

OpenAI 与 Reddit 合作伙伴关系是什么?
了解 OpenAI 与 Reddit 的合作伙伴关系,其运作方式、为双方带来的益处,以及对 ChatGPT 和 Reddit 用户的影响。
2 分钟阅读
Stack Overflow 拥有 5000 万个问题与答案,已成为大型语言模型开发的基石。包括 OpenAI、Google 和 Meta 在内的主流 AI 公司已将 Stack Overflow 数据纳入其训练数据集,因为开发者的知识代表了互联网上最高质量、经过同行评审的技术内容。开发先进 AI 系统需要数亿美元投入,其中很大一部分用于获取和处理训练数据。历史上,AI 公司是免费抓取这些数据的,但 Stack Overflow CEO Prashanth Chandrasekar 于 2023 年宣布,平台将开始向大型 AI 开发者收取内容访问费用,认可社区贡献的知识应获得回报。这一转变反映了行业更广泛的趋势:拥有有价值数据的平台正要求从其内容获利的公司支付合理报酬。
Stack Overflow 内容遵循 Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA) 许可,法律要求使用内容者必须对原作者进行署名。对于 Stack Overflow 来说,这一授权框架不可协商,因为平台认为归属是开发者信任 AI 生成内容的基础。当 AI 公司在训练模型时未正确署名 Stack Overflow 内容,实际上就违反了 Creative Commons 许可,因此 Stack Overflow 现要求所有 API 合作伙伴在合同中加入归属条款。这一点的重要性不可低估:根据 2024 年 Stack Overflow 开发者调查,65% 的开发者将缺失或错误归属列为 AI 工具的首要伦理担忧。
| 方面 | 要求 | 影响 |
|---|---|---|
| 许可类型 | CC BY-SA 4.0 | 必须署名 |
| 开发者信任 | 72% 支持度 | 采用的关键 |
| AI 合规性 | RAG 实现 | 确保来源规范 |
| 引用率 | 65% 担忧 | 首要伦理问题 |
| 内容所有权 | 用户保留 | 社区保护 |
Stack Overflow 针对 AI 的授权策略区分了免费与商业用途。平台继续为非商业、教育和开源项目提供免费 API 及数据导出,延续对开发者社区的承诺。然而,为商业目的开发大型语言模型的公司,必须与 Stack Overflow 协商授权协议,定价基于模型规模、使用量和收入等因素。Stack Overflow CEO Chandrasekar 强调,公司只向为“大型商业目的”开发 LLM 的组织收取费用,不针对个人开发者或小型项目。这种双重授权模式让 Stack Overflow 获得新收入来源,同时保护了社区成员利益——许多开发者无偿贡献内容。公司还承诺将授权收入再投入社区工具和功能改进,形成用开发者贡献直接反哺平台建设的可持续模式。
Stack Overflow 内容如今在 ChatGPT、Google Gemini、Perplexity、Microsoft Copilot 等主流平台的 AI 生成回答中占据显著位置。Google 的 Gemini Cloud Assist 在提供代码解决方案时会明确署名 Stack Overflow 回答,直接在 AI 回应中显示原问题、答案及作者信息。OpenAI 的 ChatGPT 在涉及编程话题时会给出 Stack Overflow 链接,SearchGPT(OpenAI 的搜索原型)则在对话和搜索结果中均包含 Stack Overflow 内容。这种可见性对开发者至关重要,因为它能为他们带来流量,并确立其领域专家地位。然而,并非所有 AI 平台都能做到同等归属,开发者往往难以了解自己的哪些回答被引用、频率如何、在不同 AI 系统中的具体上下文。
2024 年 Stack Overflow 开发者调查显示,AI 的采用与信任之间的鸿沟正在扩大:虽然 76% 的开发者正在使用或计划使用 AI 工具(2023 年为 70%),AI 的支持率却从 77% 降至 72%。只有 43% 的开发者信任 AI 工具的准确性,调查明确指出三大开发者最关心的伦理问题:
这种信任赤字直接影响 AI 公司在数据获取和模型训练上的策略。开发者日益要求 AI 系统引用来源、认可社区贡献,并维持与 Stack Overflow 内容同行评审性质相符的准确标准。建设可信 AI 的压力,让对高质量训练数据的需求变得更加迫切,也让 Stack Overflow 经验证、社区精选的知识比以往更具价值。
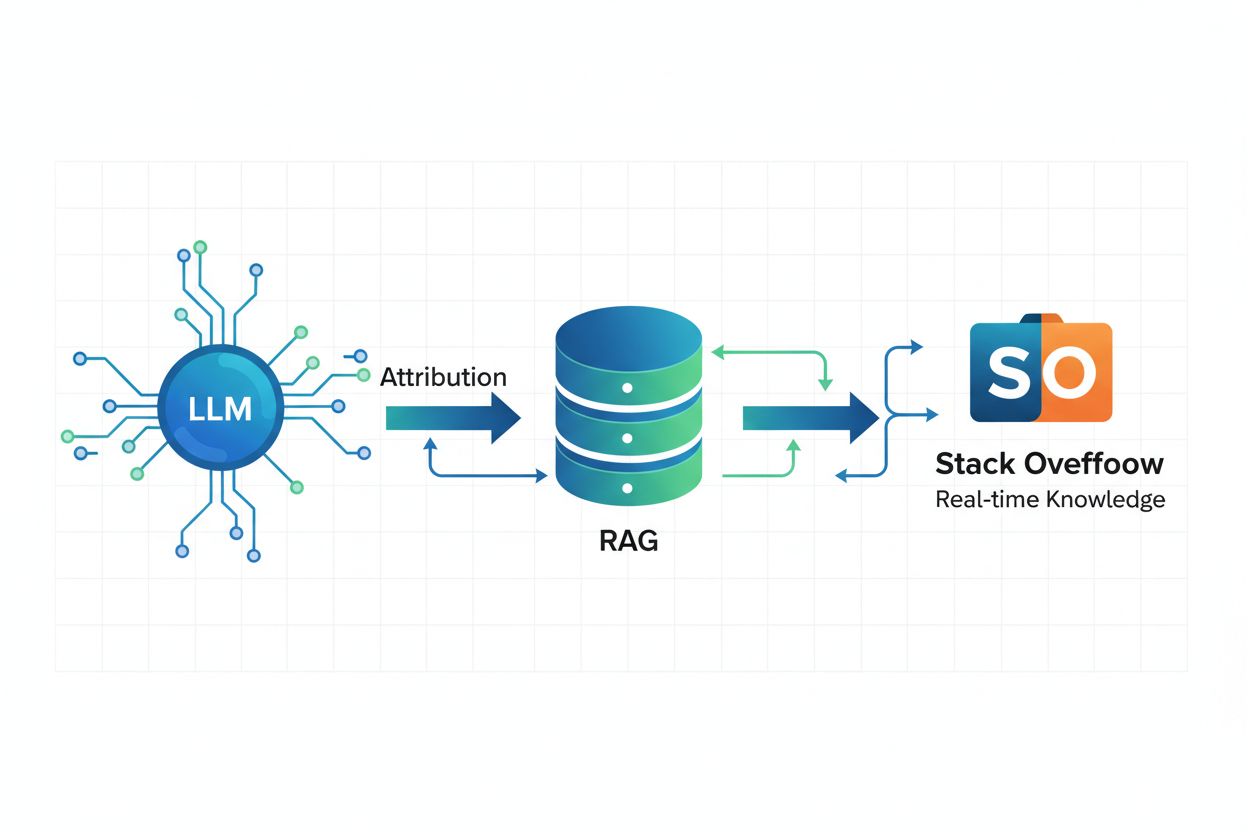
检索增强生成(RAG)是一种将大型语言模型与传统信息检索系统结合的 AI 框架,能提供最新、准确且有明确归属的答案。与仅依赖某一时间点冻结的训练数据不同,RAG 让 AI 系统能实时从 Stack Overflow 等外部来源获取信息,确保回答反映最新知识和最佳实践。所有 Stack Overflow 的 OverflowAPI 合作伙伴都已采用 RAG 实现归属,这意味着 AI 系统在用 Stack Overflow 内容生成答案时,能识别并引用具体影响回答的帖子。这项技术对于精确性和时效性要求高的领域知识尤其关键——例如,通过输入你代码库的具体示例让 AI 生成 C# 代码,能确保生成代码遵循你的团队规范和约定。RAG 通过让 AI 回应以可信、经验证的事实为基础,降低了幻觉风险,也为负责任的 AI 开发提供了技术基础。
贡献 Stack Overflow 的开发者应主动监测自己内容在各大平台 AI 生成回答中的表现。AmICited.com、XFunnel、Profound 等工具现已专为开发者设计可见性追踪,显示你的回答在 ChatGPT、Gemini、Perplexity 等 AI 系统中的引用位置、频率与上下文。应重点关注的指标包括引用频率(内容被引用的频次)、情感倾向(提及是正面还是中性)、平台分布(哪些 AI 系统引用最多)、来源归属(署名是否正确)。通过监测这些数据,开发者能识别哪些回答对 AI 系统最有价值、哪些话题最受欢迎,并据此调整自己的贡献策略。此外,跟踪可见性还能帮助开发者发现不准确或不完整的引用,便于及时更新原答案或联系 AI 公司进行修正。这种主动方式能将被动内容贡献转变为积极构建权威和影响力的策略,在 AI 驱动的信息生态中占据主动。
若要最大化在 AI 搜索结果中的可见性,并确保你的 Stack Overflow 贡献被正确引用,请专注于打造详尽、文档翔实的答案,全面回应问题并附有清晰解释和可运行的代码示例。随着技术演进,定期回顾并更新你的答案,因为 AI 系统更偏好更新内容——AI 结果引用的内容平均比 Google 排名内容新 25.7%。通过在多个相关领域持续输出高质量回答来建立权威,前 25% 的开发者在网络提及数上获得的 AI 引用量是普通开发者的 10 倍。积极参与更广泛的开发者生态,参与讨论、回答后续问题、帮助其他成员完善他们的贡献。最后,考虑你的回答如何被 AI 系统使用:用清晰标题组织内容,包含相关代码片段,并说明特定做法的适用情境和原因,使内容对人类读者和需要准确提取与署名信息的 AI 系统都更有价值。
Stack Overflow 的 5000 万个问答被纳入大型语言模型,因为它们代表了高质量、同行评审的技术内容。像 OpenAI、Google 和 Meta 这样的 AI 公司使用这些数据来训练模型,更好地理解和生成代码及技术方案。历史上,这些数据是免费被抓取的,但 Stack Overflow 现在要求商业 AI 开发者通过付费协议授权这些数据。
Stack Overflow 为非商业用途、教育用途和开源项目提供免费 API 访问权限。然而,为商业目的开发大型语言模型的公司必须协商付费授权协议。定价根据模型规模、使用量和产生的收入等因素决定,确保社区贡献获得合理补偿。
创建详尽、文档齐全的回答,包含清晰的解释和可运行的代码示例。随着技术发展,及时更新你的回答,因为 AI 系统更倾向于引用更新的内容。通过持续在多个主题下提供高质量答案来建立权威,并用清晰的标题和相关代码片段组织你的回答,方便 AI 系统提取和归属。
检索增强生成(RAG)是一种将语言模型与信息检索系统结合的 AI 框架,能提供最新、准确且有明确归属的答案。RAG 让 AI 系统能实时从 Stack Overflow 等来源提取信息,并引用影响回答的具体帖子,确保正确归属并降低幻觉风险。
像 AmICited.com、XFunnel、Profound 等工具专为开发者设计可见性追踪,显示你的回答在 ChatGPT、Gemini、Perplexity 及其他 AI 系统中的引用情况。这些工具追踪引用频率、情感倾向、平台分布及来源归属,帮助你了解哪些回答对 AI 系统最有价值。
根据 2024 年 Stack Overflow 开发者调查,开发者有三大伦理担忧:虚假信息风险(79% 担忧)、归属缺失或错误(65% 担忧)、以及无法代表多元观点的偏见(50% 担忧)。这些担忧推动了对合理授权、归属要求和高质量训练数据的需求。
Stack Overflow 内容采用 Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA) 许可,法律要求使用内容者需为原作者署名。Stack Overflow 现要求所有 API 合作伙伴在合同中加入归属条款,确保开发者的回答被 AI 系统使用时获得应有的认可。
有多种工具可用于追踪 AI 引用,包括 AmICited.com(专注于 AI 监测)、XFunnel(企业级 LLM 监测)、Profound(高级地理追踪)、Semrush AI 工具包、BrightEdge 等。这些工具帮助你追踪哪些 AI 平台引用了你、引用频率、上下文以及是否有正确归属。
了解 OpenAI 与 Reddit 的合作伙伴关系,其运作方式、为双方带来的益处,以及对 ChatGPT 和 Reddit 用户的影响。

学习 Reddit 话题优化策略,提升在 ChatGPT、Perplexity 和 Google AI Overviews 中的 AI 可见性。了解如何创作值得引用的内容并建立真实社群互动。...

探索AI训练数据所有权的复杂法律环境。了解谁控制你的内容,版权影响,以及新兴法规。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.