
Hvordan Forstår AI-systemer Enhedsrelationer?
Lær, hvordan AI-systemer identificerer, udtrækker og forstår relationer mellem enheder i tekst. Oplev teknikker til udtrækning af enhedsrelationer, NLP-metoder ...
8 min læsning

Udforsk hvordan AI-systemer genkender og bearbejder enheder i tekst. Lær om NER-modeller, transformer-arkitekturer og virkelige anvendelser af enhedsforståelse.
Enhedsforståelse er blevet en hjørnesten i moderne kunstig intelligens og gør det muligt for maskiner at identificere og forstå nøgleaktører, steder og begreber i ustruktureret tekst. Fra søgemaskiner, der forstår brugerens hensigt, til chatbots, der kan besvare komplekse spørgsmål om bestemte personer og organisationer, danner enhedsgenkendelse grundlaget for meningsfuld interaktion mellem menneske og computer. Denne tekniske evne er kritisk på tværs af industrier—finansielle institutioner bruger det til overholdelsesovervågning, sundhedssystemer udnytter det til patientjournaler, og e-handelsplatforme er afhængige af det for at forstå produktomtaler og kunde-feedback. At forstå, hvordan AI-systemer udtrækker og fortolker enheder, er essentielt for alle, der bygger eller anvender NLP-applikationer i produktion.
Navngiven Enhedsgenkendelse (NER) er NLP-opgaven at identificere og klassificere navngivne enheder—specifikke, meningsfulde informationsenheder—i tekst i foruddefinerede kategorier. Disse enheder repræsenterer de konkrete subjekter, der bærer semantisk vægt i sproget: personer der udfører handlinger, organisationer der træffer beslutninger, steder hvor begivenheder sker, tidsudtryk der forankrer begivenheder i tid, pengebeløb der kvantificerer transaktioner, og produkter der købes og sælges. Enhedsklassificering er vigtig, fordi det omdanner rå tekst til struktureret viden, som maskiner kan ræsonnere over og handle på; uden dette kan et system ikke skelne mellem “Apple virksomheden” og “apple frugten”, eller forstå at “John Smith” og “J. Smith” refererer til samme person. Evnen til nøjagtigt at klassificere enheder muliggør nedstrøms applikationer som vidensgrafkonstruktion, informationsudtræk, spørgsmål-besvarelse og relationsdetektion.
| Enhedstype | Definition | Eksempel |
|---|---|---|
| PERSON | Individuelle mennesker | “Steve Jobs,” “Marie Curie” |
| ORGANIZATION | Virksomheder, institutioner, grupper | “Microsoft,” “United Nations,” “Harvard University” |
| LOCATION | Geografiske steder og regioner | “New York,” “Amazon River,” “Silicon Valley” |
| DATE | Tidsudtryk og perioder | “15. januar 2024,” “næste tirsdag,” “Q3 2023” |
| MONEY | Pengeværdier og valutaer | “$50 millioner,” “€100,” “5000 yen” |
| PRODUCT | Varer, tjenester og kreationer | “iPhone 15,” “Windows 11,” “ChatGPT” |
Moderne AI-systemer bearbejder enheder gennem en sofistikeret flertrins-pipeline, der begynder med tokenisering, hvor rå tekst opdeles i diskrete tokens, der fungerer som grundelementer for den videre behandling. Hvert token konverteres derefter til en numerisk repræsentation via word embeddings—tætte vektorer, der indfanger semantisk betydning—som føres ind i neurale netværksarkitekturer designet til at forstå kontekst og relationer. Transformerbaserede modeller, som nu er den dominerende arkitektur i moderne NLP, bearbejder hele sekvenser parallelt frem for sekventielt, hvilket gør dem i stand til at indfange langtrækkende afhængigheder og komplekse kontekstuelle relationer, der er afgørende for korrekt enhedsforståelse. Self-attention-mekanismen i Transformers gør det muligt for hvert token dynamisk at vægte betydningen af alle andre tokens i sekvensen, hvilket skaber rige kontekstuelle repræsentationer, hvor betydningen af et ord formes af dets omgivelser; derfor forstås “bank” forskelligt i “river bank” versus “savings bank.” Fortrænede sprogmodeller som BERT og GPT lærer generelle sproglige mønstre fra enorme tekstkorpusser, før de finjusteres på enhedsgenkendelsesopgaver, hvilket gør det muligt at udnytte lærte repræsentationer af syntaks, semantik og verdensviden. Det sidste lag i enhedsgenkendelsessystemer benytter typisk en sekvensmærknings-tilgang—ofte implementeret som en Conditional Random Field (CRF) eller et simpelt klassifikationshoved—der tildeler enhedsmærker til hvert token baseret på de kontekstuelle repræsentationer, det neurale netværk har lært. Denne arkitektur gør AI-systemer i stand til ikke kun at forstå, hvilke enheder der er til stede, men også hvordan de relaterer til hinanden, og hvilke roller de spiller i tekstens bredere kontekst.
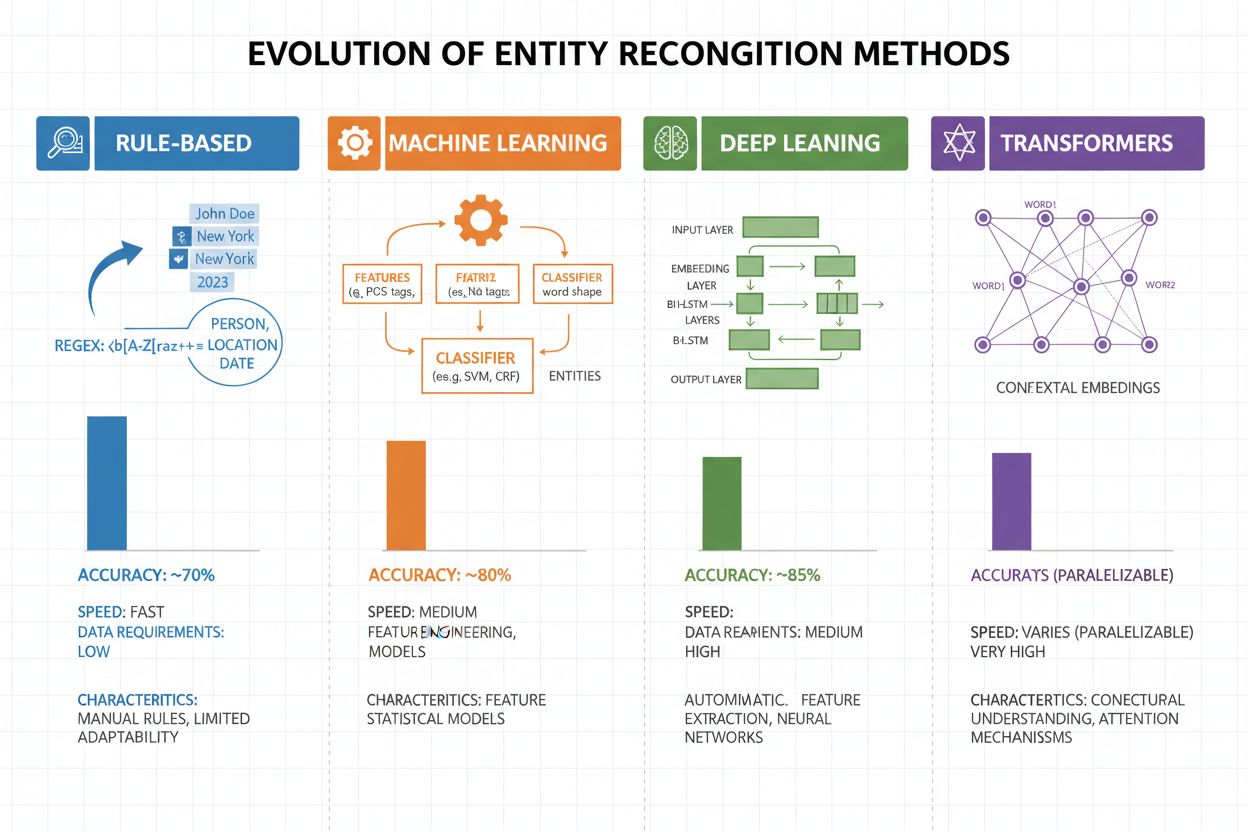
Enhedsgenkendelse har gennemgået en dramatisk udvikling de seneste to årtier, fra simple regelbaserede metoder til sofistikerede neurale arkitekturer. Tidlige systemer var baseret på håndlavede regler og ordbøger, hvor regulære udtryk og mønstergenkendelse blev brugt til at identificere enheder—metoder, der var fortolkelige og krævede minimal træningsdata, men som havde dårlig generalisering og høj vedligeholdelsesbyrde. Med maskinlæring kom superviseret tilgang som Support Vector Machines (SVM) og Conditional Random Fields (CRF), der lærte af mærkede data gennem feature engineering og markant forbedrede nøjagtigheden, selvom de stadig krævede domæneeksperter til at designe meningsfulde features. Deep learning-metoder, især LSTM og BiLSTM, automatiserede featureudtræk ved at lære repræsentationer direkte fra rå tekst og opnåede væsentligt højere nøjagtighed uden manuel feature engineering, men krævede større mærkede datasæt. Transformerbaserede modeller som BERT og RoBERTa revolutionerede feltet ved at udnytte self-attention-mekanismer til at indfange langtrækkende afhængigheder og kontekstuelle nuancer, opnåede state-of-the-art resultater (BERT nåede 90,9% F1 på CoNLL-2003) og muliggjorde transfer learning fra enorme fortrænede modeller. Afvejningen mellem kompleksitet og nøjagtighed har ændret sig markant: Mens regelbaserede systemer stadig er værdifulde i ressourcemæssigt begrænsede miljøer og meget specialiserede domæner, dominerer transformer-modeller nu, hvor der er tilstrækkelige beregningsressourcer og mærkede data, med lettere alternativer som DistilBERT som en mellemvej for produktionssystemer med latenskrav.
Transformerbaserede modeller har fundamentalt ændret enhedsgenkendelse ved at erstatte sekventiel behandling med parallelle self-attention-mekanismer, der samtidigt overvejer alle tokens i en sætning og muliggør rigere kontekstforståelse end tidligere arkitekturer. BERT og dets varianter (RoBERTa, DistilBERT, ALBERT) udnytter bidirektionel fortræning på enorme ukontrollerede tekstmængder og lærer universelle sprog-repræsentationer, der indfanger både syntaktisk og semantisk information, før de finjusteres på NER-opgaver med relativt små mærkede datasæt. Pre-training og finetuning-paradigmet er særligt kraftfuldt for enhedsgenkendelse: Modeller fortrænet på milliarder af tokens udvikler robuste repræsentationer af sprogstruktur og enhedsmønstre, som derefter kan tilpasses specifikke domæner med blot tusindvis af mærkede eksempler, hvilket dramatisk reducerer datakravene sammenlignet med træning fra bunden. Transformere udmærker sig ved at håndtere enhedsforståelse gennem deres multi-head attention-mekanisme, hvor forskellige attention-heads kan specialisere sig i forskellige typer enhedsrelationer—nogle heads fokuserer på syntaktiske grænser, mens andre indfanger semantiske forbindelser mellem enheder og deres kontekst. Flersproget enhedsgenkendelse er blevet revolutioneret af modeller som mBERT og XLM-RoBERTa, der fortrænes på 100+ sprog samtidigt, hvilket muliggør zero-shot og few-shot transfer til lavressourcesprog og krydssproglig enhedslinking. Nye modeller som GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) går endnu længere ved at muliggøre instruktionsbaseret enhedsgenkendelse, hvor modeller kan identificere vilkårlige enhedstyper angivet i naturlige sprog-prompter uden opgavespecifik finetuning og repræsenterer et skifte mod mere fleksible og generaliserbare systemer til enhedsforståelse.
På trods af bemærkelsesværdige fremskridt står enhedsgenkendelsessystemer over for vedvarende udfordringer i den virkelige verden, hvor tvetydighed og kontekstafhængighed er blandt de mest vanskelige—ordet “Apple” kræver forståelse af, om det refererer til frugten eller teknologivirksomheden baseret på sammenhængen, og selv de bedste modeller kæmper med semantisk disambiguering i støjende eller tvetydig tekst. Out-of-vocabulary (OOV) enheder udgør en anden grundlæggende udfordring: Modeller trænet på standarddatasæt kan aldrig støde på sjældne enheder, egennavne fra nye domæner eller stavefejl, hvilket får dem til enten at fejlklassificere eller undlade at genkende disse enheder helt. Domænetilpasning forbliver problematisk, fordi modeller trænet på nyhedskorpusser (som CoNLL-2003) ofte klarer sig dårligt på biomedicinsk, juridisk eller social media-tekst, hvor enhedsfordelingen og sprogmønstre adskiller sig markant, hvilket kræver dyr gen-annotering og finetuning for hvert nyt domæne. Fejl i grænsegenkendelse—hvor systemer korrekt identificerer, at en enhed eksisterer, men forkert bestemmer dens start- eller slutposition—er især almindelige ved flerords-enheder og indlejrede strukturer, såsom at skelne “New York City” fra “New York” eller håndtere enheder som “Chief Executive Officer of Apple Inc.” Flersproglige kompleksiteter forstærker disse udfordringer, da forskellige sprog har forskellige regler for store/små bogstaver, morfologiske strukturer og navngivningsmønstre, hvilket gør, at modeller trænet på engelsk ofte fejler på sprog med andre sproglige egenskaber. Datamangel for specialiserede domæner som sjældne sygdomsnavne, nye teknologier eller proprietære virksomhedsterminer skaber en flaskehals, hvor omkostningen ved manuel annotering er uoverkommelig, hvilket tvinger praktikere til at vælge mellem lavere nøjagtighed eller store investeringer i domænespecifik datainnsamling.
Enhedsforståelse er blevet uundværlig på tværs af brancher og forandrer, hvordan organisationer udtrækker værdi fra ustruktureret tekst. Inden for informationsudtræk og vidensgrafkonstruktion muliggør enhedsgenkendelse automatisk befolkning af strukturerede databaser fra dokumenter, hvilket driver søgemaskiner og anbefalingssystemer, der forstår relationer mellem personer, steder og begreber. Sundhedsorganisationer udnytter enhedsforståelse til at identificere medicinnavne, doser, symptomer og patientdemografi fra kliniske noter, hvilket forbedrer beslutningsstøtte og gør det muligt for farmakovigilanssystemer at opdage bivirkninger i stor skala. Finansielle institutioner bruger enhedsgenkendelse til at udtrække aktiesymboler, pengeværdier og markedsbegivenheder fra nyhedsfeeds og regnskaber, hvilket gør det muligt for algoritmiske handelssystemer og risikostyringsplatforme at reagere på markedsbevægende information i realtid. Juridiske teknologivirksomheder anvender enhedsforståelse til automatisk at identificere parter, datoer, forpligtelser og ansvarsparagraffer i kontrakter, hvilket reducerer advokaters dokumentgennemgang fra uger til timer. Kundeservice- og chatbotplatforme bruger enhedsgenkendelse til at udtrække brugerintentioner og relevant kontekst—såsom ordrenumre, produktnavne og problemtyper—hvilket muliggør mere præcis routing og hurtigere løsning. E-handelsplatforme anvender enhedsforståelse til at identificere produktnavne, mærker, funktioner og specifikationer fra kundeanmeldelser og søgeforespørgsler, hvilket forbedrer produktsøgning og personalisering. Indholds-anbefalingssystemer bruger enhedsgenkendelse til at forstå, hvilke enheder brugerne interagerer med, hvilket muliggør mere avanceret kollaborativ filtrering og indholdsbaserede anbefalinger, der øger engagement og indtjening.
Implementering af et produktionsklart enhedsforståelsessystem kræver omhyggelig dataforberedelse, modelvalg og evaluering. Start med højkvalitets annoterede data: Fastlæg klare definitioner af enhedstyper, brug inter-annotator agreement-målinger for at sikre konsistens, og sigt efter mindst 500-1000 mærkede eksempler pr. enhedstype, selvom domænespecifikke applikationer kan kræve mere. Modelvalg afhænger af dine begrænsninger: Regelbaserede systemer tilbyder fortolkelighed og lav latens til veldefinerede domæner, traditionelle maskinlæringsmodeller (CRF, SVM) giver god ydeevne med moderate datamængder, mens transformerbaserede modeller (BERT, RoBERTa) leverer state-of-the-art nøjagtighed, men kræver flere ressourcer og data. Trænings- og finetuningstrategier bør inkludere dataforøgelsesteknikker til håndtering af klasseubalance, krydsvalidering for at forhindre overfitting og omhyggelig tuning af hyperparametre for læringsrate og batchstørrelse. Evaluer dit system med præcision (korrekte enheder identificeret), recall (fundne enheder ud af alle faktiske enheder) og F1-score (harmonisk gennemsnit af begge), med separate målinger for hver enhedstype for at identificere svage områder. Implementeringsovervejelser omfatter latenskrav (batch vs. realtidsbehandling), skalerbarhedsbehov og integration med eksisterende datapipelines, mens overvågning efter implementering bør følge op på performance drift, falsk positive rater og brugerfeedback for at udløse nye træningscyklusser.
Økosystemet af værktøjer til enhedsforståelse tilbyder løsninger til ethvert behov og skala. Open source-biblioteker som spaCy leverer produktionsklare NER-pipelines med imponerende ydeevne (89,22% F1-score på standard benchmarks) og fremragende dokumentation, hvilket gør det ideelt for teams med ML-ekspertise; NLTK tilbyder læringsværdi og grundlæggende NER-funktionalitet; og Hugging Face Transformers giver adgang til førende fortrænede modeller, der kan finjusteres til specifikke domæner med minimal kode. Cloud-baserede managed services eliminerer infrastrukturbekymringer: Google Cloud Natural Language API, AWS Comprehend og IBM Watson NLP tilbyder fortrænet enhedsgenkendelse med understøttelse af flere sprog og enhedstyper, håndterer skalering automatisk og integrerer problemfrit med cloud-datapipelines. Specialiserede frameworks som Flair (bygget på PyTorch med fremragende sekvensmærkning) og DeepPavlov (med fortrænede modeller til flere sprog og domæner) henvender sig til forskere og teams, der har brug for mere tilpasning end generelle biblioteker giver. Valget mellem at bygge egne løsninger og bruge færdige værktøjer afhænger af datasensitivitet (on-premise vs. cloud), ønsket nøjagtighed, domænespecificitet og teamets ekspertise: Brug managed APIs til generelle formål med standardenheder, open source-biblioteker til domænespecifik tilpasning med interne data, og byg kun egne modeller, hvis eksisterende løsninger ikke kan opfylde krav til nøjagtighed eller latens.
Fremtiden for enhedsforståelse formes af store sprogmodeller, der bringer hidtil uset fleksibilitet og ydeevne til opgaven. Modeller som GPT-4 og Claude demonstrerer imponerende few-shot og zero-shot enhedsgenkendelse, så organisationer kan identificere brugerdefinerede enhedstyper med blot få eksempler eller endda naturlige sprogbeskrivelser, hvilket drastisk reducerer annoteringsbyrden og accelererer time-to-value. Multimodal enhedsforståelse er ved at blive et nyt område, hvor tekst, billeder og strukturerede data kombineres for at genkende enheder i dokumenter, fakturaer og websider med rigere kontekst og muliggør applikationer som automatiseret dokumentbehandling og visuel søgning. Forbedringer i realtidsbehandling drevet af modeldestillation og edge-implementering gør avanceret enhedsgenkendelse mulig på mobile enheder og IoT-systemer, hvilket åbner nye anvendelser i augmented reality, realtidsoversættelse og autonome systemer. Fremskridt i domænespecifik finetuning skaber specialiserede modeller til biomedicinske, juridiske og finansielle domæner, der overgår generelle modeller markant, og teknikker som domæneadaptiv fortræning og transfer learning gør dette stadig mere tilgængeligt. Efterhånden som disse teknologier modnes, bliver enhedsforståelse et usynligt fundamentlag i AI-systemer, der gør maskiner i stand til at forstå verden med menneskelignende semantisk indsigt og åbner muligheder, vi kun lige er begyndt at ane.
Efterhånden som AI-systemer som ChatGPT, Perplexity og Google AI Overviews bliver stadig mere integreret i måden information opdages og forbruges på, bliver det kritisk at forstå, hvordan disse systemer genkender og refererer til enheder—herunder dit brand. Enhedsforståelse er mekanismen, hvorved AI-systemer identificerer og bearbejder omtaler af virksomheder, produkter, personer og begreber. Når du overvåger, hvordan AI-systemer forstår og refererer til dit brand via enhedsgenkendelse, får du indsigt i:
Det er præcis det, AmICited overvåger—sporer hvordan AI-systemer genkender og refererer til dit brand som en enhed på tværs af flere AI-platforme. Ved at forstå enhedsgenkendelse kan du bedre forstå, hvordan AI-systemer opfatter og kommunikerer om din virksomhed.
Enhedsgenkendelse (NER) identificerer og klassificerer enheder i tekst (f.eks. 'Apple' som ORGANISATION), mens enhedslinking forbinder disse enheder til vidensbaser eller kanoniske referencer (f.eks. at linke 'Apple' til Wikipedia-siden for Apple Inc.). Enhedsgenkendelse er det første skridt; enhedslinking tilføjer semantisk forankring.
State-of-the-art transformerbaserede modeller som BERT opnår 90,9% F1-score på standard benchmarks som CoNLL-2003. Dog varierer nøjagtigheden betydeligt afhængigt af domænet—modeller trænet på nyheder klarer sig dårligt på biomedicinsk eller sociale medier tekst. Den reelle nøjagtighed afhænger i høj grad af domænetilpasning og datakvalitet.
Ja, flersproglige modeller som mBERT og XLM-RoBERTa understøtter 100+ sprog samtidigt. Dog varierer præstationen afhængigt af sprog på grund af forskelle i store/små bogstaver, morfologi og tilgængelige træningsdata. Sprogspecifikke modeller overgår typisk flersprogede til kritiske applikationer.
Regelbaserede systemer bruger håndlavede mønstre og ordbøger (hurtigt, fortolkeligt, men skrøbeligt). ML-baserede systemer lærer af mærkede data (mere fleksible, bedre generalisering, men kræver træningsdata og feature engineering). Moderne deep learning-tilgange automatiserer featureudtræk og opnår overlegne resultater.
Regelbaserede systemer kræver kun mønstergenkendelse. Traditionelle ML-modeller kræver 300-500 mærkede eksempler. Transformerbaserede modeller fungerer med 800+ eksempler, men drager fordel af transfer learning—fortrænede modeller kan opnå gode resultater med blot 100-200 domænespecifikke eksempler via finjustering.
Væsentlige udfordringer omfatter: tvetydighed (samme ord betyder forskellige ting), out-of-vocabulary-enheder, domænetilpasning (modeller trænet på ét domæne fejler på et andet), fejl i grænsegenkendelse, flersproglige kompleksiteter og mangel på data i specialiserede domæner. Disse kræver omhyggelig systemdesign og domænespecifik tuning.
Kontekst er afgørende—'bank' betyder noget forskelligt i 'river bank' vs. 'savings bank.' Moderne transformers bruger self-attention til at vægte kontekst fra alle omgivende tokens, hvilket gør dem i stand til at afklare enheder ud fra sproglig og semantisk kontekst. Dårlig konteksthåndtering er en væsentlig fejlkilde i enhedsgenkendelse.
Fremtidige udviklinger omfatter: store sprogmodeller der muliggør zero-shot enhedsgenkendelse, multimodal forståelse der kombinerer tekst og billeder, realtidsbehandling på edge-enheder og fremskridt i domænespecifik finjustering. Enhedsforståelse bliver et usynligt fundamentlag, der gør maskiner i stand til at forstå verden med menneskelignende semantisk forståelse.
AmICited sporer enhedsomtaler på tværs af AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Forstå hvordan AI forstår og refererer til dit brand i realtid.
Lær, hvordan AI-systemer identificerer, udtrækker og forstår relationer mellem enheder i tekst. Oplev teknikker til udtrækning af enhedsrelationer, NLP-metoder ...

Entity Recognition er en AI NLP-egenskab, der identificerer og kategoriserer navngivne enheder i tekst. Lær hvordan det fungerer, dets anvendelser i AI-overvågn...
Lær hvordan du identificerer relaterede emner for AI med emnemodellering, klyngealgoritmer og semantisk analyse. Oplev LDA, LSA, embeddings og praktiske teknikk...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.