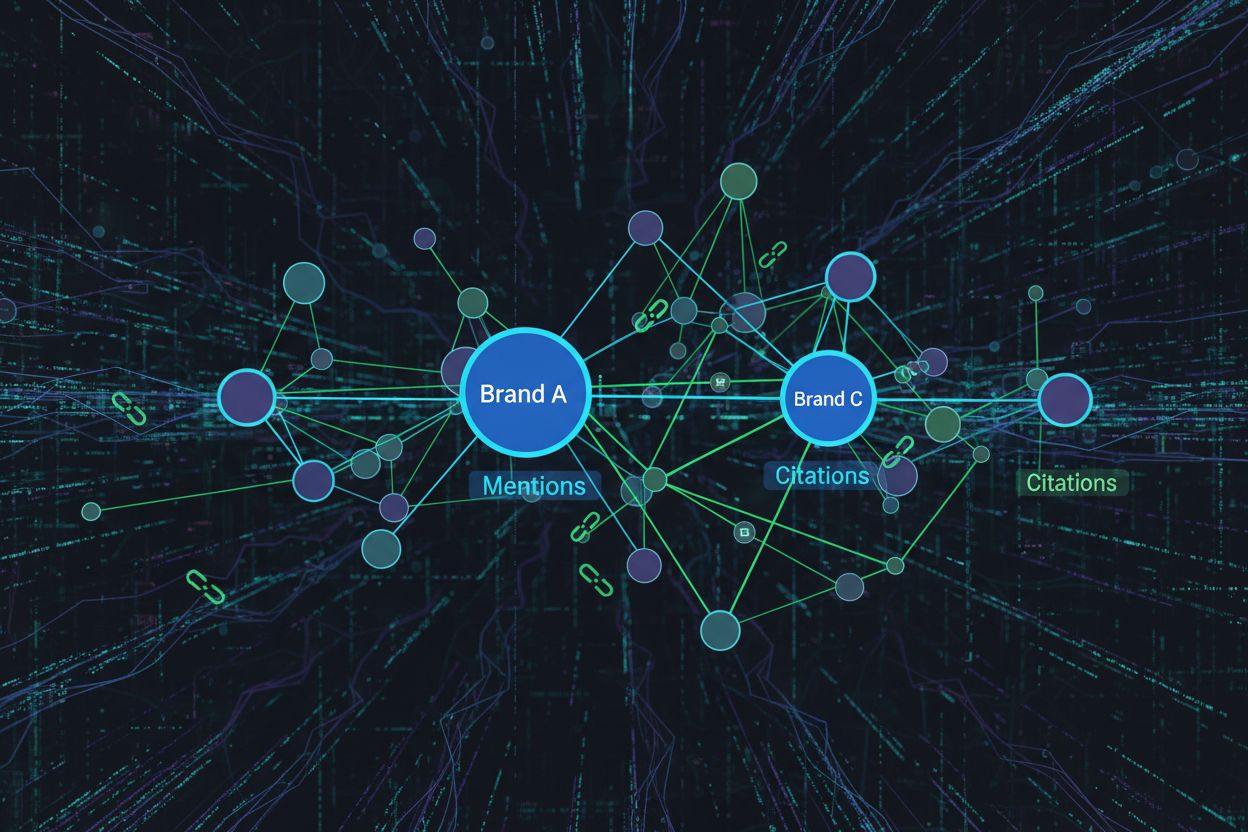
Forstå AI-citater vs. nævnelser: Hvad er forskellen?
Lær den afgørende forskel mellem AI-citater og nævnelser. Opdag hvordan du optimerer for begge signaler for at øge din brands synlighed i ChatGPT, Perplexity og...
8 min læsning
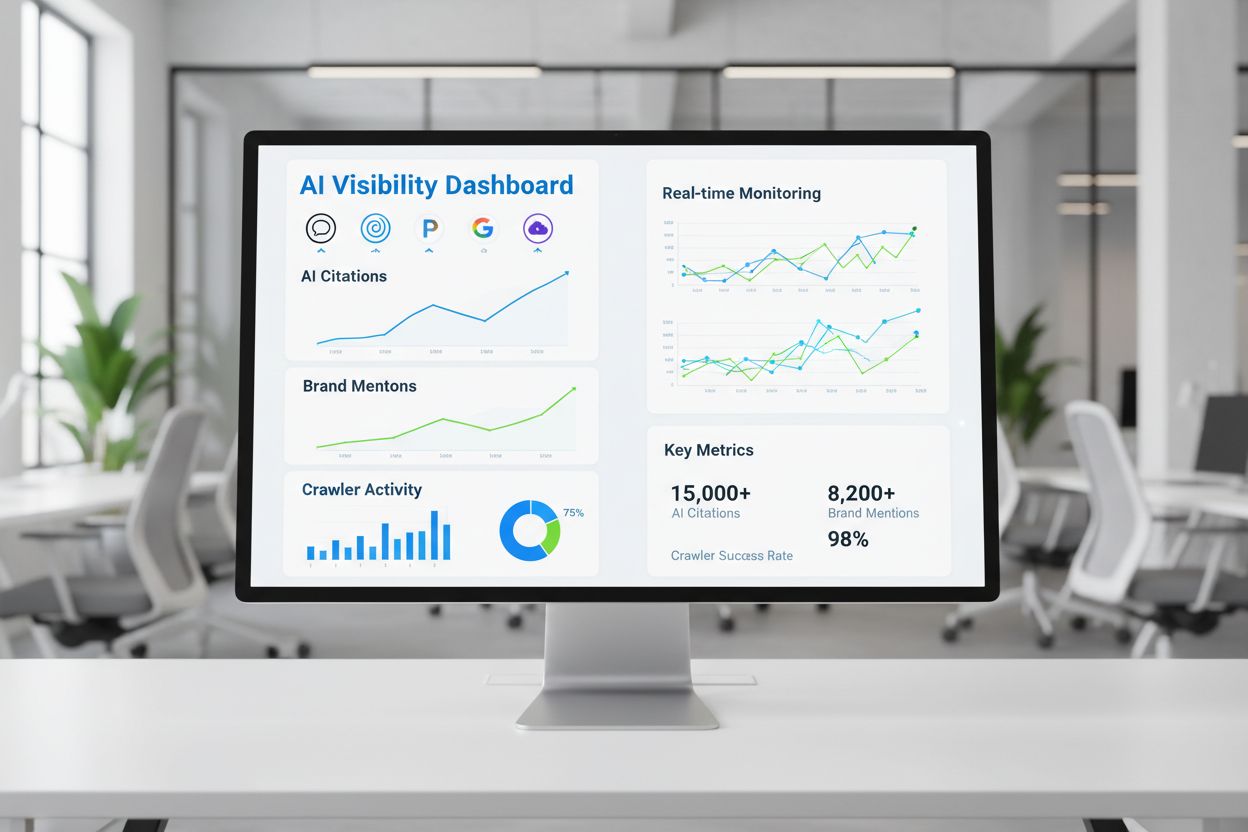
Lær hvordan du dokumenterer din AI-synlighedsstrategi med interne ressourcer. Spor AI-citater, overvåg crawler-aktivitet, og opbyg et omfattende dokumentationssystem til AI-overvågning.
Forskellen mellem AI-citater og brandomtaler er blevet stadig vigtigere for moderne markedsføringsstrategier, men mange organisationer undlader at spore denne afgørende forskel. Når dit indhold bliver citeret af AI-systemer, vejer det væsentligt tungere end en simpel brandomtale—citater indikerer, at din information var værdifuld nok til at blive direkte refereret i AI-genererede svar. Dokumentation af disse citater er essentiel, fordi AI-søgebesøgende konverterer 4,4x bedre end organiske søgebesøgende, hvilket gør det afgørende at forstå præcis, hvilket indhold der driver denne højværditrafik. Uden ordentlige dokumentationssystemer mister brands synligheden ind i deres AI-performance-målinger og kan ikke identificere, hvilke indholdsstrategier der faktisk resonerer med AI-systemer. Ved at etablere et omfattende dokumentationsframework skaber du et reviderbart spor af dine AI-synlighedsindsatser, som muliggør datadrevne beslutninger og strategisk optimering.
AI-crawlere er automatiserede systemer udsendt af AI-virksomheder for systematisk at indsamle og indeksere indhold fra hele nettet, og de danner grundlaget for træning af store sprogmodeller samt driver realtids-hentningssystemer. De største aktører på dette område omfatter GPTBot (fra OpenAI), PerplexityBot (fra Perplexity AI), ClaudeBot (fra Anthropic) og Google-Extended (Googles crawler til AI-træning). At forstå crawler-adfærd er afgørende, fordi disse systemer arbejder i to forskellige tilstande: Nogle crawlere fokuserer på indsamling af træningsdata for at forbedre modeller, mens andre udfører realtids-hentning for at hente aktuel information til generering af svar. Din indholdsstrategi skal tage højde for begge tilgange, da de kræver forskellige optimeringsteknikker og dokumentationsmetoder.
| Crawler | Firma | Primært formål | Frekvens |
|---|---|---|---|
| GPTBot | OpenAI | Træning & realtid | Kontinuerlig |
| PerplexityBot | Perplexity AI | Realtids-hentning | Hyppig |
| ClaudeBot | Anthropic | Træning & realtid | Kontinuerlig |
| Google-Extended | AI-træning | Kontinuerlig |
Forskellige crawlere har varierende adfærd og adgangsmønstre, hvilket betyder, at dit dokumentationssystem skal spore ikke bare, at du bliver crawlet, men hvilke crawlere der tilgår dit indhold og hvor ofte. Denne detaljerede forståelse gør dig i stand til at optimere din indholdsstrategi for de specifikke AI-systemer, der er mest relevante for dine forretningsmål og din målgruppe.
At skabe en central vidensbase for AI-synlighedsdokumentation begynder med at etablere en klar organisationsstruktur, som hele dit team kan forstå og bidrage til. Dit dokumentationsframework bør organiseres efter indholdstype, emneområde og performancemålinger, så det er let for teammedlemmer at finde relevant information og forstå, hvordan forskellige indholdsstykker performer i AI-systemer. De vigtigste elementer, du bør spore, omfatter: crawler-adgangslogs, citatkilder og -frekvens, indholdsperformance-målinger, konkurrenceanalysedata samt strategiske anbefalinger baseret på dokumenterede mønstre. Et velstruktureret framework kan organisere information hierarkisk—startende med overordnede AI-synlighedsmålinger på toppen, derefter ned i specifikke indholdsstykker, deres citathistorik og tilhørende crawler-aktivitet. Denne tilgang sikrer, at både ledere, der vurderer den samlede AI-synlighed, og indholdsskabere, der optimerer enkelte stykker, hurtigt og effektivt kan finde den information, de har brug for.
Sporing af AI-crawleraktivitet har traditionelt været baseret på analyse af serverlogs, hvor IT-teams manuelt gennemgår adgangslogs for at identificere crawler-user-agents og overvåge deres adfærdsmønstre. Denne metode er stadig værdifuld, fordi den giver direkte, ufiltreret data om, hvilke crawlere der tilgår dit indhold og hvornår, men den kræver teknisk ekspertise og kan være tidskrævende at implementere og vedligeholde. Moderne overvågningsværktøjer er dukket op for at forenkle denne proces og tilbyder dashboards og automatiske advarsler, der gør crawler-overvågning tilgængelig for ikke-tekniske teammedlemmer. Løsninger som AmICited.com leverer specialiserede platforme, der er designet specifikt til at overvåge AI-synlighed, med indsigter i hvilke AI-systemer, der citerer dit indhold, og hvor ofte citater forekommer på tværs af forskellige AI-platforme.
| Metode | Fordele | Ulemper | Bedst til |
|---|---|---|---|
| Serverlog-analyse | Direkte data, omfattende | Kræver teknisk viden, tidskrævende | Tekniske teams, detaljeret analyse |
| Overvågningsværktøjer | Brugervenlige, automatiske advarsler | Kan mangle lidt data, abonnementer | Marketingteams, løbende overvågning |
| Specialiserede AI-platforme | AI-specifikke målinger, citatsporing | Begrænset fokus, ekstra omkostning | AI-synlighedsstrategi, ROI-måling |
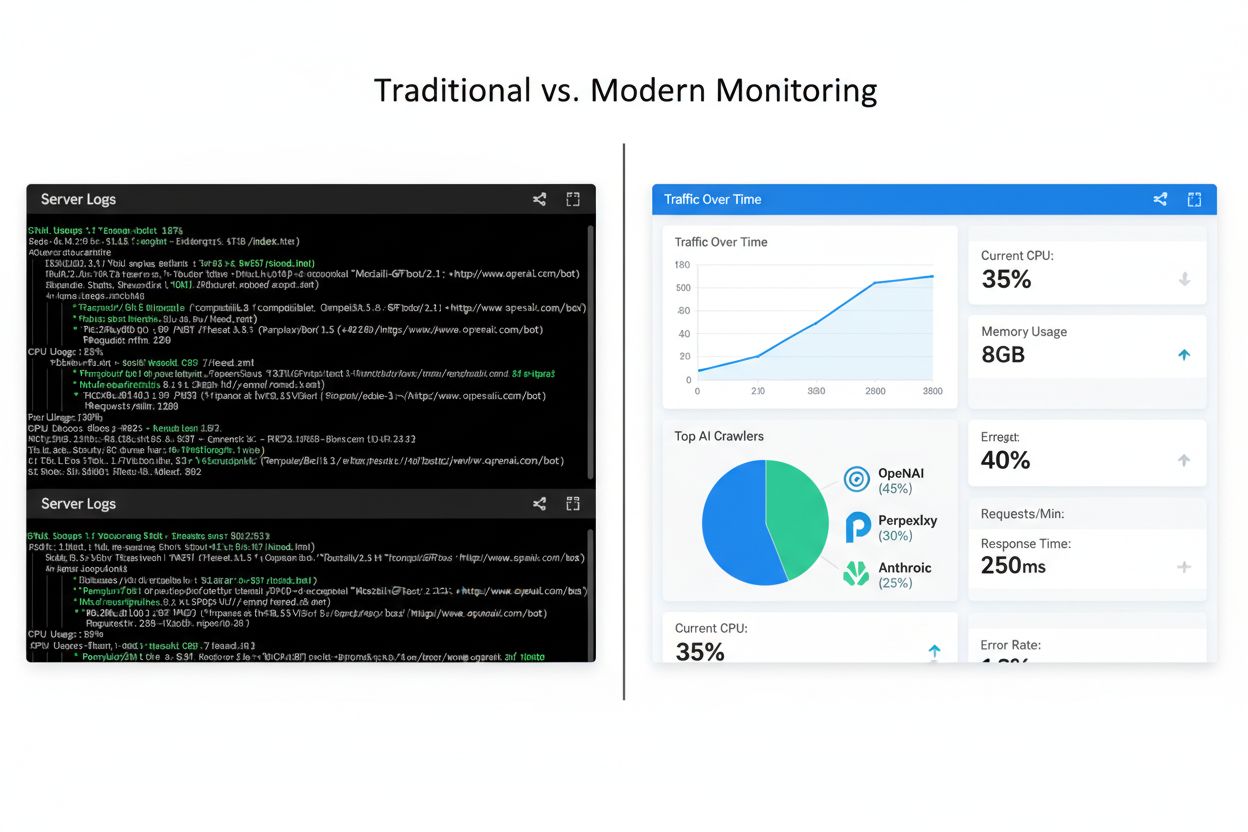
Implementering af et praktisk sporingssystem involverer at vælge værktøjer, der integrerer med din eksisterende infrastruktur, etablere basismålinger før optimeringsarbejdet starter og skabe faste rapporteringsrutiner for at overvåge ændringer over tid. Uanset om du vælger traditionel serverlog-analyse, moderne overvågningsplatforme eller en kombination, er det afgørende, at din dokumentation opsamler crawlerdata konsekvent og systematisk, så du kan identificere trends og måle effekten af dine optimeringstiltag.
At dokumentere hvilket indhold, der citeres af AI-systemer, kræver en systematisk proces til at indsamle citatdata og tilknytte dem til specifikke indholdsstykker, forfattere og udgivelsesdatoer. Du bør ikke kun spore hyppigheden af citater, men også kilderne—hvilke AI-systemer citerer dit indhold, i hvilken kontekst og til hvilke typer forespørgsler. Denne detaljerede dokumentation afslører mønstre i, hvilke typer indhold AI-systemer finder mest værdifulde, hvad enten det er tekniske guider, forskningsdata, holdningsindlæg eller andre formater. Oprettelse af skabeloner for indholdsperformance standardiserer, hvordan disse informationer indsamles på tværs af organisationen, hvilket sikrer konsistens og gør det lettere at analysere mønstre over tid. En særlig vigtig indsigt fra forskning er, at mindre end 30 % af de brands, AI nævner mest, også er dem, der citeres mest, hvilket betyder, at synlighed i AI-systemer ikke automatisk fører til citater—dokumentation hjælper dig med at forstå denne forskel og optimere for egentlige citater frem for blot omtaler.
Opbygning af et effektivt AI-synlighedsdokumentationssystem følger en struktureret proces: Først auditerer du dit nuværende indhold og etablerer basismålinger for crawleraktivitet og citater; derefter vælger du dokumentationsværktøjer, der passer til teamets arbejdsgange og tekniske evner; dernæst opretter du skabeloner og standardiserede processer til at opsamle nye data; og til sidst integrerer du dokumentationsansvar i de eksisterende arbejdsrutiner, så sporing bliver automatisk i stedet for en ekstra byrde. Populære platforme til videnshåndtering omfatter Confluence til enterprise-teams, Notion til fleksibel, tilpasselig dokumentation, Document360 til kundeorienterede vidensdatabaser og Nuclino til samarbejdende teamdokumentation. Nøglen til succesfuld implementering er at vælge værktøjer, som dit team rent faktisk vil bruge konsekvent—et sofistikeret system, som ingen vedligeholder, er mindre værd end et simpelt system, der bliver en del af jeres rutine. Integration med eksisterende værktøjer er kritisk; din AI-synlighedsdokumentation bør forbindes med dit indholdsstyringssystem, analyseplatform og teamkommunikationsværktøjer for at skabe et gnidningsfrit informationsflow.
Vedligeholdelse af din AI-synlighedsdokumentation kræver faste gennemgangsrutiner og klart ejerskab af forskellige dokumentationsområder. Effektive vedligeholdelsespraksisser inkluderer:
Dokumentation bliver hurtigt forældet i det hastigt foranderlige AI-landskab, så etablering af disse vedligeholdelsespraksisser sikrer, at din dokumentation forbliver en pålidelig sandhedskilde til strategiske beslutninger og ikke ender som et arkiv af forældet information.

Den sande værdi af AI-synlighedsdokumentation opstår, når du bruger de dokumenterede data til at informere strategiske beslutninger og identificere forbedringsmuligheder. Ved at analysere din dokumentation kan du identificere, hvilke indholdsemner, formater og distributionskanaler der genererer flest AI-citater, og derefter gentage de succesfulde mønstre i din indholdsstrategi. Konkurrenceanalysen bliver mere sofistikeret, når du dokumenterer ikke kun dine egne AI-synlighedsmålinger, men også følger med i, hvordan konkurrenternes indhold bliver citeret, hvilket afslører huller i markedet og muligheder for at etablere thought leadership. Dokumentation muliggør præcis ROI-måling ved at forbinde AI-citater til forretningsresultater—spore hvilket citeret indhold, der driver trafik, leads eller konverteringer—så du kan kvantificere forretningsværdien af dine AI-synlighedsindsatser. Denne datadrevne tilgang forvandler AI-synlighed fra et vagt markedsføringsmål til en målbar, optimerbar forretningsfunktion med klare forbindelser til omsætning og vækst, hvilket gør det lettere at retfærdiggøre fortsatte investeringer i AI-synlighedsstrategi og sikre ressourcer til løbende optimeringsarbejde.
AI-citater opstår, når dit indhold direkte refereres som en kilde i AI-genererede svar, mens brandomtaler er, når dit brandnavn nævnes i AI-svar uden nødvendigvis at linke til dit indhold. Citater er betydeligt mere værdifulde, fordi de indikerer, at dit indhold var autoritativt nok til at blive brugt som kilde, og de driver typisk trafik af højere kvalitet med bedre konverteringsrater.
De vigtigste AI-crawlere at overvåge er GPTBot (OpenAI), PerplexityBot (Perplexity AI), ClaudeBot (Anthropic) og Google-Extended (Google). Prioriter ud fra din målgruppe og forretningsmål. Hvis din målgruppe ofte bruger ChatGPT, bør GPTBot være en prioritet. For forskningsfokuseret indhold er PerplexityBot-aktivitet særligt vigtig.
Etabler en fast gennemgangsplan med ugentlig gennemgang af crawler-aktivitet, månedlig citatanalyse og kvartalsvise strategigennemgange. Dette sikrer, at din dokumentation forbliver aktuel og anvendelig. AI-landskabet ændrer sig hurtigt, så løbende vedligeholdelse forhindrer, at din dokumentation bliver forældet og upålidelig.
Mulighederne spænder fra traditionelle serverlog-analyseværktøjer som Screaming Frog og Botify til moderne, specialiserede platforme som AmICited.com. For ikke-tekniske teams er moderne overvågningsværktøjer med brugervenlige dashboards mere praktiske. For tekniske teams giver serverlog-analyse mere detaljeret kontrol. Mange organisationer bruger en kombination af begge tilgange.
Opret en systematisk proces, der indsamler citatdata, herunder indholdet, udgivelsesdato, AI-systemet der citerer det, citatfrekvens og kontekst. Brug standardiserede skabeloner for at sikre konsistens på tværs af organisationen. Spor ikke kun at indholdet er citeret, men også hvilke AI-systemer der citerede det og til hvilke typer forespørgsler.
Nøglemålinger inkluderer crawler-adgangsfrekvens efter crawlertype, citattal og -kilder, indholdsperformance-rangeringer, konkurrenceanalyse af citater, trafik fra AI-kilder og konverteringsrater fra AI-drevet trafik. Disse målinger hjælper dig med at forstå, hvilket indhold der resonerer med AI-systemer og skaber forretningsværdi.
Analyser din dokumentation for at identificere mønstre i hvilke indholdsemner, formater og distributionskanaler, der genererer flest citater. Gentag succesfulde mønstre, lav konkurrenceanalyse for at finde huller, og mål ROI ved at forbinde citater til forretningsresultater. Dette forvandler AI-synlighed fra et vagt mål til en målbar, optimerbar forretningsfunktion.
De fleste organisationer har fordel af at tillade AI-crawlere, da de giver mulighed for citater og brandomtaler. Du kan dog være selektiv—tillad crawlere fra AI-systemer relevante for din forretning, mens du blokerer andre om nødvendigt. Brug robots.txt til at styre crawler-adgang og overvej at oprette en llms.txt-fil for at fremhæve vigtigt indhold for AI-systemer.
AmICited hjælper dig med at spore, hvordan AI-systemer refererer til dit brand på tværs af ChatGPT, Perplexity, Google AI Overviews og mere. Dokumenter din AI-synlighedsstrategi med overvågning og indsigter i realtid.
Lær den afgørende forskel mellem AI-citater og nævnelser. Opdag hvordan du optimerer for begge signaler for at øge din brands synlighed i ChatGPT, Perplexity og...
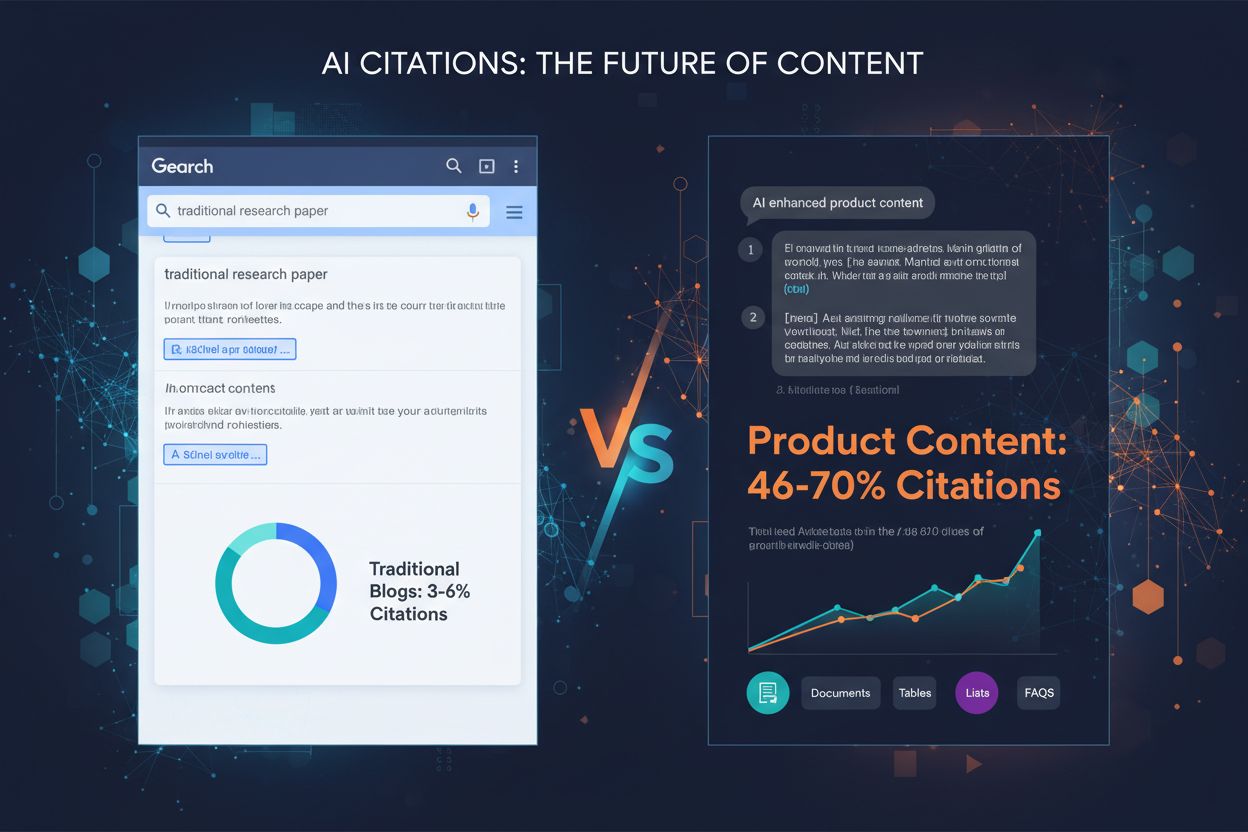
Opdag hvilke indholdsformater der citeres mest af AI-modeller. Analysér data fra 768.000+ AI-citater for at optimere din indholdsstrategi til ChatGPT, Perplexit...

Opdag hvordan kvalitetsdokumentation påvirker AI-søgemaskiner, generering af svar og brandets synlighed på AI-drevne platforme som ChatGPT, Perplexity og Claude...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.