
Findes der et AI-søgeindeks? Sådan indekserer AI-motorer indhold
Lær hvordan AI-søgeindekser fungerer, forskellene mellem ChatGPT, Perplexity og SearchGPT's indekseringsmetoder, og hvordan du optimerer dit indhold for AI-søge...
7 min læsning

Lær hvordan AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews fungerer. Opdag LLM’er, RAG, semantisk søgning og realtids-hentemekanismer.
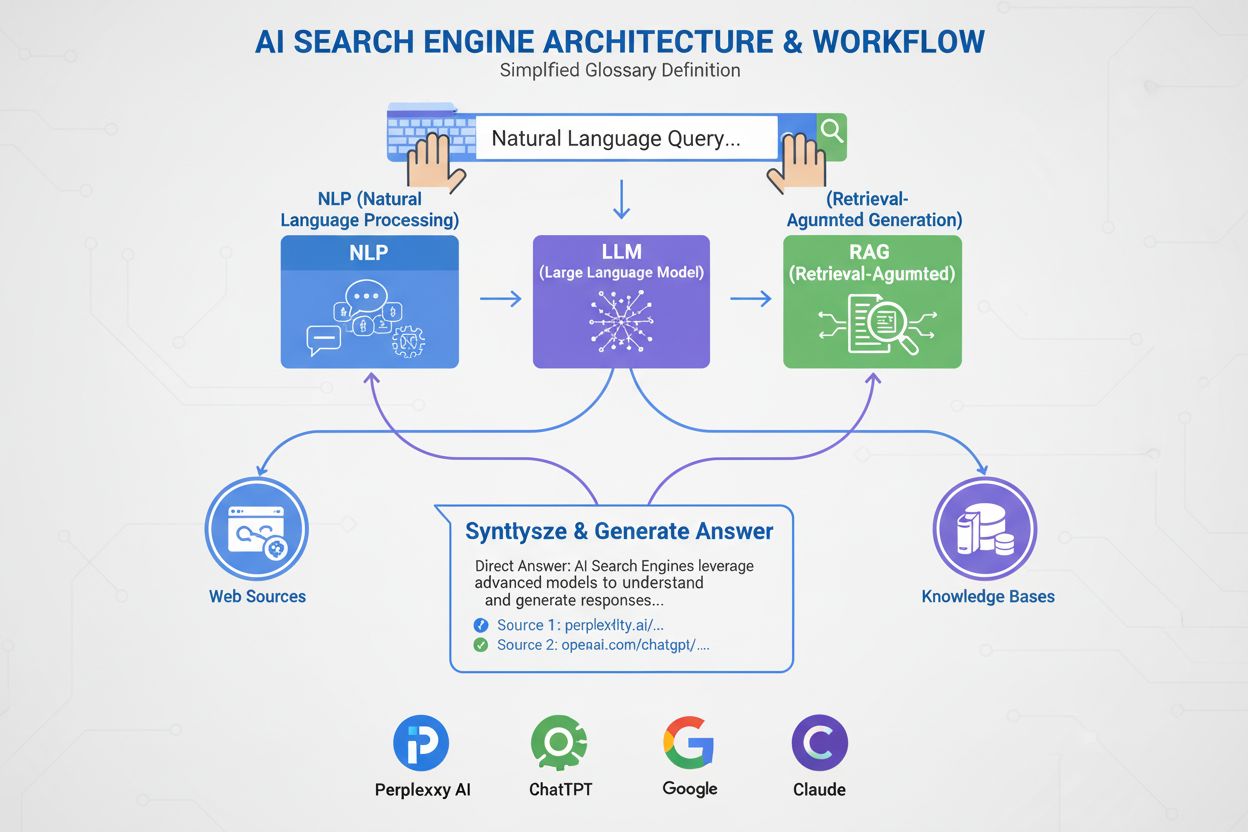
AI-søgemaskiner bruger store sprogmodeller (LLM'er) kombineret med retrieval-augmented generation (RAG) til at forstå brugerens hensigt og hente relevant information fra internettet i realtid. De behandler forespørgsler gennem semantisk forståelse, vektorembedninger og vidensgrafer for at levere samtalebaserede svar med kildehenvisninger, i modsætning til traditionelle søgemaskiner, der returnerer rangerede lister af hjemmesider.
AI-søgemaskiner repræsenterer et grundlæggende skift fra traditionel søgning baseret på nøgleord til samtalebaseret, hensigtsdrevet informationshentning. I modsætning til Googles traditionelle søgemaskine, der crawler, indekserer og rangerer hjemmesider for at returnere en liste af links, genererer AI-søgemaskiner som ChatGPT, Perplexity, Google AI Overviews og Claude originale svar ved at kombinere flere teknologier. Disse platforme forstår, hvad brugerne faktisk leder efter, henter relevant information fra autoritative kilder og syntetiserer denne information til sammenhængende svar med kildehenvisninger. Teknologien bag disse systemer er ved at forvandle den måde, folk finder information online på, hvor ChatGPT behandler 2 milliarder forespørgsler dagligt og AI Overviews vises i 18% af globale Google-søgninger. At forstå hvordan disse systemer fungerer er afgørende for indholdsskabere, marketingfolk og virksomheder, der ønsker synlighed i dette nye søgelandskab.
AI-søgemaskiner fungerer gennem tre indbyrdes forbundne systemer, der arbejder sammen for at levere nøjagtige svar med kilder. Den første komponent er Large Language Model (LLM), som trænes på enorme mængder tekstdata for at forstå sprogmønstre, struktur og nuancer. Modeller som OpenAI’s GPT-4, Google’s Gemini og Anthropics Claude trænes ved hjælp af usuperviseret læring på milliarder af dokumenter, hvilket gør dem i stand til at forudsige, hvilke ord der bør følge, baseret på statistiske mønstre lært under træningen. Den anden komponent er embed-modellen, som konverterer ord og sætninger til numeriske repræsentationer kaldet vektorer. Disse vektorer indfanger semantisk betydning og relationer mellem begreber, så systemet kan forstå, at “gaming laptop” og “højtydende computer” er semantisk beslægtede, selvom de ikke deler nøjagtige nøgleord. Den tredje kritiske komponent er Retrieval-Augmented Generation (RAG), som supplerer LLM’ens træningsdata ved at hente aktuel information fra eksterne vidensbaser i realtid. Dette er essentielt, fordi LLM’er har en træningsdatogrænse og ikke kan få adgang til live-information uden RAG. Samlet gør disse tre komponenter det muligt for AI-søgemaskiner at levere aktuelle, nøjagtige og kildehenviste svar frem for hallucinerede eller forældede oplysninger.
Retrieval-Augmented Generation er den proces, der gør det muligt for AI-søgemaskiner at forankre deres svar i autoritative kilder i stedet for kun at stole på træningsdata. Når du sender en forespørgsel til en AI-søgemaskine, konverterer systemet først dit spørgsmål til en vektorrepræsentation ved hjælp af embed-modellen. Denne vektor sammenlignes derefter med en database af indekseret webindhold, som også er konverteret til vektorer, ved hjælp af teknikker som cosinus-lighed for at identificere de mest relevante dokumenter. RAG-systemet henter disse dokumenter og sender dem til LLM’en sammen med din originale forespørgsel. LLM’en bruger derefter både de hentede oplysninger og sine træningsdata til at generere et svar, der direkte refererer til de kilder, den har konsulteret. Denne tilgang løser flere kritiske problemer: den sikrer, at svarene er aktuelle og faktuelle, den giver brugerne mulighed for at verificere oplysninger ved at tjekke kildehenvisninger, og den giver indholdsskabere mulighed for at blive citeret i AI-genererede svar. Azure AI Search og AWS Bedrock er virksomhedsløsninger med RAG, der viser, hvordan organisationer kan opbygge tilpassede AI-søgesystemer. Kvaliteten af RAG afhænger i høj grad af, hvor godt hentningssystemet identificerer relevante dokumenter, hvilket er grunden til at semantisk rangering og hybrid søgning (kombineret nøgleords- og vektorsøgning) er blevet vigtige teknikker til at forbedre nøjagtigheden.
Semantisk søgning er teknologien, der gør det muligt for AI-søgemaskiner at forstå betydning frem for blot at matche nøgleord. Traditionelle søgemaskiner leder efter nøjagtige nøgleord, men semantisk søgning analyserer hensigten og den kontekstuelle betydning bag en forespørgsel. Når du søger efter “billige smartphones med gode kameraer,” forstår en semantisk søgemaskine, at du ønsker budgettelefoner med fremragende kamerafunktioner, selvom resultaterne ikke indeholder de præcise ord. Dette opnås gennem vektorembedninger, som repræsenterer tekst som højdimensionelle numeriske arrays. Avancerede modeller som BERT (Bidirectional Encoder Representations from Transformers) og OpenAI’s text-embedding-3-small konverterer ord, sætninger og hele dokumenter til vektorer, hvor semantisk beslægtet indhold placeres tæt på hinanden i vektorrummet. Systemet beregner derefter vektorlignhed ved hjælp af matematiske teknikker som cosinus-lighed for at finde de dokumenter, der bedst matcher forespørgslens hensigt. Denne tilgang er langt mere effektiv end nøgleords-match, fordi den indfanger relationer mellem begreber. For eksempel forstår systemet, at “gaming laptop” og “højtydende computer med GPU” er beslægtede, selvom de ikke deler nogen fælles nøgleord. Vidensgrafer tilføjer et ekstra lag ved at skabe strukturerede netværk af semantiske relationer og forbinder begreber som “laptop” til “processor,” “RAM” og “GPU” for at forbedre forståelsen. Denne flerlags-tilgang til semantisk forståelse er grunden til, at AI-søgemaskiner kan levere relevante resultater på komplekse, samtalebaserede forespørgsler, som traditionelle søgemaskiner har svært ved.
| Søgeteknologi | Sådan fungerer det | Styrker | Begrænsninger |
|---|---|---|---|
| Nøgleordssøgning | Matcher præcise ord eller sætninger i forespørgslen med indekseret indhold | Hurtig, simpel, forudsigelig | Virker ikke med synonymer, tastefejl og kompleks hensigt |
| Semantisk søgning | Forstår betydning og hensigt ved hjælp af NLP og embed-modeller | Håndterer synonymer, kontekst og komplekse forespørgsler | Kræver flere computerressourcer |
| Vektorsøgning | Konverterer tekst til numeriske vektorer og beregner lighed | Præcis ligheds-matchning, skalerbar | Fokuserer på matematisk afstand, ikke kontekst |
| Hybrid søgning | Kombinerer nøgleords- og vektorsøgningsmetoder | Det bedste fra begge verdener ift. nøjagtighed og recall | Mere kompleks at implementere og optimere |
| Vidensgraf-søgning | Bruger strukturerede relationer mellem begreber | Tilføjer ræsonnement og kontekst til resultater | Kræver manuel vedligeholdelse og kuratering |
En af de største fordele ved AI-søgemaskiner frem for traditionelle LLM’er er deres evne til at få adgang til realtidsinformation fra internettet. Når du spørger ChatGPT om aktuelle begivenheder, bruger den en bot kaldet ChatGPT-User til at crawle hjemmesider i realtid og hente opdateret information. Perplexity søger ligeledes internettet i realtid for at indsamle indsigter fra førsteklasses kilder, hvilket gør, at den kan svare på spørgsmål om begivenheder, der fandt sted efter dens træningsdatogrænse. Google AI Overviews udnytter Googles eksisterende webindeks og crawling-infrastruktur til at hente aktuelle oplysninger. Denne realtids-henteevne er essentiel for at opretholde nøjagtighed og relevans. Henteprocessen indebærer flere trin: Først opdeler systemet din forespørgsel i flere relaterede underforespørgsler gennem en proces kaldet query fan-out, hvilket hjælper med at hente mere omfattende information. Derefter søger systemet i indekseret webindhold ved hjælp af både nøgleords- og semantisk match for at identificere relevante sider. De hentede dokumenter rangeres efter relevans ved hjælp af semantiske rangeringsalgoritmer, der omrangerer resultater baseret på betydning frem for blot nøgleordsfrekvens. Til sidst udtrækker systemet de mest relevante passager fra disse dokumenter og sender dem til LLM’en for at generere et svar. Hele denne proces sker på få sekunder, hvilket er grunden til, at brugere forventer AI-svar inden for 3-5 sekunder. Hastigheden og nøjagtigheden i denne hentningsproces har direkte indflydelse på kvaliteten af det endelige svar, hvilket gør effektiv informationshentning til en kritisk komponent i AI-søgemaskinens arkitektur.
Når RAG-systemet har hentet relevant information, bruger Large Language Model disse oplysninger til at generere et svar. LLM’er “forstår” ikke sprog på menneskelig vis; i stedet bruger de statistiske modeller til at forudsige, hvilke ord der skal følge, baseret på mønstre lært under træningen. Når du indtaster en forespørgsel, konverterer LLM’en den til en vektorrepræsentation og behandler den gennem et neuralt netværk med millioner af sammenkoblede noder. Disse noder har lært forbindelsesstyrker kaldet weights under træningen, som bestemmer, hvor meget indflydelse hver forbindelse har på de andre. LLM’en returnerer ikke én forudsigelse for det næste ord; den returnerer en rangeret liste af sandsynligheder. For eksempel kan den forudsige 4,5% sandsynlighed for at det næste ord burde være “lære” og 3,5% for “forudsige”. Systemet vælger ikke altid det ord med højest sandsynlighed; nogle gange vælges lavere rangerede ord for at få svarene til at lyde mere naturlige og kreative. Denne tilfældighed styres af temperatur-parameteren, som går fra 0 (deterministisk) til 1 (meget kreativ). Efter at have genereret det første ord, gentager systemet denne proces for det næste ord, og det næste, indtil et komplet svar er genereret. Denne token-for-token-generering er årsagen til, at AI-svar undertiden føles samtalebaserede og naturlige—modellen forudsiger i bund og grund den mest sandsynlige fortsættelse af en samtale. Kvaliteten af det genererede svar afhænger både af kvaliteten af de hentede oplysninger og af LLM’ens træningsniveau.
Forskellige AI-søgeplatforme implementerer disse kerne teknologier med forskellige tilgange og optimeringer. ChatGPT, udviklet af OpenAI, har fanget 81% af AI-chatbotmarkedsandelen og behandler 2 milliarder forespørgsler dagligt. ChatGPT bruger OpenAI’s GPT-modeller kombineret med realtids webadgang via ChatGPT-User til at hente aktuelle oplysninger. Den er særlig stærk til at håndtere komplekse, flertrinsforespørgsler og opretholde samtalekontekst. Perplexity adskiller sig gennem gennemsigtige kildehenvisninger, hvor brugerne kan se præcis hvilke hjemmesider, der har informeret hver del af svaret. Perplexitys mest citerede kilder omfatter Reddit (6,6%), YouTube (2%) og Gartner (1%), hvilket afspejler fokus på at finde autoritative, alsidige kilder. Google AI Overviews er integreret direkte i Googles søgeresultater og vises øverst på siden for mange forespørgsler. Disse overviews vises i 18% af globale Google-søgninger og drives af Googles Gemini-model. Google AI Overviews er særligt effektive til informationssøgende forespørgsler, hvor 88% af forespørgslerne, der udløser dem, er informationsbaserede. Googles AI Mode, en separat søgeoplevelse lanceret i maj 2024, omstrukturerer hele søgeresultatsiden omkring AI-genererede svar og har nået 100 millioner månedlige aktive brugere i USA og Indien. Claude, udviklet af Anthropic, lægger vægt på sikkerhed og nøjagtighed, og brugerne rapporterer høj tilfredshed med dens evne til at levere nuancerede, velbegrundede svar. Hver platform vælger forskellige kompromiser mellem hastighed, nøjagtighed, kildegennemsigtighed og brugeroplevelse, men alle bygger på den grundlæggende arkitektur med LLM’er, embed-modeller og RAG.
Når du sender en forespørgsel til en AI-søgemaskine, gennemgår den en sofistikeret, flertrins behandlingspipeline. Den første fase er forespørgselsanalyse, hvor systemet opdeler dit spørgsmål i grundlæggende komponenter såsom nøgleord, entiteter og sætninger. Naturlig sprogbehandlingsteknikker som tokenisering, ordklasse-tagging og entitetsgenkendelse identificerer, hvad du spørger om. For eksempel identificerer systemet i forespørgslen “bedste laptops til gaming” “laptops” som hovedentiteten og “gaming” som hensigt, hvorefter det slutter, at du har brug for høj hukommelse, processorkraft og GPU-kapaciteter. Anden fase er forespørgselsudvidelse og fan-out, hvor systemet genererer flere relaterede forespørgsler for at hente mere omfattende information. I stedet for kun at søge efter “bedste gaming laptops,” kan systemet også søge efter “gaming laptop specifikationer,” “højtydende laptops” og “laptop GPU krav.” Disse parallelle søgninger sker samtidigt og forbedrer markant informationsmængden. Tredje fase er hentning og rangering, hvor systemet søger i indekseret indhold ved hjælp af både nøgleords- og semantisk match og rangerer resultaterne efter relevans. Fjerde fase er passageudtrækning, hvor systemet identificerer de mest relevante passager fra de hentede dokumenter i stedet for at sende hele dokumenterne til LLM’en. Dette er afgørende, fordi LLM’er har token-grænser—GPT-4 accepterer omkring 128.000 tokens, men du kan have 10.000 sider dokumentation. Ved kun at udtrække de mest relevante passager maksimerer systemet informationskvaliteten, der sendes til LLM’en, samtidig med at man overholder token-begrænsninger. Den sidste fase er svargenerering og kildehenvisning, hvor LLM’en genererer et svar og inkluderer henvisninger til de anvendte kilder. Hele denne pipeline skal være gennemført på få sekunder for at opfylde brugerens forventninger til svartid.
Den grundlæggende forskel mellem AI-søgemaskiner og traditionelle søgemaskiner som Google ligger i deres overordnede mål og metoder. Traditionelle søgemaskiner er designet til at hjælpe brugere med at finde eksisterende information ved at crawle internettet, indeksere sider og rangere dem baseret på relevanssignaler som links, nøgleord og brugerengagement. Googles proces indebærer tre hovedtrin: crawling (opdage sider), indeksering (analysere og lagre sideinformation) og rangering (bestemme hvilke sider, der er mest relevante for en forespørgsel). Målet er at returnere en liste over hjemmesider, ikke at generere nyt indhold. AI-søgemaskiner derimod er designet til at generere originale, syntetiserede svar baseret på mønstre lært fra træningsdata og aktuelle oplysninger hentet fra internettet. Traditionelle søgemaskiner bruger AI-algoritmer som RankBrain og BERT til at forbedre rangering, men de forsøger ikke at skabe nyt indhold. AI-søgemaskiner genererer grundlæggende ny tekst ved at forudsige ordsekvenser. Denne forskel har store konsekvenser for synlighed. Med traditionel søgning skal du rangere i top 10 for at få klik. Med AI-søgning er 40% af kilderne, der citeres i AI Overviews, placeret lavere end top 10 i traditionel Google-søgning, og kun 14% af URL’er citeret af Googles AI Mode ligger i Googles traditionelle top 10 for de samme forespørgsler. Det betyder, at dit indhold kan blive nævnt i AI-svar, selvom det ikke rangerer højt i traditionel søgning. Derudover har branded web mentions en 0,664 korrelation med forekomster i Google AI Overviews, hvilket er langt højere end backlinks (0,218), hvilket antyder, at synlighed og omdømme betyder mere i AI-søgning end traditionelle SEO-målinger.
AI-søgelandskabet udvikler sig hurtigt med betydelige konsekvenser for, hvordan folk finder information, og hvordan virksomheder bevarer synlighed. AI-søgetrafik forventes at overhale traditionelle søgebesøg inden 2028, og nuværende data viser, at AI-platforme genererede 1,13 milliarder henvisningsbesøg i juni 2025, hvilket svarer til en stigning på 357% fra juni 2024. Vigtigst er det, at AI-søgetrafik konverterer med 14,2% sammenlignet med Googles 2,8%, hvilket gør denne trafik langt mere værdifuld, selvom den aktuelt kun udgør 1% af den globale trafik. Markedet samler sig omkring få dominerende platforme: ChatGPT har 81% af AI-chatbotmarkedet, Googles Gemini har 400 millioner månedlige aktive brugere, og Perplexity har over 22 millioner aktive månedlige brugere. Nye funktioner udvider AI-søgefunktionaliteten—ChatGPT’s Agent Mode gør det muligt for brugere at uddelegere komplekse opgaver som at booke fly direkte i platformen, mens Instant Checkout muliggør produktkøb direkte fra chatten. ChatGPT Atlas, lanceret i oktober 2025, bringer ChatGPT ud på internettet for øjeblikkelige svar og forslag. Disse udviklinger tyder på, at AI-søgning ikke blot bliver et alternativ til traditionel søgning, men en samlet platform for informationssøgning, beslutningstagning og handel. For indholdsskabere og marketingfolk kræver dette skifte en grundlæggende ændring i strategi. I stedet for at optimere til nøgleordsrangeringer kræver succes i AI-søgning, at man etablerer relevante mønstre i træningsmaterialer, opbygger brandauthoritet gennem omtaler og kildehenvisninger samt sikrer, at indholdet er friskt, dækkende og velstruktureret. Værktøjer som AmICited gør det muligt for virksomheder at overvåge, hvor deres indhold vises på AI-platforme, tracke citatmønstre og måle AI-synlighed—nødvendige egenskaber for at navigere i dette nye landskab.
Følg med i, hvor dit indhold vises i ChatGPT, Perplexity, Google AI Overviews og Claude. Få realtidsadvarsler, når dit domæne bliver nævnt i AI-genererede svar.
Lær hvordan AI-søgeindekser fungerer, forskellene mellem ChatGPT, Perplexity og SearchGPT's indekseringsmetoder, og hvordan du optimerer dit indhold for AI-søge...
Lær hvad AI-søgemaskiner er, hvordan de adskiller sig fra traditionelle søgninger, og hvilken indflydelse de har på brandets synlighed. Udforsk platforme som Pe...
Lær de essentielle første skridt til at optimere dit indhold til AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews. Opdag hvordan du strukturerer i...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.