是自毁长城。训练爬虫无偿榨取价值,而搜索爬虫仍是日益碎片化数字环境中最可靠的流量来源之一。选择性屏蔽的经济基础体现在几个关键因素:
实施选择性屏蔽策略的出版方报告称,在减少未授权内容抓取高达85%的同时,搜索流量得以维持甚至提升。这一战略认识到,并非所有AI爬虫都一视同仁,精细化的政策远比一刀切更符合业务利益。
robots.txt文件仍是传达爬虫访问权限的主要机制,只要配置得当,它在区分不同类型爬虫时非常有效。只需将此简单文本文件放置在网站根目录,并通过user-agent指令指定哪些爬虫可访问哪些内容。针对选择性AI爬虫控制,您可以精准地允许搜索引擎,屏蔽训练爬虫。
以下是一个屏蔽训练爬虫、允许搜索引擎的实用示例:
# 屏蔽OpenAI的GPTBot
User-agent: GPTBot
Disallow: /
# 屏蔽Anthropic的Claude爬虫
User-agent: Claude-Web
Disallow: /
# 屏蔽其他训练爬虫
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# 允许搜索引擎
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
这种做法为遵守规则的爬虫提供清晰指令,同时保证您的网站在搜索结果中的可发现性。不过,robots.txt本质上是一种自愿标准——依赖于爬虫运营者是否遵守。若担心爬虫不守规矩,还需更多强制措施。
仅靠robots.txt无法保证全部爬虫遵守,因为约13%的AI爬虫完全无视robots.txt指令,可能是疏忽也可能是有意规避。服务器级防护通过Web服务器或应用层在HTTP层面拦截请求,能有效阻止未授权访问,在消耗大量带宽前就将其拒之门外。
使用Nginx实现服务器级屏蔽既简单又高效:
# 在您的Nginx server块中
location / {
# 在服务器层面屏蔽训练爬虫
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# 根据IP范围屏蔽(针对伪造User-Agent的爬虫)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# 继续正常请求处理
proxy_pass http://backend;
}
该配置对被屏蔽爬虫返回403 Forbidden响应,最大限度减少服务器资源消耗,同时明确告知访问被拒绝。结合robots.txt,服务器级防护形成双重防线,既能拦截守规矩的爬虫,也能拦截违规爬虫。只要服务器规则配置得当,13%的绕过率几乎可降至零。
内容分发网络(CDN)和Web应用防火墙(WAF)能在请求到达源服务器前提供额外防护。Cloudflare、Akamai、AWS WAF等服务允许您在边缘创建规则,按User-Agent或IP范围屏蔽特定爬虫,防止恶意或不受欢迎的爬虫消耗基础设施资源。这些服务维护着已知训练爬虫IP和User-Agent的实时列表,可自动拦截,无需手动配置。
CDN层防控相较服务器级防护有诸多优势:减轻源服务器负载,支持地理屏蔽,并提供实时拦截分析。许多CDN现已将AI爬虫专属屏蔽规则作为标准功能,反映出出版方对未经授权训练数据抓取的普遍担忧。对于使用Cloudflare的出版方,只需在安全设置中启用“屏蔽AI爬虫”选项,即可一键防护主流训练爬虫,同时保留搜索引擎访问。
有效的选择性屏蔽需要根据爬虫的业务影响和可信度系统性分类。出版方不应一刀切地对待所有AI爬虫,而应建立三级分类框架,反映每种爬虫的实际价值与风险。这一框架让决策更有针对性,实现内容保护与业务机会的平衡。
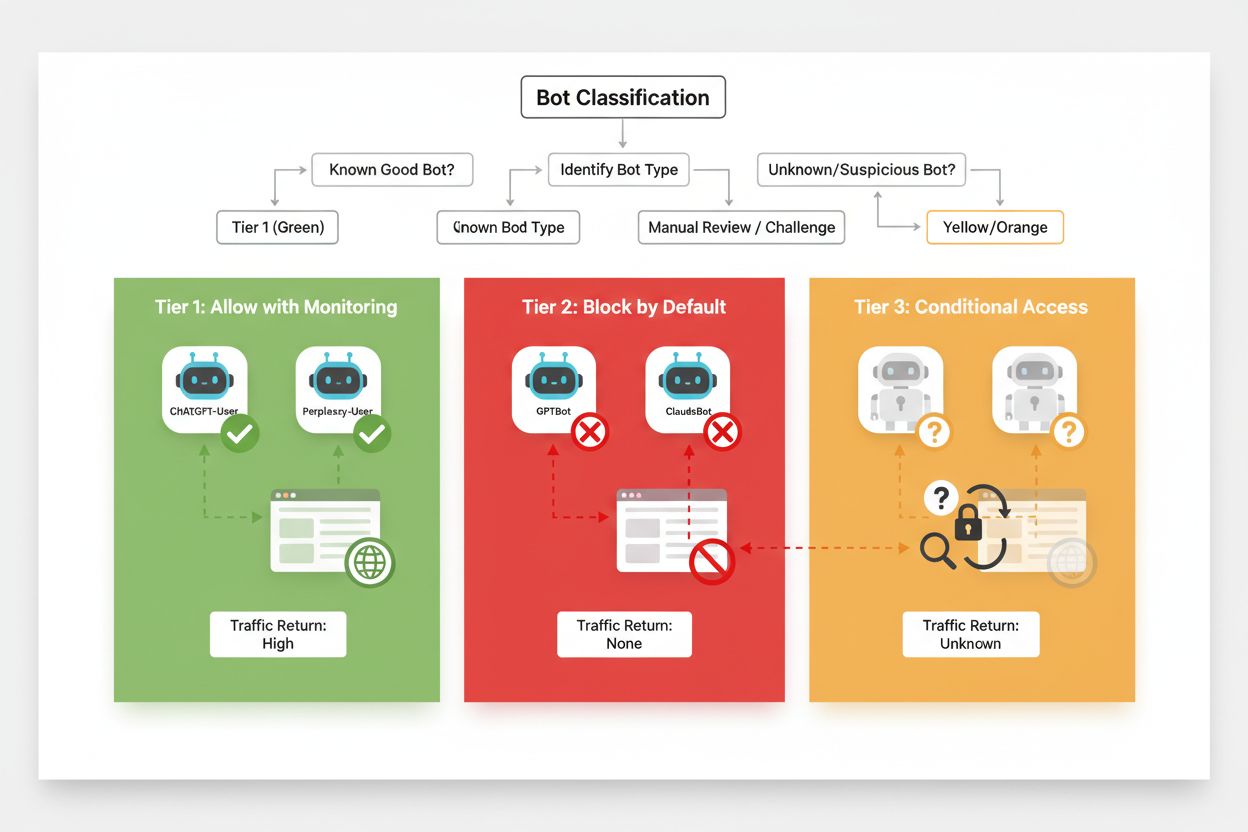
| Tier | Classification | Examples | Action |
|---|---|---|---|
| Tier 1: Revenue Generators | 搜索引擎和高流量推荐来源 | Googlebot, Bingbot, Perplexity Bot | 完全允许访问;优化爬取效率 |
| Tier 2: Neutral/Unproven | 意图不明的新兴爬虫 | 小型AI初创、研究机器人 | 密切监控;允许但限制速率 |
| Tier 3: Value Extractors | 无直接收益的训练爬虫 | GPTBot, Claude-Web, CCBot | 完全屏蔽;多层强制执行 |
实施此框架需持续关注新爬虫及其商业模式。出版方应定期审查访问日志,识别新机器人,研究其运营方的服务条款和补偿政策,并据此调整分类。某个最初归为第3层的爬虫如果开始提供分成,或许可提升至第2层;而原本受信任的爬虫若违反速率限制或robots.txt,也可能降级为第3层。
选择性屏蔽不是“一劳永逸”的配置,需随着爬虫生态变化持续监控与调整。出版方应实施全面日志记录与分析,跟踪哪些爬虫访问了您的内容、消耗了多少带宽、是否遵守了限制。这些数据为决定允许、屏蔽或限速哪些爬虫提供依据。
分析访问日志可揭示爬虫行为模式,指导策略调整:
# 识别访问您网站的所有AI爬虫
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# 统计特定爬虫消耗的带宽
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# 监控被屏蔽爬虫收到的403响应数
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
理想情况下,每周或每月定期分析这些数据,可判断屏蔽策略是否有效、是否有新爬虫出现,以及先前被屏蔽的爬虫行为是否有变。此信息可反馈到您的分类框架,确保政策始终符合业务目标和技术现实。
选择性爬虫屏蔽实施过程中,出版方常犯以下错误,导致策略失效或产生副作用。了解这些陷阱有助于您从一开始就避免代价高昂的失误,实现更有效的政策。
不加区分地屏蔽所有爬虫:最常见的错误是设置过于宽泛的屏蔽规则,将搜索引擎和训练爬虫一并屏蔽,保护内容的同时丧失搜索可见性。
只依赖robots.txt:以为仅靠robots.txt就能防止未授权访问,忽视了13%的爬虫会完全无视该文件,使内容仍易被抓取。
未做监控和调整:策略一成不变,导致错过新爬虫、未及时适应商业模式变化,甚至屏蔽了本可带来收益的爬虫。
仅按User-Agent屏蔽:高级爬虫会伪造或频繁更换User-Agent,仅靠User-Agent屏蔽效果有限,需配合IP规则和速率限制。
忽视限速:即便允许的爬虫,如不加限速,也可能消耗大量带宽,影响真人用户体验并浪费基础设施资源。
未来,出版方与AI爬虫的关系很可能将从简单双向屏蔽转向更复杂的协商与补偿机制。但在行业标准尚未形成前,选择性爬虫控制依然是保护内容、维持搜索可见性的最实用方法。出版方应将屏蔽策略视为动态政策,随着爬虫生态演变,定期重新评估哪些爬虫值得开放访问,哪些应被屏蔽。
最成功的出版方将会实施多层防御——结合robots.txt指令、服务器级控制、CDN防护和持续监控,形成全面策略。这种方法既可防范守规矩和违规爬虫,又能保住带来收入和用户参与的搜索引擎流量。随着AI公司日益重视出版方内容价值,并开始提供补偿或授权机制,您今天搭建的框架将能灵活适应新的商业模式,同时持续掌控您的数字资产。
训练爬虫如GPTBot和ClaudeBot会收集数据来构建AI模型,但不会为您的网站带来流量。搜索爬虫如OAI-SearchBot和PerplexityBot会为AI搜索引擎索引内容,并能为您的网站带来大量推荐流量。了解这一区别对于实施有效的选择性屏蔽策略至关重要。
可以,这正是选择性爬虫控制的核心策略。您可以使用robots.txt禁止训练机器人,同时允许搜索机器人,然后对无视robots.txt的机器人通过服务器级控制进行强制执行。这种方法在保护您的内容不被未经授权训练的同时,保持了在AI搜索结果中的可见性。
大多数主流AI公司声称会遵守robots.txt,但遵守是自愿的。研究显示,大约13%的AI机器人完全无视robots.txt指令。因此,对于重视内容保护的出版方来说,服务器级强制执行至关重要。
数量显著且持续增长。2025年4月,ChatGPT向250家新闻和媒体网站带来了2.438亿访问量,较1月增长98%。屏蔽这些爬虫意味着失去这一新兴流量来源。对许多出版方而言,AI搜索流量现已占推荐流量总量的5-15%。
定期解析您的服务器日志,使用grep命令识别机器人用户代理,跟踪爬取频率,并监控对robots.txt规则的遵守情况。至少每月审查一次日志,以识别新机器人、异常行为模式,以及被屏蔽的机器人是否真的被拦截。这些数据能为您的爬虫策略提供决策依据。
您可以保护您的内容不被未经授权训练,但会失去在AI搜索结果中的可见性,错失新兴流量来源,并可能减少在AI生成答案中的品牌提及。实施全面屏蔽的出版方通常会看到搜索可见性下降40-60%,并错过通过AI平台被发现品牌的机会。
至少每月一次,因为新机器人不断出现,现有机器人也在不断变化。AI爬虫生态变化迅速,新运营方不断推出爬虫,现有玩家也在合并或更名。定期审查可确保您的策略始终与业务目标和技术现实保持一致。
指的是被爬取的页面数量与实际带回您网站的访问者数之比。Anthropic每推荐回1名访问者就爬取38,000个页面,OpenAI的比率为1,091:1,Perplexity为194:1。比率越低,允许该爬虫的价值越高。该指标有助于您根据爬虫实际业务影响决定是否允许其访问。
了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...

AI爬虫与机器人完整参考指南。识别GPTBot、ClaudeBot、Google-Extended及其他20+ AI爬虫,包含User Agent、爬取频率与屏蔽策略。

了解如何根据业务目标有选择地允许或屏蔽AI爬虫。实施差异化爬虫访问,在保护内容的同时保持在AI系统中的可见性。为出版商管理GPTBot、ClaudeBot及其他AI爬虫提供战略指南。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.