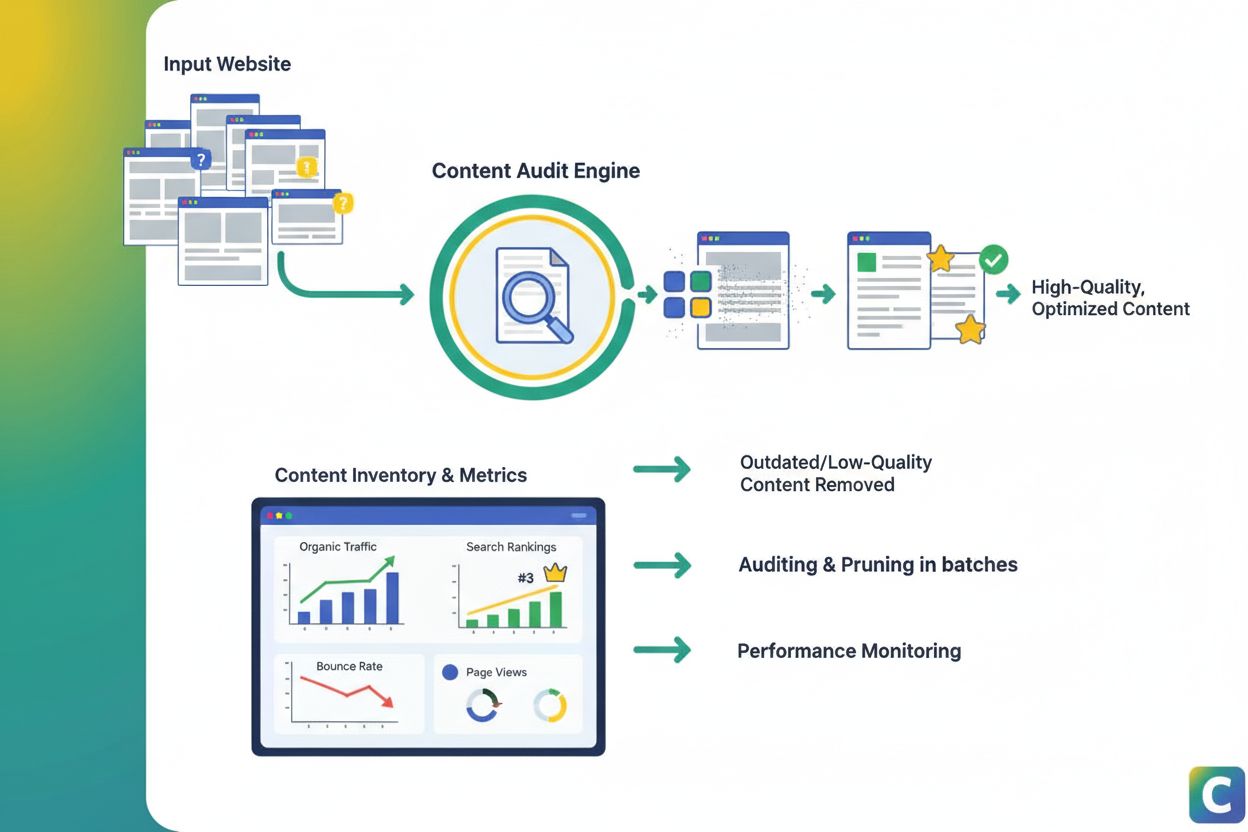
Indholdsbeskæring
Indholdsbeskæring er den strategiske fjernelse eller opdatering af underpræsterende indhold for at forbedre SEO, brugeroplevelse og søgesynlighed. Lær hvordan d...
14 min læsning

Lær hvad content pruning for AI er, hvordan det fungerer, forskellige pruning-metoder, og hvorfor det er essentielt for at implementere effektive AI-modeller på edge-enheder og i ressourcebegrænsede miljøer.
Content pruning for AI er en teknik, der selektivt fjerner overflødige eller mindre vigtige parametre, vægte eller tokens fra AI-modeller for at reducere deres størrelse, forbedre inferenshastighed og sænke hukommelsesforbruget, mens ydelseskvaliteten bevares.
Content pruning for AI er en grundlæggende optimeringsteknik, der bruges til at reducere den beregningsmæssige kompleksitet og hukommelsesforbruget for kunstige intelligensmodeller uden væsentligt at gå på kompromis med deres ydeevne. Denne proces indebærer systematisk at identificere og fjerne overflødige eller mindre vigtige komponenter fra neurale netværk, herunder individuelle vægte, hele neuroner, filtre eller endda tokens i sprogmodeller. Hovedmålet er at skabe slankere, hurtigere og mere effektive modeller, der kan implementeres effektivt på enheder med begrænsede ressourcer som smartphones, edge computing-systemer og IoT-enheder.
Konceptet pruning er inspireret af biologiske systemer, specifikt synaptisk pruning i den menneskelige hjerne, hvor unødvendige neurale forbindelser elimineres under udviklingen. Tilsvarende anerkender AI-pruning, at trænede neurale netværk ofte indeholder mange parametre, der kun bidrager minimalt til det endelige output. Ved at fjerne disse overflødige komponenter kan udviklere opnå betydelige reduktioner i modellens størrelse, mens nøjagtigheden bevares eller endda forbedres gennem omhyggelige finjusteringsprocesser.
Content pruning bygger på princippet om, at ikke alle parametre i et neuralt netværk er lige vigtige for at lave forudsigelser. Under træningsprocessen udvikler neurale netværk komplekse sammenkoblinger, hvoraf mange bliver overflødige eller bidrager minimalt til modellens beslutningsproces. Pruning identificerer disse mindre kritiske komponenter og fjerner dem, hvilket resulterer i en mere sparsom netværksarkitektur, der kræver færre beregningsressourcer for at fungere.
Effektiviteten af pruning afhænger af flere faktorer, herunder den anvendte pruning-metode, graden af aggressivitet i strategien og den efterfølgende finjusteringsproces. Forskellige pruning-tilgange retter sig mod forskellige aspekter af neurale netværk. Nogle metoder fokuserer på individuelle vægte (ustruktureret pruning), mens andre fjerner hele neuroner, filtre eller kanaler (struktureret pruning). Valget af metode har stor betydning for både den resulterende model-effektivitet og kompatibiliteten med moderne hardware-acceleratorer.
| Pruning-type | Mål | Fordele | Udfordringer |
|---|---|---|---|
| Vægt-pruning | Individuelle forbindelser/vægte | Maksimal komprimering, sparsomme netværk | Giver måske ikke hurtigere hardwareudførelse |
| Struktureret pruning | Neuroner, filtre, kanaler | Hardware-venlig, hurtigere inferens | Mindre komprimering end ustruktureret |
| Dynamisk pruning | Kontekstafhængige parametre | Adaptiv effektivitet, realtidsjustering | Kompleks implementering, højere overhead |
| Lag-pruning | Hele lag eller blokke | Betydelig størrelsesreduktion | Risiko for nøjagtighedstab, kræver grundig validering |
Ustruktureret pruning, også kendt som vægtpruning, fungerer på et granulært niveau ved at fjerne individuelle vægte fra netværkets vægtmatricer. Denne tilgang bruger typisk størrelsesbaserede kriterier, hvor vægte tæt på nul anses for mindre vigtige og elimineres. Det resulterende netværk bliver sparsomt, hvilket betyder, at kun en brøkdel af de oprindelige forbindelser forbliver aktive under inferens. Selvom ustruktureret pruning kan opnå imponerende komprimeringsrater—nogle gange reduceres antallet af parametre med 90 % eller mere—betyder det ikke nødvendigvis, at de sparsomme netværk kører tilsvarende hurtigere på standardhardware uden specialiseret understøttelse af sparsomme beregninger.
Struktureret pruning tager en anden tilgang ved at fjerne hele grupper af parametre på én gang, såsom komplette filtre i konvolutionslag, hele neuroner i fuldt forbundne lag eller hele kanaler. Denne metode er særligt værdifuld til praktisk implementering, da de resulterende modeller naturligt er kompatible med moderne hardware-acceleratorer som GPU’er og TPU’er. Når hele filtre fjernes fra konvolutionslag, realiseres de beregningsmæssige besparelser straks uden behov for specialiserede sparsomme matrixoperationer. Forskning har vist, at struktureret pruning kan reducere modellens størrelse med 50-90 % og samtidig bevare en nøjagtighed, der kan sammenlignes med de oprindelige modeller.
Dynamisk pruning repræsenterer en mere avanceret tilgang, hvor pruning-processen tilpasser sig under modellens inferens baseret på det specifikke input, der behandles. Denne teknik udnytter ekstern kontekst som fx taleridentitet, begivenhedssignaler eller sprog-specifik information til dynamisk at justere, hvilke parametre der er aktive. I systemer til retrieval-augmented generation kan dynamisk pruning reducere kontekststørrelsen med cirka 80 %, mens svarkvaliteten forbedres ved at filtrere irrelevante informationer fra. Denne adaptive tilgang er særligt værdifuld for multimodale AI-systemer, der skal behandle forskellige inputtyper effektivt.
Iterativ pruning og finjustering repræsenterer en af de mest udbredte tilgange i praksis. Denne metode indebærer en cyklisk proces: prune en del af netværket, finjustér de resterende parametre for at genskabe tabt nøjagtighed, evaluer ydeevne og gentag. Det iterative i denne tilgang gør det muligt for udviklere omhyggeligt at balancere modelkomprimering med vedligeholdelse af ydeevne. I stedet for at fjerne alle unødvendige parametre på én gang—hvilket kunne skade modellens ydeevne katastrofalt—reducerer iterativ pruning gradvist netværkets kompleksitet, mens modellen får mulighed for at tilpasse sig og lære, hvilke resterende parametre der er mest kritiske.
One-shot pruning tilbyder et hurtigere alternativ, hvor hele pruning-processen sker i ét trin efter træning, efterfulgt af en finjusteringsfase. Selvom denne tilgang er mere beregningseffektiv end iterative metoder, indebærer den en større risiko for nøjagtighedstab, hvis for mange parametre fjernes på én gang. One-shot pruning er især nyttigt, når der er begrænsede ressourcer til iterative processer, men det kræver typisk mere omfattende finjustering for at genvinde ydeevne.
Pruning baseret på følsomhedsanalyse anvender en mere avanceret rangeringsmekanisme ved at måle, hvor meget modellens tabsfunktion stiger, når bestemte vægte eller neuroner fjernes. Parametre, der har minimal indflydelse på tabsfunktionen, identificeres som sikre kandidater til pruning. Denne datadrevne tilgang giver mere nuancerede pruning-beslutninger sammenlignet med simple størrelsesbaserede metoder og resulterer ofte i bedre nøjagtighedsbevarelse ved tilsvarende komprimeringsniveauer.
Lottery Ticket Hypotesen præsenterer en interessant teoretisk ramme, der foreslår, at der inden for store neurale netværk findes et mindre, sparsomt subnetværk—“vinderbilletten”—som kan opnå en nøjagtighed, der kan sammenlignes med det oprindelige netværk, når det trænes fra samme initiering. Denne hypotese har stor betydning for forståelsen af netværksoverflod og har inspireret nye pruning-metoder, der forsøger at identificere og isolere disse effektive subnetværk.
Content pruning er blevet uundværligt i mange AI-applikationer, hvor beregningseffektivitet er afgørende. Implementering på mobile og indlejrede enheder er et af de mest markante anvendelsesområder, hvor prunede modeller muliggør avancerede AI-funktioner på smartphones og IoT-enheder med begrænset processorkraft og batterikapacitet. Billedgenkendelse, stemmeassistenter og realtidsoversættelse drager alle fordel af prunede modeller, der bevarer nøjagtigheden, mens ressourceforbruget minimeres.
Autonome systemer, herunder selvkørende biler og droner, kræver realtidsbeslutningstagning med minimal latenstid. Prunede neurale netværk gør det muligt for disse systemer at behandle sensordata og træffe kritiske beslutninger inden for stramme tidsrammer. Den reducerede beregningsmæssige overhead omsættes direkte til hurtigere responstider, hvilket er afgørende for sikkerhedskritiske anvendelser.
I cloud- og edge computing-miljøer reducerer pruning både beregningsmæssige omkostninger og lagerkrav ved implementering af store modeller. Organisationer kan betjene flere brugere med den samme infrastruktur eller alternativt reducere deres beregningsudgifter markant. Edge computing-scenarier får særligt meget ud af prunede modeller, da de muliggør avanceret AI-behandling på enheder langt fra centrale datacentre.
Evaluering af pruning-effektivitet kræver nøje overvejelse af flere målinger udover blot reduktion af antallet af parametre. Inferenslatenstid—tiden det tager for en model at generere output fra input—er en kritisk måling, der direkte påvirker brugeroplevelsen i realtidsapplikationer. Effektiv pruning bør markant reducere inferenslatenstiden og muliggøre hurtigere svartider for slutbrugerne.
Modelnøjagtighed og F1-score skal opretholdes gennem hele pruning-processen. Den grundlæggende udfordring ved pruning er at opnå betydelig komprimering uden at gå på kompromis med forudsigelsespræstationen. Velfunderede pruning-strategier holder nøjagtigheden inden for 1-5 % af den oprindelige model, samtidig med at de opnår 50-90 % parameterreduktion. Reduktion af hukommelsesforbrug er lige så vigtigt, da det afgør, om modeller kan implementeres på enheder med begrænsede ressourcer.
Forskning, der sammenligner store-sparsomme modeller (store netværk med mange parametre fjernet) med små-tætte modeller (mindre netværk trænet fra bunden) med identisk hukommelsesforbrug, viser konsekvent, at store-sparsomme modeller overgår deres små-tætte modstykker. Dette understreger værdien af at starte med større, velforberedte netværk og prune dem strategisk frem for at forsøge at træne mindre netværk fra begyndelsen.
Nøjagtighedstab forbliver den primære udfordring ved content pruning. Aggressiv pruning kan markant forringe modellens ydeevne og kræver omhyggelig kalibrering af pruning-intensiteten. Udviklere skal finde det optimale balancepunkt, hvor komprimeringsgevinsten maksimeres uden uacceptabelt nøjagtighedstab. Dette balancepunkt varierer afhængigt af den konkrete applikation, modelarkitektur og accepterede præstationsgrænser.
Hardwarekompatibilitetsproblemer kan begrænse de praktiske fordele ved pruning. Mens ustruktureret pruning skaber sparsomme netværk med færre parametre, er moderne hardware optimeret til tætte matrixoperationer. Sparsomme netværk kører måske ikke væsentligt hurtigere på standard-GPU’er uden specialiserede biblioteker og hardwareunderstøttelse for sparsomme beregninger. Struktureret pruning løser denne begrænsning ved at bevare tætte beregningsmønstre, dog på bekostning af mindre aggressiv komprimering.
Beregningsoverhead for selve pruning-metoderne kan være betydelig. Iterative pruning- og følsomhedsanalyse-baserede tilgange kræver flere træningsgange og nøje evaluering, hvilket forbruger mange ressourcer. Udviklere skal afveje engangsomkostningen ved pruning mod de løbende besparelser ved at implementere mere effektive modeller.
Generaliseringsproblemer opstår, når pruning bliver for aggressiv. Overprunede modeller kan klare sig godt på trænings- og valideringsdata, men generalisere dårligt til nye, ukendte data. Korrekte valideringsstrategier og omhyggelig testning på forskellige datasæt er afgørende for at sikre, at prunede modeller opretholder robust ydeevne i produktionsmiljøer.
Succesfuld content pruning kræver en systematisk tilgang baseret på best practices udviklet gennem omfattende forskning og praktisk erfaring. Start med større, velforberedte netværk frem for at forsøge at træne mindre netværk fra bunden. Større netværk giver mere overflod og fleksibilitet til pruning, og forskning viser konsekvent, at prunede store netværk overgår små netværk trænet fra begyndelsen.
Brug iterativ pruning med omhyggelig finjustering for gradvist at reducere modelkompleksitet, mens ydeevnen opretholdes. Denne tilgang giver bedre kontrol over balancen mellem nøjagtighed og effektivitet og gør det muligt for modellen at tilpasse sig parameterfjernelse. Anvend struktureret pruning til praktisk implementering, når hardwareacceleration er vigtig, da den producerer modeller, der kører effektivt på standardhardware uden behov for specialiseret understøttelse af sparsomme beregninger.
Valider grundigt på forskellige datasæt for at sikre, at prunede modeller generaliserer godt ud over træningsdata. Overvåg flere ydelsesmålinger, herunder nøjagtighed, inferenslatenstid, hukommelsesforbrug og strømforbrug for at vurdere pruning-effektiviteten omfattende. Tag hensyn til det målrettede implementeringsmiljø ved valg af pruning-strategier, da forskellige enheder og platforme har forskellige optimeringsegenskaber.
Området content pruning udvikler sig fortsat med nye teknikker og metoder. Contextually Adaptive Token Pruning (CATP) repræsenterer en banebrydende tilgang, der bruger semantisk tilpasning og featurediversitet til selektivt kun at bevare de mest relevante tokens i sprogmodeller. Denne teknik er særligt værdifuld for store sprogmodeller og multimodale systemer, hvor kontekststyring er afgørende.
Integration med vektordatabaser som Pinecone og Weaviate muliggør mere avancerede kontekst-pruning-strategier ved effektivt at lagre og hente relevant information. Disse integrationer understøtter dynamiske pruning-beslutninger baseret på semantisk lighed og relevansscoring, hvilket forbedrer både effektivitet og nøjagtighed.
Kombination med andre komprimeringsteknikker såsom kvantisering og knowledge distillation skaber synergetiske effekter, der muliggør endnu mere aggressiv modelkomprimering. Modeller, der samtidig er prunet, kvantiseret og destilleret, kan opnå komprimeringsrater på 100x eller mere, mens ydeevnen bevares på et acceptabelt niveau.
Efterhånden som AI-modeller fortsætter med at vokse i kompleksitet, og implementeringsscenarier bliver stadig mere mangfoldige, vil content pruning forblive en kritisk teknik for at gøre avanceret AI tilgængelig og praktisk på tværs af hele spektret af computermiljøer, fra kraftfulde datacentre til ressourcebegrænsede edge-enheder.
Opdag hvordan AmICited hjælper dig med at spore, når dit indhold optræder i AI-genererede svar på tværs af ChatGPT, Perplexity og andre AI-søgemaskiner. Sikr din brand-synlighed i den AI-drevne fremtid.
Indholdsbeskæring er den strategiske fjernelse eller opdatering af underpræsterende indhold for at forbedre SEO, brugeroplevelse og søgesynlighed. Lær hvordan d...

Fællesskabsdiskussion om indholdsbeskæring for AI-synlighed. Hvornår skal gammelt indhold fjernes, hvornår skal det konsolideres, og hvornår skal det efterlades...
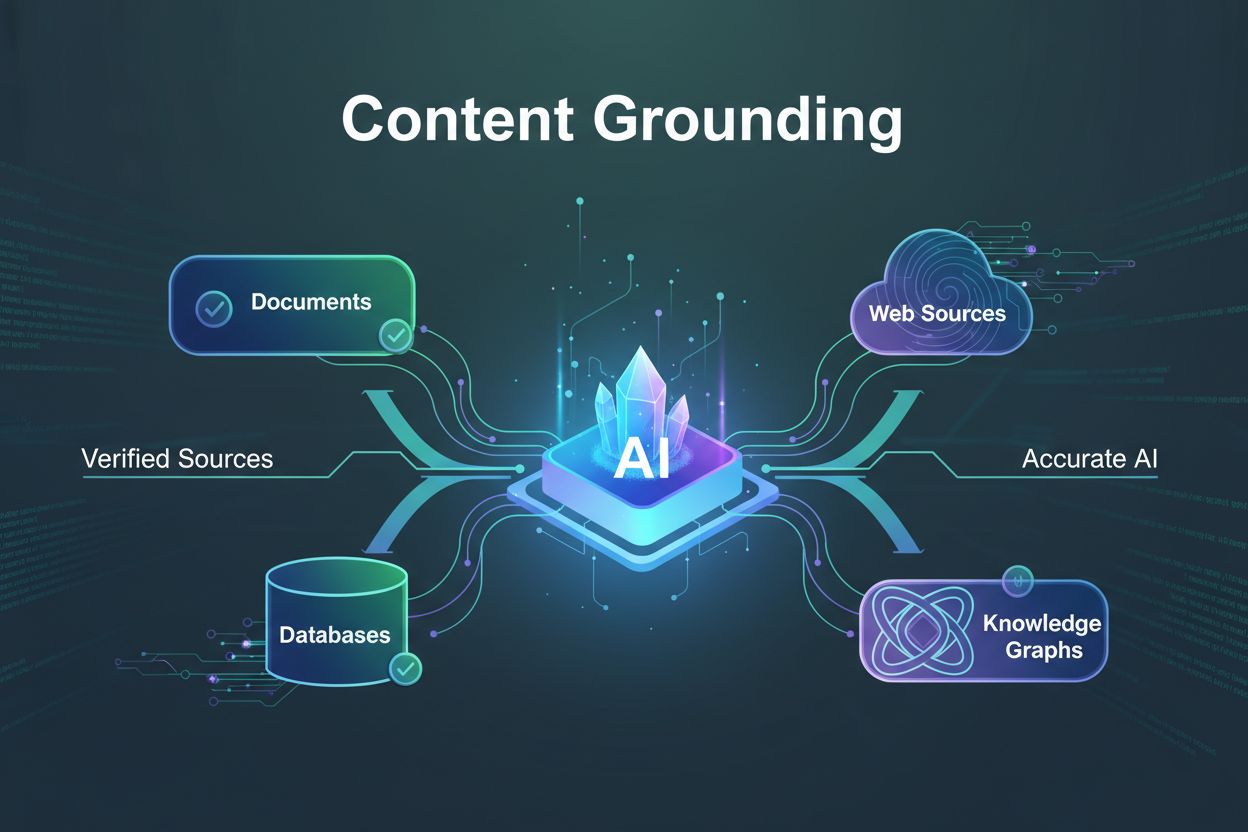
Lær hvad content grounding er, hvordan det forhindrer AI-hallucinationer, og hvorfor det er essentielt for troværdige AI-systemer. Opdag teknikker, værktøjer og...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.