
哪些 Schema 标记有助于 AI 搜索?2025 年完整指南
了解哪些 schema 标记类型能够提升你在 ChatGPT、Perplexity、Gemini 等 AI 搜索引擎中的可见性。掌握适用于 AI 答案生成器的 JSON-LD 实施策略。...
2 分钟阅读

了解哪些 schema 类型对 AI 可见性最重要。发现 LLM 如何解释结构化数据,并实施 schema 标记策略,让你的品牌在 AI 答案中获得引用。
多年来,schema 标记主要用于获取丰富结果——那些在传统搜索结果中吸引眼球的星级评分、产品卡片和 FAQ 折叠栏。如今,这一套路正逐渐过时。大型语言模型和 AI 答案引擎以根本不同的方式解释 schema 标记,它们并非为了视觉增强,而是用来构建知识图谱和理解大规模实体关系。如今大约有 4500 万个网站(占所有注册域名的 12.4%)实施了某种形式的 schema.org 标记,AI 系统由此获得了前所未有的结构化数据资源。转变极为深刻:schema 标记如今影响着你的品牌是否会被 AI 生成答案引用,模型如何准确表达你的产品与服务,以及你的内容在 AI 优先搜索环境中能否成为可信来源。
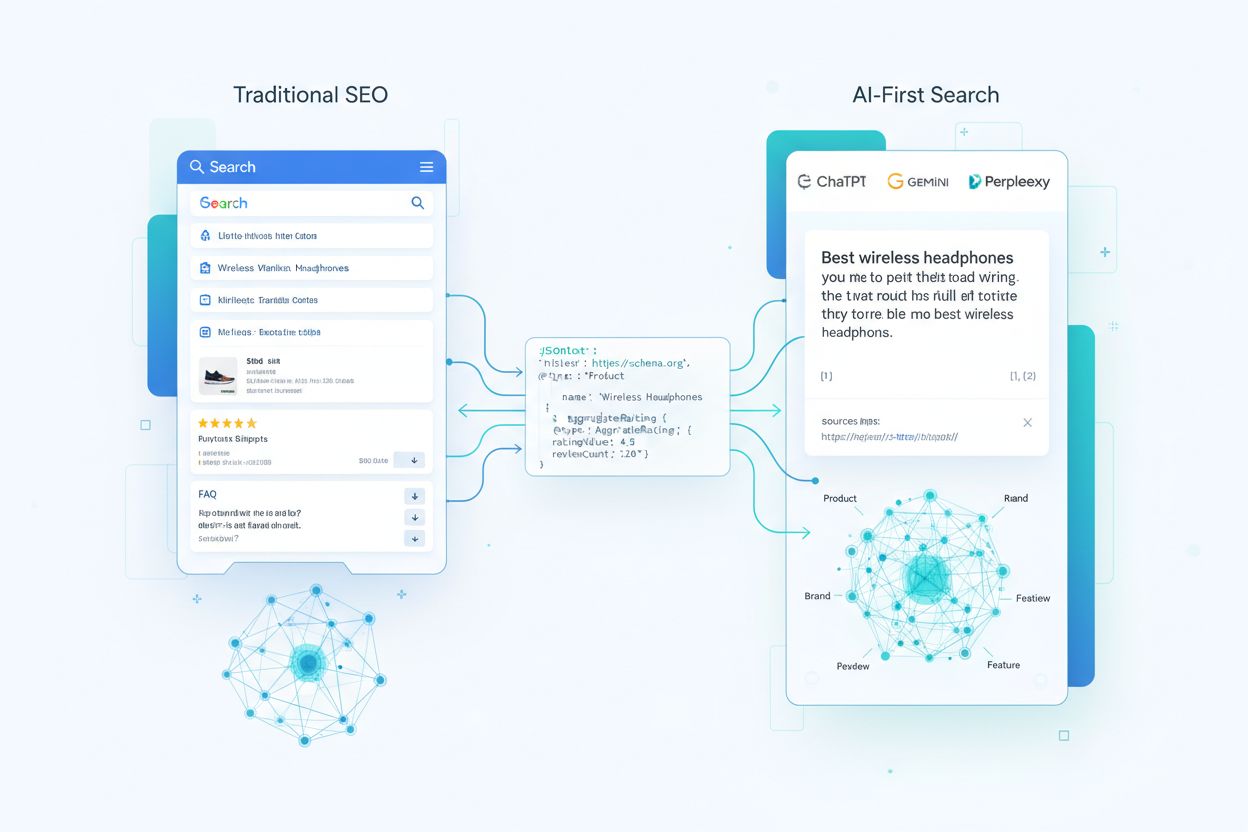
理解 AI 系统如何利用 schema 标记,需要追踪你的结构化数据从最初被爬取到 LLM 生成答案的整个旅程。当爬虫访问你的页面时,会提取 JSON-LD、microdata 或 RDFa 区块,并将其标准化,与非结构化文本和媒体共同编入索引。这些结构化数据成为 Web 级知识图谱的一部分,实体通过关系相互连接,并被赋予嵌入用于语义搜索。在检索增强生成(RAG)系统中,schema 可直接被融合进填充向量索引的内容块中——一个块可能同时包含产品描述和其 JSON-LD 标记,为模型同时提供叙述上下文和结构化键值属性。不同的 LLM 架构解析 schema 的方式不同:有的在现有搜索索引和知识图谱之上叠加模型,有的则采用多源检索管道,结构化与非结构化内容并用。关键洞见在于,优质 schema 实际上与模型形成了一份“契约”,以高度结构化的形式声明了你认为页面上的哪些事实是权威且可信的。
| 架构类型 | Schema 用法 | 引用影响 | 关键属性 |
|---|---|---|---|
| 传统搜索 + LLM 层 | 增强现有知识图谱 | 高——模型引用结构良好的来源 | Organization, Product, Article |
| 检索增强生成 | 融入向量块 | 中高——schema 有助于精准 | 所有类型及详细属性 |
| 多源答案引擎 | 用于实体解析 | 中——与其他信号竞争 | Person, LocalBusiness, Service |
| 会话式 AI | 支持上下文理解 | 不定——取决于训练数据 | FAQPage, HowTo, BlogPosting |
并非所有 schema 类型在 AI 时代都同等重要。Organization 标记是你整个实体图的锚点,帮助模型理解你的品牌身份、权威性和关系。Product schema 对电商和零售至关重要,使 AI 能跨来源比较功能、价格和评分。Article 和 BlogPosting 标记帮助模型识别适合解释性查询和思想领导力的长内容。Person schema 对于在 AI 答案中确立作者可信度和专业归属至关重要。FAQPage 标记直接对应了 AI 助手设计来回答的会话式问题。对于 SaaS 和 B2B 企业,SoftwareApplication 和 Service 类型同样重要,常出现在“X 最佳工具”比较和功能评估中。地方商户和医疗服务提供商则需关注 LocalBusiness 和 MedicalOrganization,以体现地理精准和监管合规。但真正的差异化并非只在类型选择,而在于你对高级属性的应用——页面间的一致性、清晰的实体标识符,以及明确的关系映射。
基础属性如 name、description 和 URL 已成为标配;谷歌首页排名的页面中已有 72.6% 使用了某种 schema 标记。能带来 AI 可见性真正差异化的,是那些帮助模型解析实体、理解关系和消除歧义的“连接组织”。以下是最重要的高级属性:
这些属性将 schema 从简单数据容器转变为模型可自信导航的语义地图。当你用 sameAs 将组织链接到 Wikipedia 页面时,不只是添加元数据,更是在向模型声明“这就是关于我们的权威信息源”。用 additionalProperty 编码产品规格或服务特性时,则为 AI 提供了组装对比或推荐时所需的确切属性。
多数组织将 schema 标记视为一次性任务,但在 AI 驱动搜索中要获得竞争优势,需将其当作持续的数据治理学科。一个有用的框架是四级成熟度模型,帮助团队明确现状和发展方向:
第1级——基础丰富结果 schema,仅在部分模板上做最小标记,主要为获取星级、产品卡或 FAQ 摘要。治理松散、一致性低,目标是视觉增强而非语义清晰。
第2级——以实体为中心的覆盖,在关键模板上标准化 Organization、Product、Article 和 Person 标记,引入一致的 @id 值,并添加基础 sameAs 链接防止实体混淆。
第3级——知识图谱集成 schema,将 schema ID 与内部数据模型(CMS、PIM、CRM)对齐,大量使用 about/mentions/additionalType 属性,并编码跨页面关系,使模型理解内容节点之间及与外部实体的关联。
第4级——LLM 优化与 RAG 对齐 schema,专为会话式查询和 AI 摘要格式进行结构化,schema 与内部 RAG 流程对齐,测量和迭代成为核心实践。
目前,大多数品牌停留在 1–2 级,这意味着基础应用已成为“卫生因素”而非竞争优势。进入 3–4 级,schema LLM 优化才会形成持久护城河,因为模型能在多种查询和场景下稳定解析你的实体。
不同行业有各自的实体、风险和用户意图,高级 schema 用法不能一刀切。核心原则——实体清晰、关系建模及与页面内容一致——始终不变,但你所强调的 schema 类型和属性应反映用户在你行业内真实的搜索方式。
电商与零售,核心实体是 Products、Offers、Reviews 和你的 Organization。每个高意图产品页都应暴露细致的 Product 标记,包括标识符(SKU、GTIN)、品牌、型号、尺寸、材质,以及通过 additionalProperty 表达的差异化属性。配合 Offers 编码定价和库存信息,以及 AggregateRating 结构让模型理解社会认同。更进一步,思考用户如何提问:“防水吗?”“有保修吗?”“退货政策如何?”将这些答案以 FAQPage 标记编码在同一 URL,并确保 Product 属性与 FAQ 内容同步,使答案引擎更易引用正确页面。
SaaS 和 B2B 服务,实体更抽象,但可很好地映射到 SoftwareApplication、Service 和 Organization schema。每个核心产品或服务,定义 SoftwareApplication 或 Service 实体,明确类别、支持平台、集成、定价模型,并用 additionalProperty 列举经常出现在“最佳工具”对比中的功能。通过 provider 或 offers 关系与 Organization 连接,并用 Person 标记关联专家团队成员。内容侧,Article、BlogPosting、FAQPage 和 HowTo 结构有助于 LLM 找出你在评估性和教育性查询中的优质资产。
本地、医疗及受监管行业,LocalBusiness、MedicalOrganization 及相关 MedicalEntity 类型可编码地址、服务区域、专科、接受保险类型和营业时间,比自由文本更少歧义。当 AI 助手被问到“找一个接受我保险的儿科心脏科医生”或“推荐现在营业的急诊”,这些属性尤为重要。在这些领域,尤其要注意 schema 不要夸大或暴露敏感信息——只标记你愿意在多种场景下被复用的事实,并确保合规和法务团队审核任何医疗或监管属性。
LLM 行为本质上是随机的,因此单靠 schema 变更无法获得像素级归因。但你可以搭建一个轻量级监控系统,定期针对定义好的查询集合采样 AI 答案。跟踪被提及的实体、被引用的 URL、品牌描述,以及核心事实(定价、功能、合规细节)在 ChatGPT、Gemini、Perplexity 和 Bing Copilot 等平台上的准确性。当出现问题——虚构功能、漏提或引用聚合页而非主页面时——首先检查是否存在信号冲突或不完整。页面文案是否与 schema 冲突?sameAs 链接是否缺失或指向过时资料?是否有多个页面自称是同一实体的权威来源?从战略角度,至少每季度进行一次 schema 审查,以适应新产品、内容集群及 AI 答案引擎展现方式的变化。
有些模式会持续削弱 schema 对 AI 的效果。标记页面上不可见的内容会造成信任赤字——模型会逐步降低 schema 与可见内容不符来源的权重。滥用过于通用的类型(如全部标记为“Thing”或“CreativeWork”)毫无语义信号,模型需要精确类型才能理解上下文。大量页面复制粘贴模板 schema 而不调整实体细节是最常见失误之一——如果每个产品页都有相同的 Organization 标记,或每篇文章都写同一个作者,模型会难以消歧,甚至将内容降权为低信号。页面间实体标识符不一致(同一组织或产品用不同 @id)会破坏实体解析,令相关内容被模型当作不同实体。缺少 sameAs 指向权威档案会让模型更容易将你的品牌与同名者混淆。最后,schema 与页面文案信息冲突会被视为不可靠;如果 schema 标注“有货”而页面显示“缺货”,模型会对双方都失去信任。
schema 标记正从 SEO 的表面手段转变为 AI 优先搜索的基础技术。连贯的 schema 标记——通过 sameAs、about 和 mentions 明确实体间关系——能构建 AI 可自信导航的知识图谱。竞争优势不再属于那些问“我们要做哪些最少 schema 才能出丰富结果?”的人,而是属于那些问“怎样的结构化表达能让我们的内容对机器毫无歧义,即使不在 SERP 中?”的人。这一转变推动组织采用更完善、互联、以实体为中心的 schema 模式。随着 AI 驱动搜索成为主流发现渠道,schema LLM 优化从技术好奇演化为核心 SEO 能力。那些实现从基础丰富结果 schema 到知识图谱集成和 LLM 优化模式跃迁的组织,将在 AI 驱动发现中构筑持久护城河,确保品牌被权威引用、内容成为可信来源。
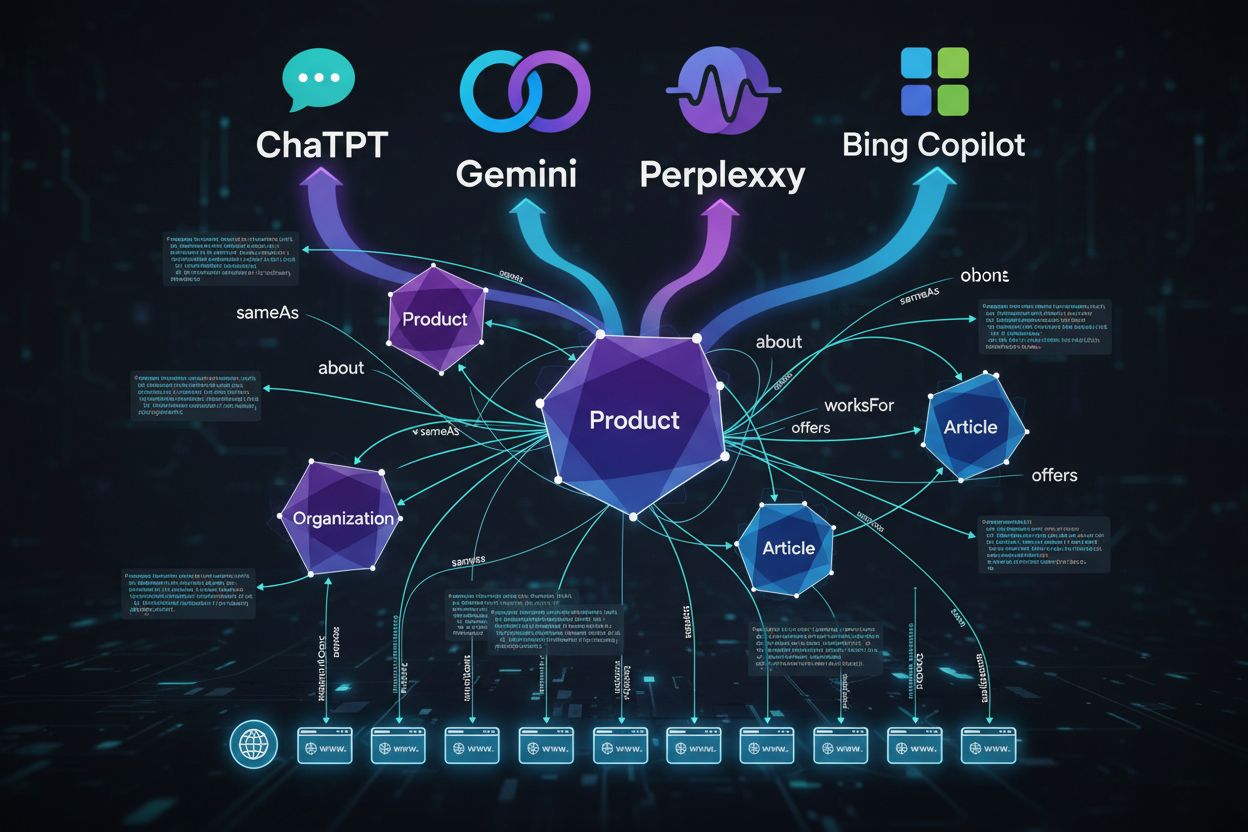
传统 schema 侧重于丰富结果(星级、摘要)。对于 AI,schema 重点在于实体清晰度、关系和知识图谱。AI 系统利用 schema 来在语义层面理解你的内容,而不仅仅是视觉增强。
Organization、Product、Article、Person 和 FAQPage 是基础类型。SaaS 行业应增加 SoftwareApplication 和 Service。地方/医疗行业应增加 LocalBusiness 和 MedicalOrganization。重要性因行业和用户意图而异。
不需要。先从 Organization 和你最有价值的页面(产品、服务、关键文章)开始。根据你的商业模式以及 AI 答案最有价值的位置,逐步扩展覆盖范围。
schema 变更可在数周内影响 AI 引用,但这种关系是概率性的。建议按季度复盘,并在多个 AI 平台持续监测以跟踪影响。
sameAs 将你的实体链接到权威档案(Wikipedia、LinkedIn),防止与同名实体混淆。about/mentions 则明确你的页面真正聚焦的内容,有助于模型理解细微差别和上下文。
不能。schema 最好与高质量、结构良好的页面内容结合使用。模型需要结构化数据和叙述性上下文,才能自信地引用你的页面。
在各平台(ChatGPT、Gemini、Perplexity、Bing)监控你的目标查询的 AI 答案。跟踪实体提及、URL 引用、事实准确性和品牌描述。关注数周/月的趋势。
JSON-LD 是大多数场景的推荐格式。它易于实现和维护,不会干扰 HTML。Microdata 和 RDFa 在现代实现中较少使用。
跟踪 AI 系统在 ChatGPT、Gemini、Perplexity 和 Google AI Overviews 中如何引用你的品牌。洞察哪些 schema 类型正在驱动可见性。
了解哪些 schema 标记类型能够提升你在 ChatGPT、Perplexity、Gemini 等 AI 搜索引擎中的可见性。掌握适用于 AI 答案生成器的 JSON-LD 实施策略。...
了解 HowTo schema 如何优化分步内容以便 AI 提取。实施结构化数据以提升在 LLM 响应和 AI 概览中的可见性。
了解组织 schema 如何帮助 AI 系统理解并引用您的品牌。品牌实体标记的完整指南,提升 LLM 可见性与 AI 引用。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.