

AI 搜索中的嵌入是什么?
了解嵌入在 AI 搜索引擎和语言模型中的工作原理。理解向量表示、语义搜索及其在 AI 生成答案中的作用。
1 分钟阅读

向量嵌入是现代人工智能系统的数字基础,将原始数据转化为机器能够理解和处理的数学表示。嵌入的核心在于将文本、图像、音频等各种内容类型转换为数字数组——通常是几十到几千维——以捕捉数据中的语义含义和上下文关系。这种数字化表示是AI系统实现内容匹配、语义搜索和推荐任务的根本,使机器不仅能识别出现了哪些词语或图片,更能理解它们实际表示的含义。如果没有嵌入,AI系统将难以把握概念之间细腻的关系,因此嵌入成为所有现代AI应用的重要基础设施。
原始数据转化为向量嵌入的过程,是通过在海量数据集上训练的复杂神经网络模型来学习有意义的模式和关系。当你将文本输入嵌入模型时,它会经过神经网络的多层处理,逐步提取语义信息,最终生成一个固定大小的向量,代表该内容的本质。流行的嵌入模型如 Word2Vec、GloVE 和 BERT 各有不同的方法——Word2Vec采用为速度优化的浅层神经网络,GloVE结合了全局矩阵分解与本地上下文窗口,BERT则利用Transformer架构理解双向上下文。
| 模型 | 数据类型 | 维度 | 主要应用场景 | 关键优势 |
|---|---|---|---|---|
| Word2Vec | 文本(词语) | 100-300 | 词语关系 | 快速高效 |
| GloVE | 文本(词语) | 100-300 | 语义关系 | 结合全局与本地上下文 |
| BERT | 文本(句子/文档) | 768-1024 | 上下文理解 | 双向上下文感知 |
| Sentence-BERT | 文本(句子) | 384-768 | 句子相似度 | 针对语义搜索优化 |
| Universal Sentence Encoder | 文本(句子) | 512 | 跨语言任务 | 语言无关性 |
这些模型会生成高维向量(通常为300到1536维),每一维都捕捉了不同的含义特征,从语法属性到概念关系。这种数字表示的魅力在于它支持数学运算——你可以对向量进行加减比较,从而发现原始文本中看不到的内在关系。正是这种数学基础,使得大规模语义搜索和智能内容匹配成为可能。
嵌入的真正威力体现在语义相似性,即在向量空间中识别不同词语或短语在本质上具有相同含义的能力。当嵌入构建得当时,语义相近的概念会自然地聚集在高维空间的相邻位置——比如“king(国王)”与“queen(王后)”相邻,“car(小汽车)”与“vehicle(车辆)”也会靠近,尽管它们用词不同。为了度量这种相似性,AI系统常用余弦相似度(衡量向量夹角)或点积(衡量大小和方向)等距离度量方法,来量化两个嵌入之间的接近程度。例如,“automobile transportation(汽车运输)”的查询与“car travel(小汽车出行)”的文档具有很高的余弦相似度,使系统能够基于含义而不是仅靠关键词实现内容匹配。这种语义理解,是现代AI搜索区别于简单关键词匹配的根本,使系统能够理解用户意图并提供真正相关的结果。
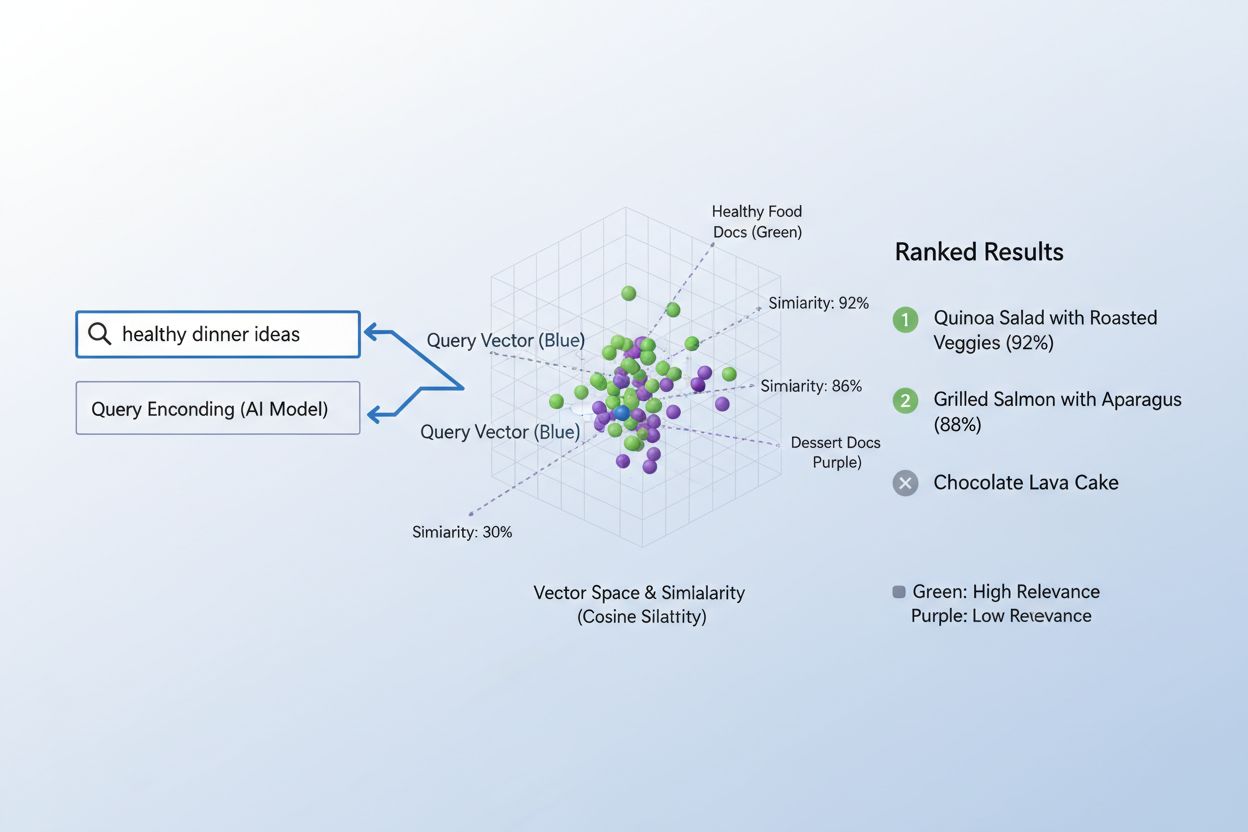
利用嵌入将内容与查询匹配的流程非常优雅,通常分为两步,这一机制支持了从搜索引擎到推荐系统的各种应用。首先,用户的查询和系统中的所有内容会分别通过同一个嵌入模型转化为向量——比如“machine learning的最佳实践”这样的查询会变成一个向量,系统数据库中的每篇文章、文档或产品也都各有一个向量。接下来,系统会计算查询向量与每个内容向量之间的相似度,通常采用余弦相似度,得出每个内容与查询相关性的分数。最后,这些分数会被排序,分数最高的内容作为最相关的结果呈现给用户。在真实的搜索引擎场景中,当你搜索“如何训练神经网络”时,系统会对你的查询进行编码,与数百万文档嵌入进行比对,并返回关于深度学习、模型优化和训练技术的文章——这一切都无需完全匹配关键词。整个匹配过程只需毫秒级,能够满足同时为数百万用户实时服务的需求。
不同类型的嵌入根据具体的匹配或理解目标,发挥着不同作用。词向量嵌入捕捉单个词语的含义,适合需要细粒度语义理解的任务;句子嵌入和文档嵌入则汇聚长文本的含义,非常适合将完整查询与整篇文章或文档进行匹配。图像嵌入将视觉内容转化为数字向量,使系统能够查找视觉上相似的图片,或将图片与文本描述相匹配;用户嵌入和商品嵌入则捕捉行为模式与特征,为推荐系统提供对用户偏好的预测。不同嵌入类型的选择涉及权衡:词向量计算效率高但丢失上下文,文档嵌入保留全部含义但需要更多计算资源。特定领域的嵌入(如医学文献或法律文档)在专用数据集上微调后,往往优于通用模型,但需要额外的数据和计算资源。
在实际应用中,嵌入技术支撑着我们日常使用的许多重要AI应用,从搜索结果到线上商品推荐。语义搜索引擎利用嵌入理解查询意图,不依赖关键词完全匹配即可呈现相关内容;而Netflix、亚马逊和Spotify的推荐系统则通过用户和物品嵌入预测你可能想看的内容、想买的商品或想听的歌曲。内容审核系统通过将用户生成的帖子与已知违规内容的嵌入进行比对,检测有害信息;问答系统则利用嵌入将用户问题与知识库中的相关内容进行语义匹配。个性化引擎通过理解用户偏好调整体验,异常检测系统则通过识别新数据点远离常规嵌入簇来发现异常模式。在AmICited,我们利用嵌入监控AI系统在互联网上的使用情况,将用户查询与内容进行匹配,以追踪AI生成或AI辅助内容的分布,帮助品牌了解自身的AI足迹,确保内容得到正确归属。
要高效应用嵌入,需要关注诸多影响性能与成本的技术细节。模型选择至关重要——你需要平衡嵌入的语义质量与计算需求,像BERT这样的大模型能生成更丰富的表示,但比轻量级模型需要更多计算资源。维度选择是关键权衡点:高维嵌入能捕捉更多细节,但消耗更多内存、降低相似度计算速度,低维嵌入则更快但可能丢失重要语义。为高效实现大规模匹配,系统会采用如FAISS(Facebook AI Similarity Search)或Annoy(Approximate Nearest Neighbors Oh Yeah)等专用索引策略,通过树结构或局部敏感哈希等方式,使相似嵌入的查找从秒级缩短到毫秒级。对嵌入模型在特定领域数据上的微调,能显著提升专业应用的相关性,但需要标注数据和更多计算。组织需要根据实际场景和约束,在速度与准确性、计算成本与语义质量、通用与专用模型之间做出持续权衡。
嵌入的未来正朝着更智能、高效与广泛集成迈进,将激发更强大的内容匹配与理解能力。多模态嵌入正在兴起,能同时处理文本、图像、音频等不同内容类型,使系统能够实现跨模态匹配——比如根据文本查询查找相关图片,或反之——为内容发现和理解开辟全新空间。研究人员正在开发更高效的嵌入模型,用更少的参数实现可比拟的语义质量,让先进AI能力惠及更小型组织和边缘设备。嵌入与大型语言模型的融合,正在催生能同时理解语义、上下文、细微差别和意图的系统。随着AI系统在互联网上愈发普及,追踪、监控和理解内容如何被匹配和使用变得日益重要——这正是AmICited等平台利用嵌入,帮助组织监控品牌影响力、跟踪AI使用模式、确保内容被正确归属和合理利用的意义所在。更优的嵌入、更高效的模型和更智能的监控工具的融合,正引领AI系统走向更加透明、负责任、符合人类价值观的未来。
向量嵌入是数据(文本、图像、音频)在高维空间中的数字表示,能够捕捉语义含义和关系。它将抽象数据转换为机器可以处理和分析的数字数组。
嵌入将抽象数据转换为机器可处理的数字,使AI能够识别内容之间的模式、相似性和关系。这种数学表示使AI系统能够理解含义,而不仅仅是匹配关键词。
关键词匹配寻找完全相同的词语,而语义相似性理解含义。这使系统即使没有相同的词语也能找到相关内容——例如,通过语义关系而不是文本完全匹配,将“automobile(汽车)”与“car(小汽车)”匹配。
可以,嵌入可以表示文本、图像、音频、用户画像、产品等。不同的嵌入模型针对不同数据类型进行了优化,从用于文本的Word2Vec到用于图像的CNN,再到用于音频的声谱图。
AmICited利用嵌入理解AI系统如何在不同平台和响应中语义匹配并引用您的品牌。这有助于跟踪您的内容在AI生成答案中的存在,并确保正确归属。
主要挑战包括选择合适的模型、管理计算成本、处理高维数据、针对特定领域进行微调,以及在相似性计算中平衡速度与准确性。
嵌入实现了语义搜索,能够理解用户意图,并根据含义而不仅仅是关键词匹配返回相关结果。这使搜索系统能够找到即使不包含查询词但在概念上相关的内容。
大型语言模型在内部使用嵌入来理解和生成文本。嵌入是这些模型处理信息、内容匹配和生成上下文相关响应的基础。
了解嵌入在 AI 搜索引擎和语言模型中的工作原理。理解向量表示、语义搜索及其在 AI 生成答案中的作用。

了解嵌入是什么、如何工作,以及它们为何对AI系统至关重要。探索文本如何转化为捕捉语义意义的数值向量,助力搜索、RAG和AI监测。...
社区讨论解释了 AI 搜索中的嵌入。为营销人员实用讲解向量嵌入如何影响内容在 ChatGPT、Perplexity 及其他 AI 系统中的可见性。...