训练数据
训练数据是用于教机器学习模型模式和关系的数据集。了解高质量训练数据如何影响AI模型的性能、准确性及其在各行业的实际应用。...
1 分钟阅读

合成数据训练是指使用人工生成的数据而非真实世界由人类创建的信息来训练 AI 模型的过程。这种方法解决了数据稀缺问题,加快了模型开发进程,并保护了隐私,但同时也带来了模型崩溃和幻觉等挑战,需要通过精细管理和验证加以应对。
合成数据训练是指使用人工生成的数据而非真实世界由人类创建的信息来训练 AI 模型的过程。这种方法解决了数据稀缺问题,加快了模型开发进程,并保护了隐私,但同时也带来了模型崩溃和幻觉等挑战,需要通过精细管理和验证加以应对。
合成数据训练指的是通过人工生成的数据而非真实世界人类创建的信息来训练人工智能模型的过程。与依赖于通过调查、观察或网络挖掘等方式采集的真实数据的传统 AI 训练不同,合成数据由算法和计算方法生成,这些方法要么从现有数据中学习统计模式,要么直接从零创造全新数据。这种训练方法的根本转变解决了现代 AI 发展中的关键挑战:计算需求的指数级增长已超越人类生成足够真实数据的能力,研究显示人类生成的训练数据可能会在未来几年内耗尽。合成数据训练提供了一种可扩展、低成本的替代方案,无需耗时的数据采集、标注与清洗流程(这些过程在传统 AI 开发中占用多达 80% 的时间),即可实现无限生成。
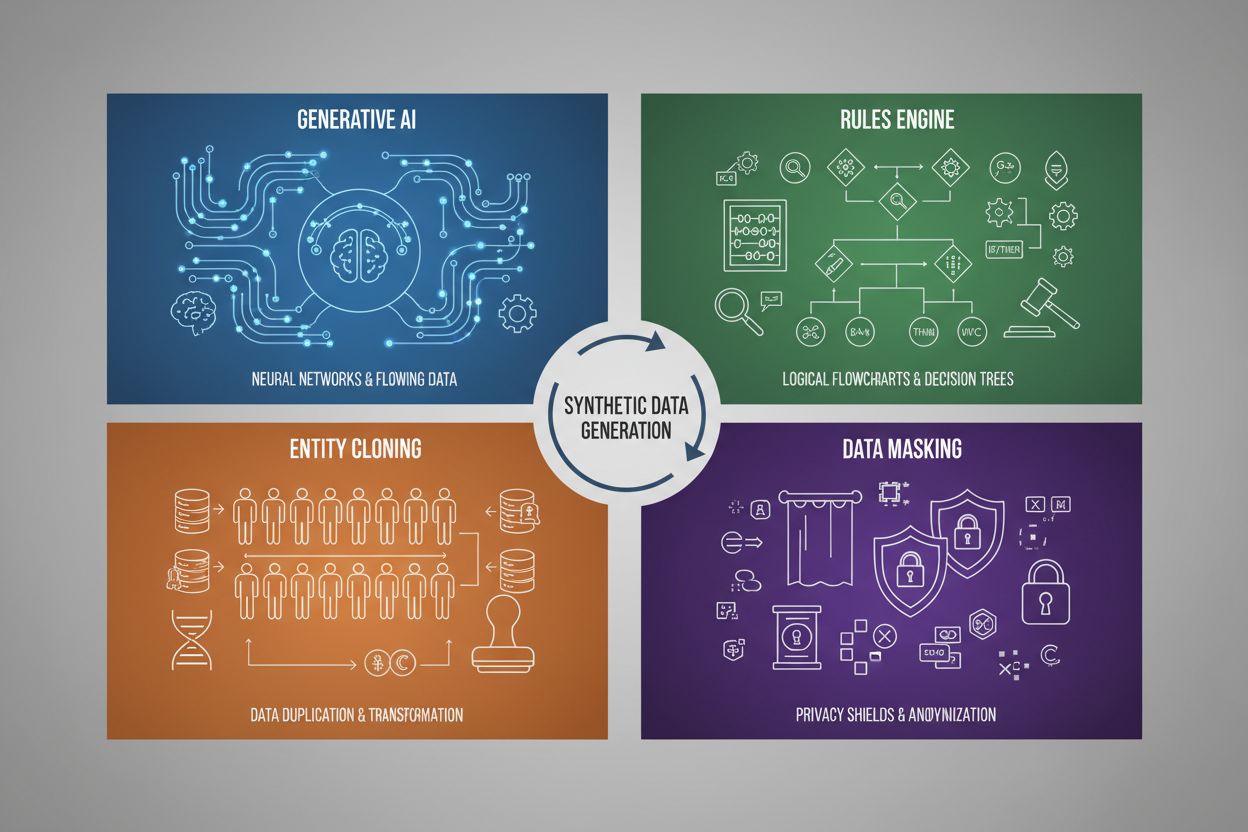
合成数据生成主要包括四种技术,每种方法机制和应用场景不同:
| 技术 | 工作原理 | 应用场景 |
|---|---|---|
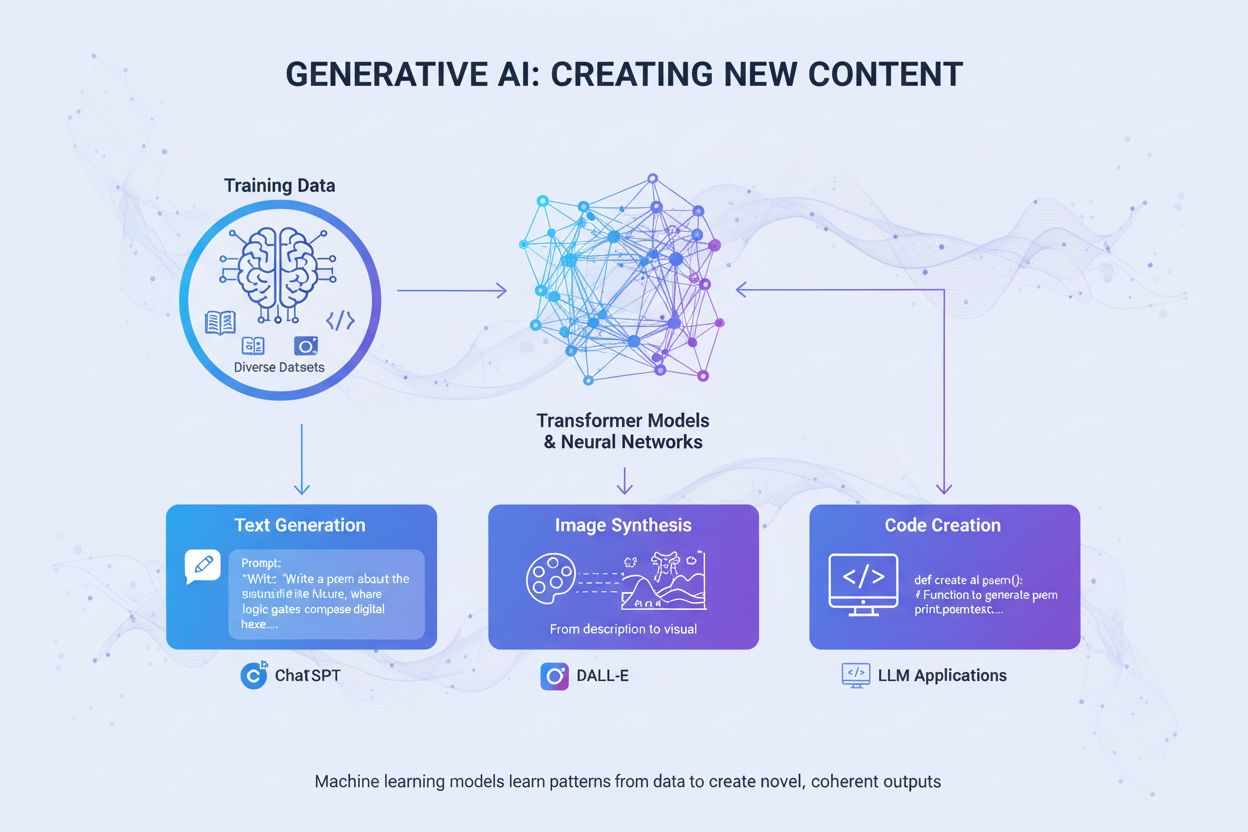
| 生成式 AI(GAN、VAE、GPT) | 利用深度学习模型学习真实数据的统计模式和分布,然后生成保持相同统计属性和关系的新合成样本。GAN 通过生成器和判别器对抗生成愈加真实的数据。 | 训练大型语言模型(如 ChatGPT)、用 DALL-E 生成合成图像、为自然语言处理任务创建多样化文本数据集 |
| 规则引擎 | 通过预定义逻辑规则和约束生成遵循特定业务逻辑、领域知识或合规要求的数据。这种确定性方法无需机器学习即可确保生成数据符合已知模式和关系。 | 金融交易数据、符合法规要求的医疗记录、具有已知运行参数的制造业传感器数据 |
| 实体克隆 | 通过对现有真实数据记录进行复制和修改(如变换、扰动或变化),在保持核心统计属性和关系的同时生成新实例。此技术既保证数据真实性,又能扩展数据集规模。 | 扩展受监管行业中的有限数据集、为罕见疾病诊断创建训练数据、增强少数类别样本不足的数据集 |
| 数据脱敏与匿名化 | 采用标记化、加密或数值替换等方法,在保留数据结构和统计关系的同时,隐藏敏感的个人身份信息(PII),从而生成具备隐私保护的合成数据版本。 | 医疗和金融数据集、客户行为数据、科研中的个人敏感信息 |
合成数据训练能够显著降低成本,因为无需再投入大量资源和时间进行昂贵的数据采集、标注和清洗。组织可以按需无限生成训练样本,大幅加速模型开发周期,让团队在无需等待真实数据收集的情况下开展快速迭代和实验。该技术还提供了强大的数据增强能力,使开发者能够扩展有限数据集,构建平衡的训练集,从而解决在真实数据中某些类别样本不足(类别不平衡)的问题。对于医学影像、罕见疾病诊断或自动驾驶测试等专业领域,收集足够真实样本成本极高或伦理上存在挑战,合成数据的价值尤为突出。隐私保护也是重要优势之一,合成数据可在不暴露敏感个人信息的前提下生成,非常适合医疗、金融等合规领域的模型训练。此外,合成数据可通过有意构建平衡多样的数据集,有效减少真实数据中的偏见,例如在训练图像中生成多元人口特征,防止 AI 模型在招聘、贷款或刑事司法等场景中延续性别或种族刻板印象。
尽管前景广阔,合成数据训练仍带来重大技术与实践挑战,若管理不当,可能严重影响模型表现。最突出的问题是模型崩溃:当 AI 模型过度依赖合成数据训练时,输出质量、准确性和连贯性会显著下降。这是因为合成数据虽然在统计上与真实数据相似,但缺少真实人类信息中的细致复杂性和边缘案例——当模型训练内容来自 AI 生成的数据时,会不断放大错误和伪影,造成每一代合成数据质量递减。
主要挑战包括:
这些挑战说明,合成数据无法取代真实数据,必须在严格质量保证和人工监督下,作为真实数据的有力补充。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
随着合成数据在 AI 模型训练中的普及,品牌面临着新的关键挑战:确保自身在 AI 生成结果和引用中的准确与正面呈现。当大型语言模型与生成式 AI 系统以合成数据为训练基础时,合成数据的质量和特征会直接影响品牌在 AI 搜索结果、聊天机器人回复及自动内容生成中的描述、推荐和引用。这带来重大的品牌安全隐患——如果合成数据中包含过时信息、竞争对手偏见或不准确品牌描述,这些内容可能被模型吸收,导致数百万用户互动中出现持续的品牌误读。对于使用 AmICited.com 等平台监控品牌在 AI 系统中表现的组织而言,理解合成数据在模型训练中的角色至关重要——品牌需要了解 AI 引用和提及内容究竟来自真实数据还是合成来源,这会影响其公信力和准确性。合成数据使用透明度的缺失带来责任归属挑战:企业难以判断自身品牌信息在用于训练模型的合成数据集中是否被准确呈现。前瞻性的品牌应优先开展 AI 监控与引用追踪,及早发现品牌误读,推动建立 AI 训练中合成数据使用的透明披露标准,并与能分析品牌在真实及合成数据双重训练 AI 系统中表现的平台合作。随着合成数据在 2030 年成为主流训练范式,品牌监控将从传统媒体追踪转向全方位 AI 引用情报,能够跨生成式 AI 系统追踪品牌表现的平台将成为品牌保护和确保品牌声音在 AI 信息生态中准确呈现的关键工具。