Knowledge Graph
Lær hvad en knowledge graph er, hvordan søgemaskiner bruger dem til at forstå entitetsrelationer, og hvorfor de er vigtige for AI-synlighed og brandovervågning ...
14 min læsning

Opdag hvad knowledge graphs er, hvordan de fungerer, og hvorfor de er essentielle for moderne datastyring, AI-applikationer og forretningsintelligens.
En knowledge graph er et struktureret netværk, der forbinder dataenheder gennem definerede relationer, hvilket gør det muligt for både maskiner og mennesker at forstå komplekse informationsmønstre. Den er vigtig, fordi den omdanner rå data til anvendelige indsigter, driver AI-applikationer, forbedrer søgepræcision og gør det muligt for organisationer at nedbryde datasiloer for bedre beslutningstagning.
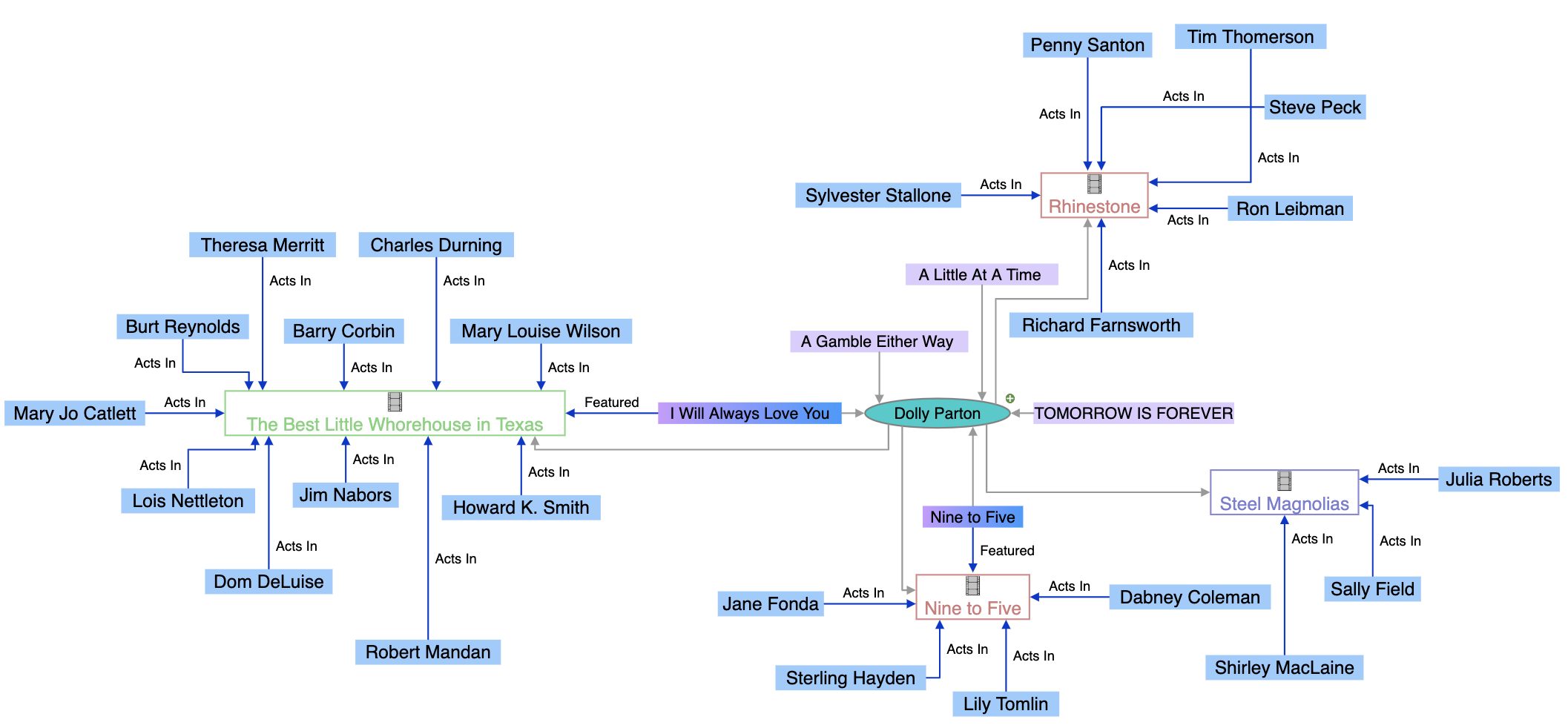
En knowledge graph er en struktureret, sammenkoblet repræsentation af dataenheder og deres relationer, organiseret som et netværk af noder og kanter. I modsætning til traditionelle relationelle databaser, der er afhængige af stive, foruddefinerede strukturer, modellerer knowledge graphs information som et semantisk web, hvor hvert punkt (node) repræsenterer en enhed—såsom en person, et sted, et produkt eller et begreb—og hver forbindelse (kant) illustrerer, hvordan disse enheder relaterer til hinanden. Denne grundlæggende forskel gør det muligt for både mennesker og maskiner at fortolke, forespørge og ræsonnere over data på måder, der tidligere ikke var mulige med konventionelle databasesystemer.
Udtrykket blev bredt anerkendt, da Google introducerede sin Knowledge Graph i 2012, hvilket revolutionerede søgeresultater ved at give direkte svar og afsløre forbindelser mellem begreber i stedet for blot at vise relevante links. Knowledge graphs har dog siden udviklet sig langt ud over forbrugerorienterede søgeapplikationer. I dag udnytter organisationer på tværs af brancher knowledge graphs til at organisere kompleks information, drive kunstige intelligenssystemer og opdage skjulte mønstre i deres dataøkosystemer. Styrken ved en knowledge graph ligger i dens evne til at indfange kontekst, ophav og betydning på tværs af hele datalandskabet, hvilket gør den til et uundværligt værktøj for moderne virksomheder, der søger konkurrencefordel gennem intelligent datastyring.
Hver knowledge graph består af fire essentielle komponenter, der arbejder sammen om at skabe et omfattende, forespørgbart informationssystem:
| Komponent | Definition | Eksempel |
|---|---|---|
| Enheder (Noder) | Objekter eller begreber, der beskrives med unikke identifikatorer | “Albert Einstein”, “Apple Inc.”, “New York City” |
| Relationer (Kanter) | Forbindelser mellem noder, der viser, hvordan enheder interagerer | “Albert Einstein opfandt relativitetsteorien” |
| Egenskaber (Attributter) | Karakteristika, der beskriver noder og giver kontekst | Fødselsdato: 14. marts 1879; Placering: Berlin, Tyskland |
| Ontologier & Skemaer | Formelle definitioner og regler, der styrer enhedstyper og relationer | RDF Schema (RDFS), Web Ontology Language (OWL), Schema.org |
Enheder danner fundamentet for enhver knowledge graph og repræsenterer virkelige objekter på en struktureret og organiseret måde. Hver enhed har en unik identifikator og kan have flere egenskaber og relationer med andre enheder. Relationer, også kaldet kanter, er de forbindelser, der binder enheder sammen og udtrykker, hvordan de interagerer og relaterer. Disse relationer kan være rettede (fra én enhed til en anden, som “John arbejder hos Google”) eller urettede (gensidige forbindelser, som “John og Mary er venner”). Ud over simple associationer kan relationer repræsentere hierarkiske strukturer, årsagssammenhænge, sekventielle afhængigheder eller netværksbaserede interaktioner.
Egenskaber eller attributter giver yderligere beskrivende information om enhederne og hjælper med at adskille dem fra lignende enheder i netværket. Disse kan spænde fra simple karakteristika som alder eller placering til komplekse, domænespecifikke egenskaber såsom medicinske tilstande, finansielle målinger eller tekniske specifikationer. Endelig etablerer ontologier og skemaer den formelle ramme, der styrer, hvordan enheder, relationer og egenskaber defineres og bruges. Populære ontologier inkluderer RDF Schema (RDFS) til grundlæggende hierarkier, Web Ontology Language (OWL) til kompleks ræsonnering og Schema.org til standardiseret webdatarepræsentation. Disse komponenter arbejder sammen for at skabe et fleksibelt, udvideligt system, der kan repræsentere viden på tværs af næsten ethvert domæne.
Knowledge graphs fungerer ved at skabe et semantisk lag på tværs af en organisations dataøkosystem, hvor adskilte datakilder omdannes til et samlet, sammenkoblet vidensnetværk. Når data indlæses i en knowledge graph, anvender maskinlæringsalgoritmer drevet af naturlig sprogbehandling (NLP) en proces kaldet semantisk berigelse. Denne proces identificerer individuelle objekter i dataene og forstår automatisk relationerne mellem forskellige objekter, selv når de stammer fra kilder med forskellige strukturelle karakteristika. Det semantiske lag er særligt kraftfuldt, fordi det kan skelne mellem ord med flere betydninger—for eksempel at forstå, at “Apple” i én kontekst refererer til teknologivirksomheden, mens det i en anden kontekst refererer til frugten.
Når knowledge graphen er konstrueret, muliggør den sofistikerede spørgesystemer og søgemekanismer, der kan give omfattende svar på komplekse spørgsmål. I stedet for at kræve nøjagtige søgeordsmatch kan semantiske søgesystemer forstå brugerens hensigt og returnere relateret information, selv når specifikke termer ikke eksplicit bruges. Denne kontekstuelle forståelse opnås gennem graphens evne til eksplicit at modellere relationer og afhængigheder. Data-integrationsindsatsen omkring knowledge graphs genererer også ny viden ved at etablere forbindelser mellem tidligere ikke-relaterede datapunkter, hvilket afslører indsigter, der ikke var synlige i isolerede datasæt. For organisationer betyder dette, at knowledge graphs kan eliminere manuelt dataindsamlings- og integrationsarbejde, accelerere forretningsbeslutninger og muliggøre selvbetjeningsanalyse, hvor forretningsbrugere kan forespørge direkte på graphen uden IT-support.
Knowledge graphs er blevet stadig mere afgørende for moderne organisationer af flere overbevisende grunde. Hurtigere beslutningstagning er en af de mest umiddelbare fordele—knowledge graphs giver et 360-graders overblik over dataenheder og deres relationer, så analytikere hurtigt kan identificere mønstre, forbindelser og indsigter, som ville tage betydeligt længere tid at finde gennem traditionelle analysemetoder. Dette komplette perspektiv gør det muligt for organisationer at træffe informerede beslutninger baseret på fuldstændig information i stedet for fragmenterede datavisninger.
Forbedret kundeoplevelse repræsenterer en anden væsentlig fordel. Ved at forbinde kundedata på tværs af forskellige kontaktpunkter—herunder købshistorik, supportinteraktioner, browsingadfærd og demografisk information—kan organisationer skabe detaljerede kundeprofiler, der muliggør personlige og relevante oplevelser. Dette samlede overblik understøtter målrettet markedsføring, produktanbefalinger og proaktiv kundeservice. Effektiv datastyring opnås gennem knowledge graphs’ evne til at forbinde og harmonisere data fra forskellige kilder, hvilket nedbryder organisatoriske siloer, der typisk forhindrer effektiv dataudveksling og samarbejde. Ved at anvende best practices i datapreparation og udnytte den semantiske styrke ved knowledge graphs opnår organisationer en betydelig konkurrencefordel.
At give forretningsbrugere magten gennem selvbetjeningsfunktioner demokratiserer dataadgang i hele organisationen. I stedet for at skulle henvende sig til IT-afdelinger for at få svar på alle datarelaterede spørgsmål, kan forretningsbrugere interagere direkte med og forespørge på knowledge graphs ved hjælp af intuitive visualiseringsværktøjer, hvilket accelererer indsigt og reducerer flaskehalse. Accelererede AI- og maskinlæringsinitiativer drager enorm fordel af knowledge graphs’ strukturerede, semantiske natur. De sammenkoblede data udgør ideelt træningsmateriale for AI-systemer og gør dem i stand til at udlede komplekse mønstre, tendenser og resultater, samtidig med at tid og omkostninger til modeludvikling reduceres. Knowledge graphs understøtter også avancerede applikationer som Retrieval-Augmented Generation (RAG), hvor AI-systemer kan udlede komplekse relationer fra store datasæt for at ræsonnere mere som mennesker og levere mere nøjagtige, kontekstuelle svar.
Knowledge graphs har bevæget sig ud over teoretiske koncepter og leverer mærkbar værdi på tværs af forskellige sektorer. Inden for sundhedsvæsen og biovidenskab bruger medicinske forskningsnetværk og kliniske beslutningsstøtteværktøjer knowledge graphs til at forbinde symptomer, behandlinger, udfald og medicinske publikationer, hvilket hjælper klinikere og forskere med at opdage indsigter, der forbedrer patientpleje og fremskynder lægemiddeludvikling. Finansielle institutioner udnytter knowledge graphs til ‘know-your-customer’ (KYC) og anti-hvidvask-initiativer, hvor relationer mellem personer, konti og transaktioner kortlægges for at opdage mistænkelige aktiviteter og forhindre økonomisk kriminalitet. Detail- og e-handelsvirksomheder implementerer knowledge graphs til at drive anbefalingsmotorer og up-sell/cross-sell-strategier, hvor købsadfærd og demografiske tendenser analyseres for at foreslå produkter, kunderne sandsynligvis vil købe.
Underholdningsplatforme som Netflix, Spotify og Amazon bruger knowledge graphs til at opbygge sofistikerede anbefalingsmotorer, der analyserer brugerengagement og indholdsrelationer for at foreslå film, musik og produkter tilpasset individuelle præferencer. Optimering af forsyningskæden er et andet stærkt anvendelsesområde, hvor knowledge graphs modellerer komplekse leverandørrelationer, logistiknetværk og vareflow, hvilket muliggør realtidsdetektion af flaskehalse og risikominimering. Regulatorisk compliance og governance drager fordel af knowledge graphs’ evne til automatisk at spore dataophav, kortlægge dataenheder til systemer og politikker og demonstrere overholdelse af regler som GDPR og HIPAA. For eksempel kan en knowledge graph øjeblikkeligt vise alle placeringer, hvor personhenførbare oplysninger (PII) er gemt, hvilke applikationer der har adgang til dem, og hvilke privatlivspolitikker der gælder—kritiske funktioner for moderne datastyring.
Selvom knowledge graphs giver betydelige fordele, skal organisationer omhyggeligt adressere flere udfordringer for at implementere dem succesfuldt. Datakvalitet og -kuratering forbliver vedvarende bekymringer, da nøjagtigheden og fuldstændigheden af knowledge graphen direkte påvirker kvaliteten af de indsigter, den producerer. Organisationer skal etablere processer til validering af data, løsning af uoverensstemmelser og vedligeholdelse af dataaktualitet, efterhånden som ny information bliver tilgængelig. Skalerbarhed og vedligeholdelse udgør tekniske udfordringer, især når knowledge graphs vokser til at omfatte millioner eller milliarder af enheder og relationer. At sikre, at forespørgselsydelsen forbliver acceptabel, og at systemet kan håndtere stigende datamængder kræver omhyggelig arkitekturplanlægning og infrastrukturinvestering.
Entity resolution—processen med at identificere, hvornår forskellige datarepræsentationer refererer til samme reelle enhed—er et komplekst problem, der kan påvirke knowledge graphens kvalitet betydeligt. Privatlivs- og sikkerhedshensyn bliver stadig vigtigere, når knowledge graphs indeholder følsomme eller personlige data, hvilket kræver robuste adgangskontroller, kryptering og compliance-mekanismer. Bias i knowledge graphs kan fastholde eller forstærke eksisterende bias i kildedataene og potentielt føre til uretfærdige eller diskriminerende resultater i AI-applikationer, der drives af graphen. Organisationer skal implementere omhyggelig overvågning og governance for at identificere og afbøde bias. På trods af disse udfordringer gør knowledge graphs’ strategiske værdi dem investeringen værd for organisationer, der er seriøse omkring at udnytte data som et konkurrenceaktiv.
Knowledge graphs repræsenterer et grundlæggende skift i, hvordan organisationer håndterer, styrer og udvinder værdi fra deres data. Ved at omdanne statiske datainventarer til levende, sammenkoblede vidensnetværk muliggør de smartere opdagelse, robust governance og AI-klare dataøkosystemer. Efterhånden som kunstig intelligens fortsætter med at udvikle sig, og organisationer samler stadig større datamængder, vil vigtigheden af knowledge graphs kun vokse. De leverer det kontekstuelle fundament, der kræves til avanceret analyse, maskinlæring og AI-forklarlighed—hvilket gør det muligt for organisationer at opdage skjulte mønstre, automatisere ræsonnement og understøtte beslutningstagning i stor skala. For enhver organisation, der ønsker at forbedre AI-evner, styrke kundeoplevelser eller opnå konkurrencefordel gennem bedre dataudnyttelse, bør implementering af knowledge graph-løsninger være en strategisk prioritet i den digitale transformationsrejse.
Ligesom knowledge graphs organiserer information intelligent, sporer vores AI-overvågningsplatform, hvordan dit brand fremstår på tværs af ChatGPT, Perplexity og andre AI-søgemaskiner. Sikr dit brands synlighed i den AI-drevne fremtid.
Lær hvad en knowledge graph er, hvordan søgemaskiner bruger dem til at forstå entitetsrelationer, og hvorfor de er vigtige for AI-synlighed og brandovervågning ...

Fællesskabsdiskussion, der forklarer Knowledge Graphs og deres betydning for synlighed i AI-søgning. Eksperter deler, hvordan entiteter og relationer påvirker A...
Lær hvad en graf er i datavisualisering. Opdag hvordan grafer viser relationer mellem data ved hjælp af noder og kanter, og hvorfor de er essentielle for at for...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.