
社交证明与AI推荐:信任的纽带
了解社交证明如何塑造AI推荐并影响品牌可见性。了解为何客户评论如今成为大模型关键训练数据,以及如何优化AI可见性。...
1 分钟阅读
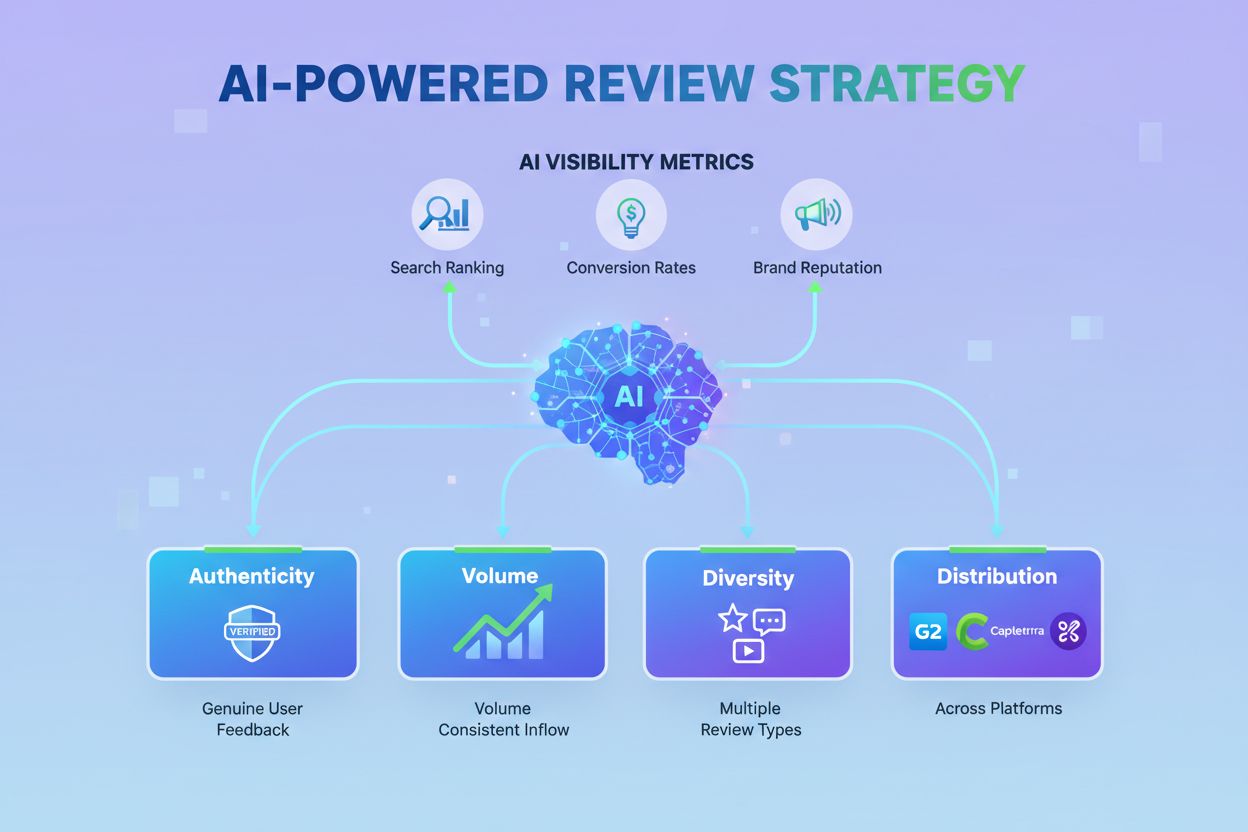
学习如何管理评论以实现最大的 AI 可见性。了解真实性、语义多样性和战略分布对于 LLM 引用和品牌在 AI 回应中的提及的重要性。
在数字化环境中,客户评论经历了根本性的转变。多年来,评论的唯一作用是建立社会认同,以安抚人类消费者、影响购买决策。如今,评论已演变为更重要的内容——它们已成为训练数据,塑造着大型语言模型如何描述和推荐品牌。像 ChatGPT、Claude 和 Perplexity 等 LLM 是通过包含公开评论内容的大型数据集训练的,这意味着每一句客户评论都成了 AI 学习如何谈论您业务的语料库组成部分。这一双重用途从根本上改变了品牌制定评论策略的思路。客户在评论中使用的语言,不仅影响其他人类,也直接编写了 AI 系统明天将生成的品牌叙事。当客户写下“在大雨中 20 英里越野跑依然表现良好”时,他不仅在安慰潜在买家——他还提供了 LLM 之后可能在推荐耐用防水装备时沿用的表述。这一转变意味着,真实的客户语言现在在两个独立渠道中都极具分量:人类信任与机器学习,使评论的真实性和多样性比以往任何时候都更加关键。

大型语言模型在生成回答时不会对所有内容一视同仁。它们出于三个相互关联的原因,特别优先考虑评论数据,品牌必须了解这些逻辑,以优化自身在 AI 中的可见性。最新性是首要关键因素——模型和 AI 概览非常依赖新鲜信号,持续不断的最新评论让 AI 认为您的品牌活跃,描述也更及时相关。数量是第二大支柱;一条评论影响很小,但数百或数千条评论形成了 AI 可以自信采纳和综合的模式。措辞多样性是第三个常被忽略的要素——“产品很好、发货快”这样的通用好评对 LLM 贡献有限,而具体、变化丰富的描述则为 AI 系统打开了新的语言空间。
| 通用评论 | 具体评论 | AI 价值 |
|---|---|---|
| “产品很好” | “在大雨中 20 英里越野跑依然表现良好” | 高——提供了具体的使用场景和性能背景 |
| “发货快” | “2 天送达并附有详细物流跟踪” | 高——提供了具体时效和服务细节 |
| “质量不错” | “素皮不显廉价且很耐用” | 高——材料和耐用性的具体评估 |
| “强烈推荐” | “马拉松训练时有效防止后跟打滑,感觉很稳” | 高——具体运动表现指标 |
这种区分意义重大,因为 LLM 是跨数据集总结模式,而不是突出个别评论。当 AI 系统遇到数百条评论都说某鞋“支撑性好且耐用”,它会将这些词汇与产品关联起来。但如果遇到多样化描述——“极强的耐磨性”、“后跟支撑出色”、“长时间穿着很稳定”、“机洗后依然完好”——AI 能获得更丰富的描述词库,适用于不同语境和提问。这种措辞多样性直接扩展了 AI 系统可利用的语义表面积,让您的品牌在更多意想不到的查询中被发现。
语义表面积指的是您的品牌在 AI 训练数据中占据的独特语言领域。每句不同的客户描述,都会为 AI 系统创造更多在不同查询下曝光品牌的入口。当评论用不同话语表达同一特性时,会指数级增加 LLM 能找到并推荐您产品的方式。例如,一双鞋可能被描述为“支撑性好”、“很稳”、“对足弓很友好”、“防止脚部疲劳”、“长距离穿着很舒适”——每个短语都为 AI 回答鞋类问题时提供了一条不同语义路径。扩展后的语义表面积,使品牌从狭窄的可见性转变为多元广泛的可见性,覆盖多种查询类型和语境。
看看多样化表述如何创造多条发现路径:
当客户用如此多样的语言描述您的产品时,他们实际上是在为 LLM 创造多条可供 AI 跟踪的语义路径。AI 回答“什么鞋适合马拉松跑者?”时,可能就是根据“马拉松训练”这一短语找到您的品牌。另一个关于“耐用素皮替代品”的查询,则可能通过完全不同的评论措辞将您的产品展示出来。这种语义扩展,让您的品牌不仅能覆盖主关键词,还能出现在您从未直接针对的相关查询中。那些在评论中用真实客户语言描绘多层次产品画像的品牌,将赢得 AI 可见性竞争。
评论策略中常见的误区是品牌需要在保持真实性和追求数量之间做选择。实际上,持续的正面评论始终胜过偶尔的负面,这正是 LLM 在总结品牌叙事时的规律。AI 不会突出单条负面评论,而是识别整个数据集的模式。这意味着,一家有 500 条真实评论(即使其中 50 条是负面的)品牌,其信号远胜于只有 100 条全是可疑好评的品牌。LLM 足够智能,能识别操控模式,并更看重持续性而非短期活动。突然爆发大量相同的五星好评,会被 AI 视为刷单;而持续不断、内容多样、偶有真实批评的正面评论,才是 AI 认为的真实用户反馈。持续评论是 AI 认可相关性的信号,远胜于一次性评论高峰后的沉寂。当 LLM 看到品牌每月都持续收到新评论,就会判断产品依然活跃且持续被关注。与其追求短时间的评论激增,不如保持稳定、真实的评论流入,这样构建的 AI 可见性更加持久。
随着评论越来越多地被用于 AI 训练数据,真实性已成为不可妥协的底线。AI 系统筛查操控手段日益精细,品牌若在评论真实性上走捷径,可能在 AI 回应中被边缘甚至惩罚。真实性包括多个层面,共同构成 AI 认可并奖励的信任信号。
对 AI 系统而言,最重要的评论恰恰是人类也会信任的。经过验证、真实且多样的声音会脱颖而出,而人为制造的信号会逐渐消失。人类信任与 AI 信任的高度一致,为评论策略设立了强大激励规则:适用于人类买家的最佳评论策略,也是 AI 可见性的最佳策略。
传统 SEO 指标如关键词排名和自然流量,在 AI 主导的发现环境下只讲述了部分故事。传统指标已不完整,因为它们无法反映 AI 如何描述您的品牌,或您是否被引用在那些并不产生直接点击的回答中。全新的核心问题不是“我们排第几?”,而是“AI 现在是如何描述我们的品牌的?”测试 LLM 如何诠释您的业务,已与跟踪排名同等重要。这需要系统地理解您的 AI 叙事。
# 测试 AI 品牌可见性的示例提示
1. "客户如何评价[品牌]?"
2. "人们为什么选择[品牌]?"
3. "[品牌] 有哪些不足?"
4. "[品牌] 哪些产品最受欢迎?"
5. "您如何将[品牌]与同类品牌比较?"
定期(最好每月)用这些提示在 ChatGPT、Claude、Perplexity 和 Google AI 概览中测试,追踪 AI 描述品牌的方式如何演变。将这些提示测试与评论数据仪表盘结合起来,理解评论多样性和新鲜度的提升是否带来了 AI 叙事的变化。这种结合能揭示您的评论策略是否真正影响了 AI 可见性。理解语境与定位同样重要;AI 可能经常提到您的品牌,但语境不符合您的定位,也可能偶尔提及但总是在高端语境中。系统化测试能揭示这些细节,帮助您判断评论策略是否以业务所需的方式提升了 AI 可见性。
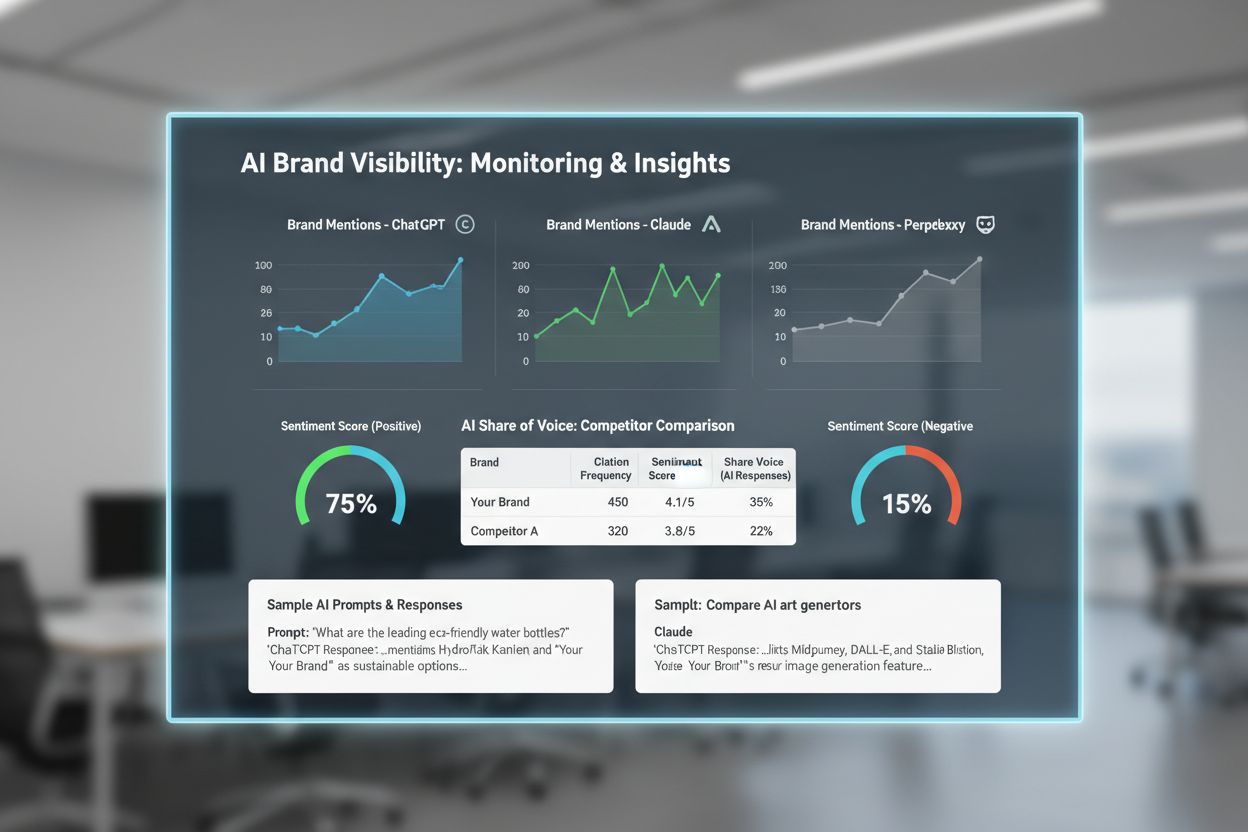
AI 可见性的转变,要求评论策略从以数量为导向的活动,根本性转向以质量为核心的可持续方法。与其追求一次性提升评论数量,不如将持续的真实反馈流入纳入日常客户触点,用以向 AI 系统传递产品持续相关性的信号。要将评论收集内嵌于客户日常互动中,而不是周期性地发起活动。表达多样性比通用好评更有价值;品牌应积极引导客户描述具体体验,而非使用模板化语言。真实性验证比数量膨胀更重要;200 条来自真实客户的验证评论,在 AI 评估中远胜于 500 条来路不明的评论。多平台分布防止评论成为信息孤岛;品牌应将评论分发到多个 AI 获取数据的平台,而不是全部集中在单一渠道。与整体数字公关战略集成,确保评论与媒体曝光、思想领导力、权威品牌提及等协同,形成强大的品牌叙事。若评论策略孤立运作,就会错失在 AI 监控的多渠道中强化品牌的机会。最有效的方法是将评论视为建设品牌权威和 AI 可见性的综合战略组成部分。
将评论视为战略情报的品牌,在 AI 时代能获得显著竞争优势。监控竞争对手在 AI 回应中的曝光,用同样的测试提示对比竞品,分析 AI 如何描述他们及您自己的品牌。这种竞争分析能揭示定位差距和差异化机会。识别评论覆盖的空白,分析哪些属性、场景和客户群体在您的评论中被忽略,而竞品却覆盖充分。如果竞品有大量关于耐用性的评论,而您的评论集中于外观,则发现了内容短板。用评论数据指导内容战略,识别评论中最常被提及的属性、使用场景和客户痛点,进而创作相关内容,为 AI 提供推荐所需的上下文。追踪评论情感与定位,了解客户如何看待您的品牌与竞品的差异,用这些洞察反哺产品与营销信息。对标行业领先者,分析品类头部品牌如何管理评论并构建 AI 可见性。这些竞争情报让评论从客户反馈工具转变为指导品牌定位和可见性战略的核心资产。
大型语言模型会学习来自公开文本,包括客户评论。真实的评论帮助 AI 系统学会如何描述品牌、产品与服务。当 LLM 遇到多样、具体的评论语言时,会将这些词语和短语与您的品牌相关联,从而让品牌更有可能在 AI 生成的回答中被引用。
语义表面积指的是您的品牌在 AI 训练数据中所占据的独特语言领域范围。当客户用不同表达方式描述同一产品特性时,他们为 AI 系统创造了多条语义路径。扩展后的表面积让品牌在更多不同的搜索和语境下被发现,而非仅限于狭窄、通用的描述。
LLM 关注的是整个数据集的模式,而不是单个评论。一家拥有 500 条真实评论(即使有些是负面的)的品牌,比只有 100 条可疑正面评论的品牌,更能向 AI 传递强烈信号。稳定持续的正面评论会盖过偶尔的负面,AI 系统也会把一致性和真实性视为真实反馈的标志。
AI 系统正变得越来越擅长过滤操控和虚假评论。已验证的购买、跨平台分布、自然的措辞变化和治理政策,都是 AI 识别真实性的信号。那些人类愿意相信的评论,正是 AI 在生成推荐和描述时优先考虑的评论。
要关注 AI 系统主动获取数据的平台,包括 G2、Capterra、TrustPilot、行业专属评论站点和您自己的网站。跨平台分布至关重要——分布在多个权威平台的评论,比集中在某一渠道的评论更能建立信任。不同 AI 系统可能偏好不同平台,因此多元化布局至关重要。
定期用具体提示在 ChatGPT、Claude、Perplexity 和 Google AI 概览中测试品牌表现。例如:'客户如何评价[品牌]?'、'如何将[品牌]与竞品比较?'。追踪 AI 如何描述品牌,并结合评论数据仪表盘,了解评论改进与 AI 叙事变化之间的关系。
对 AI 可见性而言,质量和真实性远比数量重要。LLM 更倾向于优先展示经过验证、多样且真实的评论,而不是大量通用或可疑的反馈。拥有 200 条真实客户验证评论的品牌,其 AI 可见性会胜过拥有 500 条来路不明评论的品牌。应关注持续、真实的评论流入,而非一味追求数量。
跨平台分布防止评论呈现孤岛或被操控的假象,这表明反馈是广泛且真实的。当评论出现在多个权威平台(如您的网站、G2、Capterra、TrustPilot、行业目录)时,AI 会将其视为真实客户满意度的有力证据。这种多平台曝光增强信任信号,提高 AI 有利引用的机率。
查看您的品牌在 ChatGPT、Perplexity 和 Google AI 概览等 AI 生成回答中的展现。实时追踪评论对 AI 引用和品牌提及的影响。
了解社交证明如何塑造AI推荐并影响品牌可见性。了解为何客户评论如今成为大模型关键训练数据,以及如何优化AI可见性。...

了解 Trustpilot 超过 3 亿条评论如何影响 AI 推荐、大语言模型训练和消费者信任。学习 AI 欺诈检测、优化策略以及基于评论的 AI 未来趋势。...
探索真实客户见证如何助力您的 AI 可见性,横跨 Google AI Overviews、ChatGPT 和 Perplexity。在 AI 时代,了解为什么真实客户之声比以往任何时候都更为重要。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.