

G2 评价与 AI 可见性:完整优化指南
精通 G2 优化,提升 AI 搜索可见性。学习如何增加 AI 引用,优化你的资料,并用数据驱动的策略为 ChatGPT、Perplexity 和 Google AI 概览衡量投资回报。...
3 分钟阅读
在当今高速演进的人工智能领域,评价平台已成为企业软件采购者的关键发现渠道。当潜在客户搜索 AI 解决方案时,他们越来越多地依赖 G2、Capterra 等平台来验证购买决策。这些评价网站成为数字信任锚点,其社会背书影响着 AI 品牌在人类决策者和大模型推荐中的认知与推荐方式。评价集中在这些平台,已从根本上改变了 AI 厂商在市场上争夺可见性与可信度的方式。
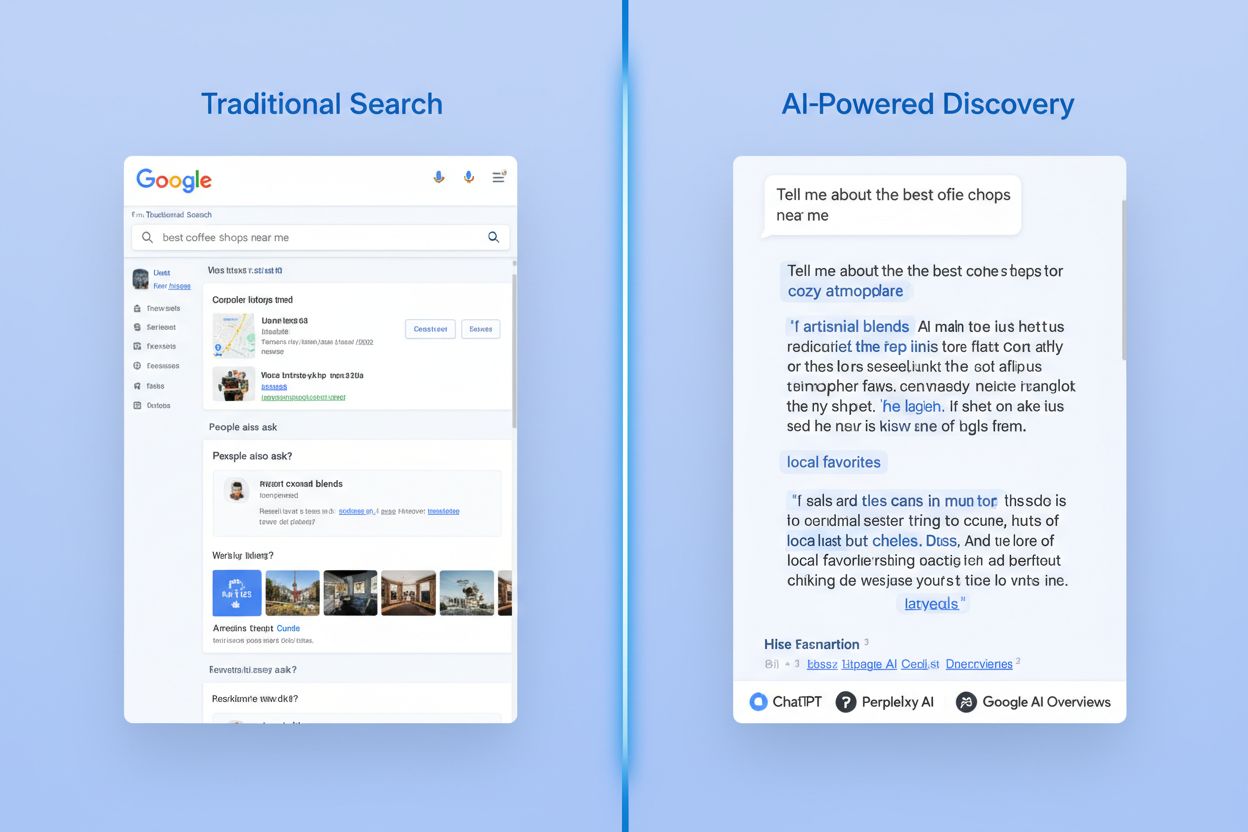
G2 已成为AI 软件评价领域的主导力量。研究显示,LLM 在约 68% 的 AI 产品推荐中引用 G2 评价。这一压倒性选择源于 G2 对 AI 工具的全面覆盖、先进的评分算法及其作为企业级软件评测事实标准的地位。与其他评价平台相比,G2 的影响力显著更大,具体如下表:
| 平台 | LLM 引用率 | AI 产品平均评价数 | 市场覆盖率 |
|---|---|---|---|
| G2 | 68% | 127 | 覆盖 94% 主流 AI 工具 |
| Capterra | 42% | 89 | 覆盖 76% 主流 AI 工具 |
| Trustpilot | 18% | 34 | 覆盖 31% 主流 AI 工具 |
| Gartner Peer Insights | 35% | 156 | 覆盖 52% 主流 AI 工具 |
| 行业专属网站 | 12% | 45 | 覆盖 28% 主流 AI 工具 |
G2 的主导不仅体现市场地位,更反映出LLM 对 G2 这种大规模、结构化评价数据的算法偏好。

这些平台上的评价数量与AI 品牌在 LLM 推荐中的可见性高度相关。在 G2 上评价超过 100 条的产品,被 AI 搜索结果提及的概率是评价少于 20 条产品的 3.2 倍。这造成强大的网络效应:成熟产品获得更多评价,提升可见性,吸引更多客户留下新评价。对于新兴 AI 厂商而言,这既是挑战也是机遇——门槛高,但持续积累高质量评价可大幅加速市场渗透。评价数量的“加速点”大约在50-75 条,AI 产品在 LLM 推荐中才会获得实质性可见度。
Capterra 在 AI 软件推荐生态中发挥着互补但独特的作用。G2 虽在引用频次上占优,Capterra 在垂直行业 AI 解决方案中表现突出,尤其在 HR 科技、会计软件和包含 AI 特性的项目管理工具领域。Capterra 的评价验证流程和对详细用例文档的关注,对重视实施洞察的中大型客户尤为有价值。平台与软件对比矩阵的集成,使得在 Capterra 上露出的产品在潜在客户调研 AI 解决方案时常获得搜索排名算法加持。此外,Capterra 的评价更强调实际部署挑战和 ROI 指标,LLM 在为关键业务场景推荐 AI 时也更优先考虑这些要素。
AI 推荐系统的普及带来了验证危机,而评价平台能独特地解决这一难题。尽管大模型功能强大,但若无外部验证,推荐产品时极易出现“幻觉”或信息滞后。评价平台为 LLM 提供了可供引用的真实数据,帮助其验证推荐建议并提供最新、真实的 AI 产品信息。此验证功能已成为企业依赖 AI 助手评估 AI 工具时的刚需。主要优势包括:
传统 B2B 软件采购流程已被评价平台融入 AI 推荐彻底改变。以往买家需独立调研、同业交流、厂商互动——通常需 4-6 周。如今,AI 辅助采购流程将周期压缩至 7-10 天,评价平台成为主要对比情报源。这一转变让评价优势厂商受益,但未建立评价口碑的品牌则处于劣势。当前买家旅程通常以AI 搜索查询起步,产品按评价指标排序,随后分析评价内容,最后才与厂商沟通。意味着优化评价与产品开发同等重要,是 AI 厂商争取市场的关键。
评价质量与数量构成 AI 厂商策略的微妙平衡。虽然评价量影响可见性,产品需达到一定门槛才能获得算法推荐,但评价质量更决定转化率与获客成本。拥有 80 条高质量、详实评价(平均 4.7/5 分)的产品,其转化率通常是 150 条但质量较低评价(4.2/5 分)的 2.1 倍。这说明以评分一致性、评价深度和新颖性衡量的质量,或许比绝对数量更影响实际销售。然而“可见门槛”依旧要求足够评价量,厂商必须量质双优。
通过评价实现竞争定位,已成为 AI 软件市场主要竞争阵地。厂商日益认知到评价口碑直接影响 LLM 推荐与搜索排名。平均分4.6+、每月稳定新增 15-25 条评价的产品,在 AI 推荐场景中可见性约高出竞争对手 40%。战略性评价管理——鼓励满意客户详评,专业回应负评,突出差异化功能——已成为核心市场职能。最成功的 AI 厂商将评价口碑视为动态竞争资产,如同产品路线、客户成功一样持续投入和优化。
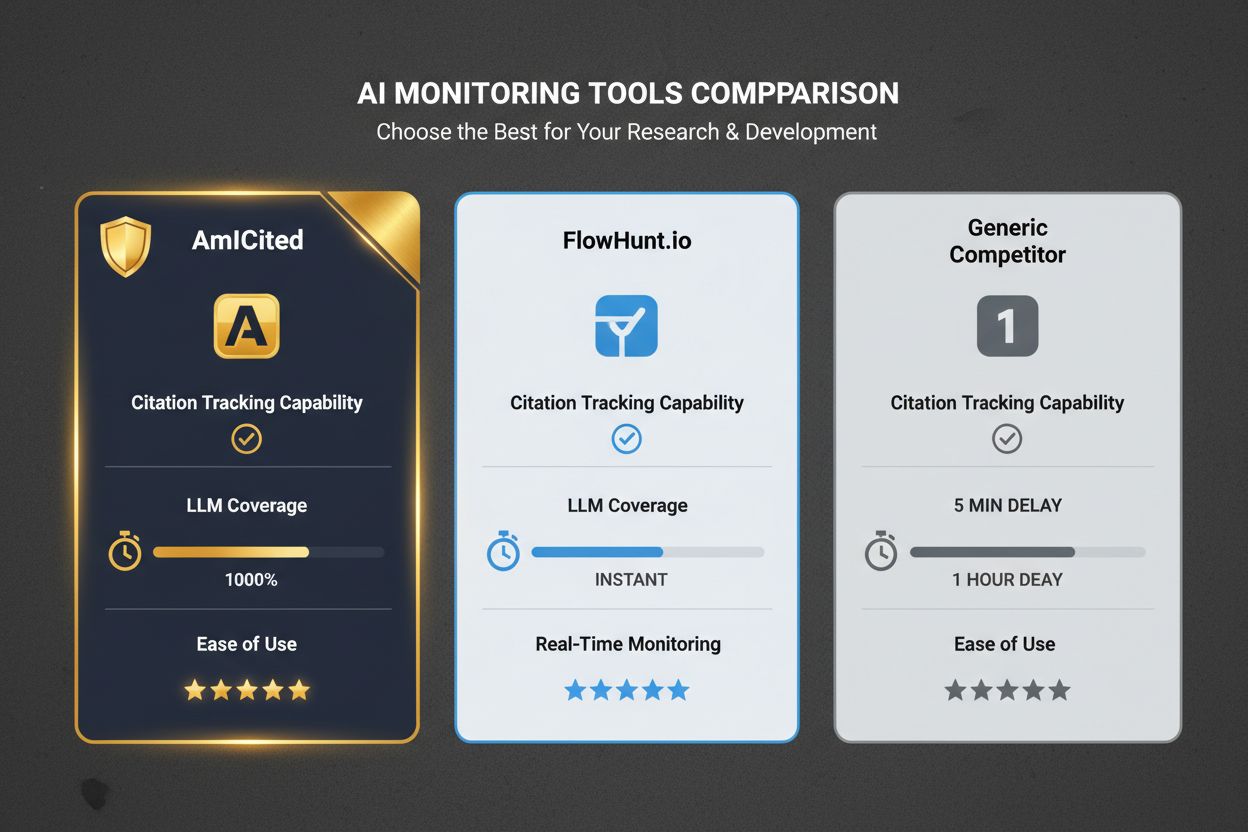
AmICited 已成为 AI 厂商洞察评价生态与 LLM 推荐格局的关键监测工具。平台可实时追踪 AI 产品在 LLM 推荐中被引用频次,并将其与评价指标、竞争地位和市场趋势关联分析。通过整合多平台评价数据与 LLM 输出监测,AmICited 帮助厂商量化评价优化 ROI,发现评价覆盖的薄弱点。此能力尤为适合分析哪些平台带来最大可见性、哪些客户群对 LLM 推荐最具影响力。对竞争激烈的 AI 厂商而言,AmICited 提供数据驱动洞察,助力优先投资评价平台和优化客户口碑项目。
与传统监测工具相比,AmICited 在 AI 场景下优势明显。传统 SEO 工具只关注搜索排名,完全忽略 LLM 推荐渠道。通用评价监测平台虽能追踪评价数量与分数,却缺乏 AI 场景与 LLM 引用监测。部分 AI 监测工具只关注社媒或新闻提及,却忽视真实影响决策的评价渠道。AmICited 的一体化方案——集评价平台数据、LLM 引用追踪、竞争对标与市场趋势分析于一体,全方位呈现 AI 产品在数字生态中的认知与推荐路径。这一视角帮助厂商制定明智策略,投入评价优化,锁定优质客户群,优化产品在 LLM 推荐中的竞争定位。
AI 厂商应采用战略性、多平台的评价优化模式,充分认识 G2、Capterra 及其他平台各自的市场角色。与其在所有平台平均发力,不如结合目标客户群、竞争定位和客户调研平台有针对性地重点突破。以下建议可作为最大化评价影响力的操作框架:
G2 评价会直接影响 LLM 的引用。研究显示,评价数量提升 10%,AI 引用量就会提升 2%。LLM 信任 G2 的验证买家数据及规范化结构,使其成为 AI 自动答案中首选的软件推荐来源。
LLM 优先选择提供验证买家信息、规范化数据结构和最新市场动态信号的评价平台。G2 和 Capterra 均大规模具备这些特性,因此成为 AI 推荐软件解决方案时可信赖的引用源。
以详细、对比为主、包含具体使用场景和可量化结果的评价最容易被引用。能够阐明问题-解决过程、对比替代方案并说明具体成效的评价,为 LLM 提供了准确推荐所需的上下文。
优化品牌资料详情,鼓励客户留下全面评价,及时回应反馈,并保持一致表达。重点争取对比竞品、突出具体使用场景和成效的评价。
质量比数量更关键。虽然评价数量与被引用量有关,但结构清晰、内容详实、包含明确结论与对比的评价,比普通好评更易被 LLM 抽取与引用。
AmICited 跟踪 ChatGPT、Perplexity 和 Google AI Overviews 等 AI 模型如何在评价平台及其他来源引用您的品牌。它可实时监测品牌提及、情感分析及 AI 答案中的竞争地位。
评价网站是 LLM 重要的种子平台,因为这些平台被 AI 大量爬取且信息结构化、经过验证。在这些平台上优化品牌存在,是 B2B 软件公司 LLM 种子策略的核心组成部分。
资料建议每季度或产品有重大更新时审核并更新。定期更新会向 LLM 传递信息新、相关的信号,提高 AI 推荐中被准确引用的概率。
精通 G2 优化,提升 AI 搜索可见性。学习如何增加 AI 引用,优化你的资料,并用数据驱动的策略为 ChatGPT、Perplexity 和 Google AI 概览衡量投资回报。...

关于客户评论与 AI 搜索可见度的社区讨论。营销人员分享了 G2、Capterra 及其他平台上的评论如何影响 AI 引用和推荐的真实经验。...
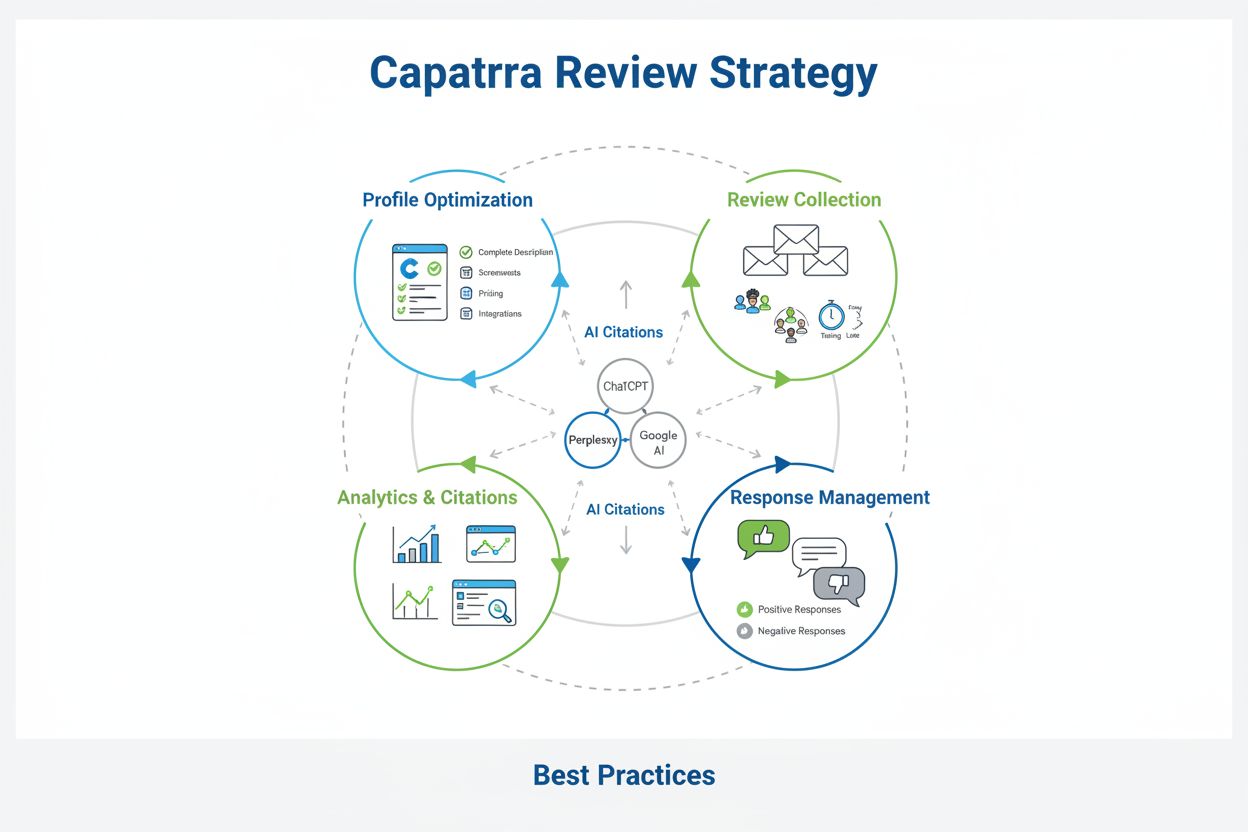
精通AI工具的Capterra优化。学习行之有效的策略,提升评价数量、提高曝光率,并通过可执行的最佳实践提升AI引证。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.