
AI 引用内容需要满足哪些质量标准?有具体门槛吗?
社区讨论 AI 搜索引用内容的质量要求。了解 ChatGPT、Perplexity 及其他 AI 平台对内容需要满足的质量门槛。
2 分钟阅读
Discussion
Content Quality
+2

了解AI内容质量阈值是什么、如何衡量,以及它为何对于监控ChatGPT、Perplexity等AI答案生成器中的AI生成内容至关重要。
AI内容质量阈值是一个可衡量的基准,用于判定AI生成的内容是否达到准确性、相关性、连贯性和伦理安全等方面的最低标准。它结合了定量指标和定性评估标准,以确保内容适合在特定场景下发布或使用。
AI内容质量阈值是预先设定的基准或标准,用于判定AI生成的内容是否达到最低可接受标准,以用于发布、分发或在特定应用场景中使用。在生成式AI时代,这些阈值成为关键的控制机制,帮助组织在自动内容生成的速度与效率和品牌完整性、准确性及用户信任之间取得平衡。阈值相当于质量闸门,确保只有符合既定标准的内容才能触达您的受众,无论是通过ChatGPT、Perplexity等AI答案引擎,还是其他AI驱动的平台。
质量阈值不是随意设定的数字,而是通过评估框架科学制定的基准线,从多个维度衡量内容表现。它们结合了技术指标、人类判断和业务目标,为AI驱动的内容生态系统建立了全面的质量保障体系。
准确性是任何质量阈值体系的基础。该维度衡量AI生成内容所呈现信息的事实正确性及可验证性。在医疗、金融、新闻等高风险领域,准确性阈值尤其严格,通常要求95-99%的正确率。AI系统的挑战在于可能生成幻觉——听起来合理但完全虚构的信息,因此准确性评估尤为关键。
通常通过将AI输出与真实数据、专家验证或权威知识库对比来评估准确性。例如,监控品牌在AI答案中的出现时,准确性阈值可确保对您内容的引用或参考是事实正确且归属得当。实施质量阈值的组织通常对通用内容设定85-90%的最低准确分数,对专业领域则要求95%以上。
相关性衡量AI生成内容对用户实际意图和查询的回应程度。即使回答语法完美、事实准确,如果未能直接回应用户需求,也算失败。相关性阈值通常评估内容结构、语气和信息层级是否与底层搜索意图一致。
现代AI内容评分系统通过多重视角分析相关性:主题覆盖度(是否涉及所有问题点?)、受众匹配度(表达层级是否合适?)、用户旅程阶段(内容是否适合研究、对比或决策等不同阶段?)。相关性阈值常在70-85%之间,考虑到某些边缘信息在特定语境下是可接受的。
连贯性指内容的结构质量和逻辑流畅性。AI系统必须生成自然流畅、句子结构清晰、语气一致、思想有序的文本。可读性指标则衡量人类对内容的理解难易程度,通常通过Flesch-Kincaid或Gunning Fog等可读性分数衡量。
连贯性阈值通常针对目标受众设定最低可读性分数。面对大众,Flesch阅读容易度得分为60-70较为典型;技术受众则可接受更低分数(40-50),前提是内容足够专业。连贯性阈值还会评估段落结构、过渡质量以及标题和格式的清晰度。
原创性确保AI生成内容不是简单复制或改写现有材料且未注明出处。此维度对维护品牌声音和避免版权纠纷尤为重要。质量阈值通常要求原创性得分在85-95%之间,即85-95%的内容应为独创或实质性改写。
抄袭检测工具会衡量内容与现有来源的匹配百分比。但阈值设定需考虑对常用短语、行业术语和不可更改的事实信息的合理复用。关键在于区分可接受的改写与有问题的复制。
品牌声音一致性衡量AI生成内容是否保持了组织独特的语调、风格和信息传递准则。该维度对在搜索引擎、答案平台等各接触点上维护品牌识别和信任至关重要。
品牌声音的质量阈值多为定性,但可通过具体标准实现:词汇选择、句式模式、情感色彩、品牌信息原则等。组织通常设定80-90%的品牌声音一致性阈值,既留有灵活度,又保证核心身份。
伦理安全涵盖多个方面:无有害刻板印象、无冒犯性语言、无偏见假设,以及避免内容被误用或造成伤害。随着组织日益重视防止AI系统放大社会偏见或生成有害内容,这一维度变得愈发重要。
伦理安全的质量阈值通常为二元或近乎二元(要求95-100%),因为即便极少量的偏见或有害内容也可能损害品牌声誉并违反伦理原则。评估方法包括自动偏见检测工具、多元化人工审核、跨不同人口背景的测试等。
现代质量阈值体系采用多项自动化指标大规模评估AI内容,包括:
| 指标类型 | 测量内容 | 阈值范围 | 应用场景 |
|---|---|---|---|
| BLEU/ROUGE分数 | 与参考文本的N-gram重叠 | 0.3-0.7 | 机器翻译、摘要 |
| BERTScore | 基于嵌入的语义相似度 | 0.7-0.9 | 通用内容质量 |
| 困惑度(Perplexity) | 语言模型预测置信度 | 越低越好 | 流利度评估 |
| 可读性分数 | 文本理解难度 | 60-70(大众) | 可访问性评估 |
| 抄袭检测 | 原创百分比 | 85-95%独创 | 版权合规 |
| 有害性分数 | 有害语言检测 | <0.1(0-1) | 安全保障 |
| 偏见检测 | 刻板印象与公平性评估 | >0.9公平性 | 伦理合规 |
这些自动化指标提供了定量、可扩展的评估,但也有局限。传统如BLEU与ROUGE难以捕捉大模型输出的语义细节,而BERTScore等新指标虽更好反映意义,但也可能遗漏领域特定的质量问题。
更先进的方法是利用大语言模型自身作为评审者,借助其强大的推理能力。这一方法称为LLM-as-a-Judge,采用G-Eval、DAG(有向无环图)等框架,通过自然语言评价标准评估内容质量。
G-Eval通过链式思考生成评价步骤后再打分。例如,评估内容连贯性时包括:(1)定义连贯标准,(2)生成评价步骤,(3)将步骤应用于内容,(4)给出1-5分。这种方法与人工判断的相关性更高(Spearman相关系数常达0.8-0.95),优于传统指标。
DAG评估法则用大语言模型驱动的决策树,每个节点代表一个评价标准,边代表决策。这在质量阈值有明确、可判定要求(如“内容必须按照特定顺序包含特定部分”)时尤其适用。
尽管自动化进步显著,人工评估仍是不可或缺的,用于判断创造力、情感共鸣、语境适宜性等复杂属性。质量阈值体系通常在多个层级引入人工复审:
人工评审者通常依据包含具体标准和评分规则的评价表进行评估,确保各评审员之间的一致性。判者间一致性(用Cohen’s Kappa或Fleiss’ Kappa衡量)应高于0.70,质量阈值才被视为可靠。
质量阈值并非一刀切,需针对具体场景、行业和用例定制。简单的FAQ得分低于综合指南是自然现象,只要阈值设定得当即可。
不同行业标准各异:
与其追踪数十个指标,成熟的质量阈值体系通常关注5项核心指标:1-2个与你用例相关的定制指标和3-4个通用指标。这种做法兼顾全面性和可管理性。
例如,监控品牌在AI答案中的出现情况可用如下指标:
质量阈值通常以0-100为尺度,但解释需讲究情境。得分78并不意味着“不合格”——还需结合标准和场景。组织常设阈值区间而非固定分数线:
这些区间实现了灵活的质量治理。有的组织发布前最低阈值为80,有的则以70为审核底线,具体取决于风险承受度和内容类型。
当您的品牌、域名或URL出现在ChatGPT、Perplexity等AI生成的答案中时,质量阈值对品牌保护极为关键。低质量引用、错误描述或归属不清的内容可能损害声誉并误导用户。
品牌监控的质量阈值通常聚焦于:
组织在为AI答案监控建立质量阈值体系时应:
这一系统化方法可确保您的品牌在所有AI平台上持续维持质量标准,保护声誉,确保用户在AI生成答案中获得准确表达。
AI内容质量阈值远不止一个简单分数,它是确保AI生成内容在准确性、相关性、连贯性、原创性、品牌一致性和伦理安全等方面符合组织标准的全面框架。通过结合自动化指标、基于LLM的评估与人工判断,组织能够建立可扩展且可靠的质量阈值。无论您是自制内容还是监控品牌在AI答案引擎中的展现,理解并实施合适的质量阈值都是维护信任、保护声誉和确保AI内容有效服务受众的基础。
社区讨论 AI 搜索引用内容的质量要求。了解 ChatGPT、Perplexity 及其他 AI 平台对内容需要满足的质量门槛。
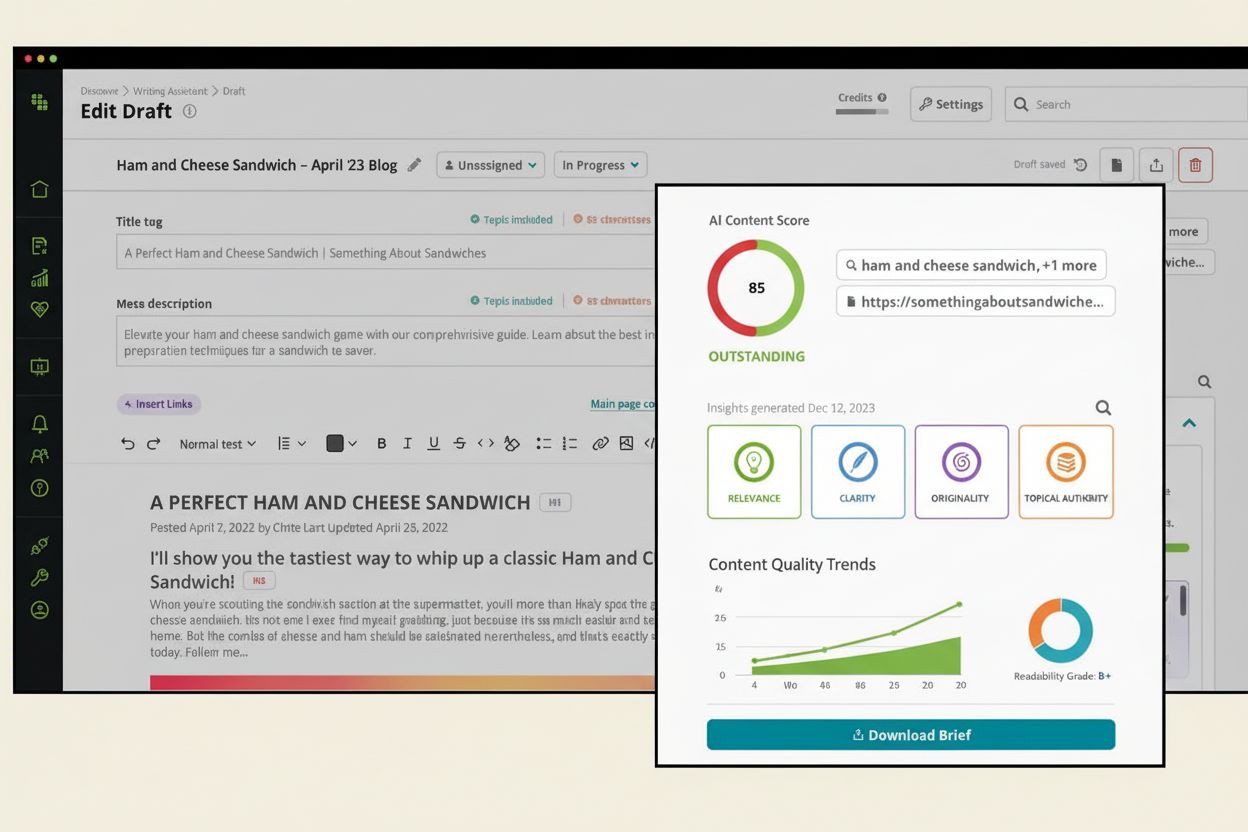
了解什么是AI内容评分、其如何评估AI系统的内容质量,以及为什么它对ChatGPT、Perplexity和其他AI平台的可见性至关重要。

Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.