AI-crawlers' indvirkning på serverressourcer: Hvad kan du forvente
Lær hvordan AI-crawlers påvirker serverressourcer, båndbredde og ydeevne. Opdag reelle statistikker, afhjælpningsstrategier og infrastrukturløsninger til effektiv håndtering af bot-belastning.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
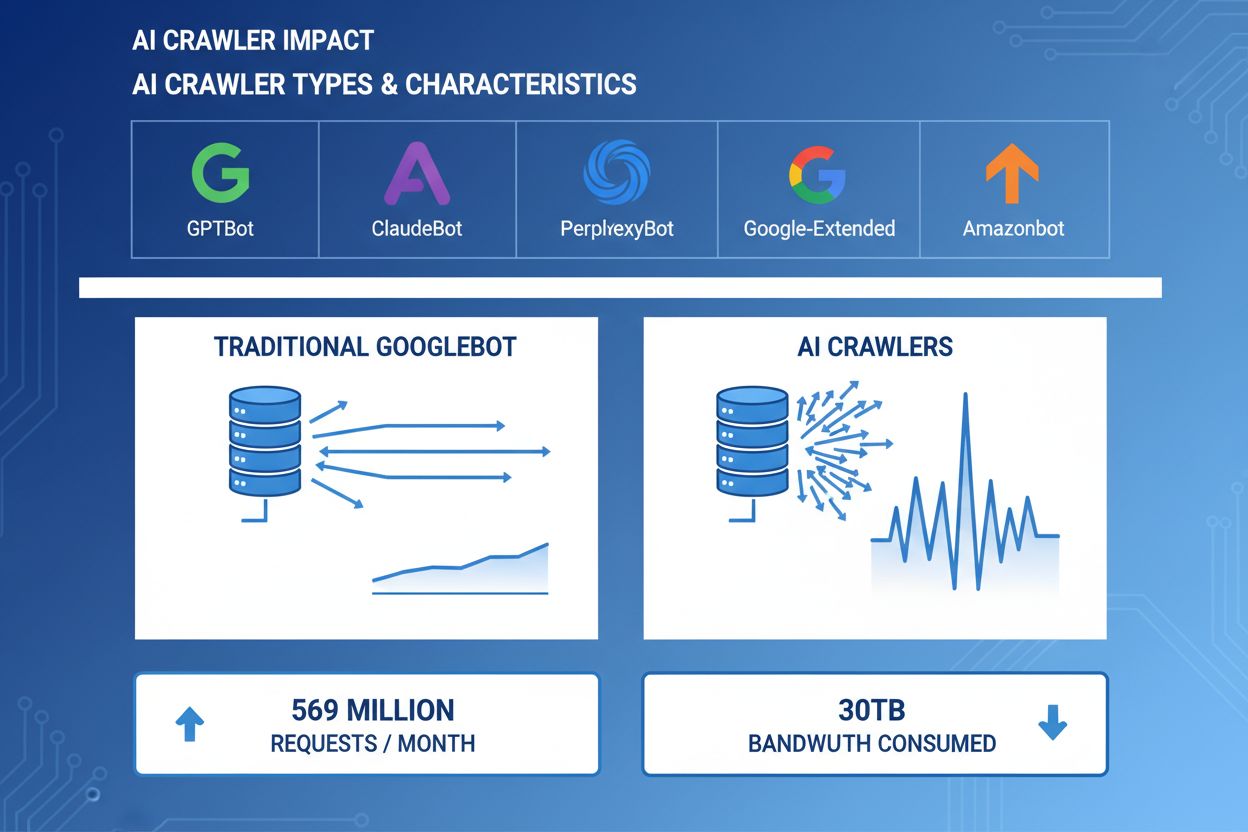
AI-crawlers er blevet en betydelig drivkraft i webtrafik, idet større AI-virksomheder udsender avancerede bots til at indeksere indhold til træning og søgning. Disse crawlers opererer i massiv skala og genererer cirka 569 millioner forespørgsler om måneden på tværs af nettet og forbruger over 30TB båndbredde globalt. De primære AI-crawlers omfatter GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) og Amazonbot (Amazon), hver med deres egne crawl-mønstre og ressourcekrav. At forstå adfærden og karakteristika ved disse crawlers er essentielt for websiteadministratorer, så de kan håndtere serverressourcer korrekt og træffe informerede beslutninger om adgangspolitikker.
AI-crawlers forbruger serverressourcer på flere fronter og skaber målbare påvirkninger på infrastrukturens ydeevne. CPU-forbrug kan stige med 300% eller mere under perioder med høj crawleraktivitet, da servere håndterer tusindvis af samtidige forespørgsler og parser HTML-indhold. Båndbreddeforbrug er en af de mest synlige omkostninger, hvor et enkelt populært website potentielt kan levere gigabyte af data dagligt til crawlers. Hukommelsesforbruget stiger markant, når servere holder forbindelser åbne og buffer store datamængder til behandling. Databaseforespørgsler mangedobles, når crawlers anmoder om sider, der udløser dynamisk indholdsgenerering, hvilket skaber ekstra I/O-belastning. Disk I/O bliver en flaskehals, når servere skal læse fra lager for at betjene crawler-forespørgsler, især for sites med store indholdsarkiver.
Ressource
Påvirkning
Virkeligt eksempel
CPU
200-300% stigning under peak crawling
Server load average stiger fra 2,0 til 8,0
Båndbredde
15-40% af samlet månedligt forbrug
500GB-site leverer 150GB til crawlers månedligt
Hukommelse
20-30% øget RAM-forbrug
8GB-server kræver 10GB under crawleraktivitet
Database
2-5x øget forespørgselsbelastning
Forespørgselstider stiger fra 50ms til 250ms
Disk I/O
Vedvarende høje læseoperationer
Diskudnyttelse hopper fra 30% til 85%
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
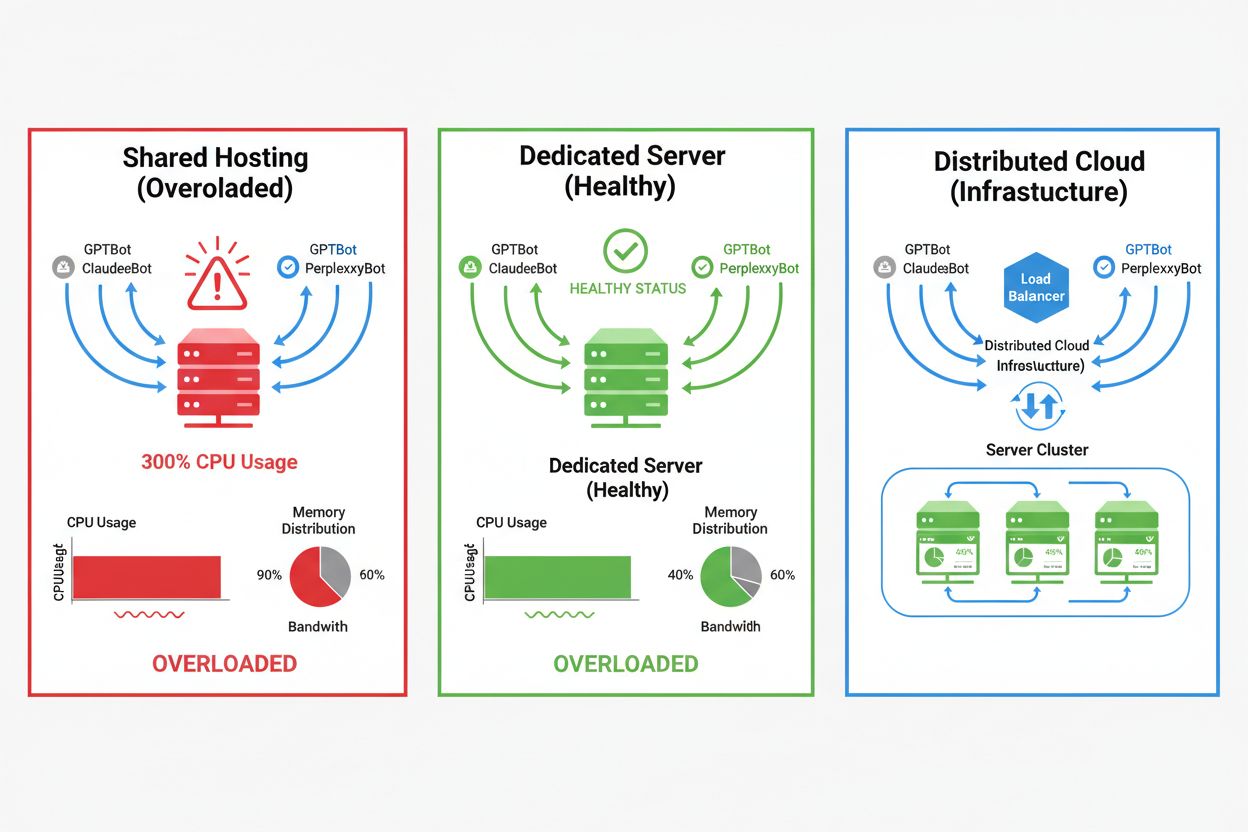
AI-crawleres påvirkning varierer dramatisk afhængigt af dit hostingmiljø, hvor delte hostingmiljøer oplever de mest alvorlige konsekvenser. I delt hosting bliver “støjende nabo-syndromet” særligt problematisk—når et website på en delt server tiltrækker tung crawlertrafik, forbruger det ressourcer, som ellers ville være til rådighed for andre hostede websites, hvilket forringer ydeevnen for alle brugere. Dedikerede servere og cloud-infrastruktur giver bedre isolering og ressourcegaranti, så du kan absorbere crawlertrafik uden at påvirke andre tjenester. Selv dedikeret infrastruktur kræver dog nøje overvågning og skalering for at håndtere den samlede belastning fra flere samtidige AI-crawlers.
Vigtige forskelle mellem hostingmiljøer:
Delt hosting: Begrænsede ressourcer, ingen isolering, crawlertrafik påvirker direkte andre sites, minimal kontrol over crawleradgang
VPS/Cloud: Dedikerede ressourcer, bedre isolering, skalerbar kapacitet, detaljeret kontrol over trafikstyring
Den økonomiske påvirkning fra AI-crawlertrafik går ud over simple båndbreddeomkostninger og omfatter både direkte og skjulte udgifter, som kan påvirke din bundlinje markant. Direkte omkostninger inkluderer øgede båndbreddeafgifter fra din hostingudbyder, hvilket kan tilføje flere hundrede eller tusinde kroner om måneden afhængigt af trafikmængde og crawlerintensitet. Skjulte omkostninger opstår gennem øgede infrastrukturkrav—du kan blive nødt til at opgradere til dyrere hosting, implementere ekstra cachelag eller investere i CDN-tjenester kun for at håndtere crawlertrafik. ROI-beregningen bliver kompleks, når man overvejer, at AI-crawlers giver minimal direkte værdi for din virksomhed, men forbruger ressourcer, som kunne betjene betalende kunder eller forbedre brugeroplevelsen. Mange websiteejere oplever, at omkostningerne ved at imødekomme crawlertrafik overstiger eventuelle fordele fra AI-modeltræning eller synlighed i AI-søgeresultater.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Ydelsespåvirkning på brugeroplevelsen
AI-crawlertrafik forringer direkte brugeroplevelsen for legitime besøgende ved at forbruge serverressourcer, der ellers ville gøre websitet hurtigere for mennesker. Core Web Vitals-målinger lider mærkbart, hvor Largest Contentful Paint (LCP) øges med 200-500ms og Time to First Byte (TTFB) forværres med 100-300ms under kraftig crawleraktivitet. Disse ydelsesforringelser udløser en kædereaktion af negative effekter: langsommere sideindlæsning mindsker brugerengagement, øger bounce rates og reducerer i sidste ende konverteringsraten for e-handel og leadgenerering. Søgemaskineplaceringer lider også, da Googles algoritme inddrager Core Web Vitals som rangeringsfaktor, hvilket skaber en ond cirkel, hvor crawlertrafik indirekte skader din SEO. Brugere, der oplever langsomme indlæsninger, forlader oftere dit site og vælger konkurrenter, hvilket direkte påvirker omsætning og brandopfattelse.
Overvågnings- og detektionsstrategier
Effektiv håndtering af AI-crawlertrafik starter med omfattende overvågning og detektion, så du forstår problemets omfang, før du implementerer løsninger. De fleste webservere logger user-agent-strenge, der identificerer crawleren bag hver forespørgsel, hvilket danner grundlag for trafikanalyse og filtrering. Serverlogs, analyseplatforme og specialiserede overvågningsværktøjer kan gennemgå disse user-agent-strenge for at identificere og kvantificere crawlertrafik.
Vigtige detektionsmetoder og værktøjer:
Loganalyse: Gennemgå serverlogs for user-agent-strenge (GPTBot, ClaudeBot, Google-Extended, CCBot) for at identificere crawler-forespørgsler
Analyseplatforme: Google Analytics, Matomo m.fl. kan segmentere crawlertrafik separat fra menneskelige brugere
Realtidsovervågning: Værktøjer som New Relic og Datadog giver realtidsindsigt i crawleraktivitet og ressourceforbrug
DNS Reverse Lookup: Verificer crawler-IP-adresser mod offentliggjorte IP-ranges fra OpenAI, Anthropic m.fl.
Adfærdsanalyse: Identificer mistænkelige mønstre som hurtige sekventielle forespørgsler, usædvanlige user-agent-kombinationer eller anmodninger til følsomme områder
Afhjælpningsstrategier – robots.txt og rate limiting
Første forsvarslinje mod overdreven AI-crawlertrafik er en velkonfigureret robots.txt-fil, der eksplicit styrer crawleradgang til dit website. Denne enkle tekstfil placeres i websitets rodkatalog og giver dig mulighed for at nægte bestemte crawlers adgang, begrænse crawl-frekvens og dirigere crawlers til et sitemap med kun det indhold, du ønsker indekseret. Rate limiting på applikations- eller serverniveau giver et ekstra lag beskyttelse ved at begrænse forespørgsler fra bestemte IP-adresser eller user-agents og forhindre ressourceudtømning. Disse strategier er ikke-blokerende og reversible, hvilket gør dem ideelle som udgangspunkt før mere aggressive tiltag.
Web Application Firewalls (WAF) og Content Delivery Networks (CDN) leverer avanceret, virksomhedsrettet beskyttelse mod uønsket crawlertrafik via adfærdsanalyse og intelligent filtrering. Cloudflare og lignende CDN-udbydere tilbyder indbyggede bot management-funktioner, der kan identificere og blokere AI-crawlers baseret på adfærdsmønstre, IP-ry og forespørgselskarakteristika uden manuel opsætning. WAF-regler kan konfigureres til at udfordre mistænkelige forespørgsler, rate-limite bestemte user-agents eller blokere trafik fra kendte crawler-IP-ranges helt. Disse løsninger arbejder ved kanten og filtrerer skadelig trafik, før den når din origin-server, hvilket dramatisk mindsker belastningen på din infrastruktur. Fordelen ved WAF- og CDN-løsninger er deres evne til at tilpasse sig nye crawlers og udviklende angrebsmønstre uden at kræve manuelle opdateringer af din konfiguration.
Balance mellem synlighed og beskyttelse
At beslutte, om man skal blokere AI-crawlers, kræver nøje overvejelse af afvejningen mellem at beskytte dine serverressourcer og opretholde synlighed i AI-drevne søgeresultater og applikationer. Blokering af alle AI-crawlers fjerner muligheden for, at dit indhold vises i ChatGPT-søgning, Perplexity AI-svar eller andre AI-baserede opdagelsesmekanismer, hvilket potentielt reducerer henvisningstrafik og brandeksponering. Omvendt resulterer ubegrænset crawleradgang i betydeligt ressourceforbrug og kan forringe brugeroplevelsen uden målbare fordele for din forretning. Den optimale strategi afhænger af din specifikke situation: højtrafikerede websites med rigelige ressourcer kan vælge at tillade crawlers, mens ressourcebegrænsede sites bør prioritere brugeroplevelse ved at blokere eller rate-limite crawleradgang. Strategiske beslutninger bør tage branch, målgruppe, indholdstype og forretningsmål i betragtning fremfor en ensartet tilgang.
Skaleringsløsninger til infrastruktur
For websites, der vælger at imødekomme AI-crawlertrafik, giver infrastrukturskalering mulighed for at opretholde ydeevne, mens den øgede belastning absorberes. Vertikal skalering—opgradering til servere med mere CPU, RAM og båndbredde—er en ligetil, men dyr løsning, der til sidst rammer fysiske grænser. Horisontal skalering—fordeling af trafik på flere servere via load balancers—giver bedre langsigtet skalerbarhed og robusthed. Cloud-infrastrukturplatforme som AWS, Google Cloud og Azure tilbyder autoskalering, der automatisk tildeler ekstra ressourcer under trafikspidser og skalerer ned i stille perioder for at minimere omkostninger. Content Delivery Networks (CDN) kan cache statisk indhold på edge-lokationer, reducere belastningen på origin-serveren og forbedre ydeevnen for både menneskelige brugere og crawlers. Databaseoptimering, query caching og forbedringer på applikationsniveau kan også reducere ressourceforbruget pr. forespørgsel og øge effektiviteten uden yderligere infrastruktur.
Overvågningsværktøjer og best practices
Løbende overvågning og optimering er afgørende for at opretholde optimal ydeevne i mødet med vedvarende AI-crawlertrafik. Specialiserede værktøjer giver indsigt i crawleraktivitet, ressourceforbrug og performancemålinger, hvilket muliggør databaserede beslutninger om crawlerhåndteringsstrategier. Implementering af omfattende overvågning fra starten giver dig mulighed for at etablere baseline, identificere trends og måle effekten af afhjælpningsstrategier over tid.
Væsentlige overvågningsværktøjer og praksisser:
Serverovervågning: New Relic, Datadog eller Prometheus til realtidsmålinger af CPU, hukommelse og disk I/O
Loganalyse: ELK Stack, Splunk eller Graylog til at parse og analysere serverlogs for crawler-mønstre
Specialiserede løsninger: AmICited.com tilbyder specialiseret overvågning af AI-crawleraktivitet med detaljeret indsigt i, hvilke AI-modeller der tilgår dit indhold
Performance-tracking: Google PageSpeed Insights, WebPageTest og Core Web Vitals-overvågning for at måle brugeroplevelses-påvirkning
Alarmering: Opsæt alarmer for ressource-spidser, usædvanlige trafikmønstre og ydelsesforringelse for hurtig reaktion
Langsigtet strategi og fremtidige overvejelser
Landskabet for AI-crawler management udvikler sig løbende med nye standarder og brancheinitiativer, der former, hvordan websites og AI-virksomheder interagerer. llms.txt-standarden repræsenterer en ny tilgang til at give AI-virksomheder struktureret information om indholdsbrugsrettigheder og præferencer og tilbyder potentielt et mere nuanceret alternativ til enten total blokering eller åbning. Branchesnak om kompensationsmodeller antyder, at AI-virksomheder i fremtiden kan komme til at betale websites for adgang til træningsdata, hvilket fundamentalt ændrer økonomien bag crawlertrafik. At fremtidssikre din infrastruktur kræver, at du holder dig opdateret på nye standarder, overvåger branchen og bevarer fleksibilitet i dine crawlerpolitikker. At opbygge relationer til AI-virksomheder, deltage i branchedebatten og arbejde for fair kompensationsmodeller bliver stadig vigtigere, efterhånden som AI bliver mere central for webopdagelse og indholdsforbrug. De websites, der trives i dette udviklende landskab, er dem, der balancerer innovation med pragmatisme, beskytter deres ressourcer og samtidig forbliver åbne over for legitime muligheder for synlighed og partnerskab.
Ofte stillede spørgsmål
Hvad er forskellen mellem AI-crawlers og søgemaskine-crawlers?
AI-crawlers (GPTBot, ClaudeBot) udtrækker indhold til LLM-træning uden nødvendigvis at sende trafik tilbage. Søge-crawlers (Googlebot) indekserer indhold for synlighed i søgning og sender typisk henvisningstrafik. AI-crawlers opererer mere aggressivt med større batch-forespørgsler og ignorerer ofte retningslinjer for båndbreddebesparelse.
Hvor meget båndbredde kan AI-crawlers forbruge?
Virkelige eksempler viser 30TB+ om måneden fra enkelte crawlers. Forbruget afhænger af sidestørrelse, indholdsmængde og crawlerfrekvens. OpenAI's GPTBot genererede alene 569 millioner forespørgsler på en enkelt måned på Vercel's netværk.
Vil blokering af AI-crawlers skade min SEO?
Blokering af AI-trænings-crawlers (GPTBot, ClaudeBot) påvirker ikke Googles placeringer. Blokering af AI-søge-crawlers kan dog reducere synlighed i AI-drevne søgeresultater som Perplexity eller ChatGPT-søgning.
Hvad er tegnene på, at min server overvældes af crawlers?
Hold øje med uforklarlige CPU-spidser (300%+), øget båndbreddeforbrug uden flere menneskelige besøgende, langsommere sideindlæsningstider og usædvanlige user-agent-strenge i serverlogs. Core Web Vitals-målinger kan også forværres markant.
Er det det værd at opgradere til dedikeret hosting for crawlerhåndtering?
For sites med betydelig crawlertrafik giver dedikeret hosting bedre ressourceisolering, kontrol og forudsigelige omkostninger. Delt hosting lider af 'støjende nabo-syndrom', hvor én sides crawlertrafik påvirker alle hostede sites.
Hvilke værktøjer bør jeg bruge til at overvåge AI-crawleraktivitet?
Brug Google Search Console til Googlebot-data, serveradgangslogs til detaljeret trafikanalyse, CDN-analyse (Cloudflare) og specialiserede platforme som AmICited.com til omfattende AI-crawlerovervågning og tracking.
Kan jeg selektivt tillade nogle crawlers, mens jeg blokerer andre?
Ja, via robots.txt-direktiver, WAF-regler og IP-baseret filtrering. Du kan tillade gavnlige crawlers som Googlebot, mens du blokerer ressourcekrævende AI-trænings-crawlers med user-agent-specifikke regler.
Hvordan ved jeg, om AI-crawlers påvirker mit websites ydeevne?
Sammenlign servermålinger før og efter implementering af crawlerkontroller. Overvåg Core Web Vitals (LCP, TTFB), sideindlæsningstider, CPU-forbrug og brugeroplevelsesmålinger. Værktøjer som Google PageSpeed Insights og serverovervågningsplatforme giver detaljeret indsigt.
Overvåg din AI-crawlerpåvirkning i dag
Få realtidsindsigt i, hvordan AI-modeller tilgår dit indhold og påvirker dine serverressourcer med AmICited's specialiserede overvågningsplatform.
Hvor ofte bør AI-crawlere besøge mit site? Mit niveau virker meget lavere end konkurrenternes – hvad øger crawl-frekvensen?
Fællesskabsdiskussion om at øge AI-crawleres frekvens. Rigtige data og strategier fra webmasters, der har forbedret hvor ofte ChatGPT, Perplexity og andre AI-cr...
Skal du blokere eller tillade AI-crawlere? Beslutningsramme
Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...
Hvilke AI-crawlere bør jeg give adgang? Komplet guide til 2025
Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
10 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.