
Hvilken schema markup hjælper med AI-søgning? Komplet guide for 2025
Opdag hvilke typer schema markup der øger din synlighed i AI-søgemaskiner som ChatGPT, Perplexity og Gemini. Lær JSON-LD implementeringsstrategier for AI-svarge...
9 min læsning

Lær hvilke schema-typer der er vigtigst for AI-synlighed. Opdag hvordan LLM’er fortolker strukturerede data og implementer schema markup-strategier, der får dit brand nævnt i AI-svar.
I årevis handlede schema markup primært om at vinde rich results—de iøjnefaldende stjernebedømmelser, produktkort og FAQ-accordioner, der dukkede op i traditionelle søgeresultater. I dag er den tilgang ved at blive forældet. Store sproglige modeller og AI-svarmotorer fortolker schema markup på fundamentalt anderledes måder; de bruger det ikke til kosmetiske forbedringer, men til at opbygge knowledge graphs og forstå entitetsrelationer i stor skala. Med cirka 45 millioner websites (12,4% af alle registrerede domæner), der nu implementerer en eller anden form for schema.org-markup, har AI-systemer adgang til en hidtil uset mængde strukturerede data at lære fra og stole på. Skiftet er markant: schema markup påvirker nu, om dit brand bliver nævnt i AI-genererede svar, hvor præcist modellerne repræsenterer dine produkter og ydelser, og om dit indhold bliver en troværdig kilde i et AI-først søgelandskab.
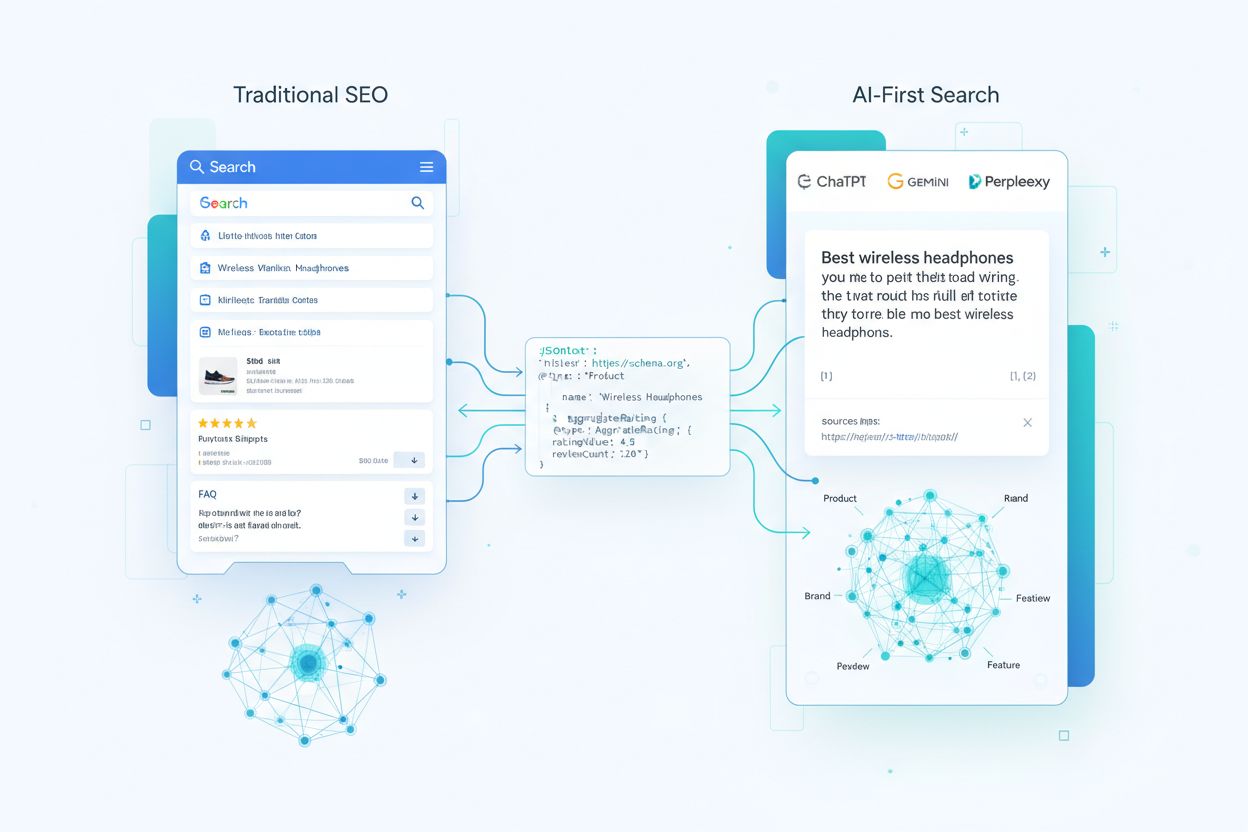
At forstå, hvordan AI-systemer bruger schema markup, kræver at man følger de strukturerede datas rejse fra første crawl til LLM-genererede svar. Når en crawler møder din side, udtrækker den JSON-LD, microdata eller RDFa-blokke og normaliserer dem i et indeks sammen med ustruktureret tekst og medier. Disse strukturerede data bliver en del af et knowledge graph i webskala, hvor entiteter forbindes via relationer og tildeles embedding for semantisk søgning. I retrieval-augmented generation (RAG)-systemer kan schema direkte indgå i de chunks, der udfylder vektorindekser—et enkelt chunk kan indeholde både en produktbeskrivelse og dens JSON-LD markup, hvilket giver modeller både narrativ kontekst og strukturerede nøgle-værdi-attributter. Forskellige LLM-arkitekturer bruger schema forskelligt: nogle lægger modeller oven på eksisterende søgeindekser og knowledge graphs, mens andre anvender multi-source retrieval pipelines, der trækker fra både struktureret og ustruktureret indhold. Den afgørende indsigt er, at velimplementeret schema fungerer som en kontrakt med modellen, der i højstruktureret form angiver, hvilke fakta på din side du anser for kanoniske og pålidelige.
| Arkitekturtype | Schema-brug | Citationspåvirkning | Nøgleegenskaber |
|---|---|---|---|
| Traditionel søgning + LLM-lag | Forbedrer eksisterende knowledge graph | Høj - modeller citerer velformede kilder | Organization, Product, Article |
| Retrieval-Augmented Generation | Indlejres i vektor-chunks | Medium-høj - schema hjælper med præcision | Alle typer med detaljerede egenskaber |
| Multi-Source Answer Engines | Bruges til entitetsopløsning | Medium - konkurrerer med andre signaler | Person, LocalBusiness, Service |
| Conversational AI | Understøtter kontekstforståelse | Variabel - afhænger af træningsdata | FAQPage, HowTo, BlogPosting |
Ikke alle schema-typer vægtes lige højt i AI-æraen. Organization-markup fungerer som anker for hele dit entitetsgraph og hjælper modeller med at forstå dit brands identitet, autoritet og relationer. Product-schema er essentielt for e-handel og detail, idet det gør AI-systemer i stand til at sammenligne funktioner, priser og bedømmelser på tværs af kilder. Article- og BlogPosting-markup hjælper modeller med at identificere længere indhold, der egner sig til forklarende forespørgsler og thought leadership. Person-schema er afgørende for at etablere forfatterens troværdighed og ekspertattribution i AI-genererede svar. FAQPage-markup kortlægger direkte til konversationelle forespørgsler, som AI-assistenter er designet til at besvare. For SaaS- og B2B-virksomheder er SoftwareApplication- og Service-typer lige så vigtige og optræder ofte i “bedste værktøjer til X”-sammenligninger og feature-evalueringer. For lokale forretninger og sundhedsudbydere giver LocalBusiness- og MedicalOrganization-typer geografisk præcision og regulatorisk klarhed. Den egentlige differentiering kommer dog ikke fra basal typeanvendelse, men fra de avancerede egenskaber, du lægger ovenpå—konsistens på tværs af sider, klare entitetsidentifikatorer og eksplicit relationsmapping.
Basale schema-egenskaber som name, description og URL er nu standard; 72,6% af siderne på Googles første side bruger allerede en eller anden form for schema markup. De egenskaber, der skaber reel differentiering for AI-synlighed, er det bindeled, der hjælper modeller med at opløse entiteter, forstå relationer og afklare betydning. Her er de avancerede egenskaber, der betyder mest:
Disse egenskaber forvandler schema fra en simpel databeholder til et semantisk kort, som modeller kan navigere med sikkerhed. Når du bruger sameAs til at linke din organisation til dens Wikipedia-side, tilføjer du ikke bare metadata—du fortæller modellen “dette er den autoritative kilde til fakta om os”. Når du bruger additionalProperty til at indkode produktspecifikationer eller servicefunktioner, leverer du præcis de attributter, AI-systemer søger, når de sammensætter sammenligninger eller anbefalinger.
De fleste organisationer ser schema markup som en engangsimplementering, men konkurrencefordel i AI-drevet søgning kræver, at man tænker på det som løbende datastyring. En nyttig ramme er en fire-niveau modenhedsmodel, der hjælper teams med at forstå, hvor de er, og hvor de skal hen:
Niveau 1 – Grundlæggende rich result schema fokuserer på minimal markup på udvalgte skabeloner, primært for at opnå berettigelse til stjerner, produktkort eller FAQ-snippets. Governance er løs, konsistensen lav, og målet er kosmetisk frem for semantisk klarhed.
Niveau 2 – Entitetscentreret dækning standardiserer Organization, Product, Article og Person markup på nøgleskabeloner, indfører konsekvent brug af @id-værdier og tilføjer basale sameAs-links for at undgå entitetsforvirring.
Niveau 3 – Knowledge-graph-integreret schema tilpasser schema-ID’er til interne datamodeller (CMS, PIM, CRM), bruger flittigt about/mentions/additionalType-egenskaber og indkoder relationer på tværs af sider, så modeller forstår, hvordan indholdsnoder relaterer til hinanden og til eksterne entiteter.
Niveau 4 – LLM-optimeret & RAG-tilpasset schema strukturerer bevidst markup til konversationelle forespørgsler og AI-snippet-formater, tilpasser schema med interne RAG-pipelines og inkluderer måling og iteration som kernepraksisser.
De fleste brands ligger i øjeblikket på niveau 1–2, hvilket betyder, at basal adoption nu er et hygiejnekrav og ikke en differentieringsfaktor. At bevæge sig mod niveau 3–4 er dér, hvor schema-LLM-optimering bliver en holdbar konkurrencefordel, fordi modeller pålideligt kan fortolke dine entiteter på tværs af mange forespørgselsformuleringer og platforme.
Forskellige brancher har forskellige entiteter, risikoprofiler og brugerintentioner, så avanceret schema-brug kan ikke være én størrelse for alle. Grundprincipperne—entitetsklarhed, relationsmodellering og overensstemmelse med on-page indhold—er konstante, men de schema-typer og egenskaber, du prioriterer, bør afspejle, hvordan folk faktisk søger i din branche.
For e-handel og detail er de primære entiteter Products, Offers, Reviews og din Organization. Hver side med høj købsintention bør have detaljeret Product-markup inklusiv identifikatorer (SKU, GTIN), brand, model, dimensioner, materialer og differentierende attributter via additionalProperty. Kombiner dette med Offers, der koder pris og tilgængelighed, og AggregateRating-strukturer, der hjælper modeller med at forstå social proof. Ud over det basale, tænk over hvordan shoppere formulerer spørgsmål: “Er dette vandtæt?” “Følger der garanti med?” “Hvad er returpolitikken?” At kode disse svar som FAQPage-markup på samme URL og sikre, at Product-attributter og FAQ-indhold er synkroniseret, gør det langt lettere for svarmotorer at citere den korrekte side.
For SaaS og B2B-services er entiteterne mere abstrakte, men matcher godt med SoftwareApplication-, Service- og Organization-schema. For hvert kerneprodukt eller ydelse, definer en SoftwareApplication- eller Service-entitet med klare beskrivelser af kategori, understøttede platforme, integrationer og prismodeller, brug additionalProperty-felter til at opliste features, der ofte indgår i “bedste værktøjer til X”-sammenligninger. Forbind disse til din Organization via provider- eller offers-relationer og til dine eksperter via Person-markup. På indholdssiden hjælper Article, BlogPosting, FAQPage og HowTo-strukturer LLM’er med at identificere dine bedste aktiver til vurderende og uddannelsesmæssige forespørgsler.
For lokale, sundheds- og regulerede brancher kan LocalBusiness-, MedicalOrganization- og beslægtede MedicalEntity-typer kode adresser, serviceområder, specialer, accepteret forsikring og åbningstider langt mindre tvetydigt end fritekst. Det er vigtigt, når en AI-assistent bliver spurgt: “Find en pædiatrisk kardiolog nær mig, der tager min forsikring” eller “Anbefal en akutmodtagelse, der har åbent nu.” I disse brancher skal du især sikre, at schema ikke overdriver eller eksponerer følsomme oplysninger—markér kun fakta, du er tryg ved kan genbruges i mange kontekster, og sørg for, at compliance- og jurateams gennemgår alle medicinske eller regulerede attributter.
LLM-adfærd er iboende stokastisk, så du opnår ikke perfekt attribution alene fra schema-ændringer. Det, du kan gøre, er at opbygge et let overvågningssystem, der løbende sampler AI-svar for et defineret sæt forespørgsler. Spor, hvilke entiteter der nævnes, hvilke URL’er der citeres, hvordan dit brand beskrives, og om nøglefakta (priser, funktioner, compliance-detaljer) er korrekte på tværs af platforme som ChatGPT, Gemini, Perplexity og Bing Copilot. Når tingene går galt—hallucinerede funktioner, manglende nævnelser eller citater, der favoriserer aggregatorer frem for dine primære sider—så start med at tjekke for modstridende eller ufuldstændige signaler. Modarbejder on-page tekst schema’et? Mangler sameAs-links eller peger de på forældede profiler? Gør flere sider krav på at være kanonisk kilde til samme entitet? Strategisk set bør du planlægge en schema-gennemgang mindst kvartalsvis, så det matcher nye tilbud, indholdsklynger og ændringer i, hvordan AI-svarmotorer fremhæver dit brand.
Flere mønstre underminerer konsekvent schema-effektiviteten for AI-systemer. At markere indhold op, som ikke faktisk er synligt på siden, skaber et tillidsunderskud—modeller lærer at ignorere kilder, hvor schema og synligt indhold ikke stemmer overens. At bruge alt for generiske typer uden specificitet (fx at markere alt som “Thing” eller “CreativeWork”) giver ingen semantisk signal; modeller har brug for præcise typer for at forstå kontekst. At kopiere standardschema på tværs af sider uden at tilpasse entitetsdetaljer er nok den mest almindelige fejl—når hver produktside har identisk Organization-markup eller alle artikler hævder samme forfatter, får modeller svært ved at skelne og kan nedprioritere dit indhold som lavsignalkilde. Inkonsekvente entitets-id’er på tværs af sider (forskellige @id-værdier for samme organisation eller produkt) bryder entitetsopløsning og tvinger modeller til at behandle relateret indhold som selvstændige entiteter. Manglende sameAs-links til autoritative profiler gør det sværere for modeller at adskille dit brand fra navnesøstre. Endelig signalerer modstridende information mellem schema og on-page tekst upålidelighed; hvis dit schema siger, at et produkt er på lager, men siden siger “ikke på lager”, vil modeller stole på ingen af delene.
Schema markup er ved at gå fra at være en kosmetisk SEO-taktik til at være en grundlæggende teknologi for AI-først søgning. Forbundet schema markup—hvor du eksplicit definerer relationer mellem entiteter via properties som sameAs, about og mentions—bygger knowledge graphs, som AI-systemer trygt kan navigere i. Fordelen ligger ikke længere hos dem, der spørger “Hvilket minimum schema skal vi bruge for et rich result?”, men hos dem, der spørger “Hvilken struktureret repræsentation gør vores indhold entydigt for en maskine, selv uden for SERP?” Dette skift skubber organisationer mod mere komplette, sammenhængende og entitetscentrerede schema-mønstre. Efterhånden som AI-drevet søgning bliver en primær opdagelseskanal, udvikler schema-LLM-optimering sig fra en teknisk nysgerrighed til en kerne-Søgeoptimeringsdisciplin. Organisationer, der bevæger sig gennem modenhedsniveauerne—fra grundlæggende rich result schema til knowledge-graph-integrerede og LLM-optimerede mønstre—bygger holdbare moats i AI-drevet opdagelse, sikrer at deres brands bliver nævnt som autoriteter og deres indhold dukker op som pålidelige kilder.
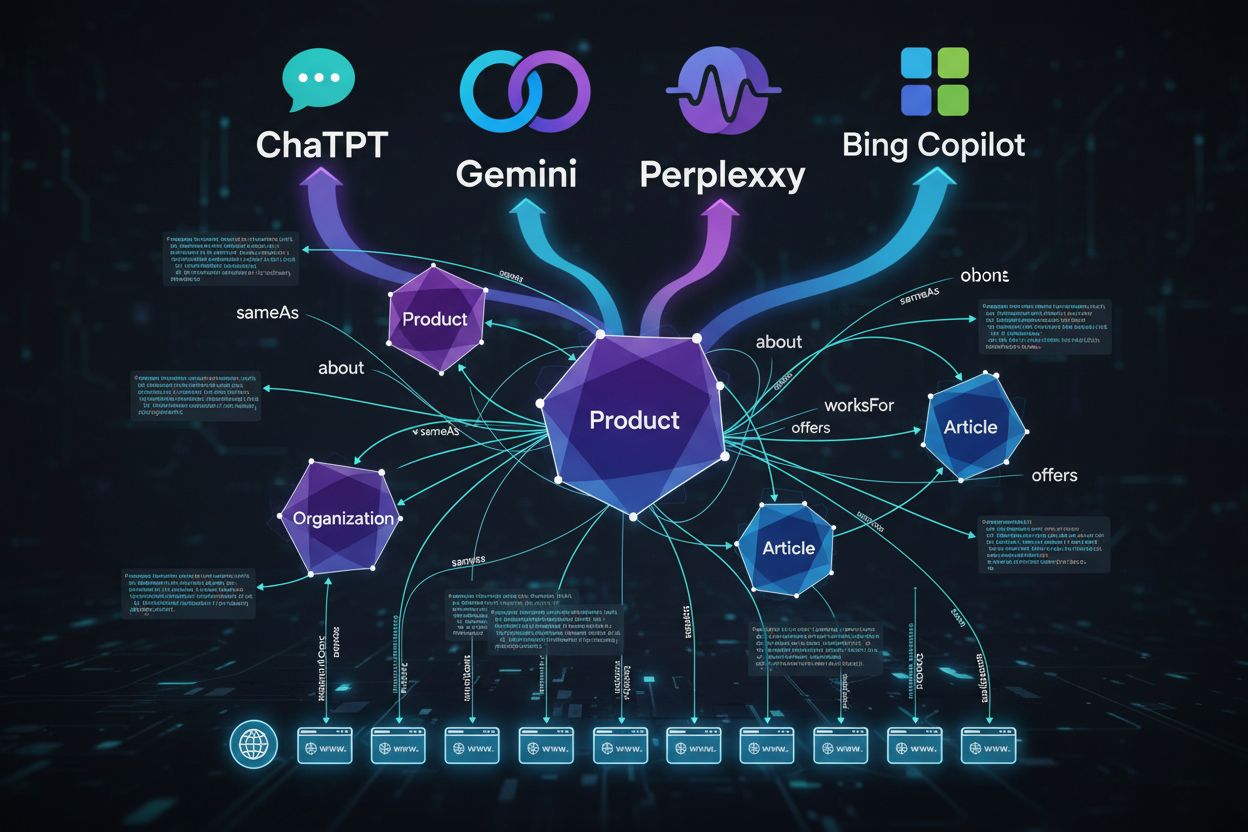
Traditionelt schema fokuserede på rich results (stjerner, snippets). For AI handler schema om entitetsklarhed, relationer og knowledge graphs. AI-systemer bruger schema til at forstå, hvad dit indhold handler om på et semantisk niveau, ikke kun for visuelle forbedringer.
Organization, Product, Article, Person og FAQPage er grundlæggende. For SaaS skal du tilføje SoftwareApplication og Service. For lokale/sundhed, tilføj LocalBusiness og MedicalOrganization. Vigtigheden varierer efter branche og brugerintention.
Nej. Start med Organization og dine mest værdifulde sider (produkter, services, vigtige artikler). Udvid gradvist dækningen baseret på din forretningsmodel og hvor AI-svar ville være mest værdifulde.
Schema-ændringer kan påvirke AI-citater inden for uger, men sammenhængen er probabilistisk. Planlæg kvartalsvise gennemgange og kontinuerlig overvågning på tværs af flere AI-platforme for at måle effekten.
sameAs forbinder din entitet til kanoniske profiler (Wikipedia, LinkedIn) for at undgå forveksling med navnesøstre. about/mentions præciserer, hvad din side reelt fokuserer på og hjælper modeller med at forstå nuancer og kontekst.
Nej. Schema fungerer bedst, når det er afstemt med indhold af høj kvalitet og god struktur på siden. Modeller har brug for både de strukturerede data og det narrative indhold for at citere dine sider med sikkerhed.
Overvåg AI-svar på tværs af platforme (ChatGPT, Gemini, Perplexity, Bing) for dine målrettede forespørgsler. Spor entitetsnævnelser, URL-citater, faktuel nøjagtighed og brandbeskrivelser. Se efter tendenser over uger/måneder.
JSON-LD er det anbefalede format til de fleste brugsscenarier. Det er nemmere at implementere, vedligeholde og forstyrrer ikke HTML. Microdata og RDFa er mindre almindelige i moderne implementeringer.
Følg, hvordan AI-systemer nævner dit brand på tværs af ChatGPT, Gemini, Perplexity og Google AI Overviews. Få indsigt i, hvilke schema-typer der driver synlighed.
Opdag hvilke typer schema markup der øger din synlighed i AI-søgemaskiner som ChatGPT, Perplexity og Gemini. Lær JSON-LD implementeringsstrategier for AI-svarge...
Lær hvordan rich results og strukturerede data påvirker AI-søgemaskiner, LLM'er og synligheden af indhold i AI-drevne svar fra ChatGPT, Perplexity og Google AI ...
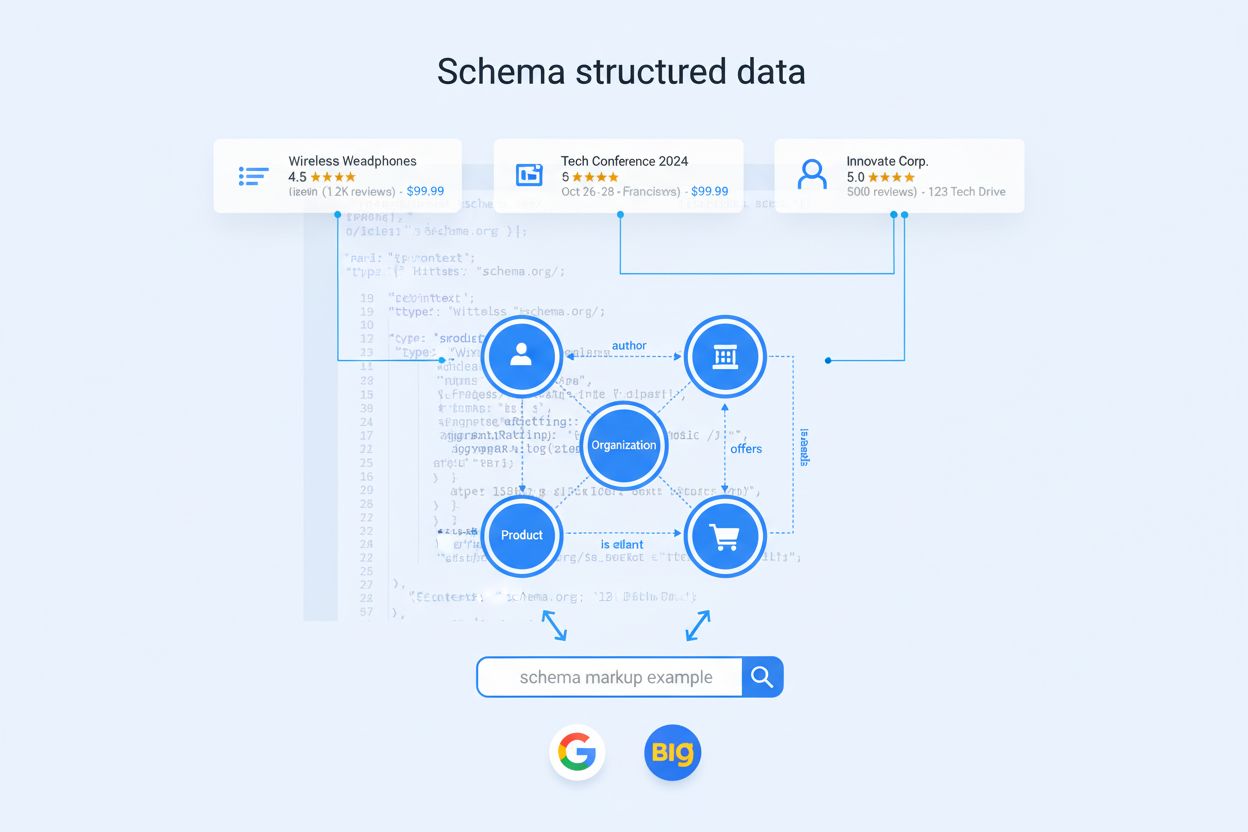
Schema markup er standardiseret kode, der hjælper søgemaskiner med at forstå indhold. Lær hvordan struktureret data forbedrer SEO, muliggør rige resultater og u...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.