
AI中的训练数据与实时搜索——我究竟该优化哪一个?
社区讨论AI训练数据与实时搜索(RAG)的区别。针对静态训练数据与实时检索,提供内容优化的实用策略。
2 分钟阅读
Discussion
Training Data
+1
训练数据优化和实时检索代表了为AI模型赋予知识的两种根本不同方法。训练数据优化通过在领域专属数据集上微调,将知识直接嵌入模型参数,形成在训练完成后保持不变的静态知识。而实时检索则将知识保留在模型外部,推理时动态检索相关信息,从而可以访问每次请求时可能变化的动态信息。核心区别在于知识集成进模型的时机:训练数据优化发生在部署前,而实时检索则在每次推理调用时进行。这一根本差异影响了实施的方方面面,包括基础设施需求、准确性特征以及合规性考量。理解这种区别对于企业选择最契合自身应用场景和约束条件的优化策略至关重要。
训练数据优化通过在微调过程中,持续让模型接触经过精心筛选的领域数据集,系统性地调整模型内部参数。当模型反复看到训练样本时,会通过反向传播和梯度更新逐步内化模式、术语和领域知识,进而重塑模型的学习机制。这一过程使企业能够将专业知识——如医学术语、法律框架或专有业务逻辑——直接编码进模型的权重与偏置中。最终模型对目标领域高度专精,通常能达到比肩更大型模型的表现;Snorkel AI的研究表明,经微调的小模型可达1400倍大模型的等效性能。训练数据优化的主要特征包括:
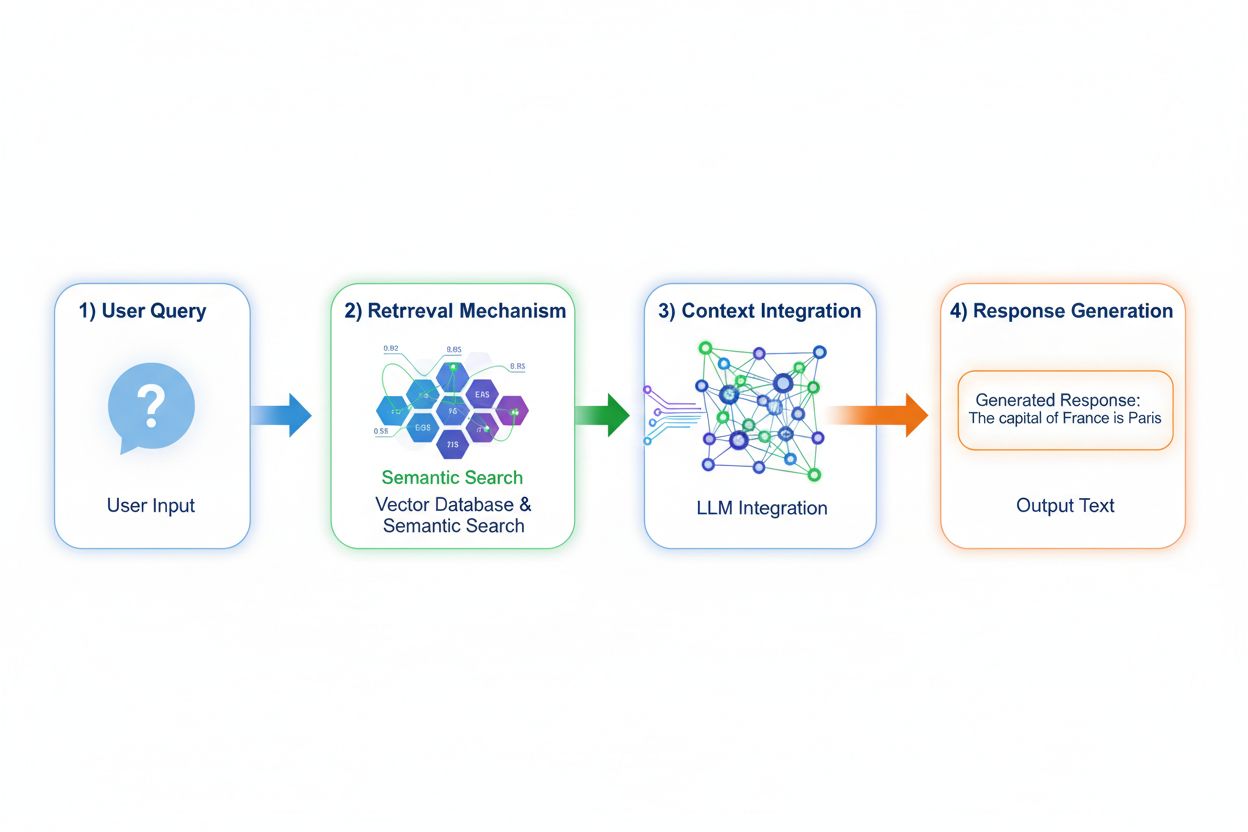
检索增强生成(RAG)彻底改变了模型获取知识的方式,实现了查询编码、语义检索、上下文排序及带溯源生成的四阶段流程。当用户输入查询时,RAG首先用嵌入模型将其转为稠密向量表示,然后在包含已索引文档或知识源的向量数据库中检索。检索阶段采用语义搜索,按相关性得分排序上下文片段,而非简单的关键词匹配。最后,模型生成回复并明确引用检索到的来源,将输出锚定于实际数据而非已学参数。这种架构让模型能访问训练时尚不存在的信息,使RAG对需最新数据、专有信息或高频更新知识库的应用尤为有价值。RAG机制本质上将模型从静态知识仓库转变为可动态整合新数据的信息合成器,无需重新训练即可吸纳新知识。
两种方法在准确性和幻觉表现上存在显著差异,直接影响实际部署效果。训练数据优化产生的模型具备深厚的领域理解力,但难以明确知识边界;当遇到超出训练分布的问题时,微调模型可能会自信地生成听起来合理但实际错误的信息。RAG通过将回复锚定在检索文档上,显著减少了幻觉现象——模型无法声称来源中没有的信息,自然限制了内容编造。但RAG也引入了不同的准确性风险:如检索阶段未找到相关来源或高排名文档无关,则模型将基于错误上下文生成回复。对于RAG系统,数据新鲜度尤为重要;训练数据优化仅能反映训练时的知识快照,而RAG则持续反映源文档的最新状态。来源归属是另一个区别:RAG天然支持内容引用和验证,而微调模型无法指明知识来源,给事实核查和合规验证带来难题。
两种方法的经济结构各异,需企业仔细权衡。训练数据优化需要高额的前期计算成本:GPU集群数日甚至数周微调模型、数据标注服务生成训练集、ML工程设计高效训练流程。训练完成后,模型部署推理成本较低,无需外部检索。RAG系统则成本结构相反:初始训练成本低,无需微调,但需持续投入基础设施维护,如向量数据库、嵌入模型部署、检索服务和文档索引等。主要成本要素包括:
两种方法在安全与合规性上的差异对受监管行业尤为重要。微调模型带来数据保护难题,因为训练数据被嵌入模型权重,想要追溯或审计模型包含了哪些知识需用复杂技术,且隐私风险随训练数据影响模型行为而增加。面对GDPR等法规,模型对培训数据的“记忆”难以删除或修改,合规变得复杂。RAG系统则提供不同的安全特性:知识保留在外部、可审计的数据源中,而非模型参数,便于实施安全控制和访问限制。企业可对检索来源设置细粒度权限,审计每次回复涉及的文档,并通过更新文档快速移除敏感信息,无需重训模型。但RAG也带来向量数据库安全、嵌入模型保护和防止检索内容泄露敏感信息等新风险。HIPAA医疗和GDPR合规的欧盟企业常因RAG的透明与可审计性而偏好这一方法,而对模型可移植性和离线运行有更高要求的场景则倾向微调的自包含优势。
选用何种方案需结合企业自身约束和场景特性评估。知识稳定且不常变化、对推理延迟极为敏感、模型需离线/隔离环境运行或需保持风格与格式一致时,优先考虑微调。知识频繁变化、需来源归属和可审计性以满足合规、知识库过大不宜编码进模型或需无需重训即可更新信息时,优先实时检索。具体应用场景包括:
混合方法将微调与RAG结合,兼收两者优点,弥补各自短板。企业可在领域基础知识和表达习惯上对模型微调,同时用RAG检索最新细节——模型学会如何思考领域问题,检索什么具体事实。此类组合策略对既需专业知识又需实时信息的场景尤为有效:如金融顾问机器人在投资原理与术语上进行微调,通过RAG检索实时行情和公司财报。实际混合应用还包括在医学知识与流程上微调的医疗系统,通过RAG检索患者信息,以及在法律推理上微调的法律检索平台,通过RAG获取最新判例。协同优势包括减少幻觉(锚定检索来源)、提升领域理解(微调)、常见问题推理更快(缓存知识)、无需重训练即可灵活更新。随着算力日益普及和实际应用复杂度提升,企业正日益采用这种优化方法,以兼顾知识深度与时效性。
随着企业规模化部署优化策略,实时监控AI回复变得越来越关键,特别是了解哪种方法对特定场景效果更佳。AI监控系统跟踪模型输出、检索质量和用户满意度等指标,帮助企业衡量微调模型和RAG系统的实际表现。引用追踪揭示了两种方法的核心差异:RAG系统天生生成引用和来源,为每条回复提供影响内容的文档审计链,而微调模型本身不具备回复监控和归属功能。对于品牌安全和竞争情报,这一差异极为重要——企业需了解AI系统如何引用竞争对手、产品及其信息来源。像AmICited.com这样的工具正好补齐了这一空白,能监控AI系统在不同优化策略下对品牌和公司的引用,实现实时追踪引用模式与频率。通过完善监控,企业能衡量所选优化策略(微调、RAG或混合)是否真正提升了引用准确性、减少了对竞争对手的幻觉,并维护了权威来源的归属。这一数据驱动的监控方式,帮助企业基于实际表现持续优化策略,而非仅凭理论判断。
行业正向更复杂的混合与自适应方法演进,根据查询特性和知识需求动态选择优化策略。新兴最佳实践包括检索增强微调,即模型微调的重点转为如何高效利用检索信息,而非死记事实;以及自适应路由系统,将查询分流至微调模型处理稳定知识、RAG系统处理动态信息。行业趋势还包括为特定领域定制的嵌入模型和优化向量数据库,以实现更精准语义检索和降低检索噪声。企业还在探索持续模型改进模式,结合定期微调与实时RAG增强,打造既可进化又能保持信息时效性的系统。优化策略的演进反映了行业对“没有一种方法适用于全部场景”的共识;未来系统大概率会实现智能选择机制,能根据查询上下文、知识稳定性、时延与合规等动态选择微调、RAG或混合方案。随着这些技术的成熟,竞争优势将从“选哪种方法”转向“如何专业地自适应融合各种策略”。
训练数据优化通过微调,将知识直接嵌入模型参数中,形成在训练后保持不变的静态知识。实时检索则将知识保持在模型外部,在推理时动态获取相关信息,使其能够访问每次请求间可能变化的动态信息。核心区别在于知识集成的时机:训练数据优化发生在部署前,实时检索则发生在每一次推理调用期间。
当知识相对稳定且不常变化、推理延迟极为关键、模型需离线运行或需要保持一致的风格和领域特定格式时,应选择微调。微调非常适用于如医疗诊断、法律文档分析或产品信息稳定的客户服务等专业化任务。然而,微调需要大量的前期计算资源,当信息频繁变化时,微调将变得不切实际。
可以,混合方法结合了微调和RAG的优点。企业可以在领域基础知识上进行模型微调,同时使用RAG访问最新、详细的信息。这种方法尤其适用于既需专业知识又需实时信息的应用,如金融顾问机器人或既需医学知识又需患者数据的医疗系统。
RAG通过将回复锚定在检索到的文档上,大幅减少了幻觉现象——模型无法声称其来源中没有的信息,从而对编造内容形成了天然约束。相比之下,微调模型在遇到超出训练分布的问题时,可能会自信地生成听起来合理但实际上错误的信息。RAG的来源归属还能验证内容,而微调模型无法指明其知识来源。
微调需要高昂的前期投入:GPU小时(每个模型$10,000-$100,000+)、数据标注(每例$0.50-$5)以及工程成本。训练完成后,推理服务成本相对较低。RAG系统初始成本较低,但需持续投入向量数据库、嵌入模型与检索服务的基础设施。微调模型的推理成本随调用量线性增长,而RAG则同时受调用量和知识库规模影响。
RAG系统天然会生成引用和来源参考,为每条回复提供影响其内容的文档审计链。这对于品牌安全和竞争情报尤为关键——企业可以追踪AI系统如何引用竞争者及自身产品。像AmICited.com这样的工具可以监控AI系统在不同优化策略下对品牌的引用,实现引用模式与频率的实时跟踪。
RAG通常更适合医疗、金融等合规性要求高的行业。知识保留在外部、可审计的数据源中,而非模型参数内,便于实施安全管控与访问限制。企业可对检索来源实施细粒度权限,审计模型访问的文档,并能在不需重新训练的情况下迅速移除敏感信息。HIPAA医疗和GDPR合规机构通常偏好RAG的透明与可审计性。
可实施AI监控系统,跟踪模型输出、检索质量和用户满意度等指标。RAG系统应监控检索准确性和引用质量,微调模型则关注领域任务准确率和幻觉发生率。可用AmICited.com等工具监控AI系统的信息引用情况,并根据实际表现对不同优化策略进行比较。
社区讨论AI训练数据与实时搜索(RAG)的区别。针对静态训练数据与实时检索,提供内容优化的实用策略。
了解 AI 训练数据与实时搜索的区别。学习知识截止、RAG 及实时检索如何影响 AI 可见性与内容策略。
了解 AI 中的实时搜索如何工作、其对用户和企业的好处,以及它与传统搜索引擎和静态 AI 模型的区别。