Meta AI
Meta AI 是 Meta 的 AI 助手,已集成至 Facebook、Instagram、WhatsApp 及 Messenger。了解其工作方式、能力以及在 AI 监测和品牌可见性中的作用。...
3 分钟阅读
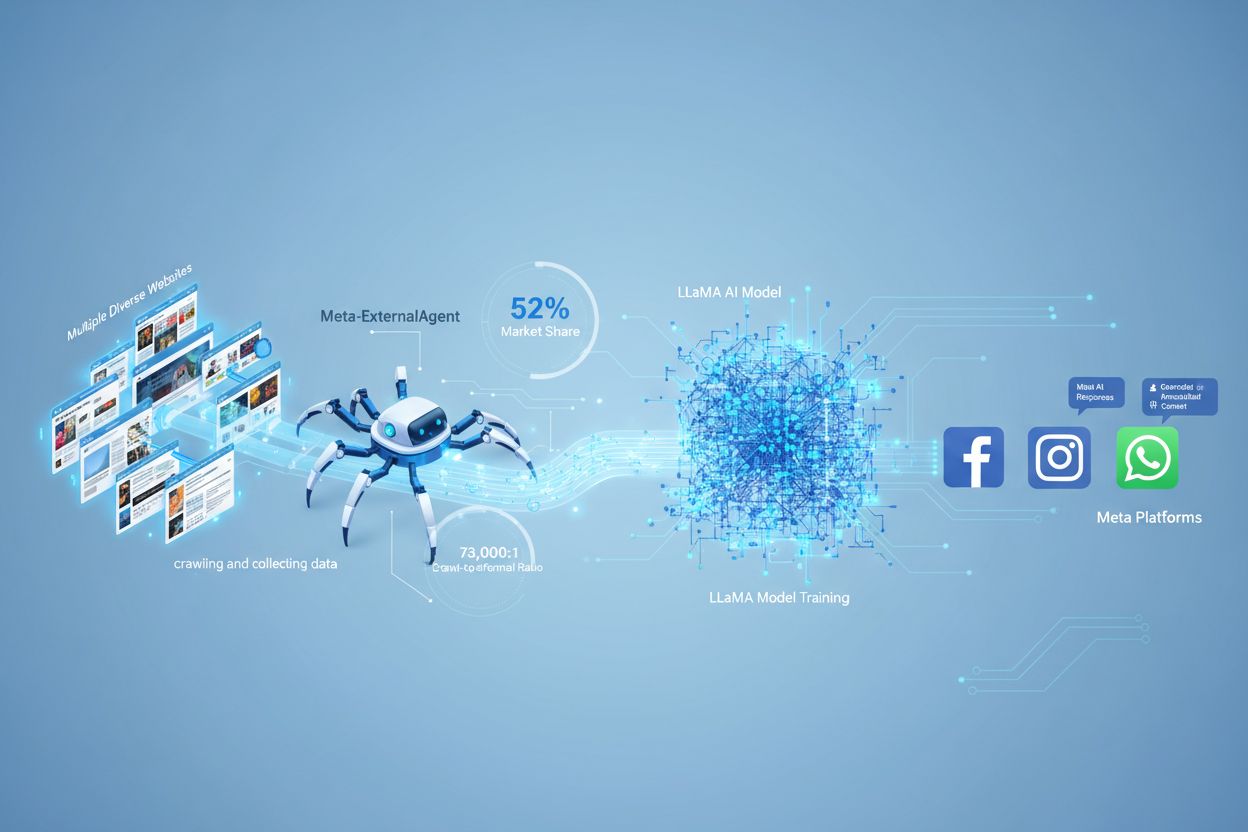
Meta-ExternalAgent 是 Meta 于 2024 年 7 月推出的网页爬虫机器人,用于收集公开内容以训练像 LLaMA 这样的 AI 模型。它通过 User-Agent 字符串 meta-externalagent/1.1 进行识别,并决定内容是否出现在 Facebook、Instagram 和 WhatsApp 的 Meta AI 回复中。发布者可以通过 robots.txt 或服务器级配置进行屏蔽,但遵守与否完全取决于自觉,且不具法律约束力。
Meta-ExternalAgent 是 Meta 于 2024 年 7 月推出的网页爬虫机器人,用于收集公开内容以训练像 LLaMA 这样的 AI 模型。它通过 User-Agent 字符串 meta-externalagent/1.1 进行识别,并决定内容是否出现在 Facebook、Instagram 和 WhatsApp 的 Meta AI 回复中。发布者可以通过 robots.txt 或服务器级配置进行屏蔽,但遵守与否完全取决于自觉,且不具法律约束力。
Meta-ExternalAgent 是 Meta Platforms 运营的网页爬虫,于 2024 年 7 月上线,用于收集数据以训练人工智能模型。该爬虫通过 User-Agent 字符串 meta-externalagent/1.1 进行识别,与 Meta 早期主要用于链接预览和社交分享功能的 facebookexternalhit 爬虫不同。Meta-ExternalAgent 标志着 Meta 在 AI 训练数据收集方式上的重大转变,目的是为 LLaMA 语言模型及集成于 Facebook、Instagram 和 WhatsApp 的 Meta AI 聊天机器人提供训练数据。与以往的 Meta 爬虫不同,该代理透明度极低,且部署时并未正式公开宣布。

Meta-ExternalAgent 是一款自动化机器人,会系统性地抓取互联网上的网站,以提取文本和内容用于 AI 模型训练。该爬虫通过向 Web 服务器发送 HTTP 请求、以独特的 User-Agent 头进行标识,并下载网页内容进行处理。内容被收集后,Meta 的系统会分析和分词,将其转换为训练数据,以提升自家大型语言模型的能力。该爬虫在自愿基础上遵守 robots.txt 文件,这是一种道德约定而非法律要求。根据 Cloudflare 数据,Meta-ExternalAgent 占据了全网 52% 的 AI 爬虫流量,成为 AI 行业中最为激进的数据收集操作之一。该爬虫持续运行,有些发布者报告其抓取频率之高,说明 Meta 更倾向于全面覆盖网络内容,而非有选择性地定向抓取。
| 爬虫名称 | User-Agent 字符串 | 主要用途 | 上线时间 | 数据用途 |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AI 模型训练(LLaMA、Meta AI) | 2024 年 7 月 | 生成式 AI 训练数据 |
| facebookexternalhit | facebookexternalhit/1.1 | 链接预览和社交分享 | 约 2010 年 | Open Graph 元数据、缩略图 |
| Facebot | facebot/1.0 | Facebook 应用内容验证 | 约 2015 年 | 移动应用内容验证 |
| Applebot | Applebot/0.1 | Apple Siri 与搜索索引 | 约 2015 年 | 搜索索引与语音助手 |
| Googlebot | Googlebot/2.1 | Google 搜索索引 | 约 1998 年 | 搜索引擎索引构建 |
Meta-ExternalAgent 对内容创作者和发布者来说是一个重要关注点,因为它以史无前例的规模运行,同时对内容如何被使用几乎没有透明度。根据 Cloudflare 研究,Meta-ExternalAgent 占据了 52% 的 AI 爬虫流量,远高于 OpenAI 的 GPTBot 和 Google 的 AI 爬虫。这种主导地位意味着 Meta 比任何其他 AI 公司都收集了更多的训练数据,但发布者在其内容被用于训练 Meta AI 模型时既得不到补偿,也没有署名。73,000:1 的抓取与引荐流量比例 说明 Meta 在大规模提取内容的同时,几乎不为源网站带来流量——这种价值交换极为失衡。尽管如此,只有 2% 的网站主动屏蔽 Meta-ExternalAgent,相比之下有 25% 屏蔽了 GPTBot,这表明许多发布者对该爬虫的存在及其影响尚不知情。随着 Meta 在 AI 基础设施上投入 400 亿美元,其数据收集力度很可能进一步加大,因此发布者有必要了解并积极管理与该爬虫的关系。
发布者可以通过 robots.txt 文件控制 Meta-ExternalAgent 的访问,但需明确,该机制依赖自觉,并不具法律效力。要屏蔽 Meta-ExternalAgent,请在 robots.txt 文件中添加如下指令:
User-agent: meta-externalagent
Disallow: /
如果希望允许爬虫访问但只限制特定目录,可以使用:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
然而,部分发布者报告称,即使配置了 robots.txt 屏蔽,Meta-ExternalAgent 仍在继续抓取其网站,说明 Meta 并不总是遵守这些指令。为了更全面的防护,发布者可通过基于 HTTP 头的拦截或利用 CDN 规则,根据 User-Agent 字符串识别并拒绝 Meta-ExternalAgent 的访问。此外,发布者还可通过检查服务器日志中的 meta-externalagent/1.1 User-Agent 字符串,确认爬虫是否访问了自己的网站。AmICited.com 等工具可帮助发布者追踪其内容是否被 Meta AI 回复引用,从而了解其作品在 Meta AI 系统中的使用情况。

当用户在 Facebook、Instagram 或 WhatsApp 上与 Meta AI 聊天机器人互动时,所生成的回复部分基于 Meta-ExternalAgent 收集的内容。然而,Meta AI 的回复通常不会向用户展示内容来源的引用或署名,用户无法得知哪些发布者的内容被用于生成答案。这种缺乏透明度给内容创作者带来了挑战,他们想要了解自己的作品为 Meta AI 系统提供了怎样的价值。与部分竞品在 AI 回复中包含引用不同,Meta 的做法更注重用户体验而非发布者署名。因缺少可见引用,发布者也难以追踪自己内容被 Meta AI 回复影响的频率,从而难以评估内容被用于 AI 训练的商业影响。这一可见性缺口是越来越多发布者寻求监控解决方案的主要原因,希望了解自己在 AI 生态中的角色。
发布者可通过服务器日志分析来验证 Meta-ExternalAgent 的活动,日志中可显示爬虫的 IP 地址、请求模式及内容访问频率。检查访问日志时,可查找 User-Agent 字符串为 meta-externalagent/1.1 的请求,判断哪些页面被频繁抓取。高级监控工具还可追踪长时间内的抓取模式,揭示 Meta 是否优先抓取某类内容或网站某些板块。发布者还应关注带宽使用情况,因为 Meta-ExternalAgent 的高频抓取可能大量消耗服务器资源,尤其是内容库庞大的网站。此外,可借助 AmICited.com 等工具,监控内容是否出现在 Meta AI 回复中,并追踪在 Meta 平台的引用分布。设置异常抓取活动提醒,有助于发布者及时发现 Meta 数据收集行为的变化并主动应对。定期审查服务器日志应成为发布者管理 AI 爬虫策略的一部分,确保对内容被访问及使用情况保持知情。
Meta-ExternalAgent 的法律地位仍存在争议,内容创作者、艺术家与出版方正在通过诉讼质疑 Meta 未经同意或补偿即将其作品用于 AI 训练的做法。Meta 认为网页抓取属于合理使用原则,但批评者指出,如此大规模且带商业目的的数据收集,并且没有署名,已经构成版权侵权。虽然 robots.txt 被广泛视为行业规范,但没有法律效力,Meta 并无强制义务遵守屏蔽指令。部分司法辖区正制定有关 AI 训练数据收集的法规,如欧盟 AI 法案及其它地区的立法,未来可能对 Meta 等公司提出更严格要求。从伦理角度看,核心问题是内容创作者是否有权控制其作品被商业 AI 训练使用,以及现行体系是否为内容价值提供了足够补偿。发布者应关注法律政策的变化,并考虑咨询法律顾问,明确自己在 AI 爬虫访问方面的权利与义务。如何在促进 AI 创新与保护创作者权益之间实现平衡,仍是尚未解决的领域,相关法律与监管正处于快速发展中。
随着发布者、监管者和 AI 公司就数据采集与使用条款不断协商,AI 爬虫管理的格局正在迅速演变。Meta 大举部署 Meta-ExternalAgent,表明大型科技公司将网络内容视为竞争性 AI 系统的核心训练材料,且这一趋势还将加速。未来可能会出现对创作者更强有力的法律保护、强制性 AI 训练数据许可框架,以及便于发布者控制和变现内容在 AI 系统中使用的技术标准。AmICited.com 等工具的兴起反映了内容创作者对 AI 系统使用已发布内容的透明度和问责制的需求日益增长,预计内容监控和验证将成为行业常态。随着 AI 行业的成熟,内容创作者与 AI 公司的协商将更为复杂,或将催生新的商业模式,实现内容发布者在 AI 训练中获得合理补偿。
Meta-ExternalAgent 是 Meta 于 2024 年 7 月推出的专用 AI 训练爬虫,通过 User-Agent 字符串 meta-externalagent/1.1 进行识别。它不同于 facebookexternalhit,后者用于生成社交分享的链接预览。Meta-ExternalAgent 专门收集内容用于训练 LLaMA 模型和 Meta AI,而 facebookexternalhit 自 2010 年左右起则用于社交功能。
您可以通过在 robots.txt 文件中添加指令来阻止 Meta-ExternalAgent。加入 'User-agent: meta-externalagent' 和 'Disallow: /' 可完全屏蔽。若需更全面保护,可通过 .htaccess(Apache)或 Nginx 配置规则实现服务器级拦截。但 robots.txt 仅为自愿遵守,并无法律约束力,因此部分发布者报告即使屏蔽后仍被爬取。
不会,屏蔽 Meta-ExternalAgent 不会影响 Facebook 链接预览。facebookexternalhit 爬虫负责链接预览和社交分享功能。您可以单独屏蔽 meta-externalagent,同时允许 facebookexternalhit 继续为 Meta 平台生成吸引人的内容预览。
Meta-ExternalAgent 的抓取与引荐流量比例约为 73,000:1,意味着 Meta 以极大规模提取内容,但几乎不为源网站带来访问流量。这与传统搜索引擎用抓取换取引荐流量形成根本性的不平衡。
robots.txt 属于自律机制,并无法律约束。虽然许多爬虫会遵守 robots.txt 指令,但部分发布者已报告 Meta-ExternalAgent 即使明确屏蔽后仍继续抓取。要彻底保护,可通过 HTTP 头、CDN 规则或防火墙配置实现服务器级拦截。
请查看您的服务器访问日志,查找 User-Agent 字符串 'meta-externalagent/1.1' 的请求。您也可以使用如 AmICited.com 这样的监控工具,跟踪您的内容是否出现在 Meta AI 回复中。Dark Visitors 和 Cloudflare Analytics 等工具还能进一步洞察 AI 爬虫在您网站的活动。
根据 Cloudflare 数据,Meta-ExternalAgent 占据全网 AI 爬虫流量的约 52%,是目前最为激进的 AI 数据收集操作。远超 OpenAI 的 GPTBot 和 Google 的 AI 爬虫,显示 Meta 在 AI 训练用网页内容收集上的主导地位。
这取决于您的业务优先级。如果 Meta AI 流量对您的受众有价值,您可以选择允许。但需注意,Meta 对用于 AI 训练的内容既无补偿也无署名。许多发布者采用选择性屏蔽策略,阻止 AI 训练,但保留社交分享的链接预览功能。
Meta AI 是 Meta 的 AI 助手,已集成至 Facebook、Instagram、WhatsApp 及 Messenger。了解其工作方式、能力以及在 AI 监测和品牌可见性中的作用。...

了解 Meta AI 优化如何通过 AI 驱动的自动化、实时竞价和智能受众定位,彻底改变 Facebook 和 Instagram 广告,实现最大化投资回报率。...

了解AI爬虫user-agent是什么、它们在HTTP通信中的工作方式,以及如何有效管控GPTBot、ClaudeBot、PerplexityBot等AI爬虫对网站的访问。...