
AI可见性调查数据:专有数据如何提升被引用率
了解专有调查数据和原创统计数据如何成为LLM的引用磁石。探索提升AI可见性并赢得ChatGPT、Perplexity与Google AI综述更多引用的策略。...
2 分钟阅读
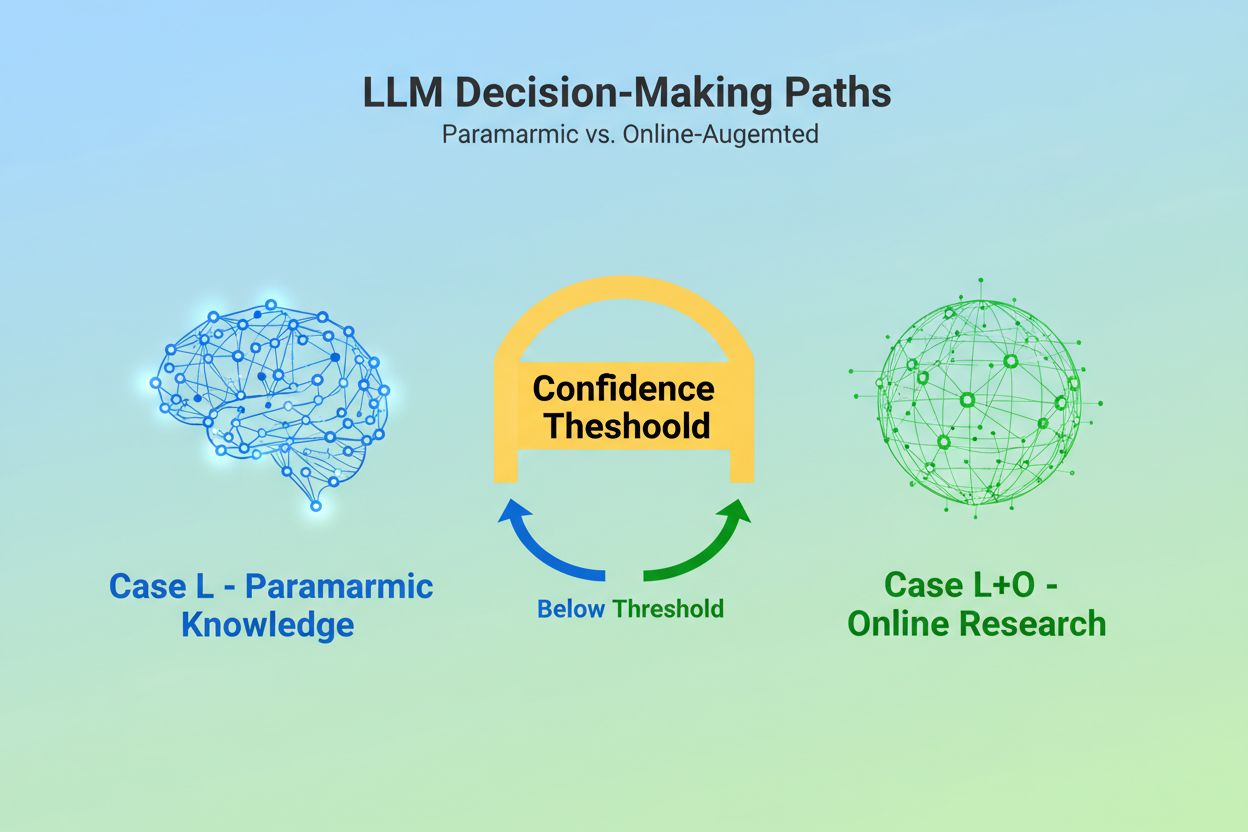
当大型语言模型接收到查询时,首先面临一个根本性的决策:是仅依赖训练期间嵌入的知识,还是检索网络上的最新信息?这种二元选择——研究人员称为Case L(仅用学习数据)与Case L+O(学习数据加上在线检索)——决定了LLM是否会引用外部来源。在Case L模式下,模型只依赖其参数知识库,即在训练期间学到的模式的浓缩表达,通常反映的是模型发布前几个月甚至一年以上的信息。在Case L+O模式下,模型会触发一个置信阈值,从而启动外部检索,打开研究人员所说的“候选空间”——即各种URL和来源。这个决策点对大多数监控工具来说是不可见的,但正是在这里,整套引用机制才开始运作——如果没有检索阶段的触发,就无法评估或引用任何外部来源。
一旦LLM决定检索外部来源,它就进入了引用选择中最关键的阶段:证据加权。此时,模型会区分普通提及和权威推荐。模型并不简单统计某个来源出现的次数或其在搜索结果中的排名;相反,它会评估证据本身的结构完整性。模型会分析文档架构——来源是否包含清晰的数据关系、重复出现的标识符和被引用的链接——并将这些视为可信度的标志。模型会构建一个“证据图谱”,其中节点代表实体,边代表文档间的关系。每个来源的权重不仅取决于内容相关性,还取决于事实在多文档间的一致性确认、信息的主题相关度以及域名的权威性。这个多维度评估形成了所谓的证据矩阵,决定了哪些来源足够可靠可以被引用。值得注意的是,这一阶段运行在LLM的推理层,而传统的GEO监控工具仅能测量检索信号,无法察觉这一过程。
结构化数据——尤其是JSON-LD、Schema.org标记和RDFa——在证据加权过程中起到倍增器的作用。正确实施结构化数据的来源,其在证据矩阵中的权重会比非结构化内容高出2-3倍。这并不是因为LLM对格式美观有所偏好,而是结构化数据实现了实体链接——通过@id、sameAs和Q-ID(Wikidata标识符)等机器可读的标识符,在多文档间连接同一实体。当LLM遇到带有组织Q-ID的来源时,可以立即在多文档中验证该实体,形成所谓的“跨文档实体共指”。这一验证大大提升了对该来源可靠性的信心。
| 数据格式 | 引用准确率 | 实体链接 | 跨文档验证 |
|---|---|---|---|
| 非结构化文本 | 62% | 无 | 手动推断 |
| 基础HTML标记 | 71% | 有限 | 部分匹配 |
| RDFa/Microdata | 81% | 良好 | 基于模式 |
| 带Q-ID的JSON-LD | 94% | 极佳 | 已验证链接 |
| 知识图谱格式 | 97% | 完美 | 自动验证 |
结构化数据的影响体现在两个时间维度。即时性上,LLM在线检索时会实时读取JSON-LD和Schema.org标记,将这些结构化信息立即纳入当前响应的证据加权。持久性上,结构化数据如果长期保持一致,会在未来训练周期中被整合进模型的参数知识库,即便没有在线检索,也能影响模型对实体的识别与评估。这种双重机制意味着,正确实施结构化数据的品牌,不仅能获得即时的引用可见性,还能在模型内部知识空间中获得长期权威地位。
在LLM引用某个来源之前,首先需要理解该来源的主题及其代表对象。这正是实体识别的工作,即将模糊的人类语言转化为机器可读的实体。当文档提到“Apple”时,LLM必须判断其指的是苹果公司、水果,还是其他含义。模型通过来自Wikipedia、Wikidata和Common Crawl的已训练实体模式,并结合上下文分析实现这一点。在Case L+O模式下,这一过程会更复杂:模型会对照外部结构化数据进行实体验证,查找@id属性、sameAs链接和Q-ID等权威标识符。这个验证步骤至关重要,因为模糊或不一致的实体引用会在模型推理过程中被淹没。品牌如果命名不一致、缺乏清晰的实体标识符或未实现Schema.org标记,对机器来说就语义模糊——表现为多个不同实体,而非统一的权威来源。相反,跨多文档持续被一致引用的实体,会被LLM视为知识图谱中的可靠节点,大幅提升被引用概率。
从查询到引用,LLM遵循研究人员通过模型行为分析出的七阶段结构化流程。第0阶段:意图解析,模型对用户输入分词、语义分析,并生成意图向量——即用户真正需求的抽象表达。这决定了哪些话题、实体和关系值得关注。第1阶段:内部知识检索,模型访问参数知识并计算置信分数。若分数高于阈值,则停留在Case L模式,否则进入外部检索。第2阶段:多路查询生成(仅Case L+O),模型生成多个语义变化的检索词组(通常每个1-6个token),尽量广泛开启候选空间。第3阶段:证据提取,模型从搜索结果中获取URL和片段,解析HTML,提取JSON-LD、RDFa和microdata——此时结构化数据首次被引用机制“看到”。第4阶段:实体链接,模型识别检索文档中的实体,并与外部标识符验证,临时构建关系知识图谱。第5阶段:证据加权,模型评估各来源证据强度,包括文档结构、来源多样性、事实确认频率和跨来源一致性。第6阶段:推理与综合,模型结合内外部证据,消解矛盾,决定每个来源是仅提及还是权威推荐。第7阶段:最终响应构建,模型将加权结果转化为自然语言输出,并在适当位置整合引用。各阶段间有反馈回路,若发现不一致,模型可调整检索或重新评估证据。

现代LLM越来越多地采用检索增强生成(RAG)技术,这彻底改变了引用的选择与论证方式。RAG系统不是仅依赖参数知识,而是主动检索相关文档、提取证据,并将回答依据具体来源。这一方式将引用从训练的隐性副产品转变为显性、可追溯的过程。RAG通常采用混合检索,将关键词检索与向量相似度检索结合,最大化召回率。检索到候选文档后,利用语义排序,按含义而非关键词匹配重新打分,确保最相关来源浮现。这种显性检索机制让引用过程更透明、可审核——每个被引用的来源都可追溯到具体支撑其入选的片段。对于关注AI可见性的组织,RAG系统尤为关键,因为它们创造了可衡量的引用模式。像AmICited这样的工具可跟踪RAG系统在不同AI平台如何引用您的品牌,帮助分析您是作为被引用来源还是仅在证据检索阶段作为背景材料出现。
并非所有引用都具有同等价值。LLM可能将某一来源作为背景资料提及,而将另一来源推荐为权威证据——这种差异完全取决于证据加权,而非检索本身。来源可以出现在候选空间(第2-3阶段),但若证据分数不足,则无法获得推荐地位。提及与推荐的分野正是传统GEO指标的盲区。标准监控工具只能衡量您的内容是否出现在搜索结果中,却无法判断LLM是否认为您的内容足够可信以被推荐。提及往往表现为“有些来源表明……”,而推荐则是“据[来源]显示,证据表明……”。二者的区别在于第5阶段的证据矩阵分数。拥有一致Q-ID、结构良好的文档架构,以及多独立来源确认的内容更易获得推荐地位;而实体引用模糊、结构混乱或仅有孤立主张的内容,则多为提及。对于品牌来说,这一区别至关重要:被检索并不等于被权威引用。从检索到推荐的转变需要语义清晰、结构完整和证据密度——这些是传统SEO优化无法覆盖的因素。
理解LLM如何选择来源,对内容策略有直接且可操作的影响。首先,在网站各处持续实施Schema.org标记,特别是组织信息、文章和关键实体,使用JSON-LD格式,并为@id和sameAs链接指向Wikidata、Wikipedia等权威来源。这能直接提升您在第5阶段的证据权重。第二,为组织、产品和核心概念建立清晰的实体标识符。使用一致命名,避免造成歧义的缩写,并通过isPartOf、about、mentions等层级关系链接相关实体。第三,创建机器可读的证据,发布结构化数据来支撑您的主张、资质和关系。不要只写“我们是X领域的领先者”,而要用结构化数据、引用和可验证关系加以佐证。第四,保持多平台和长期内容一致性。LLM会通过跨独立来源确认主张的密度来评估证据;只在单一平台孤立发声,分量会大打折扣。第五,理解传统SEO指标无法预测AI引用。高搜索排名并不保证获得LLM推荐,应将重点放在语义清晰和结构完整上。第六,用AmICited等工具监控您的引用模式,跟踪不同AI系统如何引用您的品牌,了解自己是被提及还是被推荐,以及哪些内容类型推动引用。最后,认识到AI可见性是长期投资。您今天实施的结构化数据,既提高了即时被引用概率(即时效应),又将在后续训练周期中塑造模型的内部知识库(持久效应)。
随着LLM不断进化,引用机制日益复杂且透明。未来模型很可能会实现引用图谱——明确展示不仅引用了哪些来源,还能追溯每条回应内容背后的来源影响路径。一些先进系统已经在尝试为引用附加概率置信分数,指示模型对来源相关性和可靠性的信心水平。另一个新趋势是人类参与验证,用户可对引用内容发起质询并反馈,帮助模型优化未来查询的证据加权。结构化数据被纳入训练周期,意味着今天布局语义基础设施的组织,正在为AI系统构建长期权威。与搜索引擎排名随算法变动而波动不同,结构化数据的持久效应为AI可见性提供了更稳定基础。这种从传统可见性(被找到)到语义权威(被信任)的转变,是品牌数字传播策略的根本变革。新格局下的赢家,不是内容最多或搜索排名最高的企业,而是那些以机器能可靠理解、验证和推荐的方式结构化信息的组织。
Case L仅使用模型参数知识库中的训练数据,而Case L+O则补充了实时网络检索。模型的置信阈值决定采用哪种路径。这一区别至关重要,因为它决定是否可以评估并引用外部来源。
证据加权决定了这种区别。拥有结构化数据、一致标识符和跨文档确认的来源会被提升为“推荐”,而不仅仅是提及。来源可以出现在搜索结果中,但如果其证据得分不足,则无法获得推荐地位。
结构化数据(JSON-LD、@id、sameAs、Q-ID)在证据矩阵中获得2-3倍的加权。这类标记实现了实体链接和跨文档验证,大幅提升来源的可靠性得分。正确实施Schema.org的来源更有可能被权威引用。
实体识别是LLM区分不同实体(组织、人物、概念)的方式。通过一致命名和结构化标识符实现清晰的实体识别,能避免混淆并提升被引用概率。模糊的实体引用会在模型推理过程中被忽略。
RAG系统实时检索和排序来源,使引用选择比纯参数知识更透明、更有证据基础。这种检索机制创造了可衡量的引用模式,可通过AmICited等监控工具追踪和分析。
可以。持续实施Schema.org标记,建立清晰的实体标识符,创建机器可读的证据,保持多平台内容一致性,并监控引用模式。这些因素直接影响您的内容在LLM响应中是被提及还是被推荐。
传统可见性衡量搜索结果的覆盖和排名。AI可见性衡量您的内容在LLM推理过程中的权威证据地位。被检索并不等同于被权威引用——后者需要语义清晰和结构完整。
AmICited追踪AI系统在GPT、Perplexity和Google AI Overviews中如何引用您的品牌。它揭示您是获得提及还是推荐、哪些内容类型触发引用,以及您的引用模式在不同AI平台间的对比。
了解专有调查数据和原创统计数据如何成为LLM的引用磁石。探索提升AI可见性并赢得ChatGPT、Perplexity与Google AI综述更多引用的策略。...

了解如何识别并定位LLM源站点以进行战略性反向链接。发现哪些AI平台最常引用来源,并为2025年AI搜索可见性优化您的链接建设策略。...

了解维基百科引用如何塑造AI训练数据,并在LLM中产生涟漪效应。了解为何你的维基百科存在对于AI提及和品牌认知至关重要。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.