
Differentiel Crawler-adgang
Lær at tillade eller blokere AI-crawlere selektivt baseret på forretningsmål. Implementer differentiel crawler-adgang for at beskytte indhold, mens synligheden ...
8 min læsning

Lær hvordan du bruger robots.txt til at kontrollere, hvilke AI-bots der får adgang til dit indhold. Komplet guide til blokering af GPTBot, ClaudeBot og andre AI-crawlere med praktiske eksempler og konfigurationsstrategier.
Landskabet for webcrawlere har fundamentalt ændret sig over de seneste to år og er gået ud over den velkendte søgemaskineindeksering til den komplekse verden af AI-modeltræning. Mens Googles Googlebot længe har været en forudsigelig gæst på udgiveres sider, ankommer en ny generation af crawlere nu med markant andre intentioner og forbrugsmønstre. OpenAI’s GPTBot har et crawl-to-refer-forhold på cirka 1.700:1, hvilket betyder, at den crawler 1.700 sider for kun at generere én henvisning tilbage til dit site, mens Anthropics ClaudeBot opererer med et endnu mere ekstremt 73.000:1 forhold—markant anderledes end Googles 14:1, hvor crawl-aktivitet bliver til reel trafik. Denne grundlæggende forskel skaber en presserende forretningsbeslutning for indholdsskabere: Giver du disse bots fri adgang, træner dit indhold AI-modeller, som konkurrerer med din trafik og dine indtægtskilder, mens dit site får minimal kompensation eller trafik til gengæld. Udgivere skal nu aktivt beslutte, om værdien i AI-botters adgang matcher deres forretningsmodel, hvilket gør robots.txt-konfiguration til ikke blot en teknisk, men også en strategisk forretningsmæssig nødvendighed.
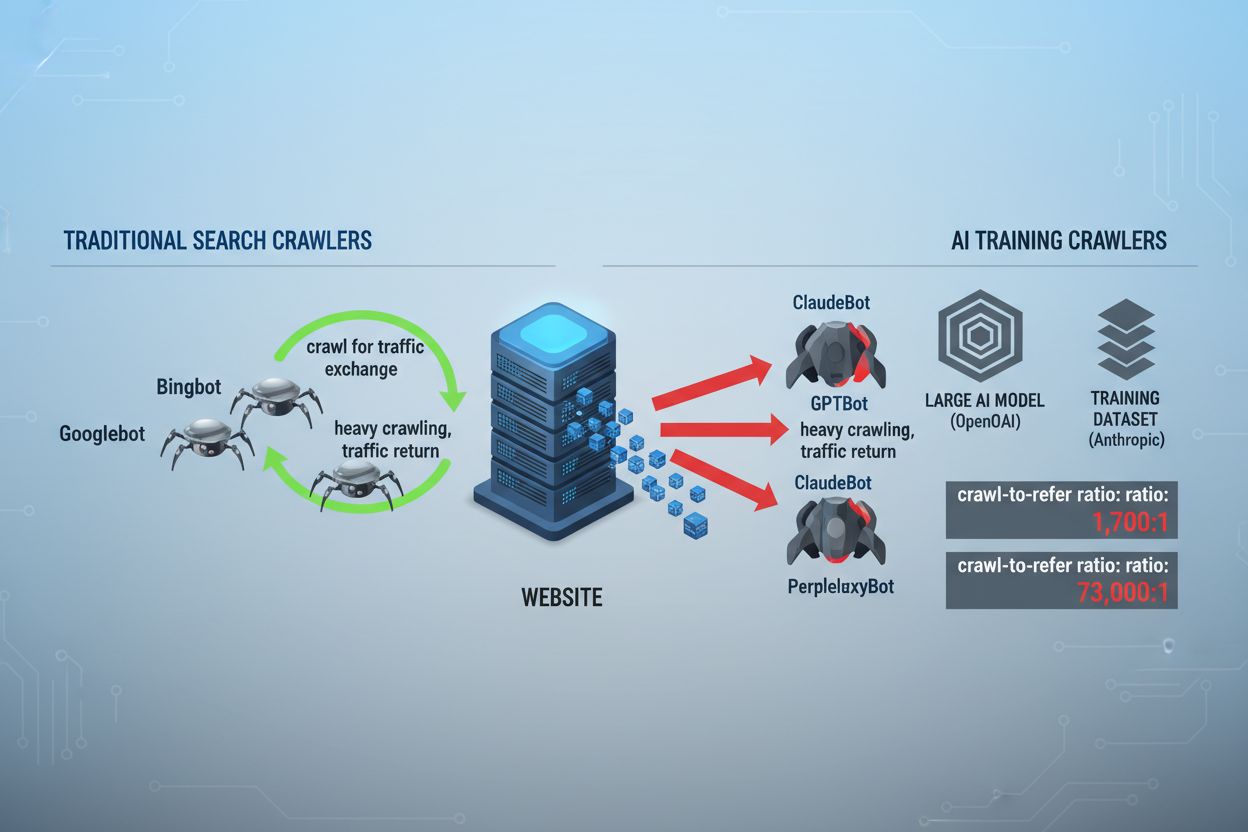
AI-crawlere opererer inden for tre distinkte kategorier, der hver især tjener forskellige formål og kræver forskellige blokeringstrategier. Træningscrawlere er designet til at indsamle store mængder indhold til træning af grundlæggende AI-modeller—herunder OpenAI’s GPTBot, Anthropics ClaudeBot, Googles Google-Extended, Perplexitys PerplexityBot, Metas Meta-ExternalAgent, Apples Applebot-Extended og nye aktører som Amazonbot, Bytespider og cohere-ai. Søgecrawlere derimod driver AI-drevne søgeoplevelser og returnerer typisk trafik til udgivere; disse inkluderer OpenAI’s OAI-SearchBot, Anthropics Claude-Web og Perplexitys søgefunktion. Brugerudløste agenter repræsenterer en tredje kategori, hvor indhold tilgås on-demand, når en bruger specifikt beder om information, såsom ChatGPT-User eller Claude-Web-interaktioner startet direkte af slutbrugere. At forstå denne taksonomi er kritisk, fordi din blokeringstrategi skal afspejle dine forretningsprioriteter—du kan byde søgecrawlere velkommen, der giver trafik, mens du blokerer træningscrawlere, som benytter indholdet uden kompensation. Hver stor AI-virksomhed har sine egne specialiserede crawlere, og forskellen mellem dem ligger ofte i det specifikke user agent-string, de bruger, hvilket gør præcis identifikation og målrettet blokering essentiel for effektiv robots.txt-konfiguration.
| Firma | Træningscrawler | Søgecrawler | Brugerudløst agent |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Bruger standard Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
At opretholde en nøjagtig, opdateret liste over AI-bots user agents er essentielt for effektiv robots.txt-konfiguration, men dette område udvikler sig hurtigt, efterhånden som nye modeller lanceres og virksomheder justerer deres crawling-strategier. De vigtigste træningscrawlere, du skal kende, inkluderer GPTBot (OpenAI’s primære træningscrawler), ClaudeBot (Anthropics træningscrawler), anthropic-ai (Anthropics alternative identifikator), Google-Extended (Googles AI-træningstoken), PerplexityBot (Perplexitys crawler), Meta-ExternalAgent (Metas træningscrawler), Applebot-Extended (Apples AI-træningsvariant), CCBot (Common Crawl’s bot), Amazonbot (Amazons crawler), Bytespider (ByteDances crawler), cohere-ai (Cohere’s træningsbot), DuckAssistBot (DuckDuckGo’s AI-assistent-crawler) og YouBot (You.com’s crawler). Søgeorienterede crawlere, der typisk returnerer trafik, inkluderer OAI-SearchBot, Claude-Web og PerplexityBot i søgefunktion. Udfordringen er, at denne liste ikke er statisk—nye AI-virksomheder dukker op jævnligt, eksisterende firmaer lancerer nye crawlere til nye produkter, og user agent-strings ændres eller udvides undertiden. Udgivere bør betragte deres robots.txt-konfiguration som et levende dokument, der kræver kvartalsvise gennemgange og opdateringer, eventuelt ved at abonnere på brancheovervågning eller overvåge serverlogs for ukendte user agents, som kan indikere nye AI-crawlere på dit site. Hvis du ikke holder din user agent-liste opdateret, risikerer du enten at give nye træningscrawlere adgang, du egentlig ville blokere, eller unødvendigt at blokere legitime søgecrawlere, som kunne give værdifuld trafik.
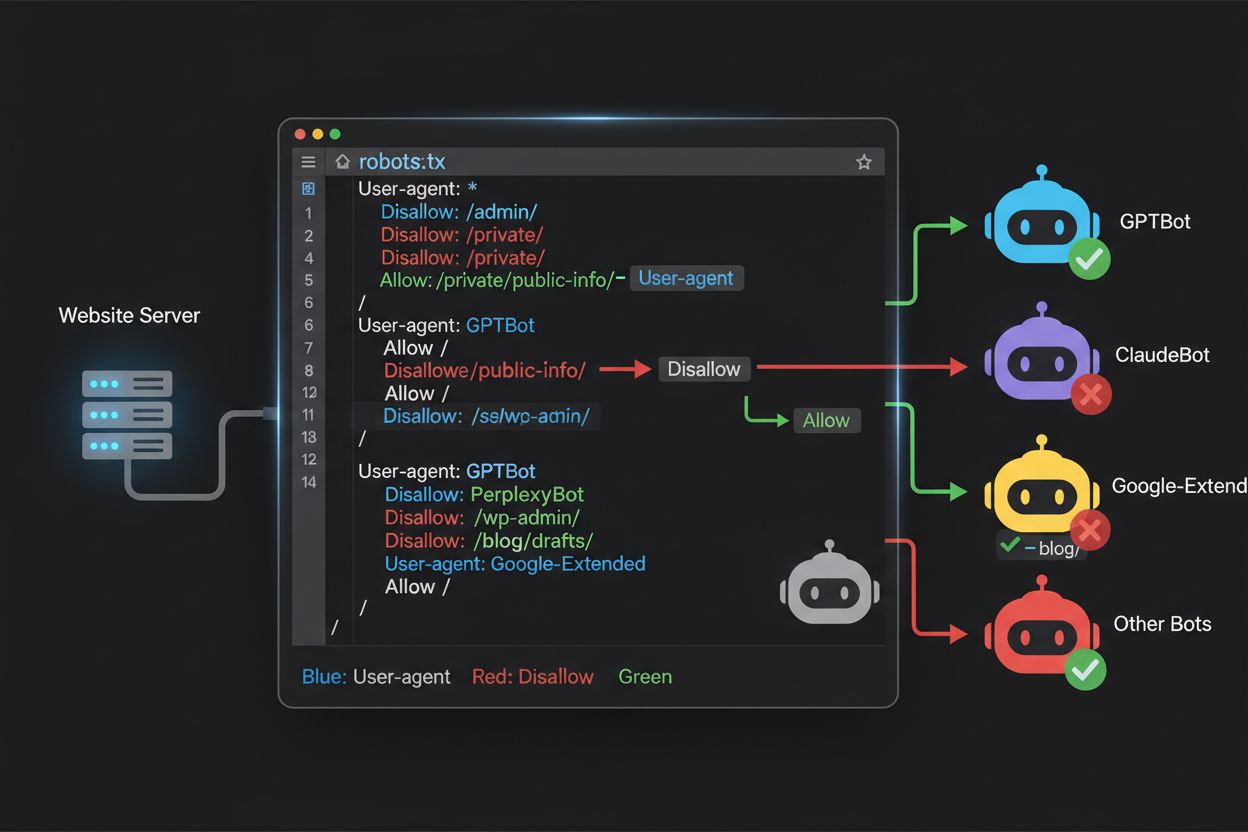
Robots.txt-filen, placeret i roden af dit domæne (yourdomain.com/robots.txt), bruger en enkel syntaks til at kommunikere crawl-præferencer til bots, der respekterer protokollen. Hver regel starter med et User-Agent-direktiv, der angiver, hvilken bot reglen gælder for, efterfulgt af en eller flere Disallow-direktiver, der angiver, hvilke stier botten ikke må tilgå. For at blokere alle store AI-træningscrawlere, mens du bevarer adgang for traditionelle søgemaskiner, opretter du separate User-Agent-blokke for hver træningscrawler, du ønsker at udelukke: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended og andre, hver med et “Disallow: /"-direktiv, som forhindrer dem i at crawle noget indhold på dit site. Samtidig sikrer du, at legitime søgecrawlere som Googlebot, Bingbot og søgevarianter som OAI-SearchBot forbliver ubeskyttede, så de fortsat kan indeksere dit indhold og generere trafik. En korrekt konfigureret robots.txt-fil bør også inkludere en Sitemap-reference til dit XML-sitemap, hvilket hjælper søgemaskiner med at opdage og indeksere dit indhold effektivt. Vigtigheden af korrekt konfiguration kan ikke overdrives—en enkelt syntaksfejl, forkert tegn eller forkert user agent-string kan gøre hele din blokeringstrategi ineffektiv og tillade uønskede crawlere adgang til dit indhold, mens legitime trafikkilder potentielt blokeres. Test af din konfiguration før implementering er derfor ikke valgfrit, men essentielt for at sikre, at din robots.txt virker efter hensigten.
# Bloker AI-træningscrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Tillad traditionelle søgemaskiner
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Sitemap reference
Sitemap: https://yoursite.com/sitemap.xml
Mange udgivere står over for en nuanceret beslutning: de ønsker at opretholde synlighed i AI-drevne søgeresultater og modtage den henvisningstrafik, disse platforme genererer, men de vil forhindre, at deres indhold bruges til at træne grundlæggende AI-modeller, der konkurrerer med deres forretning. Denne selektive blokering kræver, at man skelner mellem søgecrawlere og træningscrawlere fra samme virksomhed—f.eks. tillader du OpenAI’s OAI-SearchBot (som driver ChatGPT’s søgefunktion og returnerer trafik), mens du blokerer GPTBot (som træner den underliggende model). Tilsvarende kan du tillade PerplexityBots søgecrawler, mens du blokerer dens træningsoperationer, eller tillade Claude-Web for brugerudløste søgninger, mens du blokerer ClaudeBots træningsaktiviteter. Forretningsargumentet er overbevisende: Søgecrawlere opererer typisk med meget lavere crawl-to-refer-forhold, fordi de er designet til at drive trafik tilbage til dit site, mens træningscrawlere konsumerer indhold i massiv skala med minimal fordel for dig. Denne tilgang kræver omhyggelig konfiguration og løbende overvågning, da virksomheder nogle gange ændrer deres crawlerstrategier eller introducerer nye user agents, der udvisker grænsen mellem søgning og træning. Udgivere, der følger denne strategi, bør regelmæssigt gennemgå deres serverlogs for at verificere, at de ønskede crawlere får adgang til indholdet, mens blokerede crawlere effektivt udelukkes, og tilpasse deres robots.txt-konfiguration i takt med, at AI-landskabet udvikler sig og nye aktører kommer til.
# Tillad AI-søgecrawlere
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Bloker træningscrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Selv erfarne webmastere laver ofte konfigurationsfejl, der fuldstændigt underminerer deres robots.txt-strategi og efterlader indholdet sårbart over for de crawlere, de ville blokere. Den første almindelige fejl er at oprette stående User-Agent-linjer uden tilsvarende Disallow-direktiver—for eksempel at skrive “User-Agent: GPTBot” på én linje og derefter straks starte en ny regel uden at specificere, hvad GPTBot skal nægtes adgang til, hvilket efterlader botten helt ubeskyttet. Den anden fejl involverer forkert filplacering, navngivning eller brug af store bogstaver; filen skal hedde præcist “robots.txt” (små bogstaver), placeres i roden af dit domæne og leveres med en 200 HTTP-statuskode—placerer du den i en undermappe eller navngiver den “Robots.txt” eller “robots.TXT”, bliver den usynlig for crawlere. Den tredje fejl er indsættelse af blanke linjer inden for en regelblok, hvilket mange robots.txt-fortolkere tolker som afslutningen på reglen, så efterfølgende direktiver ignoreres eller anvendes forkert. Den fjerde fejl handler om forskel på store og små bogstaver i URL-stier; mens user agent-navne ikke skelner mellem store og små bogstaver, gør stier i Disallow-direktiver det, så “Disallow: /Admin” blokerer ikke “/admin” eller “/ADMIN”. Den femte fejl er forkert brug af wildcards—stjerne (*) matcher alle tegn, men mange udgivere bruger det forkert, f.eks. “Disallow: .pdf”, når de burde skrive “Disallow: /.pdf” eller “Disallow: /*pdf” for korrekt at matche filendelser. Derudover skaber nogle udgivere alt for komplekse regler med flere Disallow-direktiver, der modarbejder hinanden, eller de glemmer at tage højde for URL-parametre og forespørgselsstrenge, hvilket kan betyde, at legitimt indhold blokeres, eller uønsket indhold stadig kan tilgås. Test af din konfiguration med dedikerede robots.txt-validatorer før implementering kan fange disse fejl, før de påvirker dit sites crawlbarhed.
Almindelige fejl, der skal undgås:
Google-Extended er et særtilfælde i robots.txt-konfiguration, fordi det fungerer som et kontroltoken og ikke som en traditionel crawler, og det er vigtigt at forstå denne forskel for at tage informerede blokeringbeslutninger. I modsætning til Googlebot, der crawler dit site for at indeksere indhold til Google Search, er Google-Extended et signal, der styrer, om dit indhold kan bruges til at træne Googles Gemini AI-modeller og drive Googles AI Overviews-funktion i søgeresultater. Blokering af Google-Extended forhindrer dit indhold i at blive brugt i Gemini-træning og AI Overview-generering, men påvirker ikke din synlighed i traditionelle Google Search-resultater—Googlebot vil fortsat indeksere dit indhold normalt. Afvejningen er væsentlig: Blokerer du Google-Extended, vises dit indhold ikke i AI Overviews, som fylder mere og mere i Google Search og kan give betydelig trafik, men du beskytter dit indhold mod at indgå i træning af konkurrerende AI-modeller. Omvendt betyder tilladelse af Google-Extended, at dit indhold kan vises i AI Overviews (med potentielt trafikafkast), men også bidrager til at træne Gemini, som på sigt kan konkurrere med dit eget indhold eller forretningsmodel. Udgivere bør nøje overveje deres situation—nyhedsorganisationer og indholdsskabere, der lever af direkte trafik, kan have fordel af at blokere Google-Extended, mens andre kan vælge at byde synlighed og trafikpotentiale fra AI Overviews velkommen. Beslutningen bør træffes bevidst og ikke pr. automatik, da den har væsentlige konsekvenser for din langsigtede synlighed og trafikmønster i Googles økosystem.
Test af din robots.txt-konfiguration før implementering i produktion er helt afgørende, da fejl kan få vidtrækkende konsekvenser både for din synlighed i søgning og for din indholdsbeskyttelse. Google Search Console tilbyder en indbygget robots.txt-tester, hvor du kan verificere, om bestemte user agents kan tilgå bestemte URL’er på dit site—du kan indtaste en user agent-string som “GPTBot” og en URL-sti, og Google fortæller dig, om denne bot ville blive tilladt eller blokeret ifølge din nuværende konfiguration. Merkle Robots.txt Tester tilbyder lignende funktionalitet med et brugervenligt interface og detaljerede forklaringer på, hvordan dine regler fortolkes. TechnicalSEO.com tilbyder et gratis testværktøj, der validerer din robots.txt-syntaks og viser dig præcis, hvordan forskellige bots behandles. For mere omfattende overvågning tilbyder Knowatoa AI Search Console specialværktøjer til at spore AI-crawler-aktivitet og validere din konfiguration mod netop de bots, du forsøger at blokere. Din valideringsproces bør omfatte upload af din robots.txt til et staging-miljø først, derefter verificere, at vigtige sider, du ønsker tilgængelige, ikke blokeres ved en fejl, bekræfte, at de AI-bots, du vil blokere, faktisk udelukkes, og overvåge dine serverlogs for uventet crawleraktivitet. Denne testfase bør også inkludere kontrol af, at din Sitemap-reference er korrekt, og at søgemaskiner stadig kan tilgå dit indhold normalt—du vil blokere AI-træningscrawlere uden utilsigtet at blokere legitim søgetrafik. Først efter grundig test bør du udrulle din konfiguration til produktion, og selv da bør du fortsætte med at overvåge dine logs i den første uge for at fange uventede problemer.
Testværktøjer:
Selvom robots.txt er en nyttig første forsvarslinje, bør du forstå, at den fungerer på æresord—bots, der respekterer protokollen, vil følge dine direktiver, men ondsindede eller dårligt designede crawlere kan ignorere robots.txt fuldstændigt og tilgå dit indhold alligevel. Branchedata antyder, at robots.txt stopper ca. 40-60% af uønsket crawlertrafik, hvilket betyder, at 40-60% af bots enten ignorerer protokollen eller er designet til at omgå den. For udgivere, der kræver mere robust beskyttelse, bliver yderligere forsvarslag nødvendige. Cloudflares Web Application Firewall (WAF) lader dig oprette regler, der blokerer trafik baseret på user agent-strings, IP-adresser eller adfærdsmønstre og beskytter mod bots, der ignorerer robots.txt. Server-baserede værktøjer som .htaccess (på Apache-servere) eller tilsvarende konfiguration på Nginx kan blokere specifikke user agents eller IP-intervaller, før anmodningerne overhovedet når din applikation. IP-blokering kan være effektivt, hvis du identificerer IP-intervaller, der bruges af bestemte crawlere, men dette kræver løbende vedligeholdelse, da crawler-infrastrukturen ændres. Fail2ban og lignende værktøjer kan automatisk blokere IP’er, der udviser mistænkelig adfærd, f.eks. anmoder i umenneskelig hastighed eller tilgår følsomme stier. Implementering af disse ekstra beskyttelser kræver dog omhyggelig konfiguration—alt for aggressiv blokering kan utilsigtet udelukke legitim trafik, herunder rigtige brugere, der tilgår dit site via VPN eller firmaproxy, som deler IP-intervaller med kendte crawlere. Den mest effektive tilgang kombinerer robots.txt som en høflig anmodning, user agent-blokering på serverniveau for bots, der ignorerer robots.txt, og adfærdsbaseret overvågning for at fange sofistikerede crawlere, der spoof’er user agents eller bruger distribuerede IP-adresser. Udgivere bør implementere disse lag trinvis og teste hvert lag for at sikre, at de ikke ved en fejl blokerer legitim trafik, samtidig med at de opnår deres indholdsbeskyttelsesmål.
Forståelse af, hvad der faktisk tilgår dit site, er essentielt for at validere, at din robots.txt-konfiguration virker efter hensigten, og for at identificere nye crawlere, der skal blokeres. Serverloganalyse er den primære metode til denne overvågning—dine webserverlogs (Apache access logs, Nginx logs eller tilsvarende) indeholder detaljerede poster over alle anmodninger til dit site, inklusiv user agent-string, IP-adresse, tidspunkt og forespurgt ressource. Du kan bruge kommandolinjeværktøjer som grep til at søge i dine logs efter specifikke user agents; f.eks. “grep ‘GPTBot’ /var/log/apache2/access.log” vil vise alle anmodninger fra GPTBot, så du kan verificere, om dine blokeringregler virker. Mere avanceret analyse kan indebære at parse logs for at identificere crawlrate for forskellige bots, de specifikke sider, de tilgår, og om de respekterer dine robots.txt-direktiver. Automatiserede overvågningsløsninger kan løbende analysere dine logs og advare dig, når nye eller uventede crawlere dukker op, hvilket er særligt værdifuldt, da AI-crawlerlandskabet hurtigt udvikler sig. Nogle udgivere bruger logaggregeringsplatforme som ELK Stack, Splunk eller cloud-løsninger til at centralisere og analysere crawleraktivitet på tværs af flere servere. Det hurtigt skiftende landskab for AI-crawlere betyder, at overvågning ikke er en engangsopgave, men et løbende ansvar—nye bots dukker løbende op, eksisterende bots ændrer deres user agent-strings, og crawleradfærd udvikler sig, efterhånden som virksomheder justerer deres strategier. Etabler en fast overvågningsrutine (ugentlig eller månedlig loggennemgang) for at holde dig foran udviklingen og justere din robots.txt-konfiguration proaktivt frem for reaktivt at opdage problemer, når de allerede har ramt dit site.
Din robots.txt-konfiguration for AI-crawlere er i bund og grund en indtægtsbeslutning og fortjener samme strategiske overvejelse, som du ville anvende på enhver forretningsbeslutning med betydelige økonomiske konsekvenser. At give træningscrawlere fri adgang til dit indhold betyder, at AI-modeller trænet på dine data måske senere konkurrerer med din trafik og dine indtægtskilder—hvis din forretning bygger på direkte trafik, søgesynlighed eller annonceindtægter, giver du reelt gratis træningsdata til virksomheder, der udvikler konkurrerende produkter. Omvendt mister du potentiel synlighed i AI-drevne søgeresultater og henvisningstrafik fra AI-assistenter, hvis du blokerer alle AI-crawlere, hvilket er en voksende kanal for indholdsopdagelse. Den optimale strategi afhænger af din forretningsmodel: annonceunderstøttede udgivere kan have fordel af at tillade søgecrawlere (som giver trafik og annoncevisninger) og blokere træningscrawlere (som ikke giver trafik). Abonnementsbaserede udgivere kan vælge en mere restriktiv tilgang og blokere de fleste AI-crawlere for at beskytte deres indhold mod at blive opsummeret eller gengivet af AI-systemer. Udgivere med fokus på synlighed og thought leadership kan byde AI-søgesynlighed velkommen som distributionskanal. Nøglen er at træffe beslutningen bevidst frem for pr. automatik—mange udgivere har aldrig konfigureret deres robots.txt for AI-crawlere og har dermed implicit givet alle bots adgang, hvilket betyder, at de passivt har valgt at bidrage med indhold til AI-træning uden aktivt at tage stilling. Overvej også at implementere schema-markup, der sikrer korrekt attribution, når dit indhold bruges af AI-systemer, så trafik og kredit tilfalder dit site, selv når indholdet refereres af AI-assistenter. Din robots.txt-konfiguration bør afspejle din bevidste forretningsstrategi, gennemgås og opdateres løbende i takt med, at AI-landskabet og dine egne prioriteter ændrer sig.
AI-crawlerlandskabet udvikler sig i et hidtil uset tempo, hvor nye virksomheder lancerer AI-produkter, eksisterende virksomheder introducerer nye crawlere, og user agent-strings løbende ændres eller udvides. Din robots.txt-konfiguration bør ikke være en “sæt og glem”-fil, men et levende dokument, du gennemgår og opdaterer mindst kvartalsvist. Opret en proces for at overvåge branchemeddelelser om nye AI-crawlere, abonnér på relevante branche-nyhedsbreve eller blogs, der følger udviklingen, og auditér jævnligt dine serverlogs for ukendte user agents, der kan indikere nye crawlere på dit site. Når du opdager nye crawlere, undersøg deres formål og forretningsmodel for at afgøre, om de passer ind i din indholdsbeskyttelsesstrategi, og opdater så din robots.txt derefter. Overvåg desuden effektiviteten af din konfiguration ved at holde øje med metrics som crawlertrafikmængde, forhold mellem crawler-anmodninger og brugeranmodninger samt eventuelle ændringer i din organiske søgesynlighed eller henvisningstrafik fra AI-drevne søgeresultater. Nogle udgivere oplever, at deres oprindelige blokeringstrategi skal justeres efter nogle måneders data—måske opdager de, at blokering af en bestemt crawler havde utilsigtede konsekvenser, eller at tilladelse af visse crawlere gav mere værdifuld trafik end forventet. Vær klar til at justere din strategi baseret på reelle resultater og ikke antagelser. Sørg endelig for at kommunikere din robots.txt-strategi til relevante interessenter i organisationen—dit SEO-team, indholdsteam og forretningsledelse bør alle forstå, hvorfor bestemte crawlere blokeres eller tillades, så beslutninger forbliver konsistente og bevidste, efterhånden som organisationen udvikler sig. Denne løbende opmærksomhed på crawlerstyring sikrer, at din indholdsbeskyttelsesstrategi forbliver effektiv og tilpasset dine forretningsmål, mens AI-landskabet fortsætter med at forandre sig.
Nej. Blokering af AI-træningscrawlere som GPTBot, ClaudeBot og CCBot påvirker ikke dine Google- eller Bing-søgerangeringer. Traditionelle søgemaskiner bruger andre crawlere (Googlebot, Bingbot), der opererer uafhængigt. Bloker kun disse, hvis du vil forsvinde helt fra søgeresultater.
Store crawlere fra OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) og Perplexity (PerplexityBot) siger officielt, at de respekterer robots.txt-direktiver. Mindre eller mindre gennemsigtige bots kan dog ignorere din konfiguration, hvilket er grunden til, at lagdelte beskyttelsesstrategier findes.
Det afhænger af din strategi. Blokering af kun træningscrawlere (GPTBot, ClaudeBot, CCBot) beskytter dit indhold mod modeltræning, mens søgefokuserede crawlere stadig kan hjælpe dig med at dukke op i AI-søgeresultater. Komplet blokering fjerner dig helt fra AI-økosystemer.
Gennemgå din konfiguration mindst en gang i kvartalet. AI-virksomheder introducerer regelmæssigt nye crawlere. Anthropic fusionerede deres 'anthropic-ai' og 'Claude-Web' bots til 'ClaudeBot', hvilket gav den nye bot midlertidig ubegrænset adgang til sider, der ikke havde opdateret deres regler.
Robots.txt er en fil i roden af dit domæne, der gælder for alle sider, mens meta robots tags er HTML-direktiver på individuelle sider. Robots.txt tjekkes først og kan forhindre crawlere i at tilgå en side, mens meta-tags kun læses, hvis siden tilgås. Brug begge for fuld kontrol.
Ja. Du kan bruge sti-specifikke Disallow-regler i robots.txt (f.eks. 'Disallow: /premium/' for kun at blokere premium-indhold) eller bruge meta robots tags på enkelte sider. Dette lader dig beskytte følsomt indhold, mens crawlere stadig har adgang til andre områder.
Hvis en bot ignorerer robots.txt, skal du bruge ekstra beskyttelsesmetoder som server-niveau blokering (.htaccess), IP-blokering eller WAF-regler. Robots.txt stopper cirka 40-60% af uønskede crawlere, så lagdelt beskyttelse er vigtig for fuld dækning.
Brug testværktøjer som Google Search Console's robots.txt tester, Merkle Robots.txt Tester eller TechnicalSEO.com til at validere din konfiguration. Overvåg dine serverlogs for crawleraktivitet for at verificere, at blokerede bots udelukkes, og tilladte bots får adgang til dit indhold.
Robots.txt er kun det første skridt. Brug AmICited til at spore, hvilke AI-systemer der citerer dit indhold, hvor ofte de refererer til dig, og sikre korrekt attribution på tværs af GPTs, Perplexity, Google AI Overviews og mere.
Lær at tillade eller blokere AI-crawlere selektivt baseret på forretningsmål. Implementer differentiel crawler-adgang for at beskytte indhold, mens synligheden ...

Lær hvordan du tester, om AI-crawlere som ChatGPT, Claude og Perplexity kan få adgang til dit websites indhold. Opdag testmetoder, værktøjer og best practices f...

Lær hvordan webapplikationsfirewalls giver avanceret kontrol over AI-crawlere ud over robots.txt. Implementer WAF-regler for at beskytte dit indhold mod uautori...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.