AI 能访问受限内容吗?方法与影响
了解 AI 系统如何访问付费墙和受限内容、所用技术,以及如何在确保品牌 AI 可见度的同时保护您的内容。
2 分钟阅读
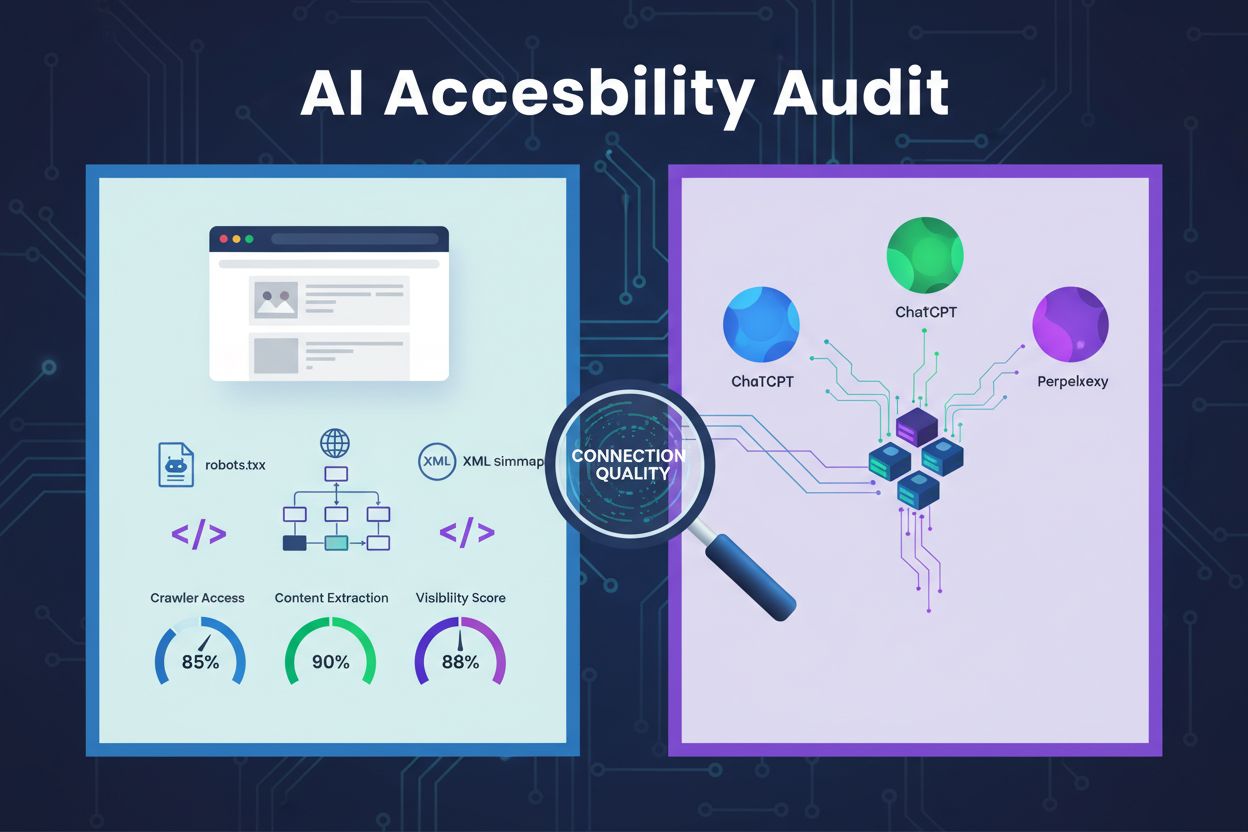
对网站架构、配置和内容结构进行技术审查,以确定 AI 爬虫是否能够有效访问、理解并提取内容。评估 robots.txt 配置、XML 站点地图、网站可爬取性、JavaScript 渲染以及内容提取能力,确保在 ChatGPT、Claude 和 Perplexity 等 AI 驱动的搜索平台上的可见性。
对网站架构、配置和内容结构进行技术审查,以确定 AI 爬虫是否能够有效访问、理解并提取内容。评估 robots.txt 配置、XML 站点地图、网站可爬取性、JavaScript 渲染以及内容提取能力,确保在 ChatGPT、Claude 和 Perplexity 等 AI 驱动的搜索平台上的可见性。
AI 可访问性审查是一种针对您网站架构、配置和内容结构的技术评估,旨在确定AI 爬虫是否能够有效访问、理解并提取您的内容。与聚焦关键词排名和外链的传统SEO 审查不同,AI 可访问性审查关注能否为 ChatGPT、Claude 和 Perplexity 等 AI 系统发现并引用您的内容提供坚实的技术基础。该审查评估包括robots.txt 配置、XML 站点地图、网站可爬取性、JavaScript 渲染以及内容提取能力等关键组件,确保您的网站在 AI 驱动的搜索生态中可完全被发现。
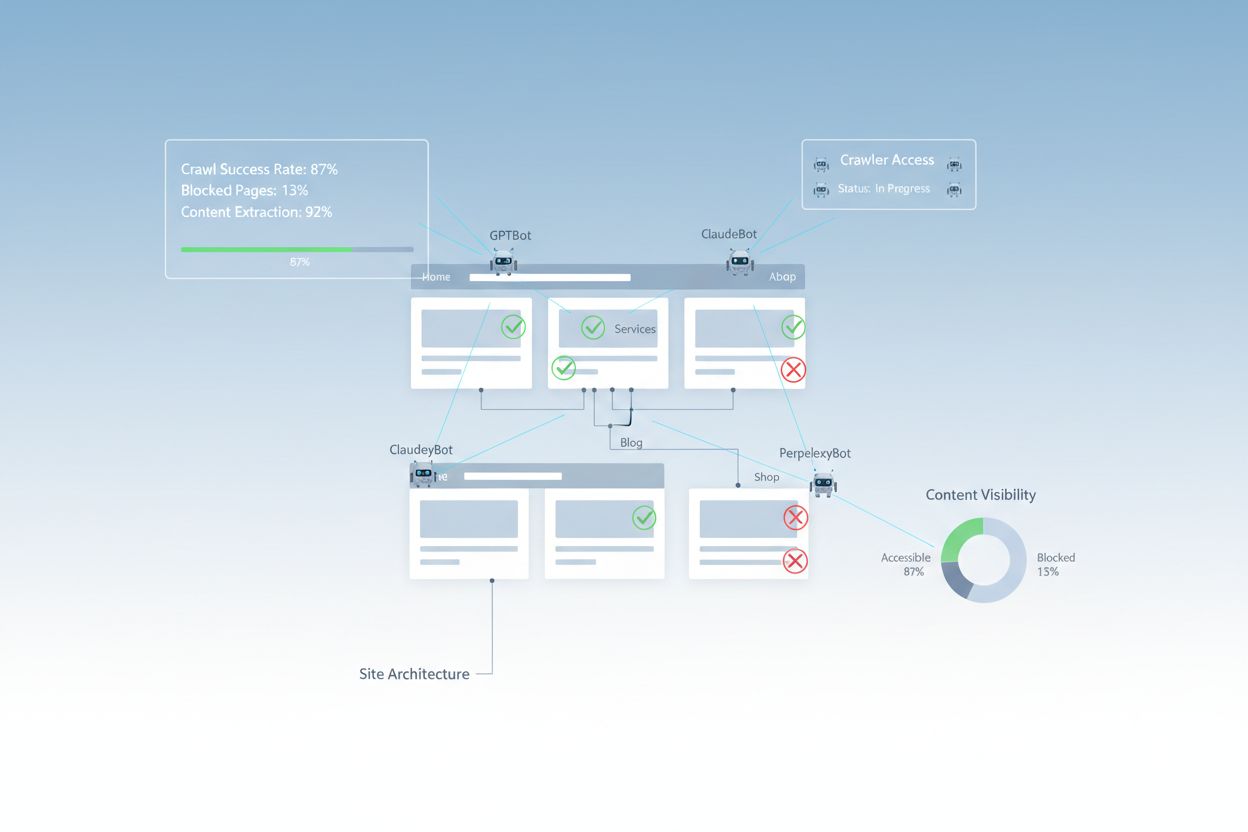
尽管网络技术不断进步,AI 爬虫在访问现代网站时仍面临诸多障碍。主要难点在于,许多当代网站高度依赖JavaScript 渲染来动态显示内容,但大多数 AI 爬虫无法执行 JavaScript 代码。这意味着约60-90% 的现代网站内容对 AI 系统来说是不可见的,尽管在用户浏览器中显示正常。此外,像Cloudflare 这样的安全工具默认会阻止 AI 爬虫,将其视为潜在威胁而非合法索引机器人。研究显示,35% 的企业网站无意中阻止了 AI 爬虫,导致有价值的内容无法被 AI 系统发现和引用。
阻碍 AI 爬虫访问的常见障碍包括:
全面的 AI 可访问性审查会检查多项技术与结构性因素,这些因素决定了 AI 系统如何与您的网站交互。每一要素都在内容能否被 AI 搜索平台发现上起着独特作用。审查流程涵盖可爬取性测试、配置文件核查、内容结构评估及实际爬虫行为监控。通过系统性分析这些要素,您可识别具体障碍并实施有针对性的解决方案,提升 AI 可见性。
| 要素 | 作用 | 对 AI 可见性的影响 |
|---|---|---|
| robots.txt 配置 | 控制哪些爬虫可访问特定站点区域 | 关键 - 配置失误将完全阻止 AI 爬虫 |
| XML 站点地图 | 指引爬虫发现重要页面与内容结构 | 高 - 帮助 AI 系统优先索引关键内容 |
| 网站可爬取性 | 确保页面无需认证或复杂导航即可访问 | 关键 - 被阻断页面对 AI 系统完全不可见 |
| JavaScript 渲染 | 决定动态内容对爬虫的可见性 | 关键 - 若未预渲染,60-90% 内容可能被遗漏 |
| 内容提取 | 评估 AI 是否易于解析与理解内容 | 高 - 结构不佳降低被引用概率 |
| 安全工具配置 | 管理防火墙及保护规则对爬虫的影响 | 关键 - 过于严格会阻断合法 AI 机器人 |
| schema 标记实施 | 提供内容的机器可读上下文 | 中 - 提升 AI 理解与引用可能性 |
| 内部链接结构 | 建立页面间语义关系 | 中 - 有助于 AI 理解主题权威与相关性 |
您的robots.txt 文件是控制哪些爬虫可访问您网站的主要机制。该文件位于域名根目录,通过简单指令告知爬虫哪些区域允许或禁止访问。对于 AI 可访问性而言,正确配置 robots.txt 至关重要,否则可能完全阻止如GPTBot(OpenAI)、ClaudeBot(Anthropic)、PerplexityBot(Perplexity)等主流 AI 爬虫。关键在于明确允许这些爬虫,同时通过禁止恶意机器人和保护敏感区域来维护安全。
AI 爬虫推荐 robots.txt 配置示例:
# 允许所有 AI 爬虫
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: ClaudeBot
User-agent: Claude-Web
User-agent: PerplexityBot
User-agent: Google-Extended
Allow: /
# 阻止敏感区域
Disallow: /admin/
Disallow: /private/
Disallow: /api/
# 站点地图
Sitemap: https://yoursite.com/sitemap.xml
Sitemap: https://yoursite.com/ai-sitemap.xml
此配置明确允许主流 AI 爬虫访问您的公开内容,同时保护管理和私有区域。Sitemap 指令可帮助爬虫高效发现重要页面。
XML 站点地图相当于爬虫的路线图,列出您希望被索引的 URL,并为每个页面提供元数据。对 AI 系统而言,站点地图尤为重要,因为它们帮助爬虫理解网站结构、优先索引重要内容,并发现通过常规链接可能遗漏的页面。与传统搜索引擎可通过链接推断结构不同,AI 爬虫极需明确指示哪些页面最关键。结构良好、元数据完善的站点地图可显著提升内容被 AI 发现、理解与引用的几率。
AI 优化的 XML 站点地图结构示例:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<!-- 供 AI 爬虫优先索引的重要内容 -->
<url>
<loc>https://yoursite.com/about</loc>
<lastmod>2025-01-03</lastmod>
<priority>1.0</priority>
</url>
<url>
<loc>https://yoursite.com/products</loc>
<lastmod>2025-01-03</lastmod>
<priority>0.9</priority>
</url>
<url>
<loc>https://yoursite.com/blog/ai-guide</loc>
<lastmod>2025-01-02</lastmod>
<priority>0.8</priority>
</url>
<url>
<loc>https://yoursite.com/faq</loc>
<lastmod>2025-01-01</lastmod>
<priority>0.7</priority>
</url>
</urlset>
priority 属性向 AI 爬虫指示页面重要性,lastmod 则体现内容新鲜度,有助于 AI 系统合理分配爬取资源、理解内容层级。
除配置文件外,还有多种技术障碍会阻止 AI 爬虫有效访问内容。JavaScript 渲染是最大挑战,现代前端框架如 React、Vue、Angular 常在浏览器动态渲染内容,导致 AI 爬虫只能获取空白 HTML。Cloudflare 及类似安全工具也常默认阻止 AI 爬虫,认为高频请求为攻击。限速会阻碍全面索引,复杂的网站架构和动态内容加载则进一步加大访问难度。幸运的是,现有多种方案可突破这些障碍。
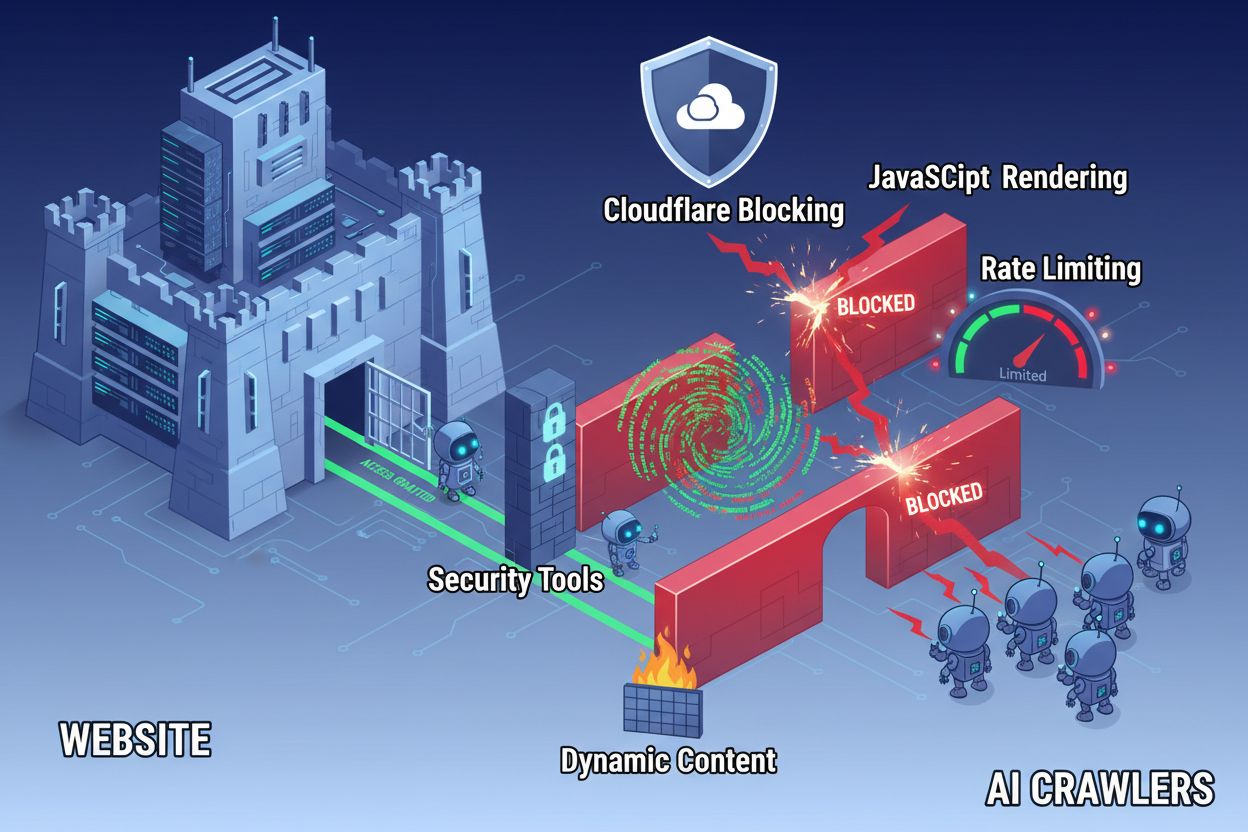
提升 AI 爬虫访问能力的方案:
AI 系统不仅要访问您的内容,还要理解它。内容提取指 AI 爬虫能否高效解析、理解并提取页面中的有价值信息。这一过程极依赖于语义化 HTML 结构,即采用规范的标题层级、描述性文本和逻辑清晰的组织方式。当您的内容结构合理,标题(H1、H2、H3)清晰、段落描述准确且逻辑流畅时,AI 系统更易识别关键信息和理解上下文。此外,schema 标记为 AI 系统提供机器可读元数据,极大提升其对内容的理解与引用几率。
良好的语义结构还包括使用如 <article>、<section>、<nav>、<aside> 等语义化 HTML 元素,而非泛用 <div>。这有助于 AI 理解不同内容区块的功能与重要性。结合 FAQ、产品、组织等结构化数据,您的内容将大幅提升对 AI 系统的可访问性,更易在 AI 生成的答案中被引用。
完成优化后,您还需验证 AI 爬虫实际访问情况,并持续监控表现。服务器日志可直接反映爬虫活动,显示哪些机器人访问了哪些页面,是否遇到错误。Google Search Console 展示谷歌爬虫与您站点的交互情况,而专业AI 可见性监控工具可追踪您的内容在不同 AI 平台的展现情况。AmICited.com 可专门监控 ChatGPT、Perplexity、Google AI Overviews 等 AI 系统对您品牌的引用频次及页面分布。
监控 AI 爬虫访问的工具与方法:
优化网站以提升 AI 爬虫访问,需要战略性、持续性的投入。与其将 AI 可访问性视为一次性项目,成功的组织都建立了持续监控与改进机制。最有效的策略是在做好技术配置的同时,优化内容,实现基础设施与内容的双重 AI 适配。
AI 可访问性优化建议:
AI 可访问性注意事项:
最成功的 AI 可访问性策略,是将爬虫视为内容分发的伙伴而非威胁。只要确保网站技术扎实、配置得当且语义清晰,您就最大化了 AI 系统发现、理解并在用户答案中引用您内容的概率。
AI 可访问性审查关注语义结构、机器可读内容以及对 AI 系统的引用价值,而传统 SEO 审查更强调关键词、外链和搜索排名。AI 审查检查爬虫是否能够访问和理解您的内容,而 SEO 审查则关注谷歌搜索排名的影响因素。
检查您的服务器日志,查找如 GPTBot、ClaudeBot 与 PerplexityBot 等 AI 爬虫的用户代理。使用 Google Search Console 监控爬取活动,利用验证工具测试 robots.txt 文件,并使用如 AmICited 这样的专业平台跟踪 AI 系统在不同平台上对您内容的引用情况。
最常见的障碍包括 JavaScript 渲染限制(AI 爬虫无法执行 JavaScript)、Cloudflare 和安全工具的阻拦(35% 的企业网站会阻止 AI 爬虫)、限速导致索引不全面、复杂的网站架构以及动态内容加载。每种障碍都需要不同的解决方案。
大多数企业允许 AI 爬虫访问会带来品牌在 AI 搜索结果和对话界面中的可见性提升。但最终决策取决于您的内容策略、竞争定位和业务目标。您可以使用 robots.txt 有选择地允许某些爬虫,同时根据实际需求阻止其他爬虫。
建议每季度进行一次全面审查,或在网站架构、内容策略或安全配置有重大变更时进行。持续通过服务器日志和专业工具监控爬虫活动。每当上线新内容板块或更改 URL 结构时,及时更新 robots.txt 和站点地图。
robots.txt 是控制 AI 爬虫访问的主要机制。正确配置可明确允许主要 AI 爬虫(如 GPTBot、ClaudeBot、PerplexityBot)访问,同时保护敏感区域。错误配置则可能完全阻止 AI 爬虫,无论内容质量如何,AI 系统都无法获取。
虽然技术优化很重要,但也可通过内容优化提升 AI 可见性——采用语义化 HTML 结构,实施 schema 标记,优化内部链接,确保内容完整性。但 JavaScript 渲染和安全工具阻拦等技术障碍,仍需通过技术手段彻底解决。
可通过服务器日志分析爬虫活动,使用 Google Search Console 获取爬取统计,robots.txt 验证工具核查配置,schema 标记验证器检查结构化数据,以及像 AmICited 这样的专业平台监控 AI 引用。许多 SEO 工具如 Screaming Frog 也能模拟爬虫测试 AI 可访问性。
使用 AmICited 跟踪 ChatGPT、Perplexity、Google AI Overviews 及其他 AI 系统对您的品牌引用情况。获取实时 AI 搜索可见性洞察,优化您的内容策略。
了解 AI 系统如何访问付费墙和受限内容、所用技术,以及如何在确保品牌 AI 可见度的同时保护您的内容。
了解如何测试像 ChatGPT、Claude 和 Perplexity 这样的 AI 爬虫是否可以访问你的网站内容。发现测试方法、工具以及 AI 可抓取性监控的最佳实践。...
了解如何让 ChatGPT、Perplexity 以及谷歌 AI 等 AI 爬虫能够看到你的内容。发现针对 AI 搜索可见性的技术要求、最佳实践以及监控策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.