

AI专用的Robots.txt:如何控制哪些机器人访问您的内容
了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...
2 分钟阅读
数字格局已从传统搜索引擎优化根本性转向了全新类别的自动化访客:AI爬虫。与通过搜索结果为您网站带来流量的传统搜索爬虫不同,AI训练型爬虫会获取您的内容,用于训练大型语言模型,却不一定带来任何推荐流量。这一区别对依赖网站流量创收的发布者、内容创作者和企业有深远影响。控制哪些AI系统能够访问您的内容,直接关系到您的竞争优势、数据隐私和营收底线。
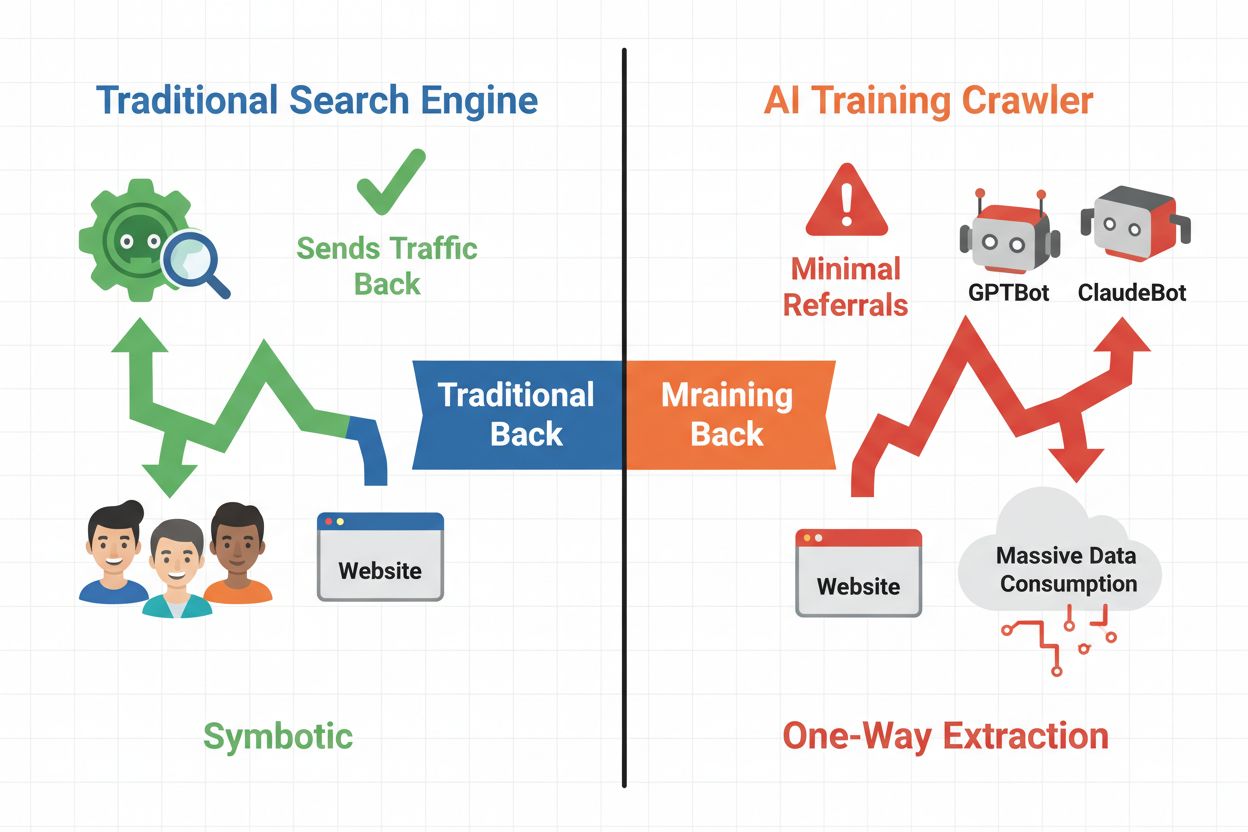
AI爬虫分为三大类型,各自用途和流量影响不同。训练型爬虫由AI公司用于训练和改进其语言模型,通常大规模运行,几乎不带回流量。搜索与引用型爬虫为AI搜索引擎和引用系统索引内容,往往会回传一定的推荐流量。用户触发型爬虫在用户与AI应用互动时按需抓取内容,规模较小但正在增长。了解这些类别,有助于您根据业务模式有针对性地允许或阻止爬虫。
| 爬虫类型 | 目的 | 流量影响 | 示例 |
|---|---|---|---|
| 训练型 | 构建/改进LLM | 极少或无 | GPTBot, ClaudeBot, Bytespider |
| 搜索/引用型 | AI搜索与引用索引 | 中等推荐流量 | Googlebot-Extended, Perplexity |
| 用户触发型 | 按需为用户抓取 | 低但持续 | ChatGPT插件, Claude浏览 |
AI爬虫生态包括全球最大科技公司的爬虫,各自具有不同的用户代理和用途。OpenAI的GPTBot(用户代理: GPTBot/1.0)用于训练ChatGPT等模型,Anthropic的ClaudeBot(用户代理: Claude-Web/1.0)用于Claude。Google的Googlebot-Extended(用户代理: Mozilla/5.0 ... Googlebot-Extended)为AI Overviews和Bard索引内容,而Meta的Meta-ExternalFetcher服务于其AI项目。其它主要爬虫还包括:
各爬虫的抓取规模与对拦截指令的遵守程度差异较大。
robots.txt文件是控制AI爬虫访问的第一道防线,但请注意它只具建议性,并无法律强制力。robots.txt位于您域名根目录(如yoursite.com/robots.txt),通过简单语法指示爬虫需避开的区域。如要全面阻止所有AI爬虫,可添加如下规则:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
如需有选择地拦截——允许搜索型爬虫但阻止训练型爬虫——可采用如下方式:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
常见错误包括使用过于宽泛的规则如Disallow: *(可能导致解析器混淆),或在只想拦截部分爬虫时忘记指定具体爬虫。OpenAI、Anthropic、Google等大公司通常会遵守robots.txt,但如Perplexity等爬虫已被证实会完全无视这些规则。
当robots.txt难以满足需求时,还有多种更强的防护措施可控AI爬虫访问。基于IP的拦截是识别AI爬虫IP段并在防火墙或服务器层面进行拦截,这种方式极为有效,但需要持续维护IP段更新。服务器级拦截可通过.htaccess(Apache)或Nginx配置文件实现,控制更细致,也比robots.txt更难被绕过。Apache服务器可采用如下规则:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Meta标签拦截(如<meta name="robots" content="noindex, noimageindex, nofollowbydefault">)可防止被索引,但无法阻止训练型爬虫。请求头验证则通过反向DNS和SSL证书校验,确认爬虫身份是否属实。若需确保爬虫绝对无法访问您的内容,应采用服务器级拦截,并多种方式结合实现最大防护。
是否阻止AI爬虫,需权衡多方利益。阻止训练型爬虫(GPTBot、ClaudeBot、Bytespider)可防止您的内容被用于AI模型训练,保护知识产权和竞争优势。但允许搜索型爬虫(Googlebot-Extended、Perplexity)则可能带来推荐流量,提高在AI搜索结果中的可见性——这是一个日益增长的流量渠道。权衡点还包括部分AI公司的“爬取/推荐比”极低:Anthropic的爬虫平均每38,000次抓取才带来一次推荐,OpenAI约为400:1。服务器负载和带宽也是考量:AI爬虫消耗大量资源,阻止它们有助于降低基础设施成本。您的选择应贴合业务模式:新闻媒体和发布者或许更看重推荐流量,而SaaS公司和专有内容创作者则倾向于全面阻止。
实施拦截只是第一步,还需验证爬虫是否遵守您的指令。服务器日志分析是主要验证手段:检查access日志中相关爬虫的用户代理和IP,确认拦截是否生效。可用grep命令筛查日志:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
此命令统计这些爬虫访问您网站的次数。还可用测试工具如curl模拟请求,检测拦截效果:
curl -A "GPTBot/1.0" https://yoursite.com/robots.txt
拦截实施首月建议每周检查日志,之后每季度检查一次。若发现爬虫无视robots.txt,应升级为服务器级拦截,或联系爬虫运营方的滥用投诉团队。
AI爬虫生态变化极快,新公司不断推出AI产品,现有爬虫也会更换用户代理和IP段。每季度检查拦截名单,确保未遗漏新爬虫或误伤正常流量。由于生态碎片化,难以形成永久有效的拦截清单。可关注如下渠道获取更新:
建议每90天设日历提醒检查robots.txt和服务器规则,并订阅安全邮件列表,关注爬虫部署新动向。
阻止AI爬虫可防止其获取您的内容,AmICited则解决了另一个问题:监控AI系统是否在其输出中引用和提及您的品牌与内容。AmICited会跟踪AI生成回答中对您组织的提及,帮助您洞察内容对AI模型输出的影响,以及品牌在AI搜索结果中的曝光。这构建了完整的AI策略:您用robots.txt和服务器级拦截控制内容访问,同时AmICited帮助您了解内容在AI系统中的下游影响。两者结合,实现AI生态下对自身影响力的全方位可见与掌控——既防止内容被滥用训练,也衡量内容在AI平台上的实际引用与影响。
不会。阻止GPTBot、ClaudeBot、Bytespider等AI训练爬虫不会影响您的Google或Bing搜索排名。传统搜索引擎使用不同的爬虫(如Googlebot、Bingbot),两者相互独立。只有在您希望完全从搜索结果中消失时才需要阻止这些爬虫。
OpenAI(GPTBot)、Anthropic(ClaudeBot)、Google(Google-Extended)和Perplexity(PerplexityBot)等主流爬虫官方声明遵守robots.txt指令。但一些规模较小或不透明的爬虫可能会忽略您的配置,这也是为什么需要分层防护策略。
取决于您的策略。仅阻止训练型爬虫(GPTBot、ClaudeBot、Bytespider)可以保护您的内容不被用于模型训练,同时允许以搜索为目的的爬虫帮助您出现在AI搜索结果中。完全阻止则会让您彻底退出AI生态。
至少每季度检查一次您的配置。AI公司会定期推出新爬虫。Anthropic将其“anthropic-ai”和“Claude-Web”合并为“ClaudeBot”,新爬虫在未更新规则的网站上获得了临时不受限的访问权限。
阻止会彻底防止爬虫访问您的内容,保护其不被用于训练数据收集或索引。允许爬虫访问则可能导致您的内容被用于模型训练,或以极少的推荐流量出现在AI搜索结果中。
可以,robots.txt是建议性而非强制性的。大型公司的爬虫一般会遵守robots.txt指令,但有些爬虫会忽略。若需更强防护,应通过.htaccess或防火墙规则实现服务器级阻止。
查看您的服务器日志,查找被阻止爬虫的用户代理字符串。如果仍有被阻止的爬虫请求,说明它们可能未遵守robots.txt。可使用Google Search Console的robots.txt测试工具或curl命令验证配置。
阻止训练爬虫通常对直接流量影响极小,因为它们本就几乎不带来推荐流量。但阻止搜索爬虫可能会降低在AI驱动的发现平台上的曝光。实施拦截后30天内监控您的分析数据以衡量实际影响。
了解如何使用robots.txt控制哪些AI机器人访问您的内容。完整指南,涵盖如何屏蔽GPTBot、ClaudeBot及其他AI爬虫的实用案例与配置策略。...

AI爬虫与机器人完整参考指南。识别GPTBot、ClaudeBot、Google-Extended及其他20+ AI爬虫,包含User Agent、爬取频率与屏蔽策略。

2025年AI爬虫全面指南。识别GPTBot、ClaudeBot、PerplexityBot及20+其他AI机器人。学习如何通过robots.txt和高级技术阻止、允许或监控爬虫。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.