

GEO(生成式引擎优化)到底是什么?这只是SEO的换皮,还是有真正的新东西?
社区讨论,深入解析生成式引擎优化(GEO)。真实从业者解释GEO与SEO的区别,并分享AI搜索可见性的策略。
2 分钟阅读
Discussion
GEO
+2
GEO实验,又称为geo lift测试或地理实验,是营销人员衡量活动真实影响方式的一次根本性变革。这些实验将地理区域分为测试组和对照组,使营销人员能够在不依赖个体级追踪的情况下,隔离营销干预的增量效果。在GDPR、CCPA等隐私法规日益严格、第三方Cookie逐步淘汰的时代,GEO实验为传统测量方法提供了一种隐私安全、统计稳健的替代方案。通过比较接受营销活动和未接受活动地区的结果,企业能够自信地回答:“如果我们没有开展这场活动,会发生什么?”这一方法对于希望深入理解增量效应并精准优化营销支出的品牌来说,已经成为必不可少的工具。
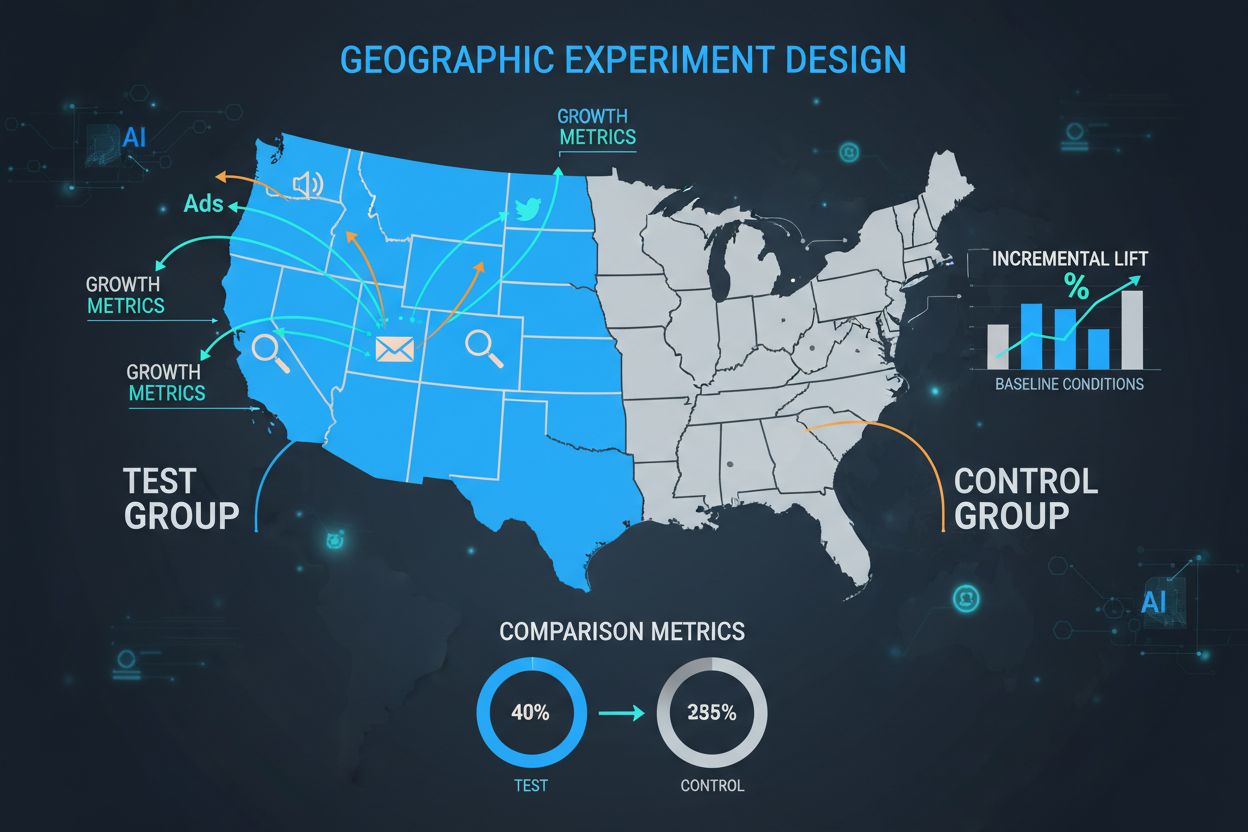
对照组是任何GEO实验的基石,是衡量所有处理效应的关键基线。对照组由未接受营销干预的地理区域组成,使营销人员能够观察在没有活动的情况下自然会发生什么。对照组的威力在于其能够控制外部因素——季节性、竞争对手活动、经济状况和市场趋势,否则这些因素会混淆实验结果。精心设计的对照组可帮助研究者隔离营销努力的真实因果影响,而不仅仅是相关性。对照区的选择需在多维度上进行细致匹配,包括人口特征、历史业绩指标、市场规模和消费者行为模式。对照组选择不当会导致结果方差大、置信区间宽,最终结论不可靠,甚至造成昂贵的营销预算误配。
| 方面 | 对照组 | 测试组 |
|---|---|---|
| 营销干预 | 无(业务如常) | 活动进行中 |
| 目的 | 建立基线 | 衡量影响 |
| 地理选择 | 与测试组匹配 | 重点关注 |
| 数据采集 | 相同指标 | 相同指标 |
| 样本规模 | 可比 | 可比 |
| 混杂变量 | 最小化 | 最小化 |
成功的GEO实验要求对影响结果和解释力的多种变量进行精细管理。理解自变量、因变量、控制变量和混杂变量的区别,是设计可付诸行动洞察的实验的基础。
自变量:这些是您主动操作和测试的营销策略,如广告投放金额、创意变体、渠道选择、定向参数或促销优惠。自变量是您希望衡量其影响的内容。
因变量:这些是您用来评估营销干预影响的结果,包括收入、转化、客户获取、品牌认知、网站流量,以及现代营销人员尤为关注的AI引用可见性和品牌在AI系统中的被提及情况。
控制变量:这些是您在测试组和对照组中保持一致的因素,以确保公平对比,如信息一致性、优惠结构、活动周期和媒体组合。
混杂变量:这些是可能独立于营销干预影响结果的外部意外因素,包括竞争对手活动、自然灾害、重大新闻事件、季节波动和经济变化。
测量变量:这些是您追踪的具体KPI和指标,包括增量提升、增量广告支出回报(iROAS)、增量获客成本(iCAC)及估算结果的置信区间等。
创建统计等价的测试组和对照组,是GEO实验设计中最关键、同时也是最具挑战性的部分之一。与拥有数百万个体用户的随机对照试验不同,GEO实验往往只涉及几十到几百个地理单元,随机分配往往无法实现真正的平衡。为应对这一难题,先进的匹配算法和优化技术应运而生。由计量经济学家开创、被Wayfair和Haus等公司推广的合成对照方法,利用历史数据识别并加权最匹配测试组特征的对照区。这些算法同时考虑人口规模、人口结构、历史销售模式、媒体消费和竞争格局等多维度,旨在创建可作为准确反事实参考的对照组。目标是最大程度减少测试组与对照组在所有前期指标上的差异,确保实验后观察到的差异可以自信地归因于营销干预,而不是原有差异。
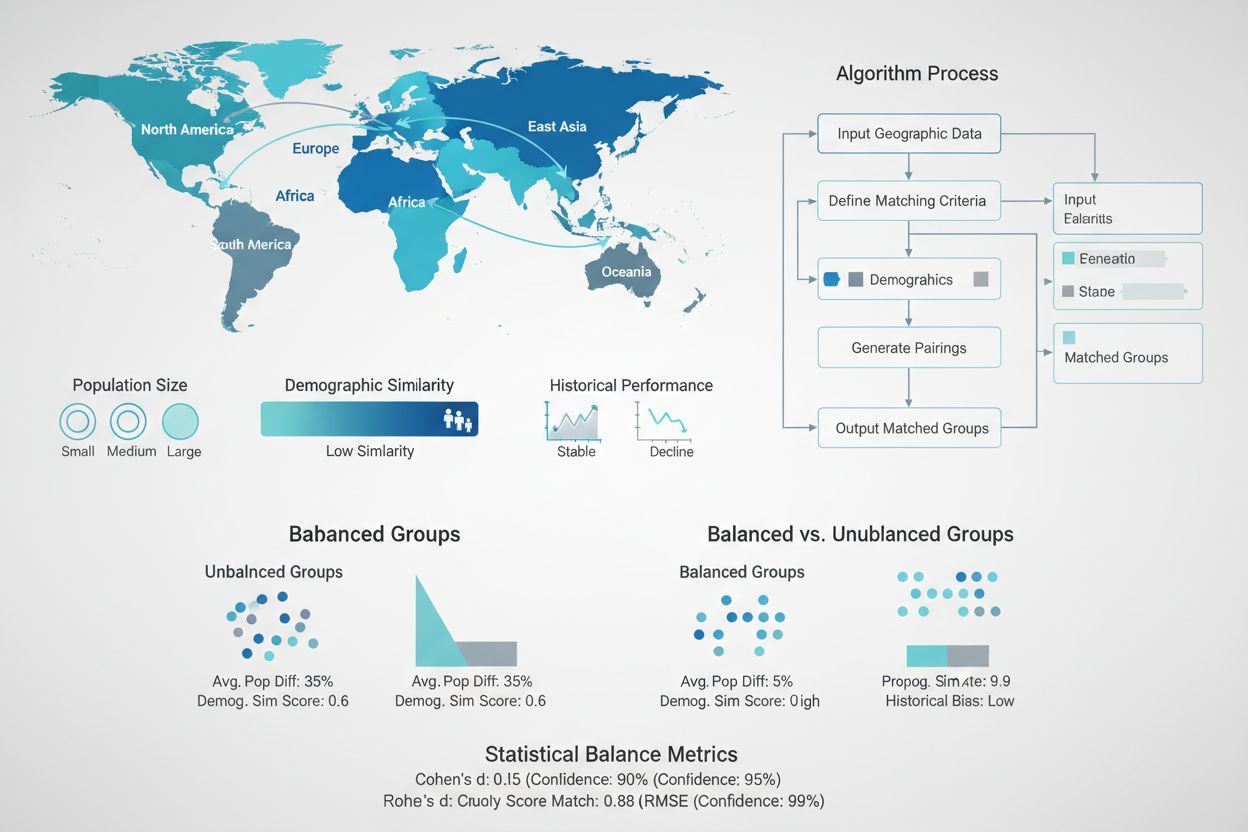
GEO实验的统计严谨性将其与随意观察或轶事证据区分开来。置信区间代表了真实处理效应很可能落入的范围,并以特定置信度(通常为95%)表达。置信区间越窄,结果的精确性和可信度越高;区间越宽,则表示存在较大不确定性。例如,若GEO实验显示提升10%,95%置信区间为±2%,则可以较有信心地认为真实效应在8%至12%之间。相反,若提升10%,置信区间为±8%(即2%至18%),则可操作性大大降低。置信区间的宽度取决于多个因素:样本量(地区数量)、结果变异性、测试时长以及预期效应的大小。最小可检测效应(MDE)计算有助于提前判断实验设计能否可靠检测到目标提升。功效分析则确保实验具有充分的统计功效(通常为80%或更高),以便在真实效应存在时能正确检测,同时控制I型错误(假阳性)和II型错误(假阴性)。
即使是有良好初衷的GEO实验,在未能避免常见陷阱时也可能产生误导性结果。理解这些陷阱并实施防护措施,是可靠测量的关键。
组间不平衡:测试组与对照组在关键前期指标上存在显著差异时,方差增大,难以检测真实效应。规避方法:使用匹配算法与合成对照方法,确保各组在重要维度上统计等价。
溢出效应:用户和媒体曝光不会严格遵守地理边界。人们会跨区出行,数字广告也可能触及非目标区域。规避方法:采用能最大限度减少交叉污染的地理边界,考虑通勤模式,并利用地理围栏技术实现精准控制。
测试周期不足:活动需要时间产生结果,客户旅程长度也有差异。测试期过短会错失延迟转化和季节波动。规避方法:至少运行4-6周实验,产品决策周期长则需更长时间,并考虑后处理观察期。
事后更改分析方案:在看到初步结果后修改分析计划会引入偏差并提升假阳性率。规避方法:在实验开始前就明确定义分析方法、KPI和成功标准。
忽视外部冲击:自然灾害、竞争行为、重大新闻和经济波动可能导致结果失效。规避方法:全程监控混杂事件,必要时延长或重跑实验。
样本量不足:地区数量过少会导致统计功效不足、置信区间过宽。规避方法:提前进行功效分析,确定实现预期效应所需的最小地区数。
增量代表了营销的真实因果影响——即实际发生与未干预情况下的差异。提升则是这一增量的量化指标,即测试组与对照组关键指标的差值。如果测试区收入为1,000,000美元,对照区为900,000美元,则绝对提升为$100,000。百分比提升为11.1%($100,000 / $900,000)。但原始提升数据未计入营销花费。增量ROAS(iROAS)用增量收入除以增量投放,表示每新增一美元投入带来多少回报。如果测试区为此多花了$50,000营销费,则iROAS为2.0倍。同理,增量CAC(iCAC)衡量获取每个新增客户的成本,对于评估获客渠道效率至关重要。这些指标在与品牌可见性测量结合时价值更大——不仅关注销售提升,还要衡量营销对GPTs、Perplexity和Google AI Overviews中AI系统引用和品牌提及的影响。
随着AI系统成为消费者的主要发现渠道,衡量营销对品牌在AI回复中可见性的影响变得至关重要。GEO实验为测试不同内容策略对AI引用频率与准确性的影响提供了严谨框架。通过在部分地区实施针对AI可见性优化的内容——如结构化数据优化、品牌信息更清晰、内容格式优化——而对照区保持基线做法,营销人员可以量化AI提及的增量影响。这对于理解AI系统在引用来源时偏好的内容格式、信息结构和表述方式尤为有用。AmICited通过追踪品牌在不同地理区域和时间段的AI生成回复中的出现频率,为可见性提升测量提供数据基础。可见性提升的增量效果还可与业务结果关联:AI引用频率更高的区域,是否表现出更高的网站流量、品牌搜索或转化?这种连接将AI可见性从虚荣指标转变为可量化的业务驱动因素,使预算能够自信地投向以可见性为核心的举措。
除了简单的差异中差异(DiD)分析外,更多先进的统计方法已被用于提升GEO实验的准确性与可靠性。合成对照法通过构建加权组合,对照区在前期轨迹上与测试区最匹配,从而生成比单一区域更精确的反事实参考。这在拥有大量潜在对照区并希望利用全部信息时尤为强大。贝叶斯结构时间序列(BSTS)模型(如Google的CausalImpact包)则在合成对照基础上引入不确定性量化和概率预测。BSTS模型在前期学习测试区与对照区的历史关系,然后预测若无干预测试区会呈现怎样的轨迹。实际值与预测值的差即为处理效应估计,并通过可信区间量化不确定性。差异中差异(DiD)分析则比较实验前后测试组与对照组的变化,有效去除时间不变差异。各方法各有优劣:合成对照需大量对照单元但不假设平行趋势;BSTS可捕捉复杂时间动态但需谨慎建模;DiD简单直观但对平行趋势假设敏感。Lifesight、Haus等现代平台已将这些方法自动化,让营销人员无需深厚统计背景也能享受先进分析的红利。
领先企业通过GEO实验取得了卓越成果。Wayfair开发的整数优化方案可同时在多个KPI上精准平衡地理单元分组,实现更敏感的实验和更小的保留比例。Polar Analytics对数百个geo测试的分析显示,合成对照法的结果比简单的匹配市场方法精度提升约4倍,置信区间更窄,决策更有信心。Haus推出了专为户外和零售活动设计的固定geo测试,解决了无法随机分配地区但又需衡量预设地理推广影响的问题。他们与Jones Road Beauty的案例展示了固定geo测试如何准确测量特定市场户外广告活动的增量效果。Lifesight为零售、快消、DTC等行业大牌提供的自动化geo测试平台,将测试周期从8-12周缩短至4-6周,并通过先进匹配算法提升了精度。这些案例一致证明,精心设计与执行的GEO实验能带来意想不到的洞察:那些被认为高效的渠道往往增量有限,而低投入渠道常展现出强劲回报,带来大量预算重分配机会。
成功运行GEO实验需在多个阶段系统推进:
明确目标与KPI:定义你要衡量的内容(收入、转化、品牌认知、AI引用)并设定具体可衡量目标,确保与业务优先事项和预期效应一致。
选择与匹配地理区域:选取能代表目标市场且数据量充足的区域。利用匹配算法找到历史指标与测试区高度相似的对照区。
确保数据就绪:确保能在整个测试周期准确追踪所有KPI。进行数据审计,保证质量、完整性和一致性。
设计实验参数:确定测试时长(通常至少4-6周),精确定义营销干预,实验前记录所有假设与成功标准。
同步执行活动:在测试区同步启动活动,对照区维持基线状态。各团队协调,保障执行一致。
全程监测:每日追踪关键指标,及时发现异常模式、外部冲击或执行问题。
数据收集与分析:汇总所有区域数据,按预设分析方法计算提升、置信区间及次级指标。
谨慎解释结果:不仅看统计显著性,更关注实际意义。结合置信区间宽度、效应大小与业务影响得出结论。
文档与分享发现:撰写包含方法、结果、经验的全面报告,与相关方分享以指导未来策略。
规划下一轮实验:用经验反哺下一轮测试,打造持续的实验和优化文化。
GEO实验生态已发生巨大变化,专业平台大大简化了复杂流程。Haus以GeoLift支持标准的随机geo测试,并有适合预设地理推广的Fixed Geo Tests,尤其擅长全渠道测量。Lifesight提供从设计到分析全自动化流程,拥有专有匹配算法和合成对照方法,缩短测试周期同时提升精度。Polar Analytics专注于增量性测试,强调因果提升测量与置信区间准确性。Paramark提供结合geo实验校准的营销组合建模,帮助品牌用真实测试结果校准MMM预测。评估平台时应关注:自动区域匹配与平衡、支持数字与线下渠道、实时监控与早停能力、方法透明与置信区间报告、与现有数据基础设施的集成。AmICited为这些平台提供可见性测量层——追踪品牌在AI生成回复中的出现频率,实现以可见性为核心的营销举措增量效果的测量。
成功的GEO实验需遵循经验证的最佳实践,以最大化可靠性和可操作性:
从明确假设出发:实验前先定义具体、可检验的假设,避免“撒网式”同时测试多个变量却无清晰预测。
投入资源进行分组匹配:前期确保测试组与对照组真正可比。匹配不佳会破坏所有后续分析,浪费资源。
实验周期要足够长:不要因早期“好看”结果而提前终止。过早结束会引入偏差并提升假阳性率,务必坚持全周期。
监控混杂因素:全程关注外部事件、竞争行为和市场动态。遇重大干扰要准备延长或重跑实验。
文档详尽:记录实验设计、执行、分析与结果细节,有助于经验沉淀、复现和组织知识积累。
打造测试文化:由一次性试验转向体系化的实验计划。每次实验都为下一步提供经验,形成优化的良性循环。
与业务结果挂钩:确保实验测量能直接影响业务目标,避免只关注无法转化为收入或战略目标的虚荣指标。
GEO实验在地理/区域层面测试,以衡量无法在单个用户层面测试的营销活动的增量效果,而A/B测试则对单个用户进行随机分组以实现数字优化。GEO实验更适合线下媒体、漏斗上游活动以及衡量真实因果影响,而A/B测试则擅长快速优化数字体验。
通常至少4-6周,具体取决于您的转化周期和季节性。测试时间越长,结果越可靠,但成本也更高。测试周期应足够长,以涵盖完整的客户旅程,并考虑延迟转化效应。
没有固定的最小值,但需要足够的数据量以获得统计学显著性。通常,您需要足够的地区和交易量,以便在具有足够统计功效(通常为80%或更高)的情况下检测到预期效应。较小的市场需要更长的测试周期。
使用能够最小化交叉污染的地理边界,考虑通勤模式和媒体覆盖重叠,采用地理围栏技术进行精确控制,并选择地理隔离的地区。溢出效应是指用户或媒体曝光在测试区和对照区之间交叉,导致结果被稀释。
标准为95%置信度(p < 0.05),意味着您可以有95%的把握认为观察到的效应是真实存在的而非偶然。然而,请结合您的业务场景——权衡误报与漏报的成本——来确定置信阈值。
可以,通过调研、品牌提升研究和AI引用追踪。您可以衡量营销对品牌认知度、好感度的影响,尤其是品牌在AI生成回复中在不同地区出现的频率,从而衡量可见性的增量提升。
自然灾害、竞争对手活动、重大新闻事件和经济变动会引入混杂变量,导致结果失效。整个测试期间需监控这些因素,并准备在发生重大干扰时延长测试周期或重新运行实验。
GEO实验通常能通过避免在无效渠道上的浪费支出而自我回本,并支持将预算自信地重新分配至高效渠道。它们提供了提升后续测量和决策质量的事实依据,从MMM校准到渠道优化均受益。
社区讨论,深入解析生成式引擎优化(GEO)。真实从业者解释GEO与SEO的区别,并分享AI搜索可见性的策略。
通过叠加多种优化方法掌握组合GEO策略。学习如何同时针对多个AI平台进行优化,最大化在ChatGPT、Gemini和Perplexity等平台的可见性。...
了解如何通过AI可见性分数、归因频率、互动率和地域表现洞察来衡量GEO策略有效性。发现测试生成式引擎优化成功的必备工具与最佳实践。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.