
Token
Lær hvad tokens er i sprogmodeller. Tokens er fundamentale enheder i tekstbehandling i AI-systemer og repræsenterer ord, delord eller tegn som numeriske værdier...
10 min læsning

Udforsk hvordan tokenbegrænsninger påvirker AI-ydeevne og lær praktiske strategier for indholdsoptimering, herunder RAG, chunking og opsummeringsteknikker.
Tokens er de grundlæggende byggesten, som AI-modeller bruger til at behandle og forstå information. I stedet for at arbejde med hele ord eller sætninger nedbryder store sprogmodeller tekst til mindre enheder kaldet tokens, som kan være individuelle tegn, delord eller hele ord afhængigt af tokeniseringsalgoritmen. Hvert token tildeles en unik numerisk identifikator, som modellen bruger internt til beregning. Denne tokeniseringsproces er essentiel, fordi den gør det muligt for AI-systemer at håndtere input af varierende længde effektivt og opretholde ensartet behandling på tværs af forskellige typer indhold. At forstå tokens er afgørende for alle, der arbejder med AI-systemer, da de direkte påvirker ydeevne, omkostninger og kvaliteten af de resultater, du kan opnå.
Forskellige AI-modeller har meget forskellige tokenbegrænsninger, som definerer den maksimale mængde information, de kan behandle i én enkelt forespørgsel. Disse grænser har udviklet sig dramatisk over de seneste år, hvor nyere modeller understøtter markant større kontekstvinduer. Tokenbegrænsningen omfatter både input-tokens (din prompt og data) og output-tokens (modellens svar), hvilket skaber et delt budget, der skal forvaltes omhyggeligt. At forstå disse begrænsninger er afgørende for at vælge den rette model til dit brugsscenarie og planlægge din applikationsarkitektur derefter.
| Model | Tokenbegrænsning | Primært anvendelsesområde | Omkostningsniveau |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Korte samtaler, hurtige opgaver | Lavt |
| GPT-4 | 8.192 | Standardapplikationer, moderat kompleksitet | Mellem |
| GPT-4 Turbo | 128.000 | Lange dokumenter, kompleks analyse | Højt |
| Claude 3.5 Sonnet | 200.000 | Udvidede dokumenter, omfattende analyse | Højt |
| Gemini 1.5 Pro | 1.000.000 | Kæmpe datasæt, hele bøger, videoanalyse | Meget højt |
Vigtige overvejelser ved vurdering af tokenbegrænsninger:
Tokenbegrænsninger skaber betydelige begrænsninger, der direkte påvirker nøjagtigheden, pålideligheden og omkostningseffektiviteten af AI-applikationer. Når du overskrider en models tokenbegrænsning, fejler applikationen fuldstændigt—der er ingen glidende nedskalering eller delvis behandling. Selv når du holder dig inden for grænserne, kan naive tilgange som simpel trunkering alvorligt forringe ydeevnen ved at fjerne kritisk kontekst, som modellen behøver for at generere korrekte svar. Dette er særligt problematisk i domæner som juridisk analyse, medicinsk forskning og softwareudvikling, hvor selv et enkelt vigtigt detalje kan føre til forkerte konklusioner, hvis det mangler. Udfordringen bliver endnu større, når du tager højde for, at forskellige typer indhold bruger tokens i forskelligt tempo—strukturerede data som kode eller JSON kræver betydeligt flere tokens end almindelig engelsk tekst på grund af symboler og formatering.
Trunkering er den simpleste metode til håndtering af tokenbegrænsninger—du afskærer blot overskydende indhold, når det overstiger modellens kapacitet. Selvom det er let at implementere, indebærer denne metode betydelige risici. Når du trunkerer tekst, mister du uundgåeligt information, og modellen har ingen måde at vide, hvad der er fjernet. Dette kan føre til ufuldstændig analyse, manglende kontekst og hallucinationer, hvor modellen skaber plausible, men forkerte oplysninger for at udfylde hullerne i sin forståelse.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
En mere sofistikeret trunkeringsstrategi skelner mellem essentielle og valgfrie indholdselementer. Du kan prioritere nødvendige elementer som den aktuelle brugerforespørgsel og kerneinstruktioner og derefter tilføje valgfri kontekst som samtalehistorik, hvis der er plads. Denne tilgang bevarer kritisk information, samtidig med at tokenbegrænsninger respekteres.
I stedet for at trunkere deler chunking dit indhold op i mindre, håndterbare stykker, som kan behandles uafhængigt eller selektivt. Chunking med fast størrelse opdeler tekst i ensartede segmenter, mens semantisk chunking bruger embeddings til at finde naturlige opdelingspunkter baseret på betydning frem for vilkårlige tokenantal. Glidende vinduer med overlap bevarer kontekst mellem chunks og sikrer, at vigtig information på tværs af chunkgrænser ikke går tabt.
Hierarkisk chunking skaber flere abstraktionsniveauer—individuelle afsnit på det fineste niveau, sektioner på næste niveau og kapitler på det højeste niveau. Denne tilgang muliggør sofistikerede hentningsstrategier, hvor du hurtigt kan identificere relevante sektioner uden at behandle hele dokumentet. Når det kombineres med vektordatabaser og semantisk søgning, bliver chunking et kraftfuldt værktøj til at håndtere store vidensbaser og samtidig bevare relevans og nøjagtighed.
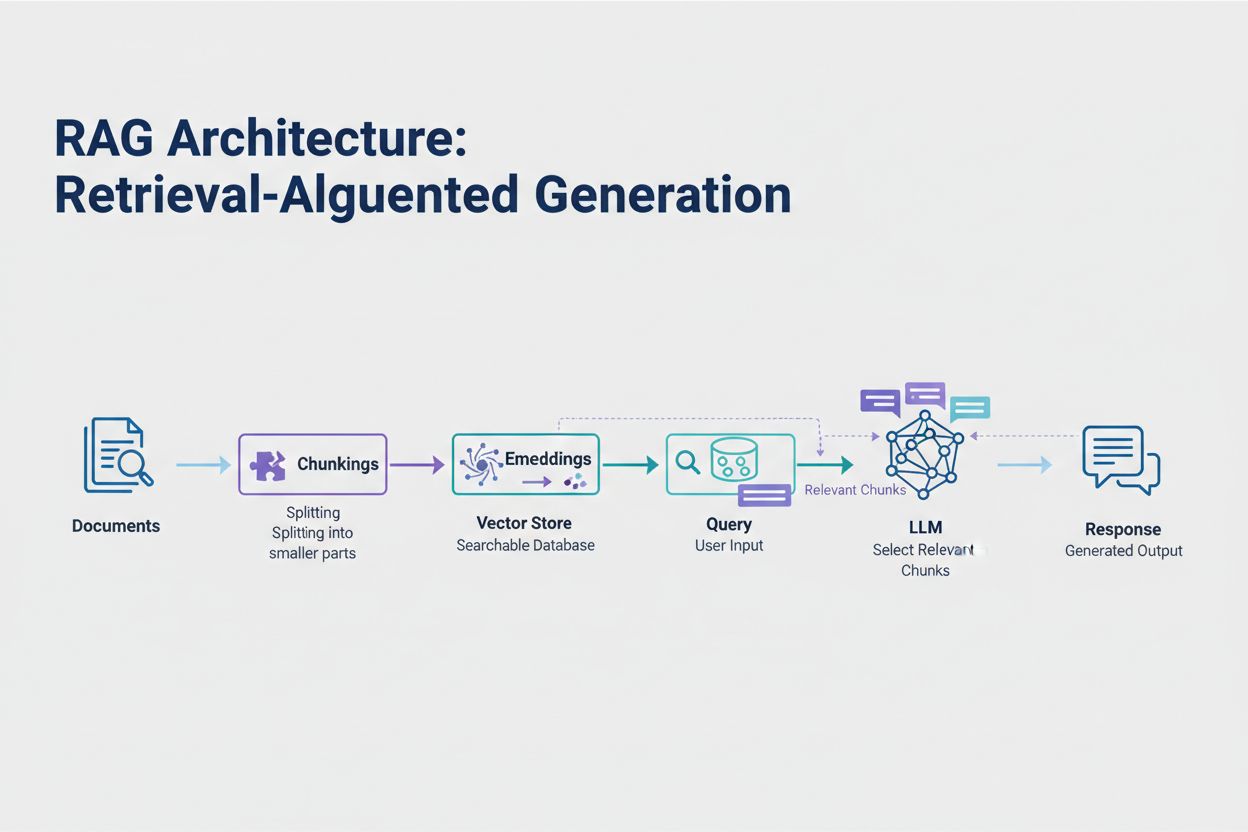
Retrieval-Augmented Generation (RAG) repræsenterer den mest effektive moderne tilgang til håndtering af tokenbegrænsninger. I stedet for at forsøge at få alle dine data ind i modellens kontekstvindue, henter RAG kun de mest relevante informationer på forespørgselstidspunktet. Processen begynder med at konvertere dine dokumenter til embeddings—numeriske repræsentationer, der fanger semantisk betydning. Disse embeddings lagres i en vektordatabase, hvilket muliggør hurtige lighedssøgninger.
Når en bruger sender en forespørgsel, embeddes forespørgslen, og de mest relevante dokumentchunks hentes fra vektorlageret. Kun disse relevante chunks indsættes i prompten sammen med brugerens spørgsmål, hvilket dramatisk reducerer tokenforbrug og forbedrer nøjagtigheden. For eksempel kan analyse af en 100-siders juridisk kontrakt med RAG kræve blot 3-5 nøgleklausuler i prompten sammenlignet med de tusindvis af tokens, det ville kræve at inkludere hele dokumentet.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Opsummering kondenserer langt indhold og bevarer essentiel information, hvilket effektivt reducerer tokenforbruget. Ekstraktiv opsummering udvælger nøglesætninger fra den oprindelige tekst, mens abstraktiv opsummering genererer ny, kortfattet tekst, der fanger hovedidéerne. Hierarkisk opsummering skaber flere niveauer af opsummeringer—først opsummeres individuelle sektioner, derefter kombineres disse opsummeringer til overblik på højere niveau. Denne tilgang fungerer særligt godt til strukturerede dokumenter som forskningsartikler eller tekniske rapporter.
Kontekstkomprimering tager en anden tilgang ved at fjerne gentagelser og fyld, men bevarer den oprindelige formulering. Vidensgrafmetoder udtrækker entiteter og relationer fra tekst og rekonstruerer konteksten med kun de mest relevante fakta. Disse teknikker kan opnå 40-60% tokenreduktion, mens den semantiske nøjagtighed bevares, hvilket gør dem værdifulde til omkostningsoptimering i produktionssystemer.
Tokenstyring påvirker direkte dine AI-applikationsomkostninger. Hvert token, der forbruges under inferens, medfører en udgift, og omkostningerne skalerer lineært med tokenforbruget. Overvågning af tokenforbrug er essentielt for at forstå din omkostningsstruktur og identificere muligheder for optimering. Mange AI-platforme tilbyder nu værktøjer til optælling af tokens og realtidsdashboard, der følger forbrugsmønstre og hjælper dig med at identificere, hvilke forespørgsler eller funktioner, der bruger flest tokens.
Effektiv overvågning afslører optimeringsmuligheder—måske overskrider visse typer forespørgsler konsekvent tokenbegrænsninger, eller specifikke funktioner bruger uforholdsmæssigt mange ressourcer. Ved at spore disse mønstre kan du træffe informerede beslutninger om, hvilken optimeringsstrategi der skal implementeres. Nogle applikationer drager fordel af at dirigere store forespørgsler til mere kapable (men dyrere) modeller, mens andre har mere ud af at implementere RAG eller opsummering. Nøglen er at måle faktisk ydeevne og omkostninger for at validere dine optimeringsvalg.
Valget af den rette tokenstyringsstrategi afhænger af dit konkrete brugsscenarie, ydelseskrav og omkostningsrammer. Applikationer, der kræver høj nøjagtighed med dokumenterede svar, får mest ud af RAG, der bevarer informationsintegritet, mens tokenforbruget styres. Løbende samtaleapplikationer drager fordel af memory-buffer-teknikker, der opsummerer samtalehistorikken, mens centrale beslutninger og kontekst bevares. Dokumenttunge applikationer som juridisk analyse eller forskning har ofte mest ud af hierarkisk opsummering kombineret med semantisk chunking.
Test og validering er afgørende, før du implementerer nogen tokenstyringsstrategi i produktion. Opret testcases, der overskrider din models tokenbegrænsninger, og vurder derefter, hvordan forskellige strategier påvirker nøjagtighed, latenstid og omkostninger. Mål parametre som svarrelevans, faktuel nøjagtighed og tokeneffektivitet for at sikre, at din valgte tilgang lever op til dine krav. Almindelige faldgruber inkluderer for aggressiv opsummering, der mister vigtige detaljer, hentningssystemer, der overser relevant information, og chunkingstrategier, der deler indhold på semantisk uhensigtsmæssige punkter.
Tokenbegrænsninger fortsætter med at udvides, efterhånden som modeller bliver mere avancerede og effektive. Nye teknikker som spars-attention mekanismer og effektive transformere lover at reducere de beregningsmæssige omkostninger ved behandling af store kontekstvinduer. Multimodale modeller, der håndterer tekst, billeder, lyd og video samtidig, introducerer nye tokeniseringsudfordringer og -muligheder. Reasoning-tokens—specielle tokens, der bruges af modeller til at “tænke sig igennem” komplekse problemer—repræsenterer en ny kategori af tokenforbrug, der muliggør mere avanceret problemløsning, men kræver omhyggelig styring.
Udviklingen er tydelig: Efterhånden som kontekstvinduer udvides og tokenbehandling bliver mere effektiv, flytter flaskehalsen sig fra rå kapacitet til intelligent indholdsudvælgelse. Fremtiden tilhører systemer, der effektivt kan identificere og hente den mest relevante information fra enorme vidensbaser, fremfor systemer, der blot behandler større datamængder. Dette gør teknikker som RAG og semantisk søgning stadigt vigtigere for at bygge skalerbare, omkostningseffektive AI-applikationer.
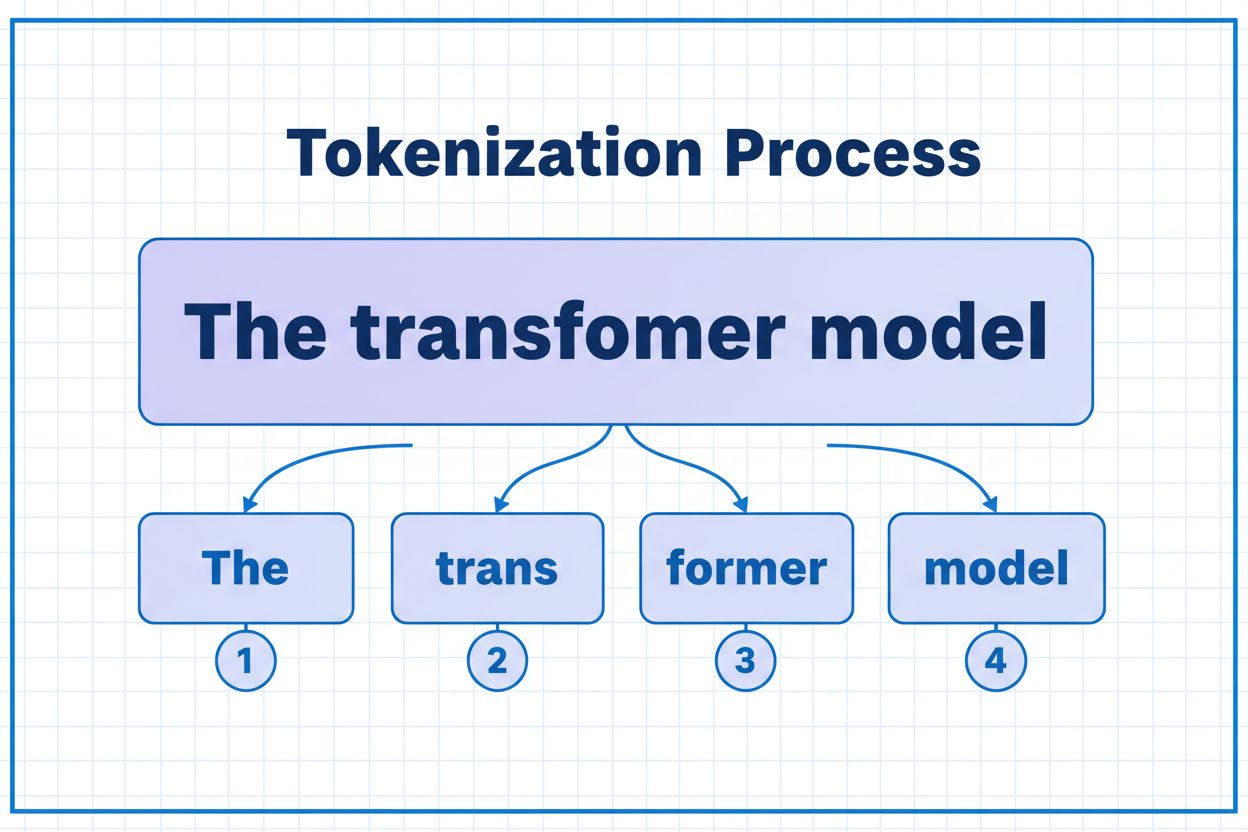
Et token er den mindste enhed af data, som en AI-model behandler. Tokens kan være individuelle tegn, delord eller hele ord afhængigt af tokeniseringsalgoritmen. For eksempel kan ordet 'transformer' opdeles i 'trans' og 'former' som to separate tokens. Hvert token tildeles en unik numerisk identifikator, som modellen bruger internt til beregning.
Tokenbegrænsninger definerer den maksimale mængde information, din AI-model kan behandle i én enkelt forespørgsel. Hvis du overskrider denne grænse, fejler din applikation fuldstændigt. Selv når du holder dig inden for grænserne, kan naive tilgange som trunkering forringe nøjagtigheden ved at fjerne kritisk kontekst. Tokenbegrænsninger påvirker også direkte omkostningerne, da du typisk betaler pr. forbrugt token.
Input-tokens er de tokens i din prompt og data, som du sender til modellen, mens output-tokens er de tokens, modellen genererer i sit svar. Disse deler et samlet budget, der er defineret af modellens kontekstvindue. Hvis dit input bruger 90% af et 128K tokenvindue, har du kun 10% tilbage til modellens output.
Trunkering er let at implementere, men risikabelt. Det fjerner information uden at modellen ved, hvad der gik tabt, hvilket fører til ufuldstændig analyse og potentielle hallucinationer. Selvom det kan bruges som sidste udvej, er bedre tilgange som RAG, chunking eller opsummering mere effektive, da de bevarer informationsintegritet, mens de styrer forbruget af tokens.
Retrieval-Augmented Generation (RAG) henter kun de mest relevante informationer på forespørgselstidspunktet i stedet for at inkludere hele dokumenter. Dine dokumenter konverteres til embeddings og gemmes i en vektordatabase. Når en bruger stiller en forespørgsel, henter systemet kun relevante stykker og indsætter dem i prompten, hvilket dramatisk reducerer tokenforbruget og forbedrer nøjagtigheden.
De fleste AI-platforme tilbyder værktøjer til tælning af tokens og realtids-dashboard til overvågning af forbrugsmønstre. Overvåg hvilke forespørgsler eller funktioner, der bruger flest tokens, og implementér derefter optimeringsstrategier såsom RAG til dokumenttunge applikationer, opsummering til lange samtaler eller routing til større modeller ved komplekse opgaver. Mål faktisk ydeevne og omkostninger for at validere dine valg.
AI-tjenester opkræver typisk betaling pr. forbrugt token. Omkostningerne skalerer lineært med tokenforbrug, så tokenoptimering har direkte betydning for dine udgifter. En reduktion på 20% i tokenforbrug betyder en omkostningsreduktion på 20%. Forståelse af tokeneffektivitet hjælper dig med at vælge den rette optimeringsstrategi inden for dit budget.
Tokenbegrænsninger fortsætter med at udvides, efterhånden som modellerne bliver mere avancerede. Nye teknikker som spars-attention mekanismer lover at reducere de beregningsmæssige omkostninger ved behandling af store kontekster. Fremtiden fokuserer på intelligent indholdsudvælgelse og -hentning frem for rå behandlingskapacitet, hvilket gør teknikker som RAG stadigt vigtigere for skalerbare AI-applikationer.
Forstå tokeneffektivitet og følg med i, hvordan AI-modeller citerer dit brand med AmICiteds omfattende AI-citationsovervågningsplatform.
Lær hvad tokens er i sprogmodeller. Tokens er fundamentale enheder i tekstbehandling i AI-systemer og repræsenterer ord, delord eller tegn som numeriske værdier...

Lær hvordan AI-modeller behandler tekst gennem tokenisering, embeddings, transformerblokke og neurale netværk. Forstå den komplette pipeline fra input til outpu...

Udforsk hvordan AI-systemer genkender og bearbejder enheder i tekst. Lær om NER-modeller, transformer-arkitekturer og virkelige anvendelser af enhedsforståelse....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.