
AI-crawlere forklaret: GPTBot, ClaudeBot og flere
Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...
12 min læsning

Opdag de afgørende forskelle mellem AI-træningscrawlere og søgecrawlere. Lær hvordan de påvirker din indholds synlighed, optimeringsstrategier og AI-citater.
Søgemaskinecrawlere som Googlebot og Bingbot er rygraden i traditionelle søgemaskiners drift. Disse automatiske bots navigerer systematisk på nettet, opdager og indekserer indhold for at afgøre, hvad der vises på søgemaskinernes resultatsider (SERPs). Googlebot, som drives af Google, er den mest kendte og aktive søgecrawler, efterfulgt af Bingbot fra Microsoft og YandexBot fra Yandex. Disse crawlere har sofistikerede evner, der gør dem i stand til at eksekvere JavaScript, gengive dynamisk indhold og forstå komplekse webstedsstrukturer. De besøger websites hyppigt baseret på faktorer som siteautoritet, indholdets friskhed og opdateringshistorik, hvor sites med høj autoritet får hyppigere besøg. Det primære mål for søgecrawlere er at indeksere indhold til rangeringsformål, hvilket betyder, at de vurderer sider ud fra relevans, kvalitet og signaler om brugeroplevelse.
| Crawler-type | Primært formål | JavaScript-understøttelse | Crawl-frekvens | Mål |
|---|---|---|---|---|
| Googlebot | Indeksér til søgerangeringer | Ja (med begrænsninger) | Hyppig, baseret på autoritet | Rangering & synlighed |
| Bingbot | Indeksér til søgerangeringer | Ja (med begrænsninger) | Regelmæssig, baseret på indholdsopdateringer | Rangering & synlighed |
| YandexBot | Indeksér til søgerangeringer | Ja (med begrænsninger) | Regelmæssig, baseret på site-signaler | Rangering & synlighed |
AI-træningscrawlere repræsenterer en fundamentalt anderledes kategori af web-bots, der er designet til at indsamle data til træning af store sprogmodeller (LLMs) fremfor til søgeindeksering. GPTBot, som drives af OpenAI, er den mest fremtrædende AI-træningscrawler, sammen med ClaudeBot fra Anthropic, PetalBot fra Huawei og Common Crawl’s CCBot. I modsætning til søgecrawlere, som har til formål at rangere indhold, fokuserer AI-træningscrawlere på at indsamle indhold af høj kvalitet og med rig kontekst for at forbedre videnbasen og svargenereringen i AI-modeller. Disse crawlere opererer typisk med lavere frekvens end søgecrawlere, ofte med besøg kun hver få uger eller måneder, og de prioriterer indholdskvalitet fremfor volumen. Distinktionen er afgørende: dit indhold kan være grundigt indekseret af Googlebot for søgesynlighed, men kun delvist eller sjældent crawlet af GPTBot til AI-modeller.
| Crawler-type | Primært formål | JavaScript-understøttelse | Crawl-frekvens | Mål |
|---|---|---|---|---|
| GPTBot | Indsaml data til LLM-træning | Nej | Sjælden, selektiv | Træningsdatakvalitet |
| ClaudeBot | Indsaml data til LLM-træning | Nej | Sjælden, selektiv | Træningsdatakvalitet |
| PetalBot | Indsaml data til LLM-træning | Nej | Sjælden, selektiv | Træningsdatakvalitet |
| CCBot | Indsaml data til Common Crawl | Nej | Sjælden, selektiv | Træningsdatakvalitet |
De tekniske forskelle mellem søgecrawlere og AI-træningscrawlere skaber væsentlige konsekvenser for indholdssynlighed. Den mest kritiske forskel er JavaScript-eksekvering: søgecrawlere som Googlebot kan eksekvere JavaScript (dog med visse begrænsninger), hvilket gør dem i stand til at se dynamisk gengivet indhold. AI-træningscrawlere derimod eksekverer slet ikke JavaScript – de parser kun den rå HTML, der er tilgængelig ved den indledende sideindlæsning. Denne grundlæggende forskel betyder, at indhold, der indlæses dynamisk via klient-side scripts, forbliver fuldstændig usynligt for AI-crawlere. Derudover respekterer søgecrawlere crawl-budgetter og prioriterer sider baseret på sitearkitektur og interne links, mens AI-crawlere benytter mere selektive, kvalitetsdrevne crawl-mønstre. Søgecrawlere følger generelt robots.txt-regler strengt, mens visse AI-crawlere historisk har været mindre gennemsigtige om deres overholdelse. Crawl-frekvensen adskiller sig markant: søgecrawlere besøger aktive sites flere gange om ugen eller endda dagligt, mens AI-træningscrawlere måske kun besøger én gang hver få uger eller måneder. Endvidere er søgecrawlere designet til at forstå rangeringssignaler og brugeroplevelsesmålinger, mens AI-crawlere fokuserer på at udtrække rent, velstruktureret tekstindhold til modeltræning.
| Funktion | Søgecrawlere | AI-træningscrawlere |
|---|---|---|
| JavaScript-eksekvering | Ja (med begrænsninger) | Nej |
| Crawl-frekvens | Høj (flere gange om ugen) | Lav (én gang hver få uger) |
| Indholds-parsing | Fuld sides gengivelse | Kun rå HTML |
| Robots.txt-overholdelse | Strikt | Variabel |
| Crawl-budget fokus | Autoritetsbaseret prioritering | Kvalitetsbaseret udvælgelse |
| Dynamisk indhold | Kan gengive og indeksere | Overser fuldstændigt |
| Primært mål | Rangering & søgesynlighed | Indsamling af træningsdata |
| Timeout-tolerance | Længere (tillader kompleks gengivelse) | Stram (1-5 sekunder) |
AI-crawleres manglende evne til at eksekvere JavaScript skaber et kritisk synlighedsgab, der påvirker mange moderne websites. Når et website er afhængigt af JavaScript til dynamisk at indlæse indhold – såsom produktbeskrivelser, kundeanmeldelser, prisinformation eller billeder – bliver dette indhold usynligt for AI-crawlere. Det er især problematisk for single-page applications (SPAs) bygget med React, Vue eller Angular, hvor det meste indhold indlæses klient-side efter den indledende HTML er serveret. For eksempel kan en e-handelsside vise produktstatus og priser via JavaScript, hvilket betyder at GPTBot kun ser en tom side eller et grundlæggende HTML-skelet. Ligeledes vil websites, der anvender lazy-loading til billeder eller infinite scroll til indhold, få disse elementer fuldstændig overset af AI-crawlere. Forretningsmæssigt er det betydeligt: hvis dine produktdetaljer, kundeudtalelser eller nøgleindhold er skjult bag JavaScript, har AI-systemer som ChatGPT og Perplexity ikke adgang til oplysningerne, når de genererer svar. Det betyder, at dit indhold kan rangere højt i Google, men være helt fraværende i AI-genererede svar, hvilket gør dig usynlig for en voksende brugergruppe, som benytter AI til informationssøgning.
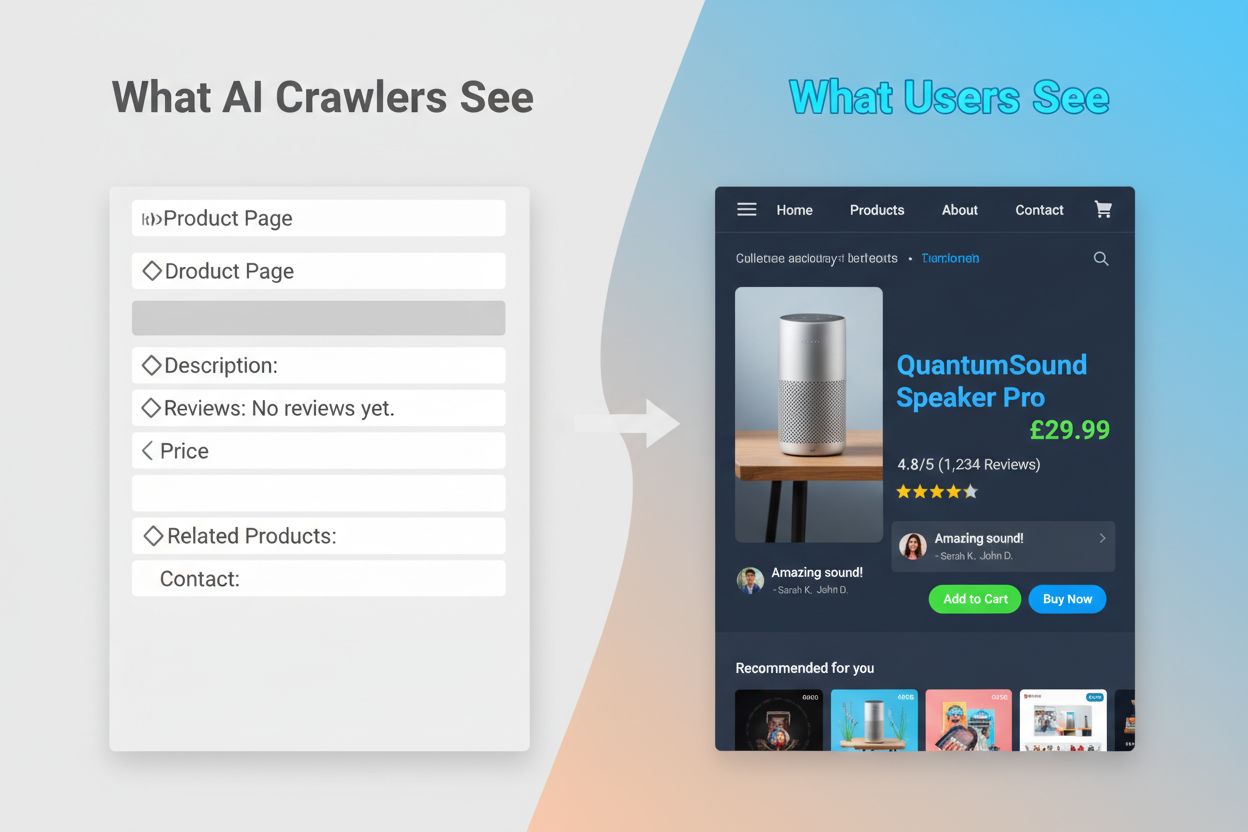
De praktiske konsekvenser af disse tekniske forskelle er dybtgående og ofte misforstået af website-ejere. Dit website kan opnå fremragende placeringer i Google, mens det samtidig er næsten usynligt for ChatGPT, Perplexity og andre AI-systemer. Dette skaber en paradoksal situation, hvor traditionel SEO-succes ikke garanterer AI-synlighed. Når brugere spørger ChatGPT om din branche eller dit produkt, kan AI-systemet citere dine konkurrenter i stedet for dig, blot fordi deres indhold var mere tilgængeligt for AI-crawlere. Forholdet mellem træningsdata og søgecitater tilføjer yderligere kompleksitet: indhold, der er brugt til at træne en AI-model, kan få forrang i modellens søgeresultater, hvilket betyder at blokering af AI-træningscrawlere potentielt kan reducere din synlighed i AI-drevne svar. For udgivere og indholdsskabere betyder det, at det strategiske valg om at tillade eller blokere AI-crawlere får reelle konsekvenser for fremtidig trafik. Et website, der blokerer GPTBot for at beskytte indhold mod træning, kan samtidig mindske sine chancer for at blive nævnt i ChatGPT’s søgeresultater. Omvendt giver det at tillade AI-crawlere adgang til dit indhold træningsdata, men det garanterer ikke citater eller trafik, hvilket skaber et ægte strategisk dilemma uden en perfekt løsning.
At forstå hvilke crawlere, der tilgår dit website, og hvor ofte de besøger, er afgørende for at optimere din indholdsstrategi. Logfile-analyse er den primære metode til at identificere crawler-aktivitet, da du kan segmentere og analysere serverlogs for at se, hvilke bots der har tilgået dit site, hvor ofte de har besøgt, og hvilke sider de har prioriteret. Ved at undersøge User-Agent-strenge i dine serverlogs kan du skelne mellem Googlebot, GPTBot, OAI-SearchBot og andre crawlere, hvilket afslører mønstre i deres adfærd. Centrale målepunkter at overvåge er crawl-frekvens (hvor ofte hver crawler besøger), crawl-dybde (hvor mange lag af din sitestruktur der crawles), og crawl-budget (det samlede antal sider crawlet i en given periode). Værktøjer som Google Search Console og Bing Webmaster Tools giver indsigt i søgecrawler-aktivitet, mens specialiserede løsninger som AmICited.com tilbyder omfattende overvågning af AI-crawleradfærd på tværs af flere platforme, herunder ChatGPT, Perplexity og Google AI Overviews. AmICited.com sporer specifikt, hvordan AI-systemer refererer til dit brand og indhold, og giver indsigt i hvilke AI-platforme, der citerer dig og hvor ofte. At forstå disse mønstre hjælper dig med at identificere tekniske problemer tidligt, optimere din crawl-budget allokering og træffe informerede beslutninger om crawler-adgang og indholdsoptimering.
Optimering for traditionelle søgecrawlere kræver fokus på etablerede tekniske SEO-grundpiller, som sikrer, at dit indhold er opdageligt og kan indekseres. Følgende strategier er fortsat essentielle for at opretholde stærk søgesynlighed:
Søgemaskiner som Google fokuserer i stigende grad på crawl-effektivitet, og Googles repræsentanter har antydet, at Googlebot vil crawle mindre i fremtiden. Det betyder, at dit website skal være så strømlinet og let at forstå som muligt, med klare hierarkier og effektiv intern linking, der guider crawlere direkte til dine vigtigste sider.
Optimering for AI-træningscrawlere kræver en anden tilgang med fokus på indholdskvalitet, klarhed og tilgængelighed fremfor rangeringssignaler. Da AI-crawlere prioriterer velstruktureret, kontekstrigt indhold, bør din optimeringsstrategi lægge vægt på grundighed og læsbarhed. Undgå JavaScript-afhængigt indhold til kritiske oplysninger – sørg for at produktdetaljer, priser, anmeldelser og nøgledata er til stede i rå HTML, hvor AI-crawlere kan tilgå dem. Skab omfattende, dybdegående indhold der dækker emner grundigt og giver kontekst, som AI-modeller kan lære af. Brug klar formatering med overskrifter, punktlister og nummererede lister, der opdeler teksten og gør indholdet let at parse. Skriv med semantisk klarhed ved at bruge ligetil sprog uden unødvendig fagjargon, som kan forvirre AI-modeller. Implementér korrekt overskrifthierarki (H1, H2, H3) for at hjælpe AI-crawlere med at forstå indholdsstruktur og sammenhænge. Inkludér relevant metadata og schema markup, der giver kontekst om dit indhold. Sørg for hurtig sideindlæsning, da AI-crawlere har stramme timeouts (typisk 1-5 sekunder) og kan springe langsomme sider over.
Den væsentligste forskel fra søgeoptimering er, at AI-crawlere er ligeglade med rangeringssignaler, backlinks eller keyword density. I stedet værdsætter de indhold, der er klart, velorganiseret og informationsrigt. En side, der måske ikke rangerer højt i Google, kan være meget værdifuld for AI-modeller, hvis den indeholder omfattende, velstruktureret information om et emne.
Landskabet for webcrawling udvikler sig hurtigt, og AI-crawlere bliver stadig vigtigere for indholdssynlighed og brand awareness. Efterhånden som AI-drevne søgeværktøjer som ChatGPT, Perplexity og Google AI Overviews vinder indpas blandt brugerne, vil evnen til at blive opdaget og citeret af disse systemer blive lige så kritisk som traditionelle søgerangeringer. Skellet mellem træningscrawlere og søgecrawlere vil sandsynligvis blive mere nuanceret, hvor virksomheder muligvis tilbyder en tydeligere opdeling mellem datainnsamling og søgehentning, ligesom OpenAI gør med GPTBot og OAI-SearchBot. Website-ejere skal udvikle strategier, der balancerer traditionel SEO-optimering med AI-synlighed og anerkende, at disse er komplementære fremfor konkurrerende mål. Fremkomsten af specialiserede overvågningsværktøjer og løsninger vil gøre det lettere at spore crawler-aktivitet på både traditionelle og AI-platforme og muliggøre datadrevne beslutninger om crawler-adgang og indholdsoptimering. De, der tidligt optimerer for både søge- og AI-crawlere, får et konkurrencemæssigt forspring og positionerer deres indhold til at blive opdaget gennem flere kanaler, efterhånden som søgelandskabet udvikler sig. Fremtidens indholdssynlighed afhænger af, at man forstår og optimerer for hele spektret af crawlere, der opdager og anvender dit indhold.
Søgecrawlere som Googlebot indekserer indhold til søgerangeringer og kan eksekvere JavaScript for at se dynamisk indhold. AI-træningscrawlere som GPTBot indsamler data til at træne LLMs og kan typisk ikke eksekvere JavaScript, hvilket betyder at de går glip af dynamisk indlæst indhold. Denne fundamentale forskel betyder, at dit website kan rangere højt i Google, men være næsten usynligt for ChatGPT.
Ja, du kan bruge robots.txt til at blokere specifikke AI-crawlere som GPTBot, mens du tillader søgecrawlere. Dette kan dog reducere din synlighed i AI-genererede svar og opsummeringer. Det strategiske valg afhænger af, om du prioriterer indholdsbeskyttelse over potentiel AI-henvisningstrafik.
AI-crawlere som GPTBot parser kun rå HTML ved den indledende sideindlæsning og eksekverer ikke JavaScript. Indhold, der indlæses dynamisk via scripts – såsom produktdetaljer, anmeldelser eller billeder – forbliver fuldstændig usynligt for dem. Dette er en kritisk begrænsning for moderne websites, der i høj grad er afhængige af client-side rendering.
AI-træningscrawlere besøger typisk sjældnere end søgecrawlere, med længere intervaller mellem besøgene. De prioriterer indhold med høj autoritet og kan kun crawle en side én gang hver få uger eller måneder. Dette sjældne crawl-mønster afspejler deres fokus på kvalitet frem for volumen.
Produktdetaljer, kundeanmeldelser, lazy-loadede billeder, interaktive elementer (faner, karuseller, modaler), prisinformation og alt indhold skjult bag JavaScript er mest sårbart. For e-handel og SPA-baserede websites kan dette udgøre en betydelig del af kritisk indhold.
Sørg for at nøgleindhold er til stede i rå HTML, forbedr hastigheden på websitet, brug klar struktur og formatering med korrekt overskrifthierarki, implementér schema markup og undgå, at kritisk indhold er afhængigt af JavaScript. Målet er at gøre dit indhold tilgængeligt for både traditionelle og AI-crawlere.
Logfile-analyseværktøjer, Google Search Console, Bing Webmaster Tools og specialiserede crawler-overvågningsløsninger som AmICited.com kan hjælpe med at spore crawleradfærd. AmICited.com overvåger specifikt, hvordan AI-systemer refererer til dit brand på tværs af ChatGPT, Perplexity og Google AI Overviews.
Potentielt ja. Selvom blokering af træningscrawlere kan beskytte dit indhold, kan det reducere din synlighed i AI-drevne søgeresultater og opsummeringer. Derudover forbliver indhold, der allerede er crawlet før blokering, i de trænede modeller. Beslutningen kræver en balance mellem indholdsbeskyttelse og potentiel tab af AI-dreven opdagelse.
Følg hvordan AI-systemer refererer til dit brand på tværs af ChatGPT, Perplexity og Google AI Overviews. Få realtidsindsigt i din AI-synlighed og optimer din indholdsstrategi.
Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...

Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
Lær hvordan du tillader AI-bots som GPTBot, PerplexityBot og ClaudeBot at crawle dit website. Konfigurer robots.txt, opsæt llms.txt og optimer for AI-synlighed....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.