AI 搜索 vs 传统搜索:为什么你的 SEO 策略需要更新
了解 AI 搜索如何重塑 SEO。学习 ChatGPT 等 AI 平台与传统谷歌搜索的关键区别,以及如何为两者优化你的内容。
2 分钟阅读
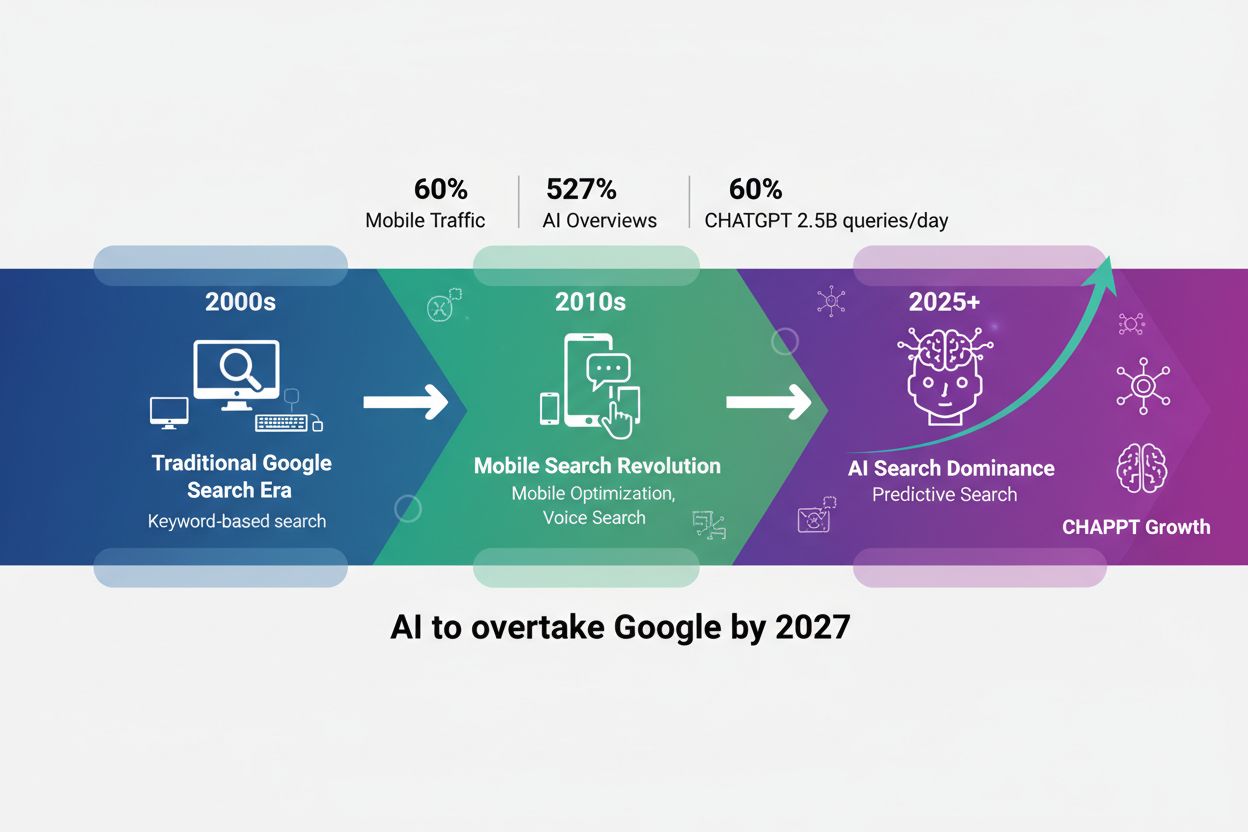
过去五年,用户搜索行为发生了根本性变化,从零散的关键词短语转向自然、对话式的查询。随着语音搜索技术普及、移动端优先的浏览习惯,以及谷歌BERT和MUM等算法的大幅进步(这些算法现在优先考虑语义理解而非精确关键词匹配),这一转变加速。用户不再搜索孤立词语,而是提出完整问题,反映他们自然的说话和思考方式。区别非常明显:
语音搜索的普及尤为重要,现在所有搜索中有50%是基于语音的,迫使搜索引擎和AI系统适应更长、更自然的语言模式。移动设备已成为大多数用户的主要搜索入口,在移动端使用对话式查询比输入关键词更顺畅。谷歌的算法更新已明确表明,理解用户意图和上下文远比关键词密度或精准短语匹配重要,这从根本上改变了内容的写作和结构方式,以保证在传统搜索和AI系统中持续可见。
对话式AI搜索与传统关键词搜索在查询处理、结果呈现和用户意图理解等方面有着根本性的不同。传统搜索引擎返回排名链接列表供用户浏览,而对话式AI系统则在上下文中分析查询,从多个来源检索相关信息,并用自然语言综合出完整答案。其技术架构有本质区别:传统搜索依赖关键词匹配和链接分析,而对话式AI则使用具备检索增强生成(RAG)的大型语言模型来理解语义意义并生成上下文响应。理解这些差异,对于希望在两种系统中都获得可见性的内容创作者极为重要,因为优化策略在许多关键点上截然不同。
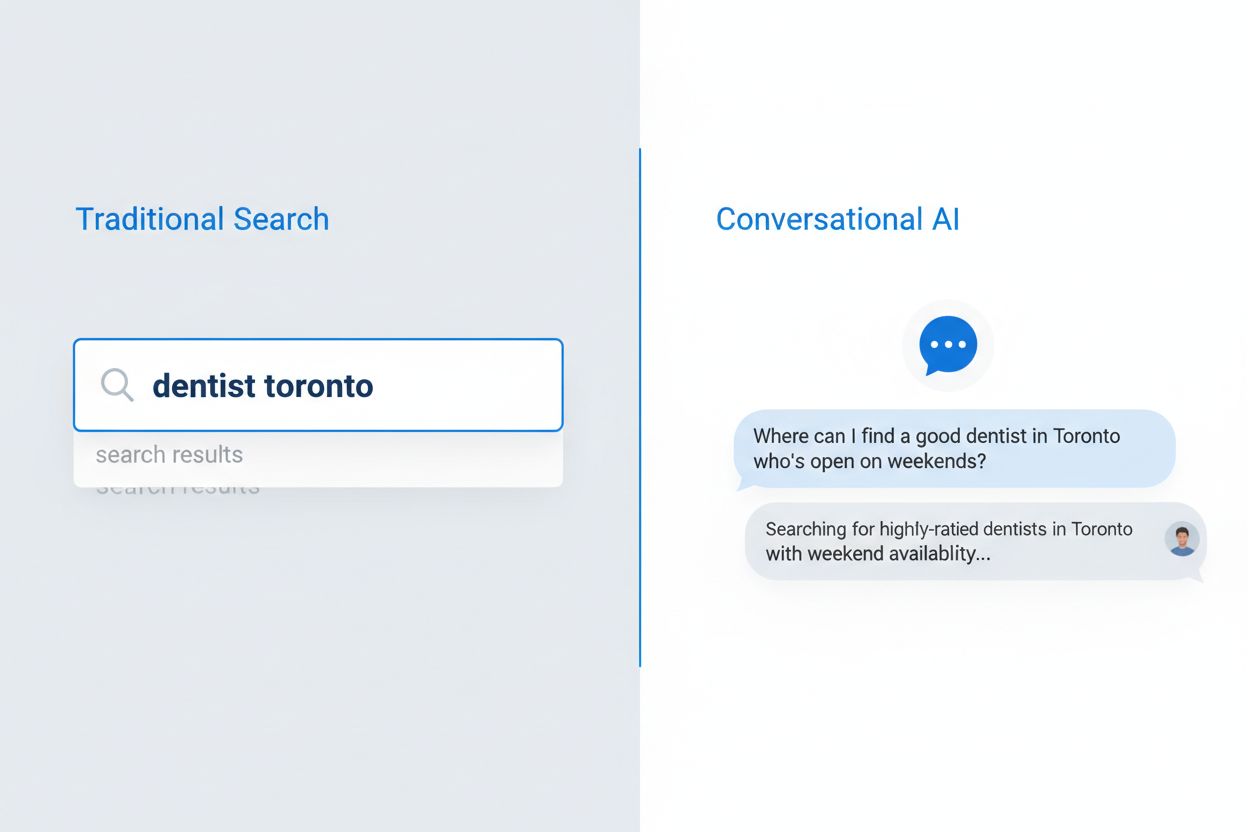
| 维度 | 传统搜索 | 对话式AI |
|---|---|---|
| 输入 | 简短关键词或短语(平均2-4词) | 完整对话式问题(平均8-15词) |
| 输出 | 用户可点击的排名链接列表 | 综合答案并带有来源引用 |
| 上下文 | 仅限查询词和用户位置 | 完整对话历史和用户偏好 |
| 用户意图 | 通过关键词和点击模式推断 | 通过自然语言明确理解 |
| 用户体验 | 需跳转外部网站 | 直接在界面提供答案 |
这一差异对内容策略有深远影响。传统搜索中,进入前10排名即为可见;在对话式AI中,成为被引用的来源才是关键。一些页面可能在关键词排名中表现优异,但若不满足AI系统对权威性、全面性和清晰度的标准,则无法获得引用。对话式AI系统有不同的内容评估标准,更重视对问题的直接回答、清晰的信息层级以及专业性,而不仅仅是关键词优化和外链数量。
大型语言模型通过“检索增强生成(RAG)”的复杂流程来选择在回答用户问题时要引用的内容,这一流程与传统搜索排名大不相同。当用户提出问题时,LLM首先从训练数据或索引来源中检索相关文档,然后根据多个标准评估,最后决定在回应中引用哪些来源。内容创作者必须理解以下几个关键优先因素:
权威性信号 —— LLM通过外链概况、域名历史和以往在传统搜索中的表现识别权威性,优先选择成熟、受信任的来源而非新建或鲜有引用的域名。
语义相关性 —— 内容需直接、高语义相关地回应用户问题,而不仅仅是关键词匹配;LLM能理解传统关键词匹配无法识别的意义和上下文。
内容结构与清晰度 —— 结构良好的内容、清晰的标题、直接的答案和逻辑顺序更易被选中,因为LLM可更容易地从结构化内容中提取信息。
新鲜度与时效性 —— 最近更新的内容权重更高,尤其是在信息需及时更新的话题上;即使历史权威内容,过时后也会被降权。
全面性 —— 多角度、数据支撑、专家观点齐全的内容比浅尝辄止的内容更可能被引用。
引用过程并非随机;LLM被训练以引用最能支撑其答案的来源,并且越来越多地向用户展示引用,这使得来源选择成为内容创作者的核心可见性指标。
内容结构已成为AI可见性最重要的因素之一,但许多内容创作者仍只为人工阅读优化,忽略AI系统提取信息的方式。LLM以层次结构解析内容,利用标题、分节和格式化来理解信息组织,并提取可引用内容。AI可读性的最优结构有明确标准:每节应为120-180字,便于LLM提取有意义的段落而不至过长;H2和H3应清晰体现主题层级;直接答案应在小节开头出现而非埋在正文中。
基于问题的标题和FAQ区块效果尤佳,因为它们与对话式AI系统理解用户查询的方式完全契合。当用户问“内容营销的最佳实践是什么?”,AI系统可立即匹配到标题为“内容营销的最佳实践是什么?”的区块,并准确提取内容。这种结构一致性极大提升了被引用概率。结构范例如下:
## 内容营销的最佳实践是什么?
### 首先明确目标受众
[120-180字的直接、可操作内容,针对该问题作答]
### 制定内容日历
[120-180字的直接、可操作内容,针对该问题作答]
### 衡量与优化表现
[120-180字的直接、可操作内容,针对该问题作答]
这种结构让LLM能迅速定位相关段落,完整提取观点并自信地引用具体部分。缺乏结构——如长篇大段、答案埋藏、层级不清——即使内容优质,也很难被AI系统选中引用。
权威性仍是AI可见性的关键因素,但其信号已超越传统SEO指标。LLM通过多渠道识别权威,内容创作者需多维度建立可信度,以最大化被引用概率。研究表明,拥有32,000+外链域名的网站引用率显著更高,域名信任分也与AI可见性强相关。但权威性不仅仅靠外链,还包括:
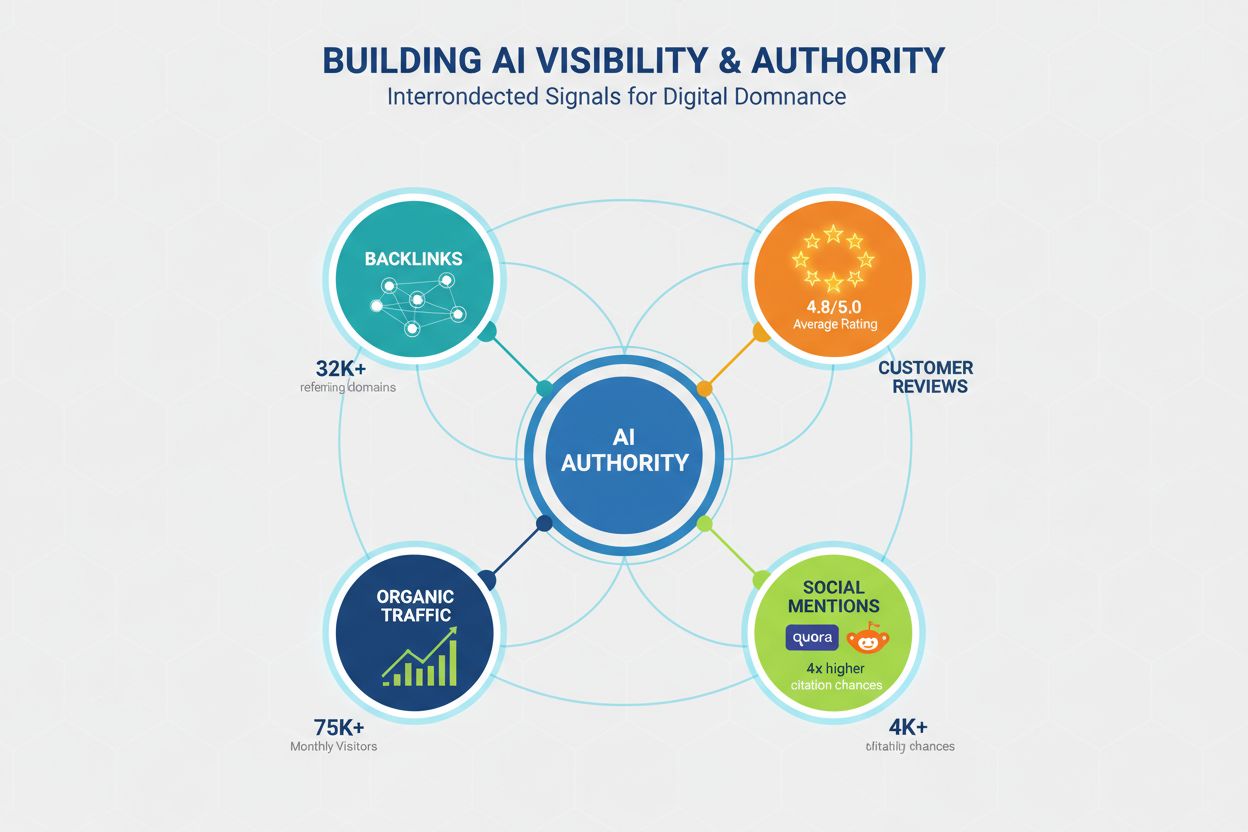
外链概况 —— 来自权威域名的优质外链表明专业性;拥有50+高质量外链的网站引用率是外链稀少网站的4.8倍。
社会背书与社区存在 —— 在Quora、Reddit、行业论坛等被提及,说明内容受真实用户信任和引用;积极参与社区可提升可信度。
评论平台与评分 —— 在Trustpilot、G2、Capterra等平台有正面评价,建立LLM可识别的信任信号;评分4.5星以上品牌引用率提升3.2倍。
首页流量与品牌认知 —— 主页的直接流量反映品牌知名度和信任度;LLM更看重知名品牌内容。
专家资质与署名 —— 由知名专家、有详细资历和简介的作者撰写的内容权重更高;作者专业性是独立于域名权威的另一个信号。
为AI可见性建立权威需长期策略,不仅包括技术优化,还需社区参与、评价管理和品牌建设。
内容深度是AI引用最强预测指标之一。研究显示,全面、详实的内容引用次数远高于浅层内容。竞争可见性的最低门槛约为1900字,而真正主导AI引用的内容通常超过2900字。这不仅是字数,更体现为信息深度、数据支持和观点广度。
数据证明内容深度的重要性:
专家引用影响 —— 包含4位及以上专家观点的内容平均获得4.1次引用,无专家内容仅2.4次。LLM将专家意见视为可信信号。
统计数据密度 —— 含有19条及以上统计数据的内容平均获得5.4次引用,数据稀少内容仅2.8次。LLM优先引用有据可依的结论。
全面覆盖 —— 涵盖8个以上子话题的内容平均获得5.1次引用,只覆盖3-4个子话题的内容仅3.2次。广度同样重要。
原创研究 —— 含有原创研究、调查或独家数据的内容平均获得6.2次引用,是AI可见性最高影响力的内容类型。
深度之所以重要,是因为LLM被训练为用户提供全面、来源可靠的答案,自然倾向于引用能在一个来源中整合多视角、数据和专家意见的内容。
内容新鲜度是AI可见性的重要但常被忽视的因素。研究显示,最近更新的内容引用量远高于过时内容。影响极其明显:过去三个月内更新内容平均获得6.0次引用,超过一年未更新的内容仅3.6次。这反映了LLM对信息时效性的偏好及其对内容准确性和相关性的判断。
面向AI可见性的内容应推行季度更新标准。这不一定要全部重写;有策略地补充新统计数据、刷新案例、修订过时建议并融入最新进展即可。对于技术、营销趋势、行业新闻等时效性话题,可能需每月更新以维持竞争力。更新流程包括:
内容若长期不变,而行业却在发展,AI可见性将逐步下降,即便曾经很权威,因为LLM已识别出过时信息对用户价值较低。
技术性能对AI可见性日益重要,因为LLM以及为其提供内容的系统会优先选择速度快、优化良好的网站。Google的核心网络指标(Core Web Vitals)与引用率强相关,说明LLM在选源时会考虑用户体验信号。性能影响显著:首屏内容绘制(FCP)小于0.4秒的页面平均获得6.7次引用,而大于2.5秒的仅2.1次。
AI可见性技术优化重点:
最大内容绘制(LCP) —— 目标:2.5秒以下。达标页面平均5.8次引用,慢页面仅2.9次。
累计布局偏移(CLS) —— 分数低于0.1;布局不稳定被判定为低质量,降低引用概率。
交互到下次绘制(INP) —— 响应时间200ms以下为佳;交互流畅页面平均5.2次引用,缓慢页面仅3.1次。
移动端响应 —— 移动优先索引,移动端体验不佳页面引用量减少40%。
语义化HTML结构 —— 正确的标题层级、语义标签和简洁代码有助于LLM解析内容,提升被引用概率。
技术性能不仅关乎用户体验,也是AI系统判断内容质量与可信度的直接信号。
基于问题的优化是让内容与对话式AI搜索模式高度契合的最直接方式,这对权威性不足的小型网站尤其有效。研究显示,对于月访问量不足5万的小型域名,基于问题的标题比传统关键词标题的影响高7倍,是新兴品牌极为有价值的策略。FAQ区块同样强大,规范实现可使热门查询引用概率翻倍。
基于问题与传统标题的差异明显:
差标题: “Top 10 Marketing Tools”
好标题: “小型企业有哪些顶级营销工具?”
差标题: “Content Marketing Strategy”
好标题: “小企业应如何制定内容营销策略?”
差标题: “Email Marketing Best Practices”
好标题: “电商企业最佳邮件营销实践有哪些?”
实用优化方法包括:
标题优化 —— 用内容回答的主要问题作为标题,采用自然语言而非堆砌关键词。
FAQ区块 —— 每页设置5-10条问答的FAQ区块,可使热门查询引用概率翻倍。
副标题对齐 —— H2、H3用常见问题模式表述,便于LLM将用户查询与您的内容匹配。
直接答案前置 —— 问题的直接答案放在小节开头,而非正文深处,便于LLM高效提取。
基于问题的优化不是投机取巧,而是让您的内容结构真正契合用户提问和AI系统理解的方式。
许多内容创作者把时间和资源浪费在对AI可见性几乎无效,甚至有害的优化手段上。理解常见误区可将精力集中在有效策略上。一个顽固的误区是LLMs.txt文件能显著提升可见性;研究显示,这类文件对引用率影响极小,有无LLMs.txt的域名平均引用(3.8 vs 4.1)几乎无差异。
应避免的常见误区:
仅靠FAQ schema标记无效 —— FAQ schema对传统搜索有用,但对AI可见性帮助有限;真正影响引用的是内容结构。带FAQ schema但结构差的内容平均3.6次引用,结构良好但无schema的内容为4.2次。
过度优化反而减少引用 —— 过度优化URL、标题和meta描述会降低被引用概率;高度优化内容平均2.8次引用,自然表达内容为5.9次。LLM能识别并惩罚明显的优化行为。
关键词堆砌无助LLM —— LLM能理解语义并识别关键词堆砌,优先引用自然语言内容。
仅靠外链不保证可见性 —— 权威重要,但内容质量与结构更关键;高权威但结构差的域名引用率低于结构优异的低权威域名。
无实质的长内容无效 —— 单纯为了字数堆砌内容会降低引用概率,LLM能识别并惩罚水分。
务必专注于真正的质量、清晰的结构和真实的专业性,而非优化套路。
了解对话式AI系统如何引用您的内容,是判断AI可见性、发现优化机会的关键,但多数内容创作者在这一核心指标上毫无可见性。AmICited.com提供专门平台,追踪ChatGPT、Perplexity、Google AI Overviews等对话式AI系统如何引用您的品牌和内容。这一监测弥补了传统SEO工具的空白,为内容创作者在全新搜索范式下提供了可见性数据。
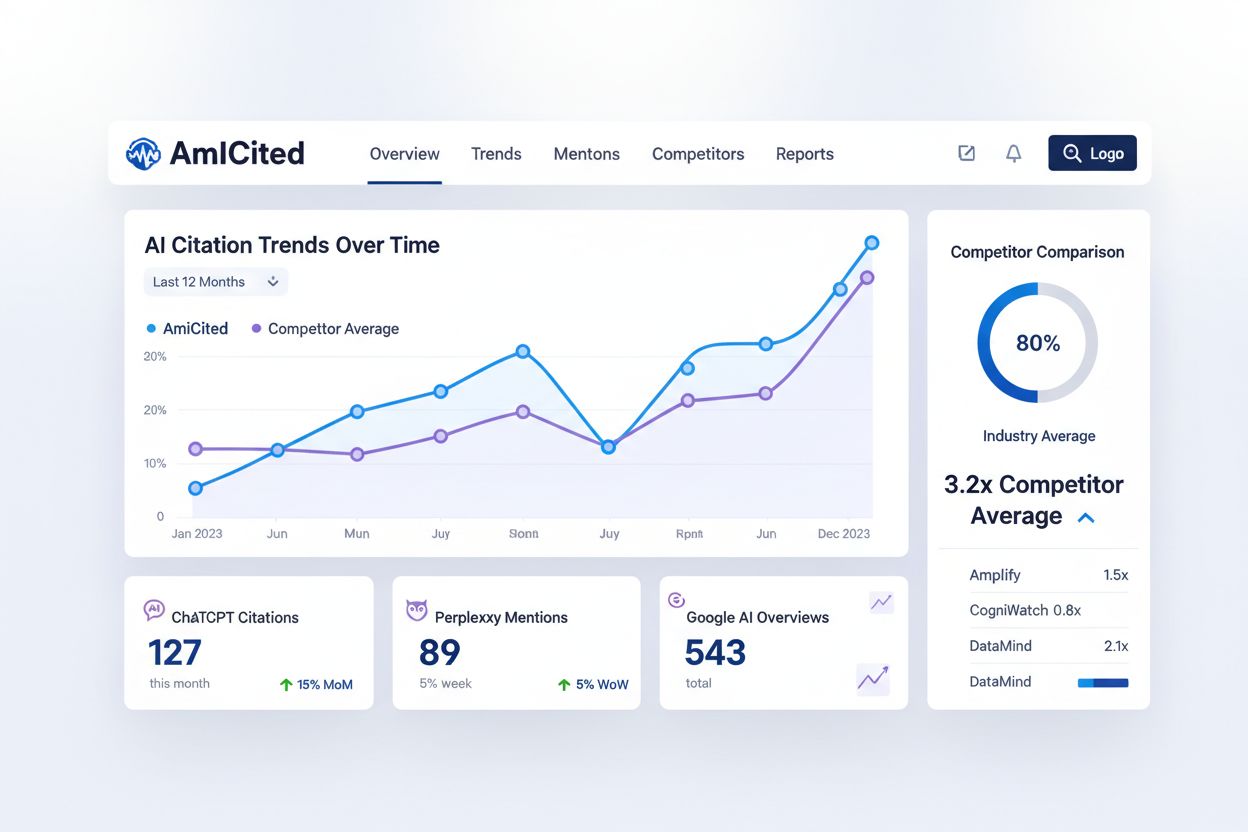
AmICited追踪传统SEO工具无法衡量的关键指标:
引用频率 —— 您的内容在不同AI系统中的引用次数,反映哪些内容受AI算法青睐,哪些主题需加强。
引用分布 —— 哪些页面与内容被引用最多,有助于发现您的内容强项和缺口。
竞争对手AI可见性 —— 对比您的AI引用率与竞争对手,了解在AI搜索格局中的竞争地位。
趋势追踪 —— 监测AI可见性随优化措施的变化,衡量内容策略调整的成效。
来源多样性 —— 追踪不同AI平台的引用情况,识别ChatGPT、Perplexity、Google AI Overviews间的差异,有针对性优化。
将AmICited纳入内容监测体系,为AI可见性优化提供了可靠数据依据,避免盲目试错。
推行基于问题的对话式AI内容策略需系统方法,既要优化现有内容,也要建立未来优化标准。整个执行流程应有条不紊、数据驱动,从内容审计到结构优化、权威建设,再到持续监测。以下八步框架为提升AI可见性提供了实操路线图:
审计现有内容 —— 分析前50个页面的结构、字数、标题层级和更新时间,识别结构良好与需优化的页面。
挖掘高价值问题关键词 —— 利用Answer the Public、Quora、Reddit等工具,研究行业相关的对话式查询,优先考虑高搜索量和商业意图的问题。
重构为问答区块 —— 将现有内容重组为基于问题的标题和直接答案,将传统关键词标题转化为与用户提问一致的问题标题。
实施标题层级 —— 确保所有内容有明确的H2/H3层级,清晰组织主题,将长段落分解为120-180字的小块并用小标题分隔。
新增FAQ区块 —— 给前20个页面设置5-10条直接问答的FAQ区块,优先添加搜索数据和用户反馈中常见问题。
通过外链建立权威 —— 制定面向行业优质域名的外链策略,重质不重量,优先获得权威来源的引用。
用AmICited监测 —— 配置品牌和重点内容的监测,建立基线指标,跟踪优化过程中的变化。
季度更新 —— 制定季度内容刷新计划,添加新统计数据、更新案例,保持内容新鲜,重点关注高流量和高引用内容。
该策略将您的内容从传统SEO优化转型为兼顾传统搜索和对话式AI的全面可见性方案。
基于问题的内容是围绕用户向对话式AI系统提出的自然语言问题结构化的材料。它不再针对“dentist Toronto”这样的关键词,而是针对完整的问题,例如“我在哪里可以找到周末营业并接受我保险的多伦多好牙医?”这种方式让内容更贴合人们自然的表达方式,也符合AI系统解读查询的方式。
传统搜索根据关键词匹配返回排名链接列表,而对话式AI会从多个来源综合直接答案。对话式AI理解上下文,保持对话历史,并以引用来源的方式提供单一综合答案。这一根本区别要求采用不同的内容优化策略。
大型语言模型会通过标题结构和分节方式分层解析内容,以理解信息的组织方式。每节120-180字、清晰的H2/H3层级、段首直接答案的最优结构,让AI系统更易提取并引用您的内容。结构差,即使内容质量高,被引用的可能性也会降低。
研究显示,约1900字是AI可见性竞争的最低门槛,真正全面的内容通常超过2900字。然而,深度比长度更重要——包含专家引用、统计数据和多视角的内容比堆砌字数的内容获得更多引用。
过去三个月内更新的内容平均获得6.0次引用,而过时内容只有3.6次。建议实行季度更新策略,补充新统计数据、更新案例,并融入最新发展。这会向AI系统传递“新鲜度”信号,保持引用竞争力。
可以。虽然大型域名在权威性上更有优势,但小型网站可通过更优的内容结构、基于问题的优化和社区参与来竞争。基于问题的标题对小型域名影响提升7倍,活跃于Quora和Reddit等社区能带来4倍更高的引用概率。
AmICited监测ChatGPT、Perplexity和Google AI Overviews如何引用您的品牌和内容。它提供引用模式可见性,识别内容缺口,追踪竞争对手AI可见性,并衡量您的优化成效——这些是传统SEO工具无法提供的指标。
不需要。Schema标记对传统搜索有帮助,但对AI可见性作用有限。带FAQ schema的内容平均获得3.6次引用,而结构良好但无schema的内容获得4.2次引用。应侧重实际内容结构和质量,而非仅依赖标记。
了解 AI 搜索如何重塑 SEO。学习 ChatGPT 等 AI 平台与传统谷歌搜索的关键区别,以及如何为两者优化你的内容。

了解对话式查询与传统关键词查询的不同之处。学习为什么AI搜索引擎更重视自然语言、用户意图和语境,而不是精确的关键词匹配。...
了解对话式查询与传统关键词的区别。学习为何 AI 搜索引擎偏好自然语言问题,以及这如何影响品牌在 AI 生成答案中的可见性。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.