实时内容 API
了解什么是实时内容 API,以及它们如何为 AI 系统提供时效性信息的当前内容更新。探索流式协议、应用场景及其如何赋能 AI 可见性与监控。...
2 分钟阅读

实时AI自适应指的是能够持续从当前事件和新输入数据中学习并即时调整的AI系统,无需手动重新训练。这些系统会随着新信息的出现动态更新其推荐、决策和行为,使组织能够即时响应不断变化的市场环境、客户行为和运营需求。
实时AI自适应指的是能够持续从当前事件和新输入数据中学习并即时调整的AI系统,无需手动重新训练。这些系统会随着新信息的出现动态更新其推荐、决策和行为,使组织能够即时响应不断变化的市场环境、客户行为和运营需求。
实时AI自适应指的是机器学习系统能够持续根据流入数据学习并调整其行为,无需手动重新训练周期。与依赖固定参数、按计划周期性重新训练的传统静态AI模型不同,自适应系统可瞬时处理新信息,并在毫秒级更新决策逻辑。其根本区别在于持续学习与批量学习——实时系统随数据到来即刻摄取并响应,而传统方法则收集数据后周期性离线更新。关键支撑技术包括在线学习算法、流式处理平台和联邦学习框架,可在边缘设备间分布计算任务。
实时AI自适应通过复杂的数据摄取、处理和反馈机制实现。系统采用在线学习算法,在每个新数据点到来时增量更新模型参数,结合如Apache Kafka和Apache Flink等流式处理引擎处理高流量数据,利用联邦学习架构实现分布式节点协同训练,数据无需集中,保障隐私。决策过程在实时中完成,模型在生成预测的同时融入反馈信号以优化后续输出。由此形成自我强化的反馈回路,每次预测与结果都推动模型性能持续提升。
| 特性 | 传统AI | 实时自适应AI |
|---|---|---|
| 模型更新 | 每周/月按计划重新训练 | 持续、毫秒级更新 |
| 学习速度 | 新模式识别需数小时至数天 | 即刻识别新模式 |
| 上下文感知 | 静态历史上下文 | 动态、实时上下文 |
| 适应能力 | 局限于预设场景 | 场景适应无限制 |
| 最佳应用场景 | 稳定、可预测环境 | 动态、变化迅速的市场 |
实时AI自适应依托多项关键技术与方法:

实时AI自适应正在各行业带来可观变革和量化效果。金融机构部署自适应欺诈检测系统,AUC-ROC得分0.96,准确率达94.2%,算法交易系统能在微秒级调整策略应对市场波动。医疗通过患者监测系统,实时采集生命体征和化验数据,自动调整治疗建议,诊断系统结合临床反馈不断提升准确率。电商平台用自适应推荐引擎将转化率从2.5%提升到4.2%,订单价值提升30%——Netflix的个性化引擎通过实时自适应驱动80%观众活跃。制造业利用预测性维护系统将设备故障率降低70%,计划时间缩短50%。客服聊天机器人每次交互都能提升响应质量,主动学习客户偏好和沟通习惯。自动驾驶依靠实时处理传感器数据,瞬时适应道路、天气和交通状况,做出分秒必争的决策。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
自适应AI系统通过加速决策和持续性能提升为企业带来巨大价值。实时自适应使决策从小时级缩短到毫秒级,在欺诈预防、交易和自动系统等对时效极敏感的场景下至关重要。持续学习机制让模型准确率实现指数级提升——传统模型仅依靠昨日数据在动态市场很快过时,而自适应系统能即时融入最新模式保持高性能。企业通过自动化重训练和减少手动维护显著降低运营成本,部分案例ML运维开销降低40%。客户体验大幅提升,系统能实时学习个人偏好和行为,提升用户忠诚度和留存率。采用自适应AI的企业预计将比竞争对手高出25%业绩,实时AI市场2024年估值10.4亿美元,预计2034年增至305.1亿美元,显示出对这一能力的爆发性需求。
实施实时AI自适应面临重大的技术与组织挑战。数据质量与噪声在大规模场景下成为关键难题——流数据中包含错误、重复与异常,若不加过滤会导致模型受损,需建设健全的数据验证流水线。计算资源需求急剧上升,每秒处理百万级事件需专用基础设施、GPU与分布式系统,推高资本与运维成本。低延迟要求使工程难度增加——系统必须在严格时间窗(常低于100毫秒)内完成数据处理、模型更新与预测,留给错误的空间极小。模型与概念漂移导致数据分布意外变化,原本准确的模型性能骤降,需持续监控与自动触发重训练。隐私与安全问题随持续数据采集与模型更新加剧,尤其在医疗、金融等受监管行业,数据治理复杂度呈指数级上升。可解释性挑战随模型持续演化而加深——当参数不断变化,理解模型为何做出某一决策变得更难。与传统系统集成也代价高昂且耗时,因现有基础设施往往缺乏流处理和实时架构能力。
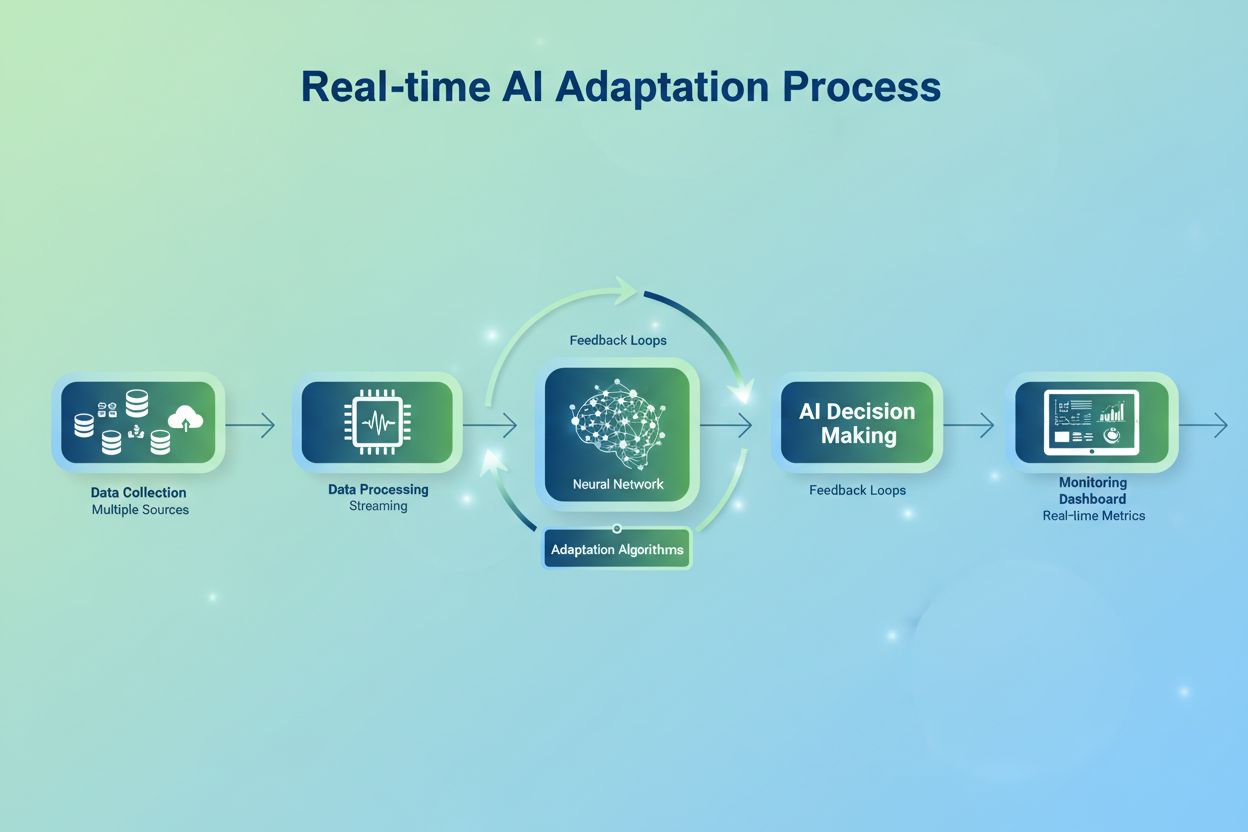
成功的实时AI自适应项目需在创新与运维稳定之间取得平衡。优先选择高影响力场景,如欺诈检测、推荐引擎、预测性维护等,能较快实现投资回报。保障数据基础设施健全,在上线自适应模型前投入流式处理平台、数据验证与监控工具——数据质量差将抵消所有后续收益。建立全面监控与治理框架,持续跟踪模型表现,检测漂移,并在准确性低于阈值时自动预警。战略性部署边缘计算,为时延敏感型应用降低延迟,同时保持云端计算和数据聚合能力。搭建反馈机制,收集真实标签、用户交互和结果数据,驱动持续学习回路。从一开始就规划可扩展性——设计能承载10倍数据量的系统,避免架构重构。采用混合方法,将实时自适应应用于关键决策,非紧急模式发现可用批量学习,以兼顾成本与性能。
实时AI自适应正朝着更智能化、自主化、深度集成的方向演进。边缘AI与5G集成将推动超低延迟自适应系统直接在移动设备和物联网传感器上运行,无需依赖云端,满足时效性最强的场景。多智能体自适应系统将在数千分布式主体间协同学习,通过集体自适应解决复杂问题,实现涌现式智能。自愈型AI系统能自动检测故障、重校模型、恢复性能,无需人工介入,进一步降低运维负担。可解释性技术(如注意力机制、因果推断)将让持续演化的模型更易理解,解决监管与信任难题。行业专用自适应架构也将出现,医疗、金融、制造等会发展出适合其独特约束和需求的自适应体系。与生成式AI融合将让自适应系统不仅能从数据中学习,还可生成合成训练样本,提升数据稀缺场景下的学习速度。全球范围的监管框架正在推动,逐步为自适应AI设立透明、公平和责任标准,对各行业的落地方式产生深远影响。