
AI 如何理解实体:技术深度解析
探索 AI 系统如何在文本中识别和处理实体。了解 NER 模型、Transformer 架构,以及实体理解的实际应用场景。
1 分钟阅读

实体消歧义是指在多个实体拥有相同名称时,判断某个具体提及指的是哪一个实体的过程。它通过解决命名实体引用中的歧义,帮助AI系统准确理解和引用内容,确保“Apple”的提及能够正确识别是指Apple公司、水果,还是其他同名实体。
实体消歧义是指在多个实体拥有相同名称时,判断某个具体提及指的是哪一个实体的过程。它通过解决命名实体引用中的歧义,帮助AI系统准确理解和引用内容,确保“Apple”的提及能够正确识别是指Apple公司、水果,还是其他同名实体。
实体消歧义是指在多个同名或相似实体存在时,判断某个具体提及到底指向哪一个实体的过程。在人工智能和自然语言处理(NLP)领域,实体消歧义确保AI系统在遇到文本中的命名实体时,能正确识别其所指的现实世界对象、人物、组织或地点。这与**命名实体识别(NER)**有本质区别,NER只是识别实体的存在并将其归类为“人”、“组织”或“地点”等类别,回答“这里有实体吗?”,而实体消歧义则要回答“具体是哪一个实体?”。例如,在句子“Apple was the brain-child of Steve Jobs”中,NER能把“Apple”识别为组织,但实体消歧义需判断它指的是科技公司Apple Inc.还是其他同名实体。这一差异对需要准确理解和引用内容的AI系统至关重要,因此AmICited.com会监测ChatGPT、Perplexity和Google AI Overviews等AI系统在生成关于品牌和组织的回答时如何处理实体消歧义。
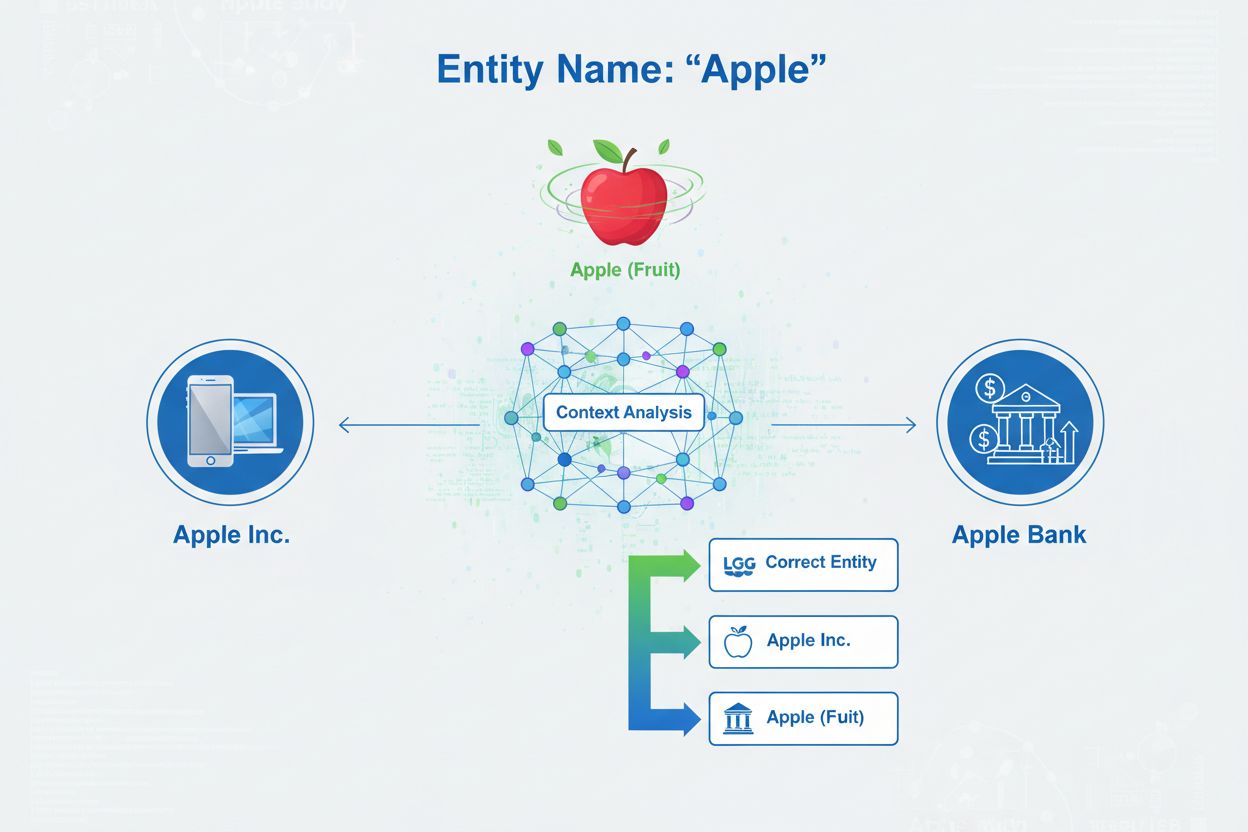
实体消歧义要解决的根本问题是歧义——许多实体名称可能指代多个不同的现实对象。这种歧义给AI系统的理解和内容生成带来了重大挑战。根据斯坦福AI指数2024,涉及品牌实体的LLM输出中,超过18%存在幻觉或实体误归属,即AI系统常常混淆不同实体或生成虚假的实体信息。这种错误对品牌形象和内容准确性影响巨大。如果AI系统误识别实体,就可能提供错误信息、将说法归属于错误的组织,或未能正确引用信息来源。
| 实体名称 | 可能含义 | AI混淆率 |
|---|---|---|
| Apple | 科技公司 / 水果 / 银行 | 高 |
| Delta | 航空公司 / 水龙头公司 / 希腊字母 | 高 |
| Jaguar | 汽车制造商 / 动物物种 | 中 |
| Amazon | 电商公司 / 雨林 / 河流 | 高 |
| Orange | 颜色 / 水果 / 电信公司 | 中 |
糟糕的实体消歧义不仅是简单的事实错误。对于内容创作者和品牌来说,AI生成内容中的误识别可能导致曝光损失、归属错误,甚至损害品牌声誉。当用户向AI系统询问“Delta”时,可能想了解达美航空,而系统却将其与Delta水龙头公司混淆,导致返回无关信息。这正是AmICited.com监测AI系统实体消歧的意义所在——帮助品牌了解自己是否在多平台AI内容中被准确识别和引用。
实体消歧义通过系统化流程,结合多种NLP技术来消除歧义、准确识别实体。理解这一流程,有助于解释为何有些AI系统在引用准确性上表现更佳。
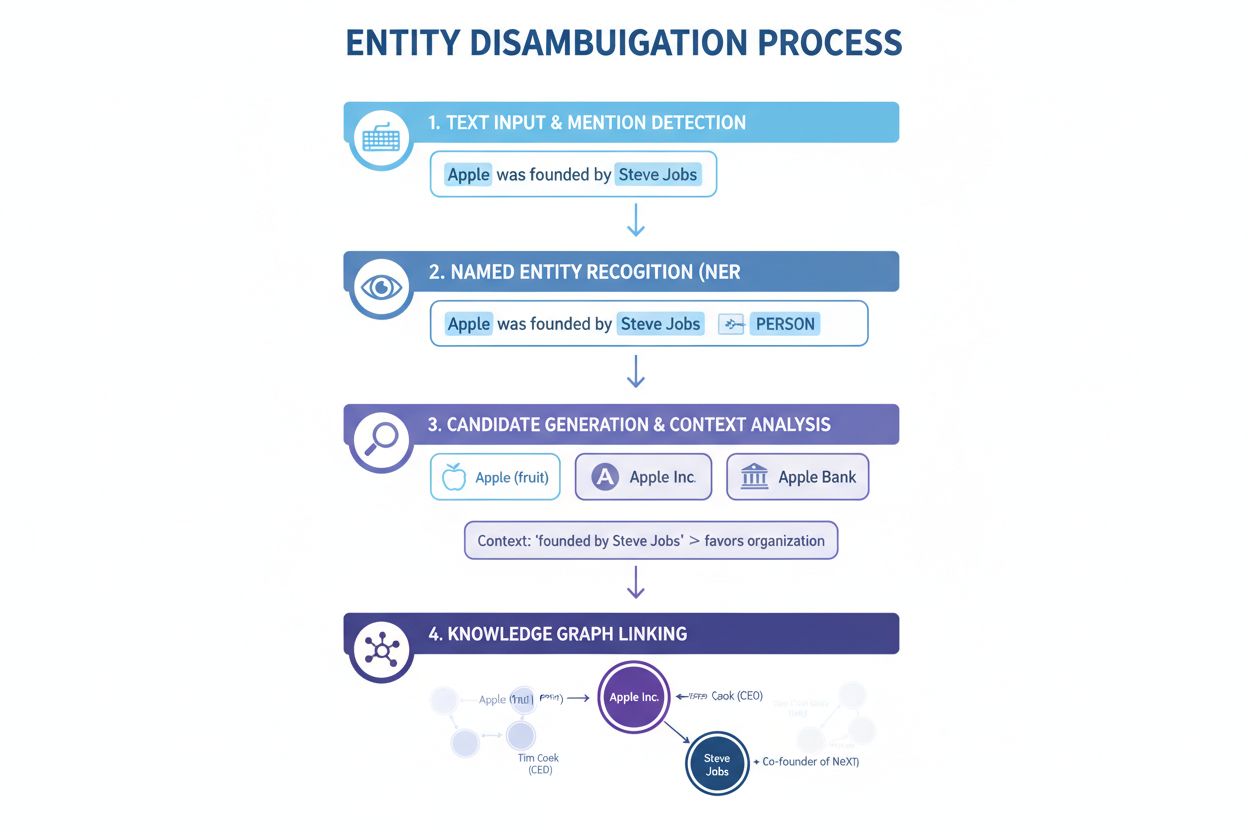
命名实体识别(NER):第一步是在文本中识别和分类命名实体。NER系统扫描文本,定位实体提及,并将其分配到如人、组织、地点、产品或日期等预设类别。比如在“Apple was the brain-child of Steve Jobs”这句话中,NER会识别“Apple”和“Steve Jobs”为实体,并分别归类为组织和个人。这是消歧的基础步骤,因为只有先识别出实体,才能进行后续消歧。
实体精细分类:识别出实体后,需要更精细地分类。这不仅是宽泛的归类,更要结合具体类型和上下文。系统分析上下文,判断“Apple”是在科技语境(暗示Apple公司)、食品语境(暗示水果)、还是金融语境(暗示Apple Bank)出现。这样的上下文分析有助于缩小候选范围,为后续消歧做准备。
消歧判定:这是核心步骤,系统要从多个同名实体中判定具体指向。系统会评估所有候选实体,利用上下文、实体描述、语义关系、知识图谱等信息,选择最可能正确的实体。例如,“Apple was the brain-child of Steve Jobs”中,系统识别到Steve Jobs与Apple公司高度相关,因此选择Apple Inc.作为正确答案。
知识库链接:最后一步是将已消歧的实体链接到外部知识库或知识图谱中的唯一标识,如Wikidata、Wikipedia或专有数据库。这一步确认了实体身份,并为后续处理和分析赋予语义信息。实体会被分配一个唯一的URI(统一资源标识符)作为最终指向。
实体消歧义的方法历经发展,各有优劣。理解这些方法有助于解释为何现代AI系统消歧准确率不同。
基于规则的方法:利用预设的语言规则和启发式模式进行消歧。例如:“Apple”若出现在“iPhone”或“MacBook”附近,则指Apple公司;“Delta”若出现在“airline”或“flight”附近,则指航空公司。此类系统可解释性强,无需大规模训练数据,但难以应对新场景,且需人工维护规则。
机器学习方法:有监督机器学习模型通过带标注数据学习如何根据上下文特征判定正确实体。这类系统提取文本上下文特征,利用支持向量机、随机森林等算法分类。机器学习方法比基于规则的系统灵活,但需要大量标注数据,对未见过的实体泛化能力有限。
深度学习与Transformer模型:现代消歧系统多采用BERT、RoBERTa等Transformer架构,或专用模型如GENRE、BLINK。这些模型能深入理解上下文,把握语义关系和复杂语言模式。Transformer模型在标准评测上表现优异,能更好地处理复杂的消歧场景。例如,Ontotext的CEEL系统采用优化的Transformer架构,在标准基准上实现了96%的实体识别准确率和76%的实体链接准确率。
知识图谱融合:现代系统越来越多地将机器学习与知识图谱结合。知识图谱提供丰富的实体属性和关系,通过在消歧时查询知识图谱,系统能获得元数据、描述和关系信息,从而更准确地消除歧义。
实体消歧义已成为众多行业和场景不可或缺的一环,各领域都因准确的实体识别与引用而受益。
搜索引擎:Google、Bing等搜索引擎高度依赖实体消歧返回相关结果。当用户搜索“Apple”时,系统必须判断其意图是Apple公司、水果还是其他实体。搜索引擎结合查询上下文、用户历史和知识图谱进行消歧,因此“Apple”的搜索结果通常优先显示科技公司,这是因为系统学习到这是最常见的意图。
媒体与出版:新闻机构和内容平台利用实体消歧提升内容可发现性和相关文章的关联。当新闻报道提及“Apple”时,系统可自动链接到Apple公司的知识库条目,为读者提供更多上下文和相关报道,提升用户粘性和理解广度。
医疗健康:医疗机构用实体消歧准确识别病历和文献中的药品、疾病及医疗操作,尤其是药品名消歧至关重要——“aspirin”可能指通用药品、品牌名或不同剂型。准确消歧确保医务人员获取正确信息,病历得以规范整理。
金融服务:投资机构和分析师用实体消歧追踪公司在新闻、财报和市场数据中的提及。在分析市场风险时,需准确识别所有与某公司相关的提及。消歧确保“Apple”归属于Apple公司,助力风险评估和投资分析。
电商平台:在线零售商用实体消歧将产品提及与实际目录商品匹配。顾客搜索“Apple laptop”时,系统需将“Apple”消歧为公司并匹配到相应产品,从而提升搜索准确率和用户体验。
AmICited.com将实体消歧原理应用于监测ChatGPT、Perplexity、Google AI Overviews等AI系统对品牌提及的处理。通过追踪这些系统是否正确消歧并准确引用品牌实体,AmICited帮助品牌了解自身在AI生成内容中的可见性与展现。
知识图谱已成为现代实体消歧系统的基础,为实体及其关系提供结构化表达。知识图谱本质上是实体(节点)及其关系(边)的数据库。每个实体节点包含如名称、描述、类型、属性等元数据。例如,知识图谱中的“Apple Inc.”实体节点可包含“1976年成立”、“总部库比蒂诺”、“行业:科技”等属性,以及“创始人Steve Jobs”、“生产iPhone”等关系。
当消歧系统遇到模糊实体时,可查询知识图谱,获得候选实体的丰富上下文信息,辅助做出更明智的消歧决策。比如系统要消歧“Apple”,发现上下文提及“Steve Jobs”,可通过知识图谱得知Steve Jobs与Apple公司高度相关,从而判定为Apple Inc.。Wikidata、Wikipedia等公开知识图谱为众多AI系统提供实体信息,Google、Microsoft等机构自建的专有知识图谱则提供更多领域知识。知识图谱与机器学习的结合大幅提升了消歧准确率,让系统能融合模式学习与结构化事实信息。
尽管取得显著进步,实体消歧系统仍面临若干持久难题,限制其准确性和应用范围。
多义性与歧义:许多实体名称有多重含义,仅靠上下文未必能完全消歧。如“Bank”既可指银行,也可指河岸;“Crane”可指起重机或鹤。有些名称本身极易歧义,连人类也需更多上下文才能判断。AI系统必须学会识别上下文不足时的处理方式。
新兴实体:知识库和训练数据会随时间过时,新的公司或产品出现时,消歧系统可能没有相应信息。零样本实体链接(即消歧未见过的实体)依然是难题。系统需能识别新实体,并恰当处理,而不是误归现有实体。
名称变体与拼写错误:实体常有多种名称、缩写与变体,如“United States”、“USA”、“U.S.”、“America”都指同一实体。拼写错误更增加难度。系统需识别这些变体并映射到标准实体,尤其在用户生成内容中更为复杂。
数据不完整或过时:知识库可能信息不全,或因实体发展而过时。公司总部、领导层变化或被收购等,若知识库未及时更新,消歧系统就会依据过时信息做决策。
可扩展性与性能:大规模文本的高精度消歧需大量算力。对于Web级应用,实时消歧极其耗费资源。系统必须在准确率、速度和成本间权衡,这常导致消歧质量下降。
对于品牌和内容创作者而言,理解实体消歧义有助于确保自身在AI生成内容中被准确展现。随着AI系统在信息发现和消费中的影响力提升,品牌必须主动确保自身被正确消歧和引用。
前置消歧策略:品牌可采取措施,便于AI系统正确消歧自身实体,包括创建清晰、独特的数字信号,帮助AI明确识别品牌。其中,采用Schema.org结构化数据和JSON-LD格式在品牌官网标注关键信息,是重要手段。这类数据明确告知AI品牌的官方名称、描述、Logo、总部等特征,便于AI系统确认实体身份。
知识图谱优化:品牌应确保在Wikidata、Wikipedia等主流知识图谱中有强力存在,包括创建或维护准确的百科条目、完善Wikidata信息、建立与相关实体的关系等。知识图谱越完善,AI系统可用的消歧信息就越丰富。
内容上下文优化:品牌应制作能清晰展示自身身份、区分同名实体的内容。例如明确提及行业、产品、创始人、独特价值等,有助于AI系统理解品牌特性。这些内容也会成为AI训练和推理时的重要上下文。
引用监测:利用AmICited.com等工具,品牌可实时监测AI系统在各平台上的消歧和引用情况。追踪ChatGPT、Perplexity、Google AI Overviews等系统是否准确识别并引用品牌,有助于发现消歧错误并及时修正。这对于AI浪潮下的品牌可见性至关重要。
生成引擎优化(GEO):随着实体消歧对AI可见性的重要性提升,品牌应将实体优化纳入整体生成引擎优化战略。这不仅包括传统SEO,还包括让AI系统更容易区分、理解和引用品牌实体。
随着AI技术进步和新挑战出现,实体消歧义也在持续演化。以下趋势正在塑造这一关键能力的未来:
多语言消歧:AI系统日益全球化,跨语言消歧能力愈发重要。同一人名在不同语言中拼写不同,同一实体在不同语境下有不同称呼。先进的多语种模型正在开发,可实现跨语言消歧,推动全球化AI系统的发展。
大模型实时消歧:现代大模型如GPT-4、Claude等正逐步实现文本生成过程中的实时实体消歧。不再仅依赖训练数据,模型可在推理时实时查询知识图谱和外部数据库,验证实体信息,提高引用准确率,减少幻觉。
零样本学习提升:未来的消歧系统能更好地处理未见过的实体。随着小样本、零样本学习技术发展,系统在无需频繁再训练的前提下更好地消歧新实体,适应性更强。
检索增强生成(RAG)集成:结合检索和生成的系统逐渐流行。这类系统可在文本生成时检索知识库的相关实体信息,提升消歧和引用质量。这一集成将极大推动AI引用准确性的提升。
标准化与互操作性:随着实体消歧对AI系统的重要性提升,行业标准有望出台,规范实体表示和消歧方法,促进不同系统和知识库间的信息互操作,便于AI系统在多平台间一致访问和使用实体信息。
实体消歧义已从小众NLP任务演变为确保AI系统准确理解和表达信息的关键能力。随着AI在信息发现和消费中的作用日益突出,实体消歧义的重要性也将持续提升。对于品牌、内容创作者和组织来说,理解并优化实体消歧义,是在生成式AI时代保持可见性和准确展现的关键。
命名实体识别是在文本中识别出实体的存在,并将其分类为人、组织或地点等类别。实体消歧义则更进一步,判断在多个同名实体中,具体指的是哪一个。例如,NER会把“Apple”识别为一个组织,而实体消歧义会判断它指的是Apple公司、Apple Bank还是其他实体。
实体消歧义确保AI系统能准确理解讨论的是哪个实体,并正确引用。根据斯坦福AI指数2024,涉及品牌实体的LLM输出中有18%以上存在幻觉或误归属。准确的实体消歧义能防止AI系统混淆实体,这对维护品牌声誉和引用准确性至关重要。
知识图谱为实体及其关系提供结构化信息。当AI系统遇到模糊的实体提及时,可以查询知识图谱,获取候选实体的元数据、描述和关系信息。这些上下文信息有助于系统做出更明智的消歧决策,选择正确的实体。
可以,通过零样本实体链接方法。现代系统能识别新实体,并进行恰当处理,而不是错误地匹配到已存在的实体。但这仍是一个挑战性问题,系统在新实体有明显上下文信号时表现更好。
准确的实体消歧义确保您的品牌在AI生成的回答中被正确识别和引用。当AI系统正确区分您的品牌时,用户能获得关于您组织的准确信息,从而提升品牌可见性和声誉。消歧不当可能导致您的品牌与竞争对手或其他实体混淆,降低可见性甚至损害声誉。
主要挑战包括多义性(同名多义)、训练数据中没有的新实体、名称变体与拼写错误、知识库不完整或过时以及可扩展性问题。此外,有些实体名称本身就很模糊,仅靠上下文可能无法确定正确实体。
品牌可以采用Schema.org结构化数据、维护准确的维基百科和Wikidata词条、创建能清晰区分品牌的上下文内容,并通过AmICited等工具监测AI系统对品牌的消歧。这些策略有助于AI系统正确识别和引用您的品牌。
上下文对实体消歧义至关重要。周围文本、相关实体和语义关系都提供了信号,帮助AI系统判断指的是哪个实体。例如,“Apple”出现在“Steve Jobs”和“科技”附近,系统就能利用这些上下文将其正确消歧为Apple公司而非水果。
探索 AI 系统如何在文本中识别和处理实体。了解 NER 模型、Transformer 架构,以及实体理解的实际应用场景。

了解如何在AI搜索中提升实体可见性。掌握知识图谱优化、结构化数据标记和实体SEO策略,提升品牌在ChatGPT、Perplexity和Google AI Overviews中的影响力。...

社区讨论如何加强品牌实体以便AI识别。打造AI系统用来理解和推荐品牌的实体信号的策略。