Informationsdensitet
Lær hvad informationsdensitet er, og hvordan det forbedrer sandsynligheden for AI-citation. Opdag praktiske teknikker til at optimere indhold for AI-systemer so...
14 min læsning

Lær hvordan du skaber informationsrigt indhold, som AI-systemer foretrækker. Bliv fortrolig med hypotesen om ensartet informationsdensitet og optimer dit indhold til AI Overviews, LLMs og bedre citater.
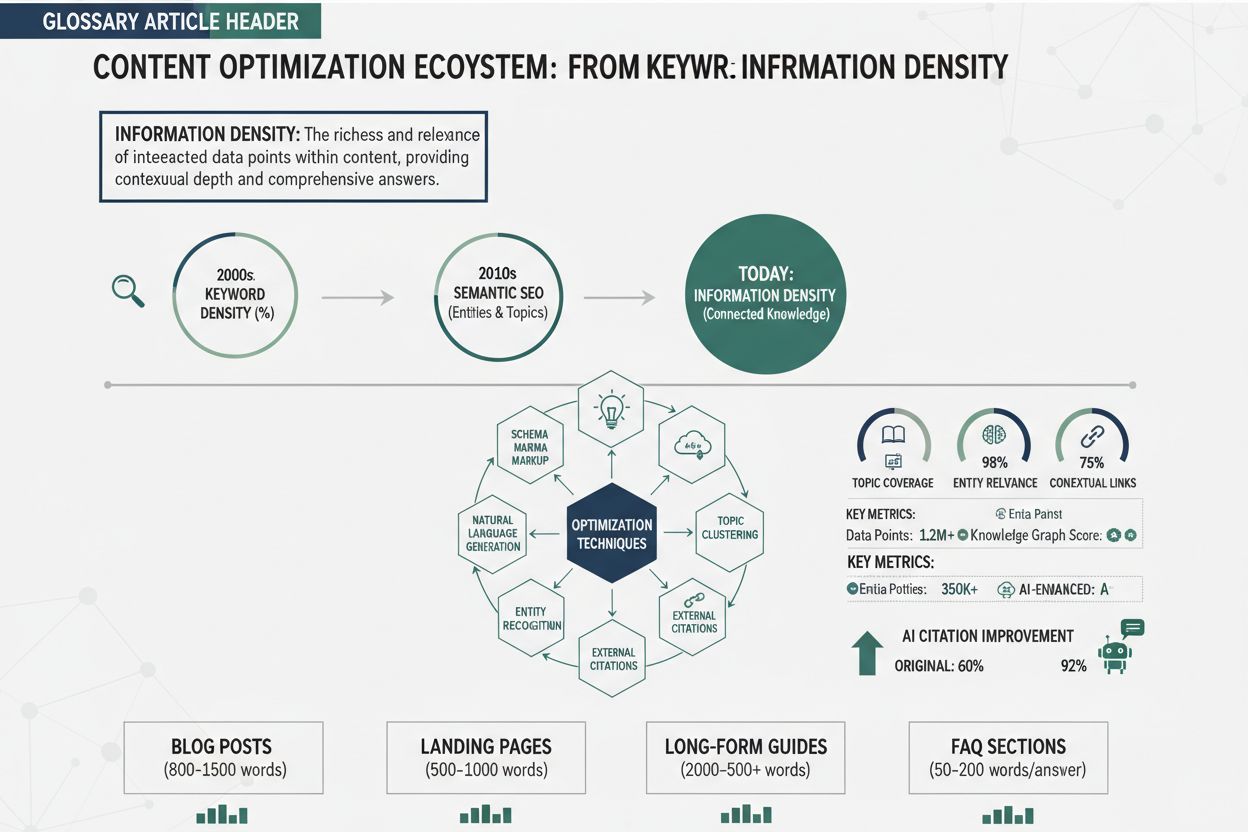
Informationsdensitet refererer til koncentrationen af meningsfulde, handlingsrettede indsigter i et givent stykke indhold—altså hvor meget værdi der er pakket ind i hvert ord, sætning eller afsnit. Dette begreb er blevet stadig mere afgørende i AI-drevet søgning, især med fremkomsten af Large Language Models (LLMs) og AI Overviews. Hypotesen om ensartet informationsdensitet (UID), et sprogligt princip understøttet af nyere forskning på ArXiv, antyder, at både mennesker og AI-systemer behandler information mere effektivt, når den kognitive belastning fordeles jævnt gennem indholdet i stedet for at være koncentreret i isolerede afsnit. For AI-systemer, der evaluerer indhold, påvirker informationsdensitet direkte, hvor sandsynligt det er, at dit indhold udvælges, citeres og rangeres i AI-søgeresultater. Når du skaber værdifuldt indhold, skriver du ikke kun til menneskelige læsere—du optimerer også til, hvordan LLMs udtrækker, syntetiserer og refererer information fra dit arbejde.
LLMs vurderer indholds-densitet gennem adskillige sofistikerede mekanismer, der rækker langt ud over simple ordoptællinger eller hyppigheden af nøgleord. Disse systemer analyserer indholdsmålinger ved hjælp af entropibaserede beregninger, der måler, hvor meget information der formidles i forhold til den samlede tekstlængde, og undersøger, hvad forskere kalder “trin-niveau ensartethed”—altså hvor jævnt informationen fordeles gennem sekventielle afsnit af dit indhold. Når en LLM behandler din artikel, beregner den informationsgevinst ved hvert token og vurderer, om du leverer en ensartet værdi, eller om visse afsnit er overflødige, irrelevante eller af lav værdi. Forskellige evalueringsrammer prioriterer forskellige aspekter af indholdskvalitet, som vist i tabellen nedenfor:
| Metrik | Hvad den måler | AI-relevans | Bedst til |
|---|---|---|---|
| BLEU Score | Præcision af ordmatches | Lavere relevans for densitet | Maskinoversættelses-evaluering |
| ROUGE Score | Recall af indholdsoverlap | Moderat relevans | Opsummeringskvalitet |
| Perplexity | Forudsigelighed af tekstsekvenser | Høj relevans | LLMs selvtillidsvurdering |
| Informationsdensitet | Meningsfuldt indhold pr. enhedslængde | Højeste relevans | AI-citering og udvælgelse |
Forståelse af disse LLM-vurderingsrammer hjælper dig med at indse, at AI-systemer ikke blot leder efter omfattende indhold—de søger indhold, der fastholder en ensartet informationsværdi hele vejen igennem og undgår den udbredte faldgrube med fyld eller overflødigt materiale, der udvander dit budskab.
Forskellen mellem tæt indhold og spredt indhold former grundlæggende, hvordan AI-systemer interagerer med dit materiale. Tæt indhold leverer høj informationsværdi med minimal fyld, mens spredt indhold indeholder betydelige mængder gentagelse, fyldstof eller udredninger med lav værdi. Overvej disse nøgleforskelle:
Et praktisk eksempel: En spredt artikel om AI-indholdsoptimering kunne bruge tre afsnit på at forklare, hvad AI er, derefter tre mere på hvorfor indhold er vigtigt, før teknikkerne til optimering endelig behandles. En tæt indholds-version ville forudsætte basal viden, integrere kontekst naturligt og afsætte forholdsmæssig plads til handlingsrettede strategier. AI-systemer anerkender og belønner denne effektivitet, fordi det viser, at forfatteren forstår sit emne tilstrækkeligt dybt til at formidle det kortfattet.
Informationsdensitet er blevet et afgørende rangeringssignal i AI-drevne søgemiljøer og påvirker direkte, om dit indhold vises i AI Overviews, og hvor ofte det får citater fra AI-systemer. Forskning fra BrightEdge’s analyse af AI-algoritmer viser, at indhold udvalgt til AI Overviews har ca. 40 % højere informationsdensitet end indhold, der ikke bliver udvalgt, hvilket antyder, at AI-systemer aktivt prioriterer tæt, værdifuldt materiale, når de syntetiserer svar. Forholdet mellem informationsdensitet og citationsrater er særligt vigtigt fra AmICited.com’s perspektiv: Når AI-systemer som Perplexity eller Googles AI Overviews skal referere til kilder, citerer de fortrinsvis indhold, der leverer koncentreret værdi, da dette mindsker behovet for at citere flere kilder for at besvare en enkelt forespørgsel fyldestgørende. Indhold med høj informationsdensitet har også en tendens til at rangere bedre, fordi det mere fuldstændigt opfylder brugerens intention – AI-systemer genkender, at tæt indhold giver mere grundige svar og mindsker sandsynligheden for, at brugeren skal konsultere yderligere kilder. Desuden vurderer AI Overviews-algoritmer specifikt, om indholdet let kan opsummeres og syntetiseres, og tæt indhold er af natur lettere at opsummere, fordi der er færre overflødige elementer, der skal filtreres ud under syntesen.
At skabe værdifuldt indhold kræver bevidste strukturelle og redaktionelle valg, hvor informationsformidling prioriteres over ordantal. Begynd med en grundig revision af dit eksisterende indhold: identificer hver sætning, der ikke fremmer dit kerneargument eller tilføjer handlingsværdi, og fjern den eller integrer den i omkringliggende sætninger, der tjener flere formål. Brug strukturerede indholdsformater—nummererede lister, sammenligningstabeller, hierarkiske overskrifter og definitionsafsnit—som gør det nemt for læsere og AI-systemer hurtigt at udtrække nøgletekst uden at skulle afkode fortællende prosa. Implementer princippet om “én idé pr. afsnit”, så hvert afsnit har et klart formål og ikke udvander sit budskab med sidebemærkninger; dette understøtter direkte UID-hypotesen ved at fordele den kognitive belastning jævnt. Når du forklarer komplekse begreber, brug progressiv afsløring: introducer den væsentlige information først, og læg derefter lag på med detaljer, eksempler og nuancer – dette gavner både menneskelige læsere og LLMs, der kan udtrække indhold på forskellige detaljeringsniveauer. Indsæt specifikke datapunkter, statistikker og konkrete eksempler frem for abstrakte generaliseringer; “ca. 40 % højere informationsdensitet” er mere værdifuldt for AI-systemer end “betydeligt højere densitet”. Optimer endelig din indholdsoptimeringsproces ved at behandle informationsdensitet som en primær måling sammen med traditionelle SEO-faktorer—gennemgå udkast med spørgsmålet, om hvert afsnit kunne kondenseres, kombineres eller fjernes uden at miste væsentlig værdi.
At måle informationsdensitet kræver kendskab til både de teoretiske rammer og de praktiske værktøjer, der er tilgængelige for indholdsskabere. Den mest direkte metode indebærer beregning af en informationsdensitetsscore ved hjælp af entropibaserede målinger: divider det samlede informationsindhold (målt i bits eller via semantisk analyse) med det samlede ordantal for at bestemme, hvor meget meningsfuld information du leverer pr. tekst-enhed. Flere værktøjer kan hjælpe med denne vurdering: Natural Language Processing-platforme kan analysere semantisk diversitet og begrebsfordeling, læsbarhedsværktøjer kan identificere mønstre af overflødigheder, og egne scripts med Python-biblioteker som NLTK kan beregne entropimålinger for dit indhold. Et praktisk eksempel: Hvis en artikel på 2.000 ord indeholder ca. 150 distinkte semantiske begreber jævnt fordelt, har den højere informationsdensitet end en 2.000-ords artikel med kun 80 distinkte begreber, der er samlet i første halvdel. Du kan også bruge proxy-målinger som forholdet mellem unikke termer og samlede ord, gennemsnitlig informationsgevinst pr. afsnit eller antallet af handlingsrettede pointer pr. 500 ord—disse er ikke perfekte, men giver nyttige pejlemærker. BrightEdge’s forskning anbefaler at overvåge, hvor ofte dit indhold citeres af AI-systemer som en reel validering af informationsdensiteten; hvis dit indhold konsekvent vises i AI Overviews og modtager citater, rammer du sandsynligvis de rigtige densitetsmål.
Den mest udbredte fejl i forsøget på at opnå informationsdensitet er overoptimering, hvor indholdsskabere forsøger at maksimere densitet så aggressivt, at indholdet bliver svært at læse eller mister nødvendig kontekst og forklaring. Dette viser sig ofte som keyword stuffing forklædt som densitetsoptimering—hvor flere søgeord presses ind i sætninger, hvor de ikke naturligt passer, hvilket faktisk reducerer informationsværdien og udløser AI-systemers straf. En anden kritisk fejl er informations-overload ved at dække for mange emner i et enkelt stykke; dette bryder UID-hypotesen ved at koncentrere for høj kognitiv belastning i visse afsnit, mens andre efterlades tynde. Dårlig strukturel organisering er en anden udbredt faldgrube: selv informationsrigt indhold mister effekt, hvis det ikke er organiseret hierarkisk med tydelige relationer mellem begreber, hvilket gør det vanskeligere for både læsere og AI-systemer at udtrække værdi. Nogle forveksler også densitet med kortfattethed og producerer indhold, der teknisk set er kort, men mangler tilstrækkelig dybde til at opfylde brugerens intention eller give den kontekst, som AI-systemer har brug for til nøjagtig syntese og citat. Endelig underminerer det effektiviteten, hvis du ikke fastholder en ensartet informationsfordeling i hele dit indhold—for eksempel ved at samle alle statistikker og data i indledningen og derefter kun give fortællende forklaring, hvilket strider mod UID-princippet og reducerer den samlede effektivitet overfor AI-systemer.
Principperne for informationsdensitet gælder på tværs af alle indholdsformater, men det optimale densitetsniveau og implementeringsstrategien varierer betydeligt efter indholdstype. Blogindlæg drager typisk fordel af moderat til høj informationsdensitet med strategisk brug af eksempler og forklaringer, der gør tætte begreber tilgængelige; et teknisk blogindlæg kan fastholde 70-80 % informationsdensitet, mens et begynderfokuseret indlæg kan ligge på 50-60 % for bedre forståelse. Teknisk dokumentation kræver den højeste informationsdensitet, da læsere forventer koncentreret værdi og minimal fyld—dokumentation, der opnår 85 %+ informationsdensitet, klarer sig typisk bedre i AI-systemer, fordi det er lettere at opsummere og citere. Produktsider kræver en anden tilgang, hvor informationsdensitet afbalanceres med overtalelseselementer og brugeroplevelse; du vil gerne pakke værdi ind i funktionsbeskrivelser og fordele, men for høj densitet kan overvælde potentielle kunder og reducere konverteringsraten. Nyhedsartikler og journalistisk indhold opererer under andre vilkår, hvor narrativt flow og kontekst nogle gange kræver lavere informationsdensitet, selvom AI-systemer stadig foretrækker nyhedsindhold, der leverer fakta effektivt uden overdreven redaktionel kommentar. Forskningsartikler og whitepapers kan opretholde meget høj informationsdensitet, fordi publikum forventer teknisk dybde, men selv akademisk indhold har fordel af klar struktur og strategisk brug af opsummeringer for at fastholde UID-principper. At forstå disse variationer gør dig i stand til at optimere informationsdensiteten passende for din specifikke indholdstype og samtidig bevare effektiviteten både overfor læsere og AI-systemer.
Efterhånden som AI-systemer bliver mere avancerede, vil informationsdensitet sandsynligvis blive et endnu vigtigere rangerings- og citeringssignal, især efterhånden som konkurrencen om at blive inkluderet i AI Overviews intensiveres. Ny forskning antyder, at fremtidige LLMs vil udvikle stadig mere nuancerede metoder til at vurdere informationskvalitet og -densitet, potentielt ud over simple entropiberegninger og mod mere sofistikeret semantisk analyse, der belønner ikke blot koncentreret information, men også information, der er optimalt struktureret til syntese og citat. Udviklingen af AI-søgning vil sandsynligvis favorisere dem, der forstår, at AI-udvikling ikke handler om at manipulere algoritmer, men om reelt at opfylde brugerens intention bedre—tæt, velstruktureret indhold tjener dette formål ved at give AI-systemerne rigere materiale at arbejde med. Indholdsskabere bør forberede sig på en fremtid, hvor indholdsstrategien i stigende grad vægter kvalitet over kvantitet, hvor en artikel på 1.500 ord med exceptionel informationsdensitet overgår en på 5.000 ord med moderat densitet, og hvor evnen til at kommunikere komplekse idéer kortfattet bliver en konkurrencefordel. Organisationer, der overvåger deres tilstedeværelse i AI Overviews og følger citationsrater via platforme som AmICited.com, vil have en væsentlig fordel, da de direkte kan observere, hvordan ændringer i informationsdensitet påvirker deres synlighed i AI-drevne søgeresultater. De indholdsskabere og organisationer, der allerede nu investerer i at forstå og optimere for informationsdensitet, vil være bedst positioneret til at trives, når AI-søgning bliver den dominerende opdagelsesmekanisme for onlineindhold.

Informationsdensitet refererer til koncentrationen af meningsfulde, handlingsrettede indsigter i indholdet – hvor meget værdi der er pakket ind i hvert ord eller hver sætning. AI-systemer vurderer denne måling for at afgøre, hvilket indhold de vil citere og fremhæve i AI Overviews. Højere informationsdensitet resulterer typisk i bedre synlighed i AI-søgeresultater.
UID-hypotesen antyder, at effektiv kommunikation opretholder et stabilt informationsflow gennem hele indholdet. AI-systemer behandler indhold mere effektivt, når den kognitive belastning er jævnt fordelt fremfor koncentreret i isolerede afsnit. Dette princip påvirker direkte, hvordan LLMs udvælger og citerer dit indhold.
Tæt indhold leverer høj informationsværdi med minimal fyld, bruger præcist sprog og eliminerer overflødigheder. Spredt indhold indeholder betydelig gentagelse og uddyber uden megen værdi. AI-systemer foretrækker tæt indhold, fordi det er lettere at syntetisere og citere, hvilket mindsker behovet for at referere til flere kilder.
Du kan måle informationsdensitet ved at beregne forholdet mellem meningsfuld information og det samlede antal ord ved hjælp af entropibaserede målinger. Praktiske metoder inkluderer at følge unikke semantiske begreber pr. ord, registrere handlingsrettede pointer pr. 500 ord eller observere, hvor ofte AI-systemer citerer dit indhold i AI Overviews.
Ja, markant. Forskning viser, at indhold udvalgt til AI Overviews har cirka 40 % højere informationsdensitet end ikke-udvalgt indhold. AI-systemer citerer fortrinsvis tæt, værdifuldt materiale, fordi det giver fyldestgørende svar med færre kildehenvisninger.
Almindelige fejl omfatter overoptimering, der mindsker læsbarheden, keyword stuffing forklædt som densitet, informations-overload ved at dække for mange emner, dårlig struktur, at forveksle densitet med kortfattethed og at undlade at fastholde ensartet informationsfordeling i indholdet.
Informationsdensitetskrav varierer efter format: teknisk dokumentation har gavn af 85 %+ densitet, blogindlæg fungerer godt ved 70-80 %, produktsider balancerer densitet og overtalelse ved 50-70 %, og nyhedsartikler kan have lavere densitet pga. narrativet. Optimer densiteten efter din specifikke indholdstype.
Efterhånden som AI-systemer bliver mere avancerede, vil informationsdensitet sandsynligvis blive et endnu vigtigere rangeringssignal. Fremtidige LLMs vil formentlig udvikle mere nuancerede metoder til at vurdere informationskvalitet og foretrække dem, der forstår, at tæt, velstruktureret indhold bedst opfylder brugerens hensigt.
Følg med i, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews citerer og refererer til dit brand. Få realtidsindsigt i din AI-synlighed og indholdsperformance.
Lær hvad informationsdensitet er, og hvordan det forbedrer sandsynligheden for AI-citation. Opdag praktiske teknikker til at optimere indhold for AI-systemer so...

Lær, hvad indholds omfattendehed betyder for AI-systemer som ChatGPT, Perplexity og Google AI Overblik. Opdag hvordan du skaber komplette, selvstændige svar, so...
Lær hvad indholdsdybde betyder for AI-søgemaskiner. Opdag hvordan du strukturerer omfattende indhold til AI Overviews, ChatGPT, Perplexity og andre AI-svar gene...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.