
AI Crawler Reference Card: Alle Bots på et Øjeblik
Komplet referenceguide til AI-crawlere og bots. Identificer GPTBot, ClaudeBot, Google-Extended og 20+ andre AI-crawlere med brugeragenter, crawl-hastigheder og ...
14 min læsning

Lær hvordan du blokerer eller tillader AI-crawlere som GPTBot og ClaudeBot ved hjælp af robots.txt, server-niveau blokering og avancerede beskyttelsesmetoder. Komplet teknisk guide med eksempler.
Det digitale landskab har fundamentalt ændret sig fra traditionel søgemaskineoptimering til håndtering af en helt ny kategori af automatiske besøgende: AI-crawlere. I modsætning til konventionelle søgebots, der driver trafik tilbage til dit site via søgeresultater, bruger AI-træningscrawlere dit indhold til at opbygge store sprogmodeller uden nødvendigvis at sende henvisningstrafik tilbage. Denne forskel har dybtgående konsekvenser for udgivere, indholdsskabere og virksomheder, der er afhængige af webtrafik som indtægtskilde. Indsatsen er høj—kontrol over hvilke AI-systemer, der får adgang til dit indhold, har direkte indflydelse på din konkurrencefordel, dataprivatliv og bundlinje.
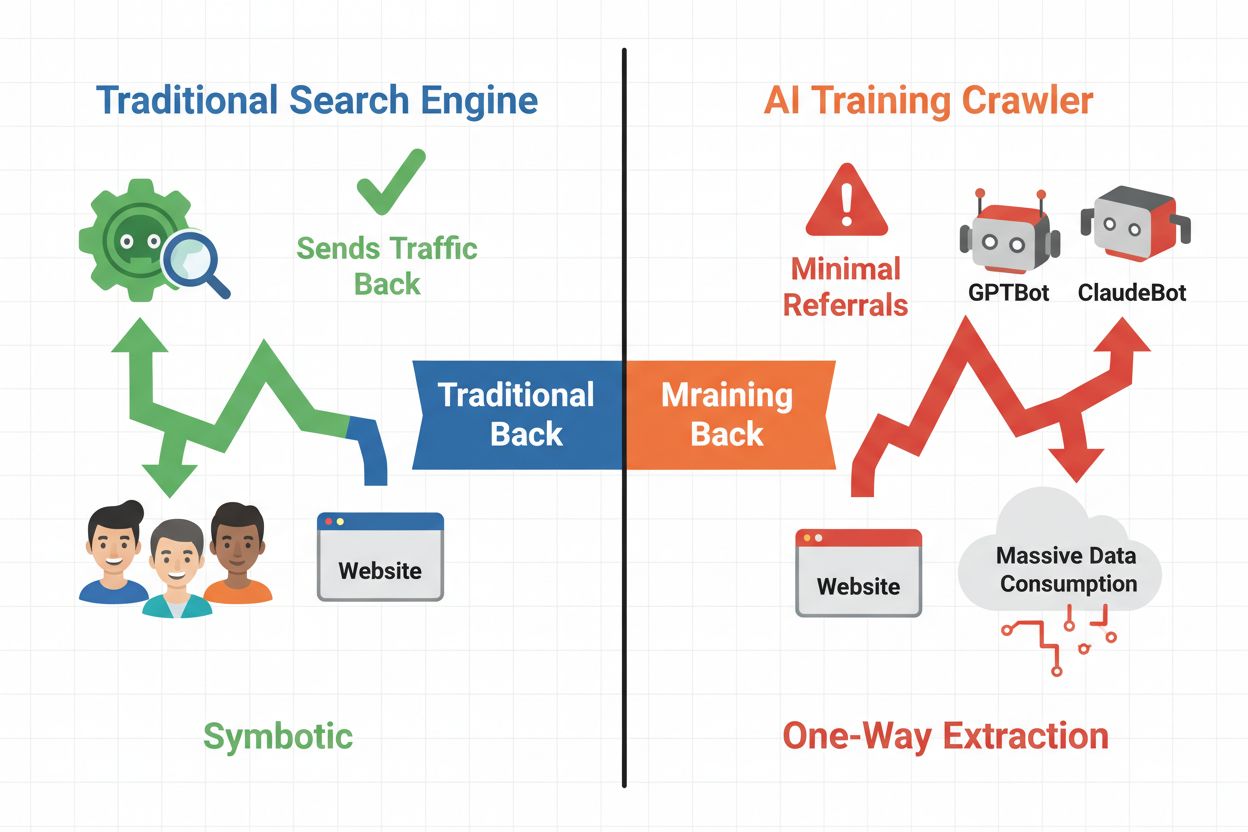
AI-crawlere falder i tre forskellige kategorier, hver med forskellige formål og trafikpåvirkninger. Træningscrawlere bruges af AI-firmaer til at opbygge og forbedre deres sprogmodeller, typisk i massiv skala med minimal tilbagevendende trafik. Søge- og citationscrawlere indekserer indhold til AI-drevne søgemaskiner og citationssystemer og driver ofte noget henvisningstrafik tilbage til udgivere. Brugerudløste crawlere henter indhold on-demand, når brugere interagerer med AI-applikationer, og udgør et mindre men voksende segment. Forståelse af disse kategorier hjælper dig med at træffe informerede beslutninger om, hvilke crawlere du vil tillade eller blokere baseret på din forretningsmodel.
| Crawler-type | Formål | Trafikpåvirkning | Eksempler |
|---|---|---|---|
| Træning | Opbygge/forbedre LLMs | Minimal til ingen | GPTBot, ClaudeBot, Bytespider |
| Søge/Citation | Indeksering til AI-søgning & citationer | Moderat henvisningstrafik | Googlebot-Extended, Perplexity |
| Brugerudløst | Hent on-demand til brugere | Lav men stabil | ChatGPT plugins, Claude browsing |
AI-crawler-økosystemet omfatter crawlere fra verdens største teknologiselskaber, hver med forskellige user agents og formål. OpenAI’s GPTBot (user agent: GPTBot/1.0) crawler for at træne ChatGPT og andre modeller, mens Anthropic’s ClaudeBot (user agent: Claude-Web/1.0) tjener tilsvarende formål for Claude. Google’s Googlebot-Extended (user agent: Mozilla/5.0 ... Googlebot-Extended) indekserer indhold til AI Overviews og Bard, mens Meta’s Meta-ExternalFetcher crawler for deres AI-initiativer. Andre store aktører inkluderer:
Hver crawler opererer i forskellig skala og respekterer blokeringer med varierende grad af overholdelse.
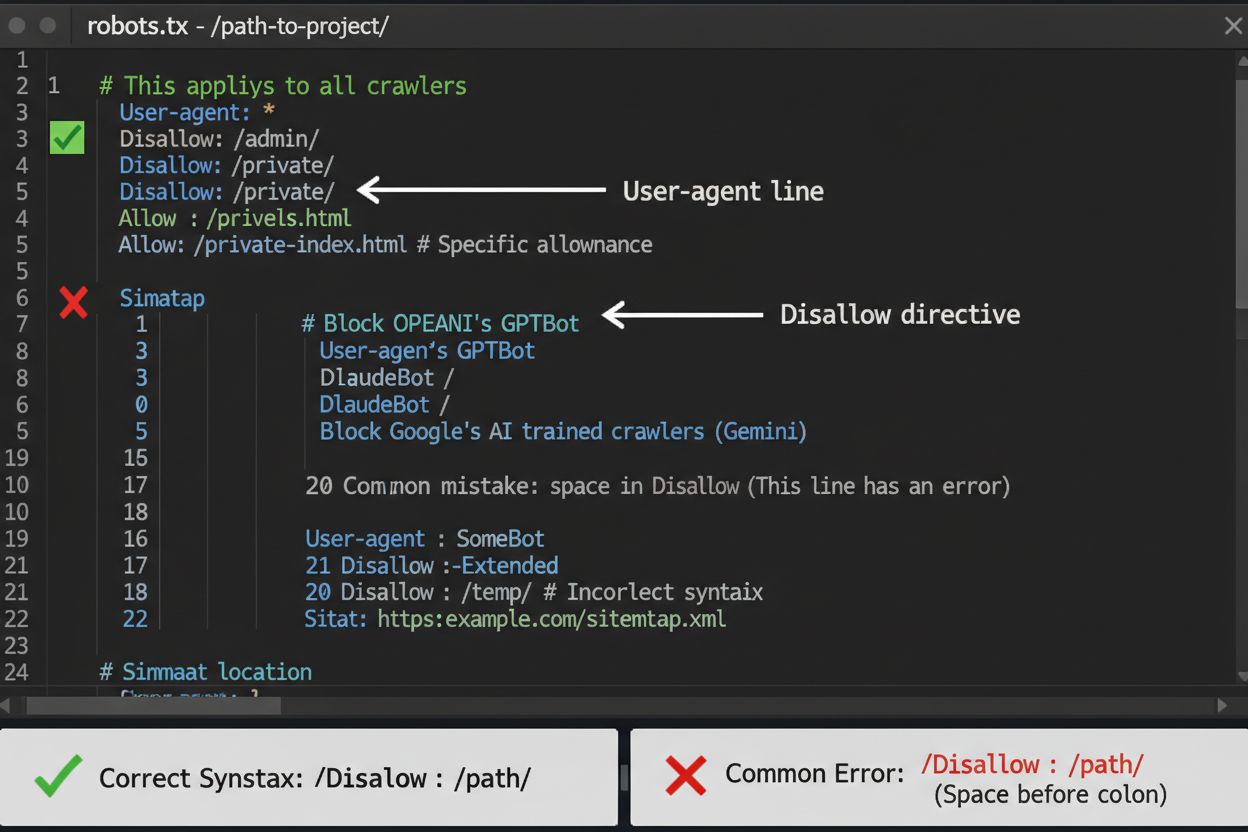
robots.txt-filen er dit første forsvarslag til kontrol af AI-crawler-adgang, selv om det er vigtigt at forstå, at den kun er vejledende og ikke juridisk bindende. Den er placeret i roden af dit domæne (f.eks. dinside.com/robots.txt) og bruger enkel syntaks til at instruere crawlere, hvilke områder de skal undgå. For at blokere alle AI-crawlere fuldstændigt, tilføj følgende regler:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Hvis du foretrækker selektiv blokering—tillader søgecrawlere, mens du blokerer træningscrawlere—brug denne tilgang:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
En almindelig fejl er at bruge for brede regler som Disallow: *, der kan forvirre parserne, eller at glemme at specificere enkelte crawlere, hvis du kun vil blokere bestemte. Store virksomheder som OpenAI, Anthropic og Google respekterer generelt robots.txt-direktiver, mens nogle crawlere som Perplexity er dokumenteret for helt at ignorere disse regler.
Når robots.txt ikke er tilstrækkelig, findes der flere stærkere beskyttelsesmetoder, der giver øget kontrol over AI-crawler-adgang. IP-baseret blokering indebærer at identificere AI-crawler IP-ranges og blokere dem på firewall- eller serverniveau—det er meget effektivt, men kræver løbende vedligeholdelse, da IP-ranges ændrer sig. Blokering på serverniveau via .htaccess-filer (Apache) eller Nginx-konfigurationsfiler giver mere granulær kontrol og er sværere at omgå end robots.txt. For Apache-servere kan du implementere denne blokering:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Meta-tag blokering med <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> forhindrer indeksering, men stopper ikke træningscrawlere. Request header-verifikation tjekker, om crawlere reelt kommer fra de påståede kilder ved at verificere reverse DNS og SSL-certifikater. Brug blokering på serverniveau, når du har brug for absolut sikkerhed for, at crawlere ikke får adgang til dit indhold, og kombiner flere metoder for maksimal beskyttelse.
At beslutte om du skal blokere AI-crawlere kræver en afvejning af flere konkurrerende interesser. Blokering af træningscrawlere (GPTBot, ClaudeBot, Bytespider) forhindrer, at dit indhold bruges til at træne AI-modeller, hvilket beskytter din intellektuelle ejendom og konkurrencefordel. Ved at tillade søgecrawlere (Googlebot-Extended, Perplexity) kan du dog få henvisningstrafik og øge synligheden i AI-drevne søgeresultater—en voksende kanal for opdagelse. Afvejningen kompliceres yderligere af, at nogle AI-virksomheder har dårlige forhold mellem crawl og henvisning: Anthropic’s crawlere genererer cirka 38.000 crawl-forespørgsler for hver enkelt henvisning, mens OpenAI’s forhold er omtrent 400:1. Serverbelastning og båndbredde er en anden faktor—AI-crawlere bruger betydelige ressourcer, og blokering kan reducere infrastrukturudgifter. Din beslutning bør tilpasses din forretningsmodel: nyhedsorganisationer og udgivere kan have gavn af henvisningstrafik, mens SaaS-virksomheder og ejere af proprietært indhold typisk foretrækker blokering.
Implementering af crawler-blokeringer er kun halvdelen af arbejdet—du skal sikre, at crawlerne faktisk respekterer dine direktiver. Analyse af serverlogs er dit primære verifikationsværktøj; gennemgå dine adgangslogs for user agent-strenge og IP-adresser for crawlere, der forsøger at tilgå dit site efter blokering. Brug grep til at søge i dine logs:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Denne kommando tæller, hvor mange gange disse crawlere har tilgået dit site. Testværktøjer såsom curl kan simulere crawler-forespørgsler for at verificere, at dine blokeringer fungerer korrekt:
curl -A "GPTBot/1.0" https://dinside.com/robots.txt
Overvåg dine logs ugentligt den første måned efter implementering af blokeringer, derefter kvartalsvis. Hvis du opdager crawlere, der ignorerer din robots.txt, gå videre til blokering på serverniveau eller kontakt crawler-operatørens abuse-team.
AI-crawler-landskabet udvikler sig hurtigt, efterhånden som nye virksomheder lancerer AI-produkter, og eksisterende crawlere ændrer deres user agent-strenge og IP-ranges. Kvartalsvise gennemgange af din blokliste sikrer, at du ikke overser nye crawlere eller ved en fejl blokerer legitim trafik. Crawler-økosystemet er fragmenteret og decentraliseret, hvilket gør det umuligt at oprette en virkelig permanent blokliste. Overvåg disse ressourcer for opdateringer:
Sæt kalenderpåmindelser til at gennemgå din robots.txt og serverregler hver 90. dag, og abonner på sikkerhedsmailinglister, der følger nye crawler-udrulninger.
Selvom blokering af AI-crawlere forhindrer dem i at tilgå dit indhold, adresserer AmICited den komplementære udfordring: at overvåge, om AI-systemer citerer og refererer til dit brand og indhold i deres output. AmICited sporer omtaler af din organisation i AI-genererede svar og giver overblik over, hvordan dit indhold påvirker AI-modellers output, og hvor dit brand optræder i AI-søgeresultater. Det skaber en komplet AI-strategi: Du kontrollerer, hvad crawlere har adgang til via robots.txt og serverblokering, mens AmICited sikrer, at du forstår den nedstrøms effekt af dit indhold i AI-systemer. Sammen giver disse værktøjer dig fuldt overblik og kontrol over din tilstedeværelse i AI-økosystemet—fra at forhindre uønsket brug til træningsdata til at måle de faktiske citater og referencer, dit indhold genererer på tværs af AI-platforme.
Nej. Blokering af AI-træningscrawlere som GPTBot, ClaudeBot og Bytespider påvirker ikke dine Google- eller Bing-placeringer. Traditionelle søgemaskiner bruger andre crawlere (Googlebot, Bingbot), der arbejder uafhængigt. Blokér kun disse, hvis du helt vil forsvinde fra søgeresultaterne.
Store crawlere fra OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) og Perplexity (PerplexityBot) udtaler officielt, at de respekterer robots.txt-direktiver. Mindre eller mindre gennemsigtige bots kan dog ignorere din konfiguration, hvilket er grunden til, at lagdelte beskyttelsesstrategier findes.
Det afhænger af din strategi. Ved kun at blokere træningscrawlere (GPTBot, ClaudeBot, Bytespider) beskytter du dit indhold mod modeltræning, mens du tillader søgecrawlere at hjælpe dig med at fremstå i AI-søgeresultater. Fuld blokering fjerner dig helt fra AI-økosystemer.
Gennemgå din konfiguration mindst hvert kvartal. AI-virksomheder introducerer regelmæssigt nye crawlere. Anthropic fusionerede deres 'anthropic-ai' og 'Claude-Web' bots til 'ClaudeBot', hvilket gav den nye bot midlertidig ubegrænset adgang til sider, der ikke havde opdateret deres regler.
Blokering forhindrer crawlere i helt at tilgå dit indhold og beskytter det mod træningsdataindsamling eller indeksering. Ved at tillade crawlere får de adgang, men dit indhold kan bruges til modeltræning eller optræde i AI-søgeresultater med minimal henvisningstrafik.
Ja, robots.txt er vejledende og ikke juridisk bindende. Veldrevne crawlere fra store virksomheder respekterer generelt robots.txt-direktiver, men nogle crawlere ignorerer dem. For stærkere beskyttelse, implementer blokering på serverniveau via .htaccess eller firewall-regler.
Tjek dine serverlogs for user agent-strenge fra blokerede crawlere. Hvis du ser forespørgsler fra crawlere, du har blokeret, respekterer de muligvis ikke robots.txt. Brug testværktøjer som Google Search Consoles robots.txt-tester eller curl-kommandoer for at verificere din konfiguration.
Blokering af træningscrawlere har typisk minimal direkte trafikpåvirkning, da de alligevel sender meget lidt henvisningstrafik. Blokering af søgecrawlere kan dog reducere synligheden i AI-drevne opdagelsesplatforme. Overvåg din analytics i 30 dage efter implementering af blokeringer for at måle den faktiske effekt.
Selvom du styrer crawler-adgang med robots.txt, hjælper AmICited dig med at spore, hvordan AI-systemer citerer og refererer til dit indhold i deres output. Få fuldt overblik over din AI-tilstedeværelse.
Komplet referenceguide til AI-crawlere og bots. Identificer GPTBot, ClaudeBot, Google-Extended og 20+ andre AI-crawlere med brugeragenter, crawl-hastigheder og ...

Omfattende guide til AI-crawlere i 2025. Identificér GPTBot, ClaudeBot, PerplexityBot og 20+ andre AI-bots. Lær hvordan du blokerer, tillader eller overvåger cr...

Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.