
NoAI 元标记:通过头信息控制 AI 的访问权限
了解如何实现 noai 和 noimageai 元标签,以控制 AI 爬虫对您网站内容的访问。AI 访问控制头信息及实现方法的完整指南。
2 分钟阅读

一种 HTML 元标签,用于向 AI 训练系统和网络爬虫发出信号,表示网站内容不应被用于机器学习模型训练。最初由 DeviantArt 推出,它为创作者担忧未经授权的 AI 数据收集行为提供了一种内容保护机制和选择退出的信号。
一种 HTML 元标签,用于向 AI 训练系统和网络爬虫发出信号,表示网站内容不应被用于机器学习模型训练。最初由 DeviantArt 推出,它为创作者担忧未经授权的 AI 数据收集行为提供了一种内容保护机制和选择退出的信号。
NoAI 元标签是一种以 HTML 元标签形式实现的内容保护机制,用于向AI 训练系统和网络爬虫发出信号,指示网站内容不应被用于机器学习模型训练。NoAI 指令最早于 2022 年 9 月由 DeviantArt 推出,作为艺术家对其作品被抓取并在未获同意或补偿的情况下用于生成式 AI 模型训练的担忧的草根回应。这一元标签通过在网页头部添加简单的 HTML 声明,向 AI 系统明确传达内容不允许用于训练的意愿。虽然在大多数司法管辖区并无法律约束力,NoAI 标签却为创作者在日益激进的 AI 数据收集时代保护其知识产权提供了重要的选择退出机制。
网络爬虫(又称机器人、蜘蛛或抓取器)是自动化软件程序,系统性地浏览互联网,跟随链接下载内容以进行索引、分析或数据收集。爬虫通过读取网站根目录下的 robots.txt 文件,获知哪些区域可以或不可以被自动化访问者访问。robots.txt 文件通过 User-agent、Disallow 和 Allow 等指令告知爬虫权限,但是否遵守完全取决于爬虫开发者的自觉。除了 robots.txt,网站还可通过HTTP 头和元标签表达内容使用权和限制的额外信号。不同类型的爬虫对这些信号的尊重程度各异:
| 爬虫类型 | robots.txt 遵守情况 | 元标签遵守情况 | AI 训练用途 |
|---|---|---|---|
| 搜索引擎 | 高 | 高 | 有限 |
| AI 训练机器人 | 中 | 中 | 是 |
| 商业爬虫 | 低 | 低 | 不定 |
| 学术机器人 | 高 | 中 | 仅限研究 |
| 恶意机器人 | 无 | 无 | 无限制 |
noai 和 noimageai 指令用于内容保护,功能相关但范围和具体性不同。noai 指令是一种更广泛的信号,表示页面上的所有内容(包括文本、图片、代码及其他媒体)均不应被用于 AI 训练,适用于内容类型混合或需全面保护的网站。而 noimageai 指令仅针对图片内容,允许文本和其他非图片材料可被训练,同时保护视觉资产不被生成式图像模型使用。对于希望允许文本 AI 索引(如搜索引擎或辅助功能)但保护视觉内容的网站,这一区别尤为重要。以下为实现方式差异:
<!-- 全面保护所有内容 -->
<meta name="robots" content="noai">
<!-- 仅保护图片内容 -->
<meta name="robots" content="noimageai">
<!-- 组合方式最大化明确性 -->
<meta name="robots" content="noai, noimageai">
NoAI 元标签可通过多种方式实现,根据您的技术架构和具体需求各有优劣。最直接的方法是在 HTML <head> 部分直接添加元标签,对单独页面生效且可按需自定义。对于页面较多或希望全站生效的网站,通过HTTP 响应头实现该指令更具可扩展性,无需逐页修改即可统一应用。此外,robots.txt 文件也可包含针对特定 AI 爬虫的指令,尽管该方法的标准化程度不如元标签或头信息。三种主要实现方式如下:
<!-- 方法一:HTML 元标签(最常见) -->
<head>
<meta name="robots" content="noai">
</head>
# 方法二:robots.txt 指令
User-agent: *
Disallow: /
X-Robots-Tag: noai
# 方法三:HTTP 头(通过 .htaccess 或服务器配置)
X-Robots-Tag: noai
对于 Apache 服务器,请在 .htaccess 添加:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
对于 Nginx 服务器,在 server block 中添加:
add_header X-Robots-Tag "noai" always;
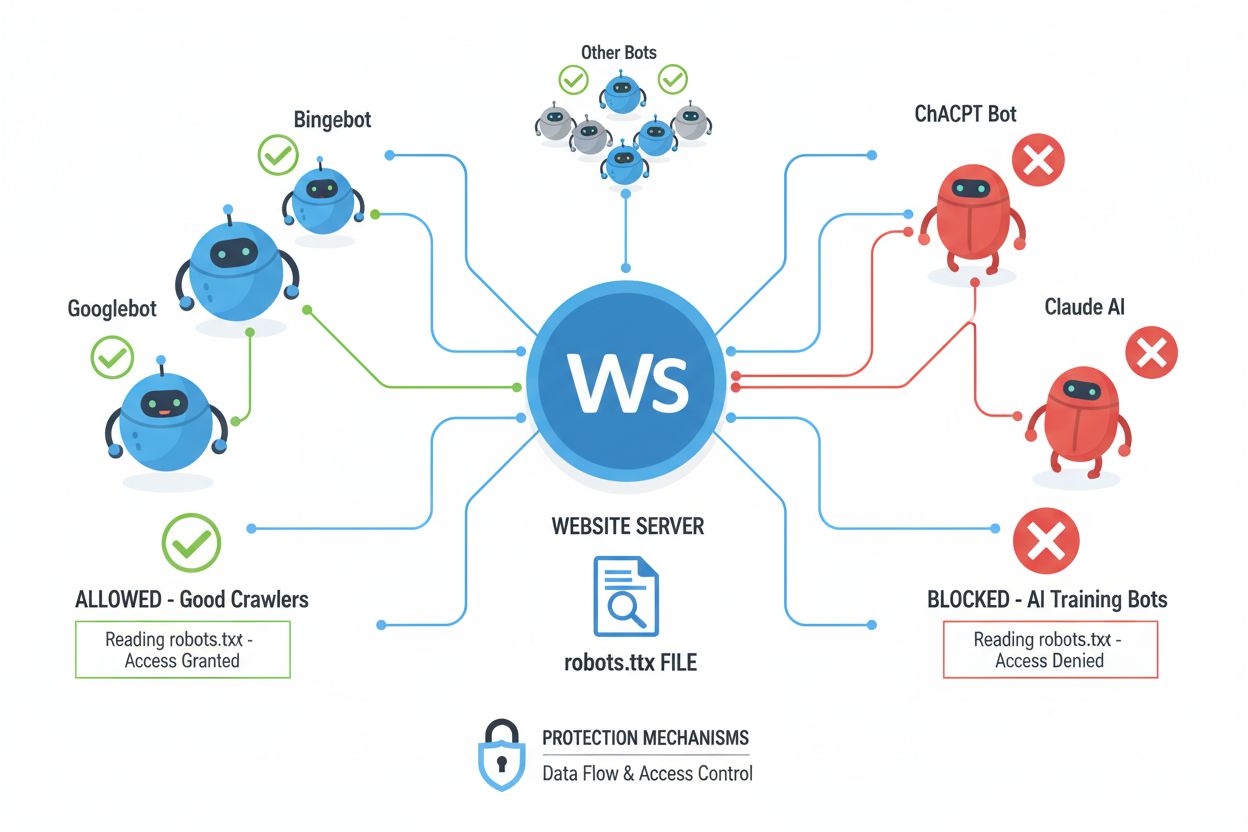
NoAI 元标签作为内容保护的重要一步,其运作基于自觉原则,完全取决于 AI 开发者和数据爬虫是否选择遵守。主流 AI 公司如 OpenAI、Google、Anthropic 等已开始在其爬虫中尊重 NoAI 指令,但恶意行为者和不良爬虫仍常常无视这些信号,因此对顽固的数据窃取者无效。NoAI 的有效性还受限于只能阻止未来的训练;它无法删除已被收集并用于现有模型的数据,也无法在被违规使用时提供法律追索。各 AI 系统的遵守率差异很大,有的会遵守,有的则有意规避,因此 NoAI 是有用但并不完整的解决方案。此外,该标签无法防止直接下载、截图或手动复制内容,也无法防止竞争对手无视指令直接使用您的内容。因此,NoAI 应被视为全面内容保护策略中的一环,而非唯一解决方案。
NoAI 元标签已被主流 AI 公司和平台大规模采用,OpenAI、Google 和 Stability AI 已公开承诺在其训练流程中遵守该指令。DeviantArt 的 NoAI 实践推动了整个行业对伦理 AI 开发和创作者同意权的关注,提高了 AI 开发者和内容创作者双方的意识。然而,行业内的执行仍不一致,小型 AI 公司、学术研究者和商业爬虫的遵守情况各异。随着 C2PA(内容出处与真实性联盟)等竞争标准的出现,以及机器可读权限表达的讨论,行业正朝着比自愿元标签更精细、具法律支撑的内容保护机制发展。行业组织和标准制定机构正积极推动这些保护的正式化,未来 AI 监管有可能要求明确遵守创作者偏好,从而将 NoAI 从自愿信号转变为具有法律约束的要求。
实施 NoAI 保护应作为多层次内容安全策略的一部分,结合技术、法律和监测手段,实现全面保护。为提升有效性,建议如下:
此外,请定期审核您的内容保护实现,确保所有页面均包含相应指令,并考虑使用自动化工具在公共 AI 数据集和训练库中扫描您的内容。将 NoAI 实施情况纳入内容治理政策,并及时向您的受众传达这些保护措施,若您是托管用户生成内容的平台,这尤为重要。
noai 指令保护所有类型的内容(文本、图片、代码)不被用于 AI 训练,而 noimageai 仅保护图片内容。如果需要全面保护请使用 noai,如果只想允许文本索引但保护视觉资产免受生成式图像模型训练,则使用 noimageai。
不能,NoAI 元标签依赖自觉原则,取决于 AI 开发者是否选择遵守。OpenAI 和 Google 等大公司会尊重它,但不良行为者和恶意爬虫经常忽略这些信号,因此它只是保护的一层,而非完全解决方案。
可以通过三种方式实现:将 HTML 元标签添加到页面头部、在服务器上设置 HTTP 响应头,或在 robots.txt 文件中包含指令。对于大多数网站主来说,HTML 元标签是最常见且最直接的方法。
包括 OpenAI(ChatGPT)、Google、Anthropic(Claude)和 Stability AI 在内的主流 AI 公司已经公开承诺在其训练流程中遵守 NoAI 指令。但对于小型 AI 公司、学术研究者和商业爬虫,执行情况各不相同。
可以,两者可同时使用以达到最大效果。NoAI 元标签和 robots.txt 指令可以协同作用,将您的内容保护偏好传达给不同类型的爬虫和系统。
将 NoAI 与其他保护措施结合使用,包括 HTTP 头、robots.txt 规则、水印、访问控制和法律服务条款。监控您的内容是否出现在 AI 数据集,并考虑使用工具追踪未经授权的使用。
虽然被主流 AI 公司广泛采用,但 NoAI 尚未成为正式的 W3C 标准。不过,行业组织正在推动更复杂的标准,如 C2PA 及机器可读权限表达,未来可能为其提供法律支持。
NoAI 与 robots.txt、HTTP 头、水印、访问控制和法律保护等方法结合使用时最有效。单一方法无法提供完全保护,因此建议采用多层次策略实现全面的内容安全。
通过 AmICited 的 AI 监测平台,跟踪哪些 AI 系统正在引用您的品牌和内容。准确了解您的作品被 ChatGPT、Perplexity、Google AI Overviews 及其他 AI 系统如何使用。
了解如何实现 noai 和 noimageai 元标签,以控制 AI 爬虫对您网站内容的访问。AI 访问控制头信息及实现方法的完整指南。

了解 noai 元标签、其防止 AI 训练数据采集的工作方式、局限性,以及如何在你的网站上实现它,从而保护你的内容免受生成式 AI 程序的侵用。...

了解隐身爬虫如何绕过robots.txt指令、爬虫规避的技术机制,以及如何保护您的内容免受未经授权的AI抓取。