
Målretning af LLM-kildesider for backlinks
Lær hvordan du identificerer og målretter LLM-kildesider for strategiske backlinks. Oplev hvilke AI-platforme der citerer kilder mest, og optimer din linkbuildi...
9 min læsning

Opdag hvordan store sprogmodeller udvælger og citerer kilder gennem evidensvægtning, entitetsgenkendelse og strukturerede data. Lær den 7-fasede beslutningsproces for citater og optimer dit indhold til AI-synlighed.
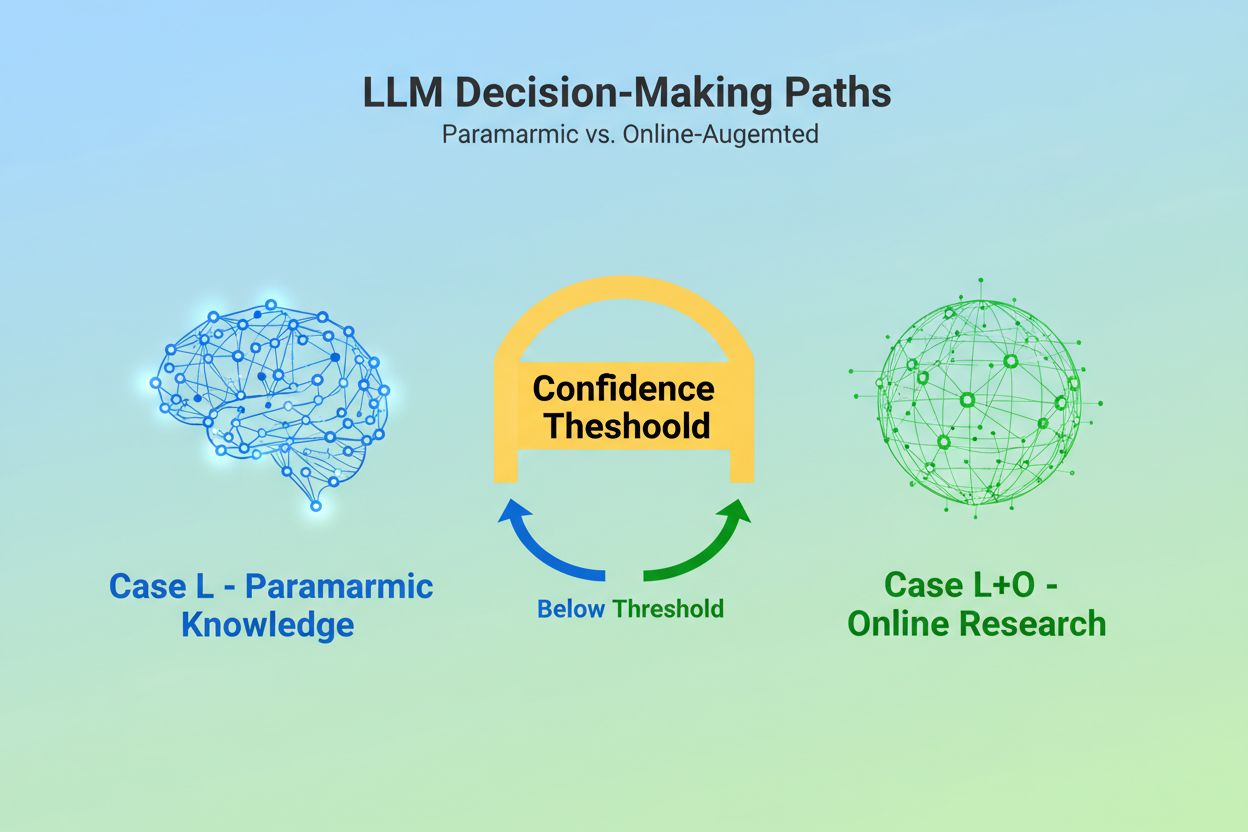
Når en stor sprogmodel modtager en forespørgsel, står den over for en grundlæggende beslutning: Skal den udelukkende stole på viden indlejret under træningen, eller skal den søge på internettet efter aktuelle oplysninger? Dette binære valg—hvad forskere kalder Case L (kun læringsdata) versus Case L+O (læringsdata plus online research)—afgør, om en LLM overhovedet vil citere kilder. I Case L-tilstand trækker modellen udelukkende fra sin parametriske vidensbase, en kondenseret repræsentation af mønstre lært under træningen, der typisk afspejler oplysninger fra flere måneder til over et år før modellens udgivelse. I Case L+O-tilstand aktiverer modellen en tillidstærskel, der udløser ekstern research og åbner det, forskere kalder “kandidatrummet” af URL’er og kilder. Dette beslutningspunkt er usynligt for de fleste overvågningsværktøjer, men det er her, hele citeringsmekanismen begynder—fordi uden at udløse søgefasen kan ingen eksterne kilder evalueres eller citeres.
I det øjeblik en LLM beslutter at søge efter eksterne kilder, træder den ind i den mest kritiske fase for valg af citater: evidensvægtning. Her skelnes der mellem en blot nævnelse og en autoritativ anbefaling. Modellen tæller ikke blot, hvor mange gange en kilde optræder eller hvor højt den rangerer i søgeresultater; i stedet vurderer den strukturel integritet af selve evidensen. Den vurderer dokumentarkitektur—om kilder indeholder klare datarelationer, tilbagevendende identifikatorer og refererede links—og tolker disse som tegn på troværdighed. Modellen konstruerer det, forskere kalder en “evidensgraf”, hvor noder repræsenterer entiteter og kanter repræsenterer dokumentrelationer. Hver kilde vægtes ikke kun på indholdsrelevans, men på hvor konsekvent fakta bekræftes på tværs af flere dokumenter, hvor emnerelevant informationen er, og hvor autoritativt domænet fremstår. Denne multidimensionelle vurdering skaber det, der er kendt som en evidensmatrix, en omfattende vurdering, der afgør, hvilke kilder der er pålidelige nok til at blive citeret. Kritisk nok foregår denne fase i ræsonneringslaget af LLM’en, hvilket gør den usynlig for traditionelle GEO-overvågningsværktøjer, der kun måler hentningssignaler.
Strukturerede data—særligt JSON-LD, Schema.org-markup og RDFa—virker som en multiplikator i evidensvægtningen. Kilder, der implementerer korrekt struktureret data, får 2-3 gange højere vægt i evidensmatricen sammenlignet med ustruktureret indhold. Det er ikke fordi LLM’er foretrækker formaterede data æstetisk; det er fordi strukturerede data muliggør entitetslinking, processen med at forbinde nævnelser på tværs af dokumenter via maskinlæsbare identifikatorer som @id, sameAs og Q-IDs (Wikidata-identifikatorer). Når en LLM støder på en kilde med en Q-ID for en organisation, kan den straks verificere denne entitet på tværs af flere dokumenter og skabe det, forskere kalder “tværdokument entitetskoreferencer”. Denne verifikationsproces øger dramatisk tilliden til kildens pålidelighed.
| Dataformat | Citeringsnøjagtighed | Entitetslinking | Tværdokumentverifikation |
|---|---|---|---|
| Ustruktureret tekst | 62% | Ingen | Manuel inferens |
| Grundlæggende HTML-markup | 71% | Begrænset | Delvis matchning |
| RDFa/Microdata | 81% | God | Mønsterbaseret |
| JSON-LD med Q-IDs | 94% | Fremragende | Verificerede links |
| Vidensgraf-format | 97% | Perfekt | Automatisk verifikation |
Effekten af strukturerede data opererer på to tidsakser. Forbigående, når en LLM søger online, læser den JSON-LD og Schema.org-markup i realtid og indarbejder straks denne strukturerede information i evidensvægtningen for det aktuelle svar. Vedvarende, strukturerede data, der forbliver konsistente over tid, bliver integreret i modellens parametriske vidensbase under fremtidige træningscyklusser og former, hvordan modellen genkender og vurderer entiteter selv uden online research. Denne dobbelte mekanisme betyder, at brands, der implementerer korrekt struktureret data, opnår både øjeblikkelig citeringssynlighed og langsigtet autoritet i modellens interne vidensrum.
Før en LLM kan citere en kilde, skal den først forstå hvad kilden handler om og hvem den repræsenterer. Dette er entitetsgenkendelsens arbejde, en proces der omsætter upræcist menneskesprog til maskinlæsbare entiteter. Når et dokument nævner “Apple”, skal LLM’en afgøre, om dette refererer til Apple Inc., frugten eller noget helt andet. Modellen opnår dette gennem trænede entitetsmønstre afledt fra Wikipedia, Wikidata og Common Crawl, kombineret med kontekstuel analyse af omgivende tekst. I Case L+O-tilstand bliver processen mere sofistikeret: Modellen verificerer entiteter mod eksterne strukturerede data, søger efter @id-attributter, sameAs-links og Q-IDs, der giver entydig identifikation. Dette verifikationstrin er afgørende, fordi tvetydige eller inkonsistente entitetsreferencer går tabt i modellens ræsonneringsstøj. Et brand, der bruger inkonsekvente navne, undlader at etablere klare entitetsidentifikatorer eller ikke implementerer Schema.org-markup, bliver semantisk uklart for maskinen—og fremstår som flere forskellige entiteter frem for én sammenhængende kilde. Omvendt bliver organisationer med stabile, konsekvent refererede entiteter på tværs af flere dokumenter genkendt som pålidelige noder i LLM’ens vidensgraf og øger markant deres sandsynlighed for at blive citeret.
Rejsen fra forespørgsel til citat følger en struktureret syv-faset proces, som forskere har kortlagt gennem analyse af LLM-adfærd. Fase 0: Intentionstolkning begynder, når modellen tokeniserer brugerinputtet, udfører semantisk analyse og opretter en intentionvektor—en abstrakt repræsentation af, hvad brugeren reelt spørger om. Denne fase afgør, hvilke emner, entiteter og relationer der overhovedet er relevante at overveje. Fase 1: Intern videnshentning tilgår modellens parametriske viden og beregner en tillidsscore. Hvis denne score overstiger en tærskel, forbliver modellen i Case L-tilstand; hvis ikke, går den videre til ekstern research. Fase 2: Fan-Out søgegenerering (kun Case L+O) skaber flere semantisk varierede søgeforespørgsler—typisk 1-6 tokens hver—designet til at åbne kandidatrummet så bredt som muligt. Fase 3: Evidensudtrækning henter URL’er og uddrag fra søgeresultater, parser HTML og udtrækker JSON-LD, RDFa og microdata. Her bliver strukturerede data først synlige for citeringsmekanismen. Fase 4: Entitetslinking identificerer entiteter i de hentede dokumenter og verificerer dem mod eksterne identifikatorer, hvilket skaber en midlertidig vidensgraf over relationer. Fase 5: Evidensvægtning vurderer styrken af evidensen fra alle kilder, herunder dokumentarkitektur, kildediversitet, bekræftelsesfrekvens og sammenhæng på tværs af kilder. Fase 6: Ræsonnement & syntese kombinerer intern og ekstern evidens, løser modsigelser og afgør, om hver kilde fortjener en nævnelse eller en anbefaling. Fase 7: Endelig responsopbygning oversætter den vægtede evidens til naturligt sprog og integrerer citater, hvor det er relevant. Hver fase fører videre til den næste, med feedbacksløjfer, så modellen kan forfine sin søgning eller revurdere evidens, hvis der opstår inkonsistenser.
Moderne LLM’er benytter i stigende grad Retrieval-Augmented Generation (RAG), en teknik der fundamentalt ændrer, hvordan citater udvælges og begrundes. I stedet for kun at stole på parametrisk viden, henter RAG-systemer aktivt relevante dokumenter, udtrækker evidens og forankrer svar i specifikke kilder. Denne tilgang forvandler citater fra et implicit biprodukt af træning til en eksplicit, sporbar proces. RAG-implementeringer bruger typisk hybrid søgning, hvor nøgleordsbaseret hentning kombineres med vektorsimilaritet for at maksimere recall. Når kandidatdokumenter er hentet, foretager semantisk rangering en gen-score af resultaterne baseret på betydning og ikke blot på nøgleords-match, så de mest relevante kilder kommer øverst. Denne eksplicitte hentemekanisme gør citeringsprocessen mere gennemsigtig og reviderbar—hver citeret kilde kan spores tilbage til specifikke passager, der berettigede dens inddragelse. For organisationer, der overvåger deres AI-synlighed, er RAG-baserede systemer særligt vigtige, fordi de skaber målbare citeringsmønstre. Værktøjer som AmICited sporer, hvordan RAG-systemer refererer til dit brand på tværs af forskellige AI-platforme og giver indsigt i, om du optræder som citeret kilde eller blot som baggrundsmateriale i evidensudtræksfasen.
Ikke alle citater er lige. En LLM kan nævne en kilde som baggrundskontekst, mens den anbefaler en anden som autoritativ evidens—og denne forskel afgøres udelukkende af evidensvægtning, ikke af succes med hentning. En kilde kan optræde i kandidatrummet (Fase 2-3), men ikke opnå anbefalingsstatus, hvis dens evidensscore er utilstrækkelig. Denne opdeling mellem nævnelse og anbefaling er, hvor traditionelle GEO-målinger kommer til kort. Standardovervågningsværktøjer måler fan-out—om dit indhold optræder i søgeresultater—men de kan ikke måle, om LLM’en faktisk anser dit indhold for troværdigt nok til at anbefale. En nævnelse kan lyde som “Nogle kilder antyder…”, mens en anbefaling lyder som “Ifølge [Kilde] viser evidensen…”. Forskellen ligger i evidensmatrixscoren fra Fase 5. Kilder med konsekvente Q-IDs, velstruktureret dokumentarkitektur og bekræftelse på tværs af flere uafhængige kilder opnår anbefalingsstatus. Kilder med tvetydige entitetsreferencer, dårlig strukturel sammenhæng eller isolerede påstande forbliver nævnelser. For brands er denne skelnen kritisk: At blive hentet er ikke det samme som at blive citeret som autoritativ. Vejen fra hentning til anbefaling kræver semantisk klarhed, strukturel integritet og evidenstæthed—faktorer, som traditionel SEO-optimering ikke adresserer.
At forstå, hvordan LLM’er udvælger kilder, har øjeblikkelige, handlingsrettede konsekvenser for indholdsstrategien. For det første, implementér Schema.org-markup konsekvent på dit website, især for organisationsoplysninger, artikler og nøgleentiteter. Brug JSON-LD-format med korrekte @id-attributter og sameAs-links til Wikidata, Wikipedia eller andre autoritative kilder. Disse strukturerede data øger direkte din evidensvægt i Fase 5. For det andet, opret klare entitetsidentifikatorer for din organisation, produkter og nøglebegreber. Brug konsistente navngivningskonventioner, undgå forkortelser der skaber tvetydighed, og forbind relaterede entiteter gennem hierarkiske relationer (isPartOf, about, mentions). For det tredje, skab maskinlæsbar evidens ved at publicere strukturerede data om dine påstande, credentials og relationer. Skriv ikke bare “Vi er den førende leverandør af X”—strukturer denne påstand med understøttende data, citater og verificerbare relationer. For det fjerde, oprethold indholdskonsistens på tværs af platforme og over tid. LLM’er vurderer evidenstæthed ved at tjekke, om påstande bekræftes på tværs af uafhængige kilder; isolerede påstande på én platform vægtes lavere. For det femte, forstå at traditionelle SEO-målinger ikke forudsiger AI-citering. Høje søgerangeringer garanterer ikke LLM-anbefalinger; fokusér i stedet på semantisk klarhed og strukturel integritet. For det sjette, overvåg dine citeringsmønstre med værktøjer som AmICited, der sporer, hvordan forskellige AI-systemer refererer til dit brand. Det afslører, om du opnår nævnelses- eller anbefalingsstatus, og hvilke typer indhold der udløser citater. Til sidst, indse at AI-synlighed er en langsigtet investering. Strukturerede data, du implementerer i dag, former både den øjeblikkelige sandsynlighed for citat (forbigående effekt) og modellens interne vidensbase i fremtidige træningscyklusser (vedvarende effekt).
Efterhånden som LLM’er udvikler sig, bliver citeringsmekanismerne stadig mere sofistikerede og gennemsigtige. Fremtidige modeller vil sandsynligvis implementere citeringsgrafer—eksplicitte kort, der ikke bare viser, hvilke kilder der blev citeret, men hvordan de påvirkede specifikke påstande i svaret. Nogle avancerede systemer eksperimenterer allerede med sandsynlighedsbaserede tillidsscorer knyttet til citater, der indikerer, hvor sikker modellen er på kildens relevans og pålidelighed. En anden fremvoksende tendens er menneskelig verifikation i loop’et, hvor brugere kan udfordre citater og give feedback, der forfiner modellens evidensvægtning til fremtidige forespørgsler. Integration af strukturerede data i træningscyklusser betyder, at organisationer, der implementerer korrekt semantisk infrastruktur i dag, i praksis bygger deres langsigtede autoritet i AI-systemer. I modsætning til søgemaskinerangeringer, der kan svinge baseret på algoritmeopdateringer, skaber den vedvarende effekt af strukturerede data et mere stabilt fundament for AI-synlighed. Dette skift fra traditionel synlighed (at blive fundet) til semantisk autoritet (at blive betroet) repræsenterer en grundlæggende ændring i, hvordan brands bør tilgå digital kommunikation. Vinderne i dette nye landskab vil ikke være dem med mest indhold eller de højeste søgerangeringer, men dem der strukturerer deres information på en måde, som maskiner pålideligt kan forstå, verificere og anbefale.
Case L bruger kun træningsdata fra modellens parametriske vidensbase, mens Case L+O supplerer dette med realtids web-research. Modellens tillidstærskel afgør, hvilken vej der vælges. Denne skelnen er afgørende, fordi det bestemmer, om eksterne kilder overhovedet kan evalueres og citeres.
Evidensvægtning afgør denne forskel. Kilder med strukturerede data, konsistente identifikatorer og bekræftelse på tværs af dokumenter løftes til 'anbefalinger' frem for blot nævnelser. En kilde kan optræde i søgeresultater, men ikke opnå anbefalingsstatus, hvis dens evidensscore er utilstrækkelig.
Strukturerede data (JSON-LD, @id, sameAs, Q-IDs) får 2-3 gange højere vægt i evidensmatricer. Denne markering muliggør entitetslinking og tværdokumentverifikation, hvilket dramatisk øger kildens pålidelighedsscore. Kilder med korrekt Schema.org-implementering er markant mere tilbøjelige til at blive citeret som autoritative.
Entitetsgenkendelse er, hvordan LLM'er identificerer og skelner mellem forskellige entiteter (organisationer, personer, begreber). Klar entitetsidentifikation gennem konsistente navne og strukturerede identifikatorer forhindrer forvirring og øger sandsynligheden for citat. Tvetydige entitetsreferencer går tabt i modellens ræsonneringsproces.
RAG-systemer henter og rangerer aktivt kilder i realtid, hvilket gør udvælgelsen af citater mere gennemsigtig og evidensbaseret end ren parametrisk viden. Denne eksplicitte hentemekanisme skaber målbare citeringsmønstre, der kan spores og analyseres via overvågningsværktøjer som AmICited.
Ja. Implementér Schema.org-markup konsekvent, opret tydelige entitetsidentifikatorer, skab maskinlæsbar evidens, oprethold indholdskonsistens på tværs af platforme, og overvåg dine citeringsmønstre. Disse faktorer påvirker direkte, om dit indhold opnår nævnelses- eller anbefalingsstatus i LLM-svar.
Traditionel synlighed måler rækkevidde og placering i søgeresultater. AI-synlighed måler, om dit indhold anerkendes som autoritativ evidens i LLM'ers ræsonneringsprocesser. At blive hentet er ikke det samme som at blive citeret som troværdig—sidstnævnte kræver semantisk klarhed og strukturel integritet.
AmICited sporer, hvordan AI-systemer refererer til dit brand på tværs af GPT'er, Perplexity og Google AI Overviews. Det afslører, om du opnår nævnelses- eller anbefalingsstatus, hvilke typer indhold der udløser citater, og hvordan dine citeringsmønstre sammenlignes på forskellige AI-platforme.
Forstå hvordan LLM'er refererer til dit brand på ChatGPT, Perplexity og Google AI Overviews. Spor citeringsmønstre og optimer for AI-synlighed med AmICited.
Lær hvordan du identificerer og målretter LLM-kildesider for strategiske backlinks. Oplev hvilke AI-platforme der citerer kilder mest, og optimer din linkbuildi...

Lær hvordan proprietære undersøgelsesdata og originale statistikker bliver citatmagneter for LLM'er. Opdag strategier til at forbedre AI-synlighed og få flere c...

Opdag hvordan LLM-grounding og websøgning gør det muligt for AI-systemer at få adgang til realtidsinformation, reducere hallucinationer og levere præcise citate...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.