
Server-side rendering vs CSR: Indvirkning på AI-synlighed
Opdag hvordan SSR- og CSR-renderingstrategier påvirker AI-crawleres synlighed, brandcitater i ChatGPT og Perplexity samt din samlede AI-søgepræsentation.
7 min læsning

Lær hvorfor AI-crawlere som ChatGPT ikke kan se JavaScript-renderet indhold, og hvordan du gør dit site synligt for AI-systemer. Oplev rendering-strategier for AI-synlighed.
Det digitale landskab har fundamentalt ændret sig, men de fleste organisationer er ikke fulgt med. Mens Googles sofistikerede rendering-pipeline kan afvikle JavaScript og indeksere dynamisk genereret indhold, arbejder AI-crawlere som ChatGPT, Perplexity og Claude under helt andre begrænsninger. Dette skaber et kritisk synlighedshul: Indhold, der ser helt fint ud for menneskelige brugere og endda for Googles søgemaskine, kan være fuldstændig usynligt for de AI-systemer, der i stigende grad driver trafik og påvirker købsbeslutninger. At forstå denne forskel er ikke bare en teknisk nysgerrighed—det bliver afgørende for at opretholde synlighed i hele det digitale økosystem. Indsatsen er stor, og løsningerne er mere nuancerede, end de fleste organisationer er klar over.
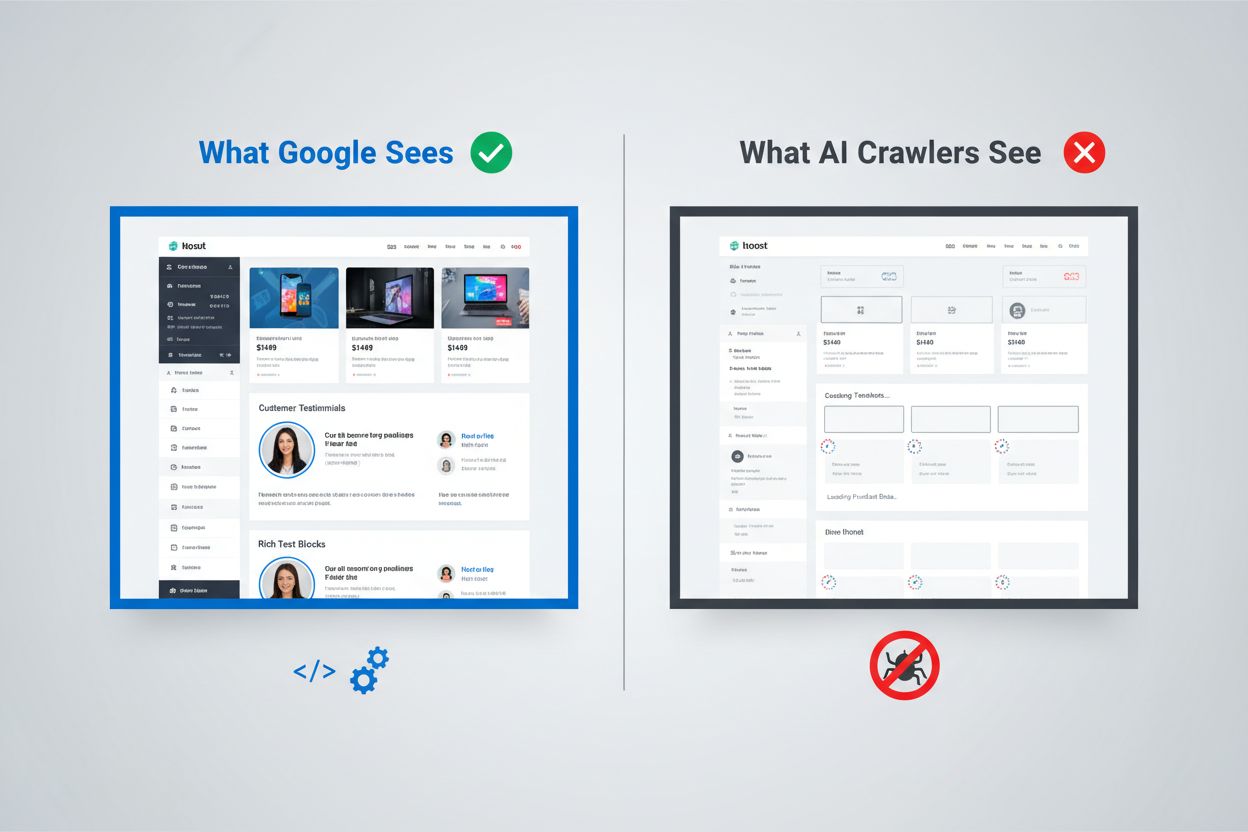
Googles tilgang til JavaScript-rendering repræsenterer et af de mest sofistikerede systemer, der nogensinde er bygget til web-indeksering. Søgegiganten anvender et to-bølge rendering-system, hvor sider først crawles for deres statiske HTML-indhold og derefter gen-renderes ved hjælp af en headless Chrome-browser via sin Web Rendering Service (WRS). Under denne anden bølge afvikler Google JavaScript, opbygger den komplette DOM (Document Object Model) og indfanger hele den renderede sidetilstand. Denne proces inkluderer rendering-caching, hvilket betyder, at Google kan genbruge tidligere renderede versioner af sider for at spare ressourcer. Hele systemet er designet til at håndtere kompleksiteten i moderne webapplikationer og samtidig kunne crawle milliarder af sider. Google investerer enorme computerressourcer i denne evne, hvor tusindvis af headless Chrome-instanser kører for at bearbejde webben fyldt med JavaScript-indhold. For organisationer, der er afhængige af Google Search, betyder det, at deres klient-side renderede indhold har en chance for synlighed—men kun fordi Google har bygget en exceptionelt dyr infrastruktur til at understøtte det.
AI-crawlere opererer under fundamentalt forskellige økonomiske og arkitektoniske begrænsninger, som gør JavaScript-afvikling upraktisk. Ressourcebegrænsninger er den primære begrænsning: At afvikle JavaScript kræver opstart af browsermotorer, håndtering af hukommelse og vedligeholdelse af tilstand mellem forespørgsler—alt sammen dyre operationer i stor skala. De fleste AI-crawlere arbejder med timeout-vinduer på 1-5 sekunder, hvilket betyder, at de skal hente og behandle indhold ekstremt hurtigt eller helt opgive anmodningen. Omkostnings- og nytteberegningen taler ikke for JavaScript-afvikling for AI-systemer; de kan træne på langt mere indhold ved blot at behandle statisk HTML end ved at render hver side, de støder på. Derudover fjerner databehandlings-pipelinen for store sprogmodeller typisk CSS og JavaScript under indtagelsen og fokuserer kun på det semantiske HTML-indhold. Den arkitektoniske filosofi er fundamentalt forskellig: Google byggede rendering ind i sit kerneindekseringssystem, fordi søgerelevans afhænger af forståelse af renderet indhold, mens AI-systemer prioriterer bredden af dækning frem for dybden af rendering. Dette er ikke en begrænsning, der nemt overvindes—det er indlejret i de grundlæggende økonomiske vilkår for, hvordan disse systemer fungerer.
Når AI-crawlere anmoder om en side, modtager de den rå HTML-fil uden nogen JavaScript-afvikling, hvilket ofte betyder, at de ser en dramatisk anderledes version af indholdet end menneskelige brugere. Single Page Applications (SPA’er) bygget med React, Vue eller Angular er særligt problematiske, fordi de typisk leverer minimal HTML og er helt afhængige af JavaScript for at udfylde sideindholdet. En AI-crawler, der anmoder om et React-baseret e-handelssite, kan modtage HTML, der kun indeholder tomme <div id="root"></div>-tags uden egentlig produktinformation, priser eller beskrivelser. Crawleren ser sidens skelet men ikke indholdet. For indholdstunge sider betyder det, at produktkataloger, blogindlæg, pristabeller og dynamiske indholdssektioner simpelthen ikke eksisterer i AI-crawlerens visning. Virkelige eksempler er mange: Et SaaS-platforms funktionssammenligningstabel kan være fuldstændig usynlig, en e-handelssides produktanbefalinger bliver ikke indekseret, og en nyhedssides dynamisk indlæste artikler kan fremstå som tomme sider. Den HTML, AI-crawlere modtager, er ofte blot applikationsskallen—det faktiske indhold lever i JavaScript-bundter, som aldrig bliver afviklet. Dette skaber en situation, hvor siden ser perfekt ud i en browser, men fremstår næsten tom for AI-systemer.
Forretningspåvirkningen af dette rendering-hul rækker langt ud over tekniske bekymringer og påvirker direkte omsætning, synlighed og konkurrenceposition. Når AI-crawlere ikke kan se dit indhold, lider flere kritiske forretningsfunktioner:
Den samlede effekt er, at organisationer, der investerer massivt i indhold og brugeroplevelse, kan ende med at være usynlige for en stadig vigtigere klasse af brugere og systemer. Dette er ikke et problem, der løser sig selv—det kræver målrettet handling.
Forskellige rendering-strategier giver vidt forskellige resultater, når de ses med AI-crawler-syn. Valget af rendering-tilgang afgør grundlæggende, hvad AI-systemer kan se og indeksere. Sådan sammenlignes de vigtigste strategier:
| Strategi | Hvad AI ser | Effekt på AI-synlighed | Kompleksitet | Bedst til |
|---|---|---|---|---|
| Server-side rendering (SSR) | Komplet HTML med alt indhold renderet | Fuld synlighed—AI ser alt | Høj | Indholdstunge sites, SEO-kritiske applikationer |
| Statisk sidesignering (SSG) | Forudrenderede HTML-filer | Fremragende synlighed—indholdet er statisk HTML | Medium | Blogs, dokumentation, marketingsider |
| Klient-side rendering (CSR) | Tom HTML-skal, minimalt indhold | Dårlig synlighed—AI ser kun skelet | Lav | Realtidsdashboards, interaktive værktøjer |
| Hybrid (SSR + CSR) | Initial HTML + klient-side forbedringer | God synlighed—kerneindhold synligt | Meget høj | Komplekse applikationer med dynamiske funktioner |
| Pre-rendering-tjeneste | Cachet renderet HTML | God synlighed—afhænger af tjenestekvalitet | Medium | Eksisterende CSR-sider, der kræver hurtige løsninger |
| API-first + markup | Strukturerede data + HTML-indhold | Fremragende synlighed—hvis korrekt implementeret | Høj | Moderne webapplikationer, headless CMS |
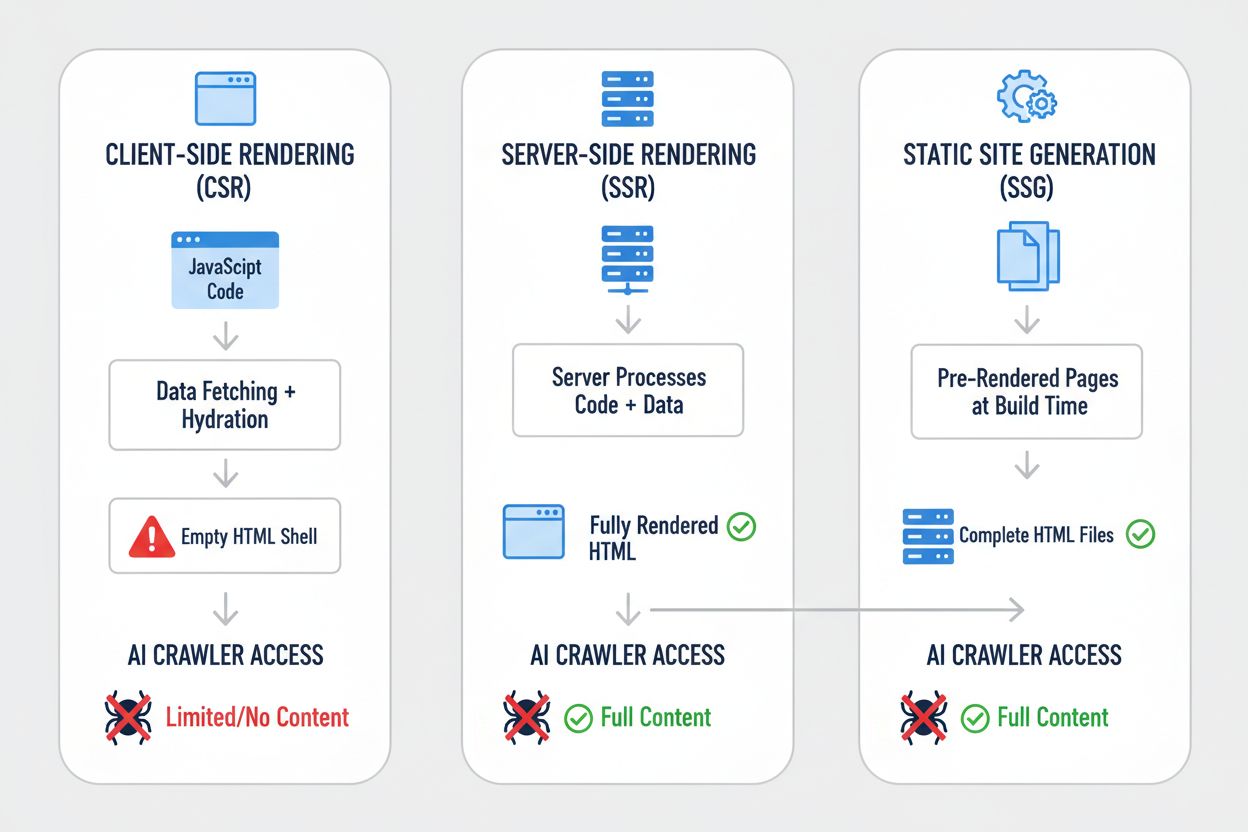
Hver strategi repræsenterer et forskelligt kompromis mellem udviklingskompleksitet, ydeevne, brugeroplevelse og AI-synlighed. Den kritiske erkendelse er, at synlighed for AI-systemer korrelerer stærkt med at have indhold i statisk HTML-form—uanset om HTML’en genereres ved buildtid, ved forespørgsel eller serveres fra en cache. Organisationer skal evaluere deres rendering-strategi ikke kun for brugeroplevelse og ydeevne, men eksplicit for AI-crawler-synlighed.
Server-side rendering (SSR) repræsenterer guldstandarden for AI-synlighed, fordi den leverer komplet, renderet HTML til enhver forespørger—både menneskelige browsere og AI-crawlere. Med SSR afvikler serveren din applikationskode og genererer det fulde HTML-svar, før det sendes til klienten, hvilket betyder, at AI-crawlere modtager hele, renderede sider ved første forespørgsel. Moderne frameworks som Next.js, Nuxt.js og SvelteKit har gjort SSR betydeligt mere praktisk end tidligere, idet de håndterer kompleksiteten ved hydration (hvor klient-side JavaScript overtager fra server-renderet HTML) transparent. Fordelene rækker ud over AI-synlighed: SSR forbedrer typisk Core Web Vitals, reducerer Time to First Contentful Paint og giver bedre ydeevne for brugere på langsomme forbindelser. Ulempen er øget serverbelastning og kompleksitet i håndtering af tilstand mellem server og klient. For organisationer, hvor AI-synlighed er kritisk—særligt indholdstunge sites, e-handelsplatforme og SaaS-applikationer—er SSR ofte det mest forsvarlige valg. Investeringen i SSR-infrastruktur giver udbytte på flere fronter: bedre søgemaskinesynlighed, bedre AI-crawler-synlighed, bedre brugeroplevelse og bedre ydeevnemålinger.
Statisk sidesignering (SSG) tager en anden tilgang ved at forudrender sider ved buildtid og generere statiske HTML-filer, der kan serveres øjeblikkeligt til enhver forespørger. Værktøjer som Hugo, Gatsby og Astro har gjort SSG stadig mere kraftfuldt og fleksibelt, med understøttelse af dynamisk indhold via API’er og inkrementel statisk regeneration. Når en AI-crawler anmoder om en side genereret med SSG, modtager den komplet, statisk HTML med alt indhold fuldt renderet—perfekt synlighed. Ydeevnefordelene er fremragende: statiske filer serveres hurtigere end nogen dynamisk rendering, og infrastrukturkravene er minimale. Begrænsningen er, at SSG fungerer bedst til indhold, der ikke ændrer sig ofte; sider skal genbygges og genudrulles, når indhold opdateres. For blogs, dokumentationssites, marketingsider og indholdstunge applikationer er SSG ofte det optimale valg. Kombinationen af fremragende AI-synlighed, fremragende ydeevne og minimale infrastrukturkrav gør SSG attraktiv i mange tilfælde. Dog bliver SSG mindre praktisk for applikationer, der kræver realtidspersonalisering eller hyppigt ændrende indhold, uden yderligere kompleksitet som inkrementel statisk regeneration.
Klient-side rendering (CSR) forbliver populært trods dets betydelige ulemper for AI-synlighed, primært fordi det giver den bedste udvikleroplevelse og mest fleksible brugeroplevelse for meget interaktive applikationer. Med CSR sender serveren minimal HTML og er afhængig af JavaScript til at opbygge siden i browseren—hvilket betyder, at AI-crawlere ser næsten ingenting. React-, Vue- og Angular-applikationer leveres typisk med CSR som standard, og mange organisationer har bygget hele deres teknologistak omkring dette mønster. Attraktionen er forståelig: CSR muliggør rige, interaktive oplevelser, realtidsopdateringer og glidende klient-side navigation. Problemet er, at denne fleksibilitet sker på bekostning af AI-synlighed. For applikationer, der absolut kræver CSR—realtidsdashboards, samarbejdsværktøjer, komplekse interaktive applikationer—findes der løsninger. Pre-rendering-tjenester som Prerender.io kan generere statiske HTML-snapshots af CSR-sider og servere dem til crawlere, mens den interaktive version serveres til browsere. Alternativt kan organisationer implementere hybride tilgange, hvor kritisk indhold server-renderes, mens interaktive funktioner forbliver klient-side. Den vigtigste læring er, at CSR skal være et bevidst valg truffet med fuld forståelse for synlighedskompromisset, ikke en standardantagelse.
Implementering af praktiske løsninger kræver en systematisk tilgang, der starter med at forstå din nuværende tilstand og fortsætter med implementering og løbende overvågning. Start med et audit: Brug værktøjer som Screaming Frog, Semrush eller tilpassede scripts til at crawle dit site, som en AI-crawler ville, og undersøg hvilket indhold der faktisk er synligt i den rå HTML. Implementer rendering-forbedringer baseret på dine audit-fund—det kan betyde migrering til SSR, at tage SSG i brug for relevante sektioner eller implementering af pre-rendering for kritiske sider. Test grundigt ved at sammenligne, hvad AI-crawlere ser i forhold til hvad browsere ser; brug curl-kommandoer til at hente rå HTML og sammenligne med den renderede version. Overvåg løbende for at sikre, at rendering-ændringer ikke ødelægger synligheden over tid. For organisationer med store, komplekse sites kan det betyde, at man prioriterer sider med høj værdi først—produktsider, prissider og nøgleindholdssektioner—før man angriber hele sitet. Værktøjer som Lighthouse, PageSpeed Insights og tilpassede overvågningsløsninger kan hjælpe med at spore rendering-ydeevne og synlighedsmålinger. Investeringen i at få dette rigtigt giver udbytte på tværs af søgesynlighed, AI-synlighed og overordnet sideydeevne.
Test og overvågning af din rendering-strategi kræver specifikke teknikker, der afslører, hvad AI-crawlere faktisk ser. Den simpleste test er at bruge curl til at hente rå HTML uden JavaScript-afvikling:
curl -s https://example.com | grep -i "product\|price\|description"
Dette viser dig præcis, hvad en AI-crawler modtager—hvis dit kritiske indhold ikke optræder i denne output, vil det ikke være synligt for AI-systemer. Browserbaseret test med Chrome DevTools kan vise dig forskellen mellem den indledende HTML og den fuldt renderede DOM; åbn DevTools, gå til Network-fanen, og undersøg det indledende HTML-svar i forhold til den endelige renderede tilstand. Til løbende overvågning skal du implementere syntetisk overvågning, der regelmæssigt henter dine sider, som en AI-crawler ville, og advarer dig, hvis indholdssynligheden forværres. Spor målinger som “procentdel af indhold synligt i initial HTML” og “tid til indholdssynlighed” for at forstå din rendering-ydeevne. Nogle organisationer implementerer tilpassede overvågningsdashboards, der sammenligner AI-crawler-synlighed på tværs af konkurrenter og giver konkurrenceintelligens om, hvem der optimerer for AI-synlighed, og hvem der ikke gør. Det centrale er at gøre denne overvågning kontinuerlig og operationel—synlighedsproblemer skal fanges og rettes hurtigt, ikke opdages måneder senere, når trafikken pludselig falder.
Fremtiden for AI-crawleres evner er uvis, men de nuværende begrænsninger vil sandsynligvis ikke ændre sig markant i den nærmeste fremtid. OpenAI har eksperimenteret med mere avancerede crawlere som Comet og Atlas-browsere, der kan afvikle JavaScript, men disse er stadig eksperimentelle og er ikke udrullet i stor skala til træningsdatainhentning. De grundlæggende økonomiske forhold er uændrede: At afvikle JavaScript i stor skala er fortsat dyrt, og træningsdatapipelinen drager stadig større nytte af bredde end dybde. Selv hvis AI-crawlere på sigt får JavaScript-afviklingsevner, vil den optimering, du laver nu, ikke skade—server-renderet indhold performer bedre for brugere, indlæses hurtigere og giver bedre SEO uanset hvad. Den fornuftige tilgang er at optimere for AI-synlighed nu i stedet for at vente på, at crawler-evnerne forbedres. Det betyder at betragte AI-synlighed som en førsteklasses bekymring i din rendering-strategi, ikke en eftertanke. Organisationer, der foretager dette skifte nu, vil have en konkurrencefordel, efterhånden som AI-systemer bliver stadig vigtigere for trafik og synlighed.
At overvåge din AI-synlighed og spore forbedringer over tid kræver de rette værktøjer og målinger. AmICited.com giver en praktisk løsning til at spore, hvordan dit indhold optræder i AI-genererede svar og overvåge din synlighed på tværs af forskellige AI-systemer. Ved at spore hvilke af dine sider, der bliver citeret, citeret eller refereret til i AI-genereret indhold, kan du forstå den reelle effekt af dine rendering-optimeringer. Platformen hjælper dig med at identificere, hvilket indhold der er synligt for AI-systemer, og hvilket indhold der forbliver usynligt, og giver konkrete data om effektiviteten af din rendering-strategi. Når du implementerer SSR, SSG eller pre-rendering-løsninger, kan du på AmICited.com måle den faktiske forbedring i AI-synlighed—og se, om dine optimeringsindsatser fører til flere citationer og referencer. Denne feedback-loop er afgørende for at retfærdiggøre investeringen i rendering-forbedringer og identificere, hvilke sider der kræver yderligere optimering. Ved at kombinere teknisk overvågning af, hvad AI-crawlere ser, med forretningsmålinger af, hvor ofte dit indhold faktisk optræder i AI-svar, får du et komplet billede af din AI-synligheds-performance.
Nej, ChatGPT og de fleste AI-crawlere kan ikke afvikle JavaScript. De ser kun den rå HTML fra den indledende sideindlæsning. Alt indhold indsat via JavaScript efter siden er indlæst forbliver fuldstændig usynligt for AI-systemer, i modsætning til Google, som bruger headless Chrome-browsere til at render JavaScript.
Google bruger headless Chrome-browsere til at render JavaScript, ligesom en rigtig browser gør. Dette kræver mange ressourcer, men Google har infrastrukturen til at gøre det i stor skala. Googles to-bølge rendering-system crawler først statisk HTML, og gen-render derefter sider med JavaScript-eksekvering for at indfange hele DOM'en.
Deaktiver JavaScript i din browser og indlæs dit site, eller brug curl-kommandoen for at se rå HTML. Hvis nøgleindhold mangler, kan AI-crawlere heller ikke se det. Du kan også bruge værktøjer som Screaming Frog i 'Kun tekst'-tilstand for at crawle dit site, som en AI-crawler ville gøre.
Nej. Du kan også bruge statisk sidesignering, pre-rendering-tjenester eller hybride tilgange. Den bedste løsning afhænger af din indholdstype og opdateringsfrekvens. SSR fungerer godt til dynamisk indhold, SSG til stabilt indhold, og pre-rendering-tjenester til eksisterende CSR-sider.
Google kan håndtere JavaScript, så dine Google-placeringer bør ikke blive påvirket direkte. Dog forbedrer optimering for AI-crawlere ofte den samlede sidekvalitet, ydeevne og brugeroplevelse, hvilket indirekte kan gavne dine Google-placeringer.
Det afhænger af AI-platformens crawl-frekvens. ChatGPT-User crawler efter behov, når brugere anmoder om indhold, mens GPTBot crawler sjældent med lange genbesøgelsesintervaller. Ændringer kan tage uger, før de vises i AI-svar, men du kan overvåge fremskridt med værktøjer som AmICited.com.
Pre-rendering-tjenester er nemmere at implementere og vedligeholde med minimale kodeændringer, mens SSR giver mere kontrol og bedre ydeevne for dynamisk indhold. Vælg ud fra dine tekniske ressourcer, indholdsopdateringsfrekvens og kompleksitet af din applikation.
Ja, du kan bruge robots.txt til at blokere specifikke AI-crawlere som GPTBot. Dette betyder dog, at dit indhold ikke vil optræde i AI-genererede svar, hvilket potentielt mindsker synlighed og trafik fra AI-drevne søgeværktøjer og assistenter.
Spor hvordan AI-systemer refererer til dit brand på tværs af ChatGPT, Perplexity og Google AI Overviews. Identificer synlighedshuller og mål effekten af dine rendering-optimeringer.
Opdag hvordan SSR- og CSR-renderingstrategier påvirker AI-crawleres synlighed, brandcitater i ChatGPT og Perplexity samt din samlede AI-søgepræsentation.

Lær hvordan du gør dit indhold synligt for AI-crawlere som ChatGPT, Perplexity og Googles AI. Opdag tekniske krav, bedste praksis og overvågningsstrategier for ...
Opdag de kritiske tekniske SEO-faktorer, der påvirker din synlighed i AI-søgemaskiner som ChatGPT, Perplexity og Google AI Mode. Lær, hvordan sidehastighed, sch...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.