
Token
了解语言模型中的 token。Token 是 AI 系统文本处理的基本单位,将单词、子词或字符转换为数值。理解 token 对于把握 AI 成本与性能至关重要。...
3 分钟阅读

探索 token 限制如何影响 AI 表现,并学习包括 RAG、分块和摘要技术在内的内容优化实用策略。
Token 是 AI 模型处理和理解信息的基本构建单元。大型语言模型并不是以完整词语或句子为单位运作,而是将文本拆分为更小的单元——token。每个 token 可以是字符、子词或单词,具体取决于分词算法。每个 token 都被分配唯一的数字标识符,供模型内部计算使用。这一分词过程至关重要,因为它让 AI 系统能够高效处理变长输入,并在不同类型内容间保持一致的处理方式。理解 token 的作用对于任何 AI 系统的开发者来说都非常关键,因为它们直接影响性能、成本以及您最终能取得的结果质量。
不同 AI 模型的 token 限制差异巨大,这决定了它们在单次请求中最多可处理的信息量。近年来,这些限制快速提升,新一代模型支持的上下文窗口大为增长。token 限制涵盖输入 token(您的提示和数据)与输出 token(模型的响应),共同组成需精细管理的预算。理解这些限制对于选择合适的模型和规划应用架构至关重要。
| 模型 | Token 限制 | 主要应用场景 | 成本级别 |
|---|---|---|---|
| GPT-3.5 Turbo | 4,096 | 简短对话、快速任务 | 低 |
| GPT-4 | 8,192 | 标准应用、中等复杂度 | 中 |
| GPT-4 Turbo | 128,000 | 长文档、复杂分析 | 高 |
| Claude 3.5 Sonnet | 200,000 | 长文档、全面分析 | 高 |
| Gemini 1.5 Pro | 1,000,000 | 海量数据集、整本书、视频分析 | 极高 |
评估 token 限制时的关键考量:
Token 限制构成了直接影响 AI 应用准确性、可靠性和成本效益的重要约束。一旦超出模型 token 限制,应用会完全失败——不会有部分处理或降级机制。即便在限制之内,简单截断等朴素方法也可能因删除关键信息而严重降低表现,模型无法生成准确答案。在法律分析、医学研究、软件工程等领域,这尤为致命,遗漏细节可能导致错误结论。不同类型内容消耗 token 的速度也不同——如代码或 JSON 这类结构化数据由于符号和格式化,token 用量远高于纯英文文本。
截断是处理 token 限制最简单的方法——内容超限时直接裁剪。虽然易于实现,这一做法风险较大。截断文本时,信息必然丢失,模型无法知道丢掉了哪些内容,进而导致分析不完整、遗漏上下文,甚至出现模型“编造”信息来填补认知空白的幻觉。
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
更高级的截断策略会区分核心与可选内容。您可以优先保留当前用户提问和主要指令,只有空间充足时才附加历史对话等可选上下文。这样既保证了关键信息,又不超出 token 限制。
与截断不同,分块将内容拆分为更小、可独立或选择性处理的单元。定长分块将文本等分,语义分块则使用嵌入识别自然语义断点,而非机械地按 token 数裁切。带重叠的滑动窗口能在分块间保留上下文,避免跨块关键信息丢失。
分层分块可建立多级抽象——最细粒度为段落,上升为章节,再到整章。这样便于构建复杂检索机制,无需处理全篇文档即可快速锁定相关内容。结合向量数据库与语义检索,分块成为管理大规模知识库、兼顾相关性与准确性的有力工具。
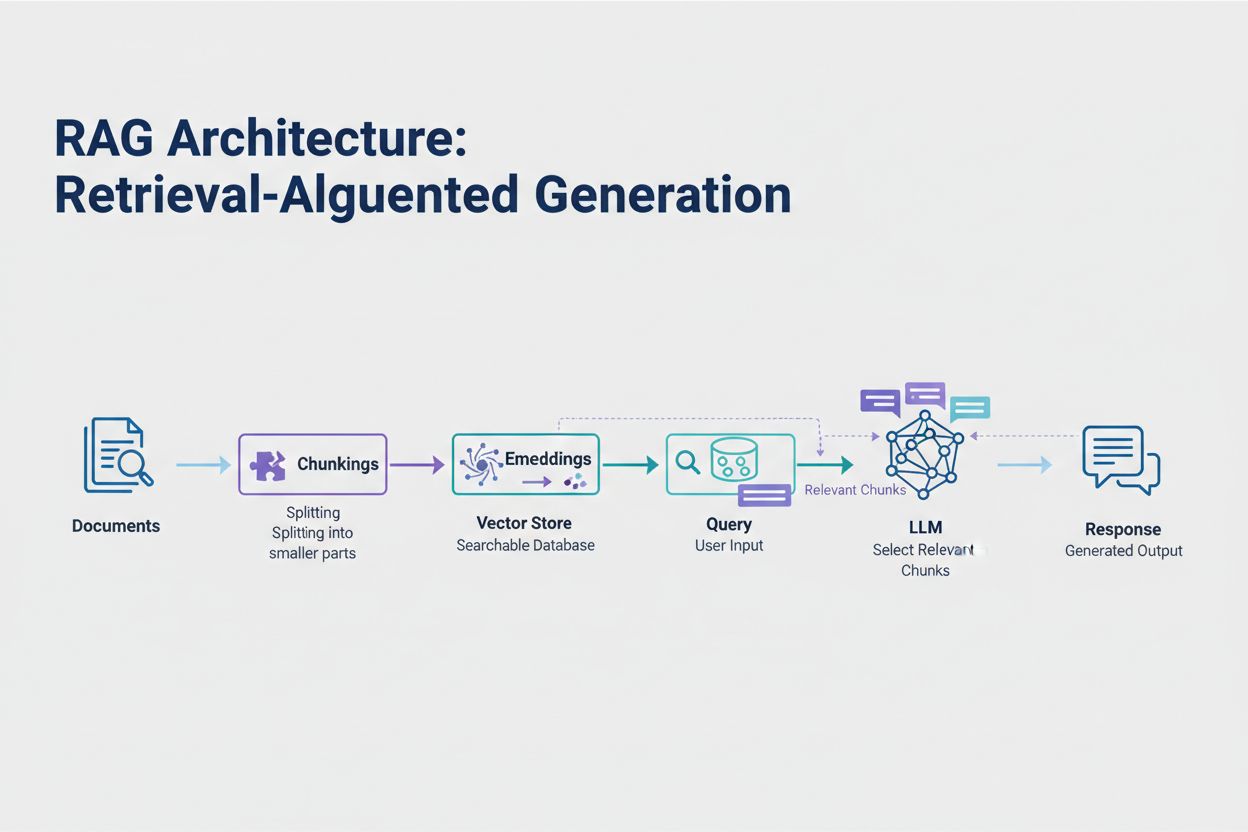
检索增强生成(RAG)是当前应对 token 限制最有效的方法。它不再试图将所有数据塞入模型窗口,而是在查询时只检索最相关的信息。流程是:先将文档转换为嵌入(数值化语义表示),存入向量数据库,实现高速相似度检索。
用户查询时,系统将查询也做嵌入,检索出最相关的文档分块。这些相关分块与用户问题一起注入提示,大幅减少 token 用量,同时提升准确率。例如,分析 100 页法律合同时,通过 RAG 只需把 3-5 条关键条款塞进提示,而不是数千个 token 的全合同内容。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
摘要技术可在保留关键信息的同时压缩长内容,显著减少 token 消耗。抽取式摘要挑选原文的关键句子,生成式摘要则重写为简洁的新文本,把核心思想表达出来。分层摘要先对各个小节进行摘要,再将这些摘要合并为更高层级的总览,非常适合结构化文档如论文或技术报告。
上下文压缩则通过删除冗余、填充内容来缩减 token 数,同时保留原始表述。知识图谱方法则提取文本中的实体及其关系,只用最相关事实重建上下文。这些方法能在保持语义正确的前提下,将 token 减少 40-60%,非常适合生产系统中的成本优化。
Token 管理直接影响 AI 应用成本。推理时每消耗一个 token 都会计费,整体成本与 token 用量线性相关。监控 token 消耗对于理解成本结构和识别优化机会至关重要。许多 AI 平台已经提供 token 计数工具和实时仪表盘,帮助您追踪 token 消耗的查询和功能。
有效监控能发现优化空间——比如某些查询类型经常超限,或某些功能消耗资源异常。通过跟踪这些模式,您可做出明智决策:有些应用适合将大请求路由到更强大(但更昂贵)的模型,有些则更适合用 RAG 或摘要。关键在于实际测量表现与成本,验证优化选择。
选择何种 token 管理策略,需结合具体应用场景、性能要求和成本约束。需高准确率且有出处的应用最适合 RAG,既能保真又能控量。长对话应用可借助记忆缓冲,将历史内容摘要压缩,仅保留关键决策和上下文。文档密集型场景如法律分析、科研工具,则常结合分层摘要与语义分块。
生产前必须进行测试与验证。设计超出模型 token 限制的测试案例,评估不同策略对准确率、延迟和成本的影响。衡量答案相关性、事实准确性、token 效率等指标,确保方案满足要求。常见陷阱包括过度摘要丢失细节、检索系统遗漏关键信息、分块割裂语义等。
随着模型日益复杂与高效,token 限制会继续扩展。稀疏注意力、效率更高的 Transformer 等新技术有望降低大窗口推理的计算成本。多模态模型(同时处理文本、图像、音频、视频)带来新的分词挑战与机遇。推理 token——模型用以“思考”复杂问题的特殊 token——也成为新兴的消耗类型,使更复杂推理成为可能,但需要精细管理。
趋势很明确:上下文窗口扩展、token 处理更高效后,瓶颈将从容量转向智能内容选择。未来属于那些能从海量知识库中高效识别与检索最相关信息的系统,而非单纯处理更多数据的系统。这使 RAG 与语义检索等技术对构建可扩展、低成本的 AI 应用越来越重要。
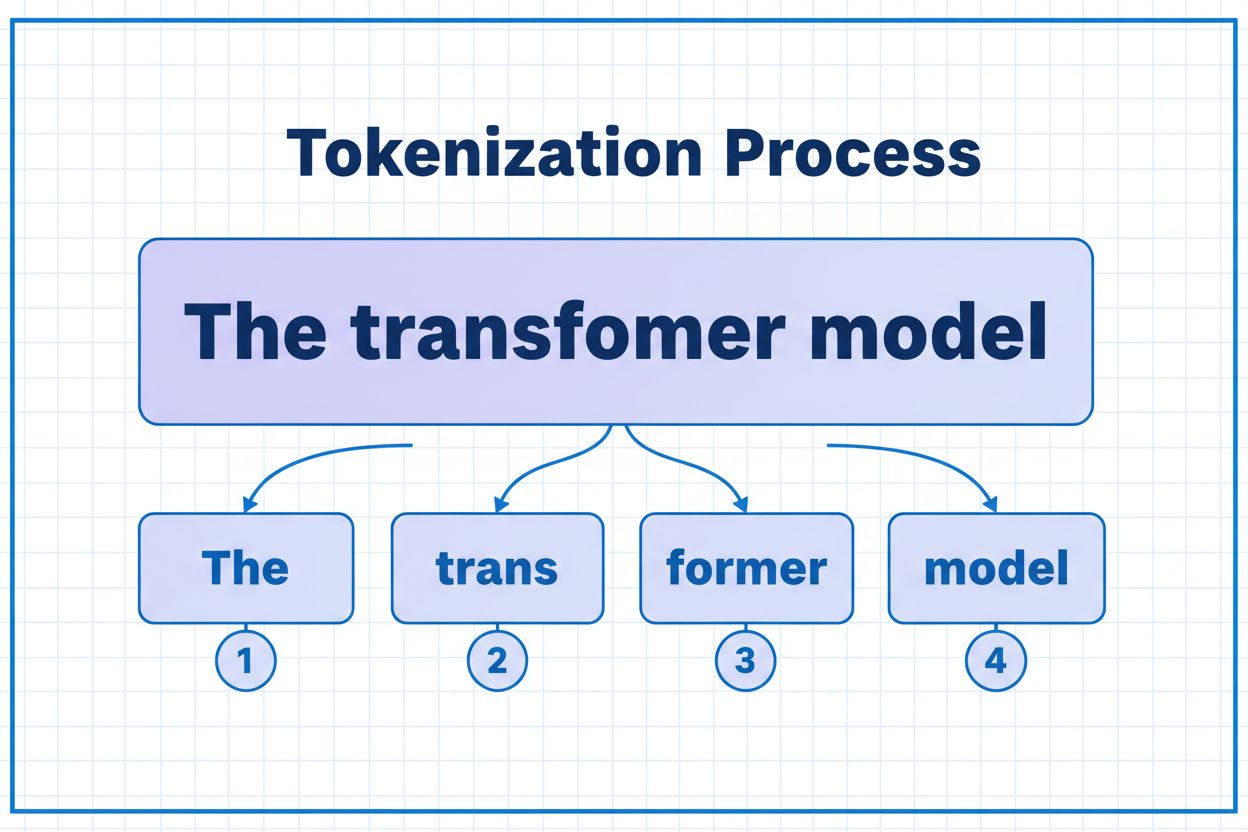
Token 是 AI 模型处理的最小数据单元。根据分词算法,token 可以是单个字符、子词或完整单词。例如,单词 'transformer' 可能会被分为 'trans' 和 'former' 两个 token。每个 token 都被分配唯一的数字标识符,模型在内部计算时会用到这些标识符。
Token 限制定义了您的 AI 模型在单次请求中能处理的信息量上限。超过此限制时,应用会完全失败。而即使在限制范围内,诸如截断这样的简单做法也可能因删除关键信息而降低准确性。token 限制还直接影响成本,因为通常是按消耗的 token 数量计费。
输入 token 指的是您发送给模型的提示和数据中的 token,输出 token 是模型在响应中生成的 token。这些 token 共享由模型上下文窗口定义的总预算。例如,在 128K token 的窗口中,如果输入占用了 90%,则输出只剩下 10% 的空间。
截断实现简单但风险较高。它会直接删除信息,模型无法知晓丢失了哪些内容,可能导致分析不完整和产生虚假内容。虽然作为最后手段有用,但如 RAG、分块或摘要等更优方法可以在管理 token 消耗的同时保留信息的完整性。
检索增强生成(RAG)只在查询时检索最相关的信息,而不是包含完整文档。您的文档会被转换为嵌入并存储在向量数据库中。当用户发起查询时,系统仅检索相关分块并注入到提示中,大幅减少 token 消耗,同时提升准确性。
大多数 AI 平台提供 token 计数工具和实时仪表盘以追踪使用模式。监控哪些查询或功能消耗最多的 token,然后针对文档密集型应用采用 RAG、对长对话用摘要、复杂任务路由到更大模型等优化策略。实际测量性能与成本,验证您的优化选择。
AI 服务通常按消耗的 token 计费。成本与 token 用量线性增长,因此 token 优化直接影响支出。token 消耗减少 20%,成本也会降低 20%。理解 token 效率有助于根据预算选用合适的优化策略。
随着模型日趋复杂,token 限制持续扩展。新兴技术如稀疏注意力机制有望降低处理大规模上下文的计算成本。未来重点会从原始处理能力转向智能内容选择与检索,RAG 等技术对可扩展 AI 应用越来越重要。
了解语言模型中的 token。Token 是 AI 系统文本处理的基本单位,将单词、子词或字符转换为数值。理解 token 对于把握 AI 成本与性能至关重要。...

了解AI模型如何通过分词、嵌入、Transformer模块和神经网络处理文本。理解从输入到输出的完整流程。
了解什么是 AI 语言模型中的上下文窗口,它们的工作原理、对模型性能的影响,以及它们为何对 AI 应用和监控至关重要。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.