Sonar-algoritme
Sonar-algoritmen er Perplexitys proprietære RAG-rangeringssystem, der kombinerer hybrid retrieval, neural gen-rangering og realtids-citationsgenerering. Lær hvo...
12 min læsning

Lær hvordan Perplexitys Sonar-algoritme driver AI-søgning i realtid med omkostningseffektive modeller. Udforsk varianterne Sonar, Sonar Pro og Sonar Reasoning.
Sonar er Perplexitys letvægts, omkostningseffektive søgemodelfamilie, optimeret til realtidsintegration af websøgningsresultater med store sprogmodeller. Den kombinerer hurtig informationshentning med underbyggede svar og tilbyder varianter, herunder basis-Sonar til hurtig Q&A, Sonar Pro til komplekse forespørgsler samt Sonar Reasoning til kæde-af-tanke-problemløsning med live webadgang.
Sonar er Perplexitys proprietære søgemodelfamilie, designet til at integrere realtids websøgningsfunktioner direkte i store sprogmodeller for at generere underbyggede, præcise svar. I modsætning til traditionelle søgemaskiner, der returnerer blå links, driver Sonar-algoritmer en AI-først søgeoplevelse, hvor modellen syntetiserer information fra flere kilder for at levere omfattende og citerede svar. Sonar-familien repræsenterer et grundlæggende skifte i, hvordan AI-systemer tilgår og behandler aktuelle oplysninger, hvilket gør det muligt for modeller at besvare spørgsmål om nylige begivenheder, breaking news og opdaterede data uden at skulle stole på statiske træningsdata. Denne teknologi er afgørende i det udviklende landskab af AI-søgemaskiner som Perplexity, ChatGPT med websøgningsfunktion, Google AI Overviews og Claude, hvor realtids informationshentning er blevet essentielt for at opretholde nøjagtighed og relevans.
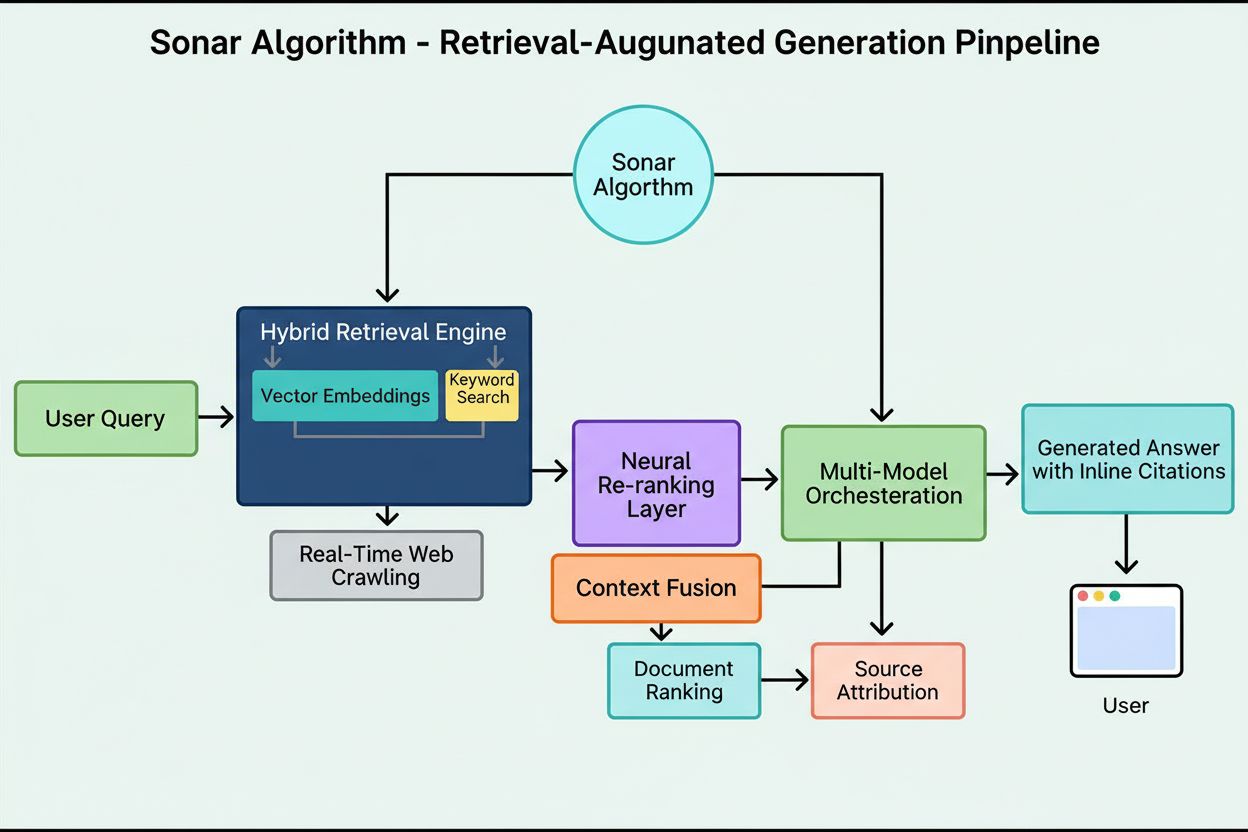
Perplexitys søgeinfrastruktur behandler over 200 millioner daglige forespørgsler og opretholder et indeks, der sporer over 200 milliarder unikke URL’er, hvilket gør det til et af de største og mest opdaterede webindekser, optimeret specifikt til AI-brug. Sonar-algoritmen blev udviklet for at afhjælpe kritiske begrænsninger i ældre søge-API’er, der var designet til mennesker frem for AI-modeller. Traditionelle søge-API’er opkrævede urimelige gebyrer (nogle leverandører opkrævede $200 per tusind forespørgsler), fungerede med forældede indekser og returnerede dokumentniveau-resultater, der var for grovkornede til AI-modeller med begrænsede kontekstvinduer. Sonar løser disse problemer via en hybrid pipeline til informationshentning og rangering, der kombinerer både leksikalske (nøgleordsbaserede) og semantiske (meningsbaserede) signaler for at identificere de mest relevante oplysninger på subdokument-niveau.
Arkitekturen bag Sonar bygger på tre grundlæggende principper: fuldstændighed, aktualitet og hastighed. Søgeindekset skal kortlægge nettet omfattende, konstant opdateres for at afspejle den nyeste information og besvare forespørgsler på millisekunder for at understøtte realtids-AI-applikationer. Perplexitys crawling-infrastruktur består af titusindvis af CPU’er og hundredvis af terabyte RAM, hvilket gør det muligt for systemet at udføre titusindvis af indekseringsoperationer i sekundet. Maskinlæringsmodeller forudsiger, hvilke URL’er der skal indekseres og hvornår, hvilket sikrer, at populære og ofte opdaterede dokumenter forbliver aktuelle, samtidig med at crawl-raten holdes håndterbar for websideoperatører.
| Modelvariant | Primær anvendelse | Nøglefunktioner | Kontekstlængde | Optimeringsfokus |
|---|---|---|---|---|
| Sonar (Basis) | Hurtig Q&A og ligetil søgninger | Letvægts, omkostningseffektiv, realtids websøgningsmodel | 128K tokens | Hastighed og prisvenlighed |
| Sonar Pro | Komplekse forespørgsler og avanceret research | Forbedret informationshentning, kilde-tilpasning, citationer | 128K tokens | Nøjagtighed og håndtering af kompleksitet |
| Sonar Reasoning | Logisk problemløsning og analyse | Chain-of-Thought ræsonnement, trinvis inferens | 128K tokens | Dybere ræsonnement med live søgning |
| Sonar Reasoning Pro | Højtydende kompleks analyse | Avanceret multi-trins CoT, forbedret informationshentning | 128K tokens | Maksimal ræsonnementsevne |
Perplexitys Sonar-familie inkluderer fire forskellige modelvarianter, hver optimeret til forskellige anvendelser og kompleksitetsniveauer. Basis Sonar-model er den letteste og mest omkostningseffektive løsning, designet til daglig brug såsom opsummering af indhold, opslag af definitioner og nyhedsbrowsing. Den behandler forespørgsler til $1 per 1 million input tokens og $1 per 1 million output tokens, hvilket gør den væsentligt billigere end konkurrerende løsninger. Sonar Pro bygger videre på dette fundament med forbedrede evner til at håndtere komplekse, flertrinsforespørgsler, der kræver dybere analyse og kilde-tilpasning. Brugere kan angive, hvilke kilder der skal prioriteres eller udelukkes, hvilket giver dem detaljeret kontrol over informationshentningen.
Sonar Reasoning introducerer Chain-of-Thought (CoT) ræsonnement, en teknik hvor modellen eksplicit arbejder sig trinvis gennem problemer, før den når frem til konklusioner. Denne variant drives af DeepSeek-R1-teknologi og udmærker sig i logisk ræsonnement, matematisk problemløsning og struktureret analyse. Sonar Reasoning Pro repræsenterer det højeste præstationsniveau og kombinerer avanceret multi-trins ræsonnement med forbedret informationshentning til de mest krævende analytiske opgaver. Alle Sonar-varianter har en 128K token kontekstlængde, hvilket giver betydelig plads til behandling af lange dokumenter, flere kilder og komplekse prompts.
Sonar-algoritmen implementerer en flertrins pipeline til informationshentning og rangering, der gradvist raffinerer søgeresultaterne med stigende sofistikering. Processen begynder med hybrid informationshentning, hvor systemet forespørger søgeindekset med både leksikale og semantiske metoder samtidigt og derefter samler resultaterne til et omfattende kandidatfelt. Denne dobbelte tilgang sikrer, at både nøgleordsbestemte matches og konceptuelt lignende indhold indfanges. Efterfølgende trin anvender forfiltreringsheuristik til at fjerne klart irrelevante eller forældede resultater, efterfulgt af flere runder af rangering med stadig mere avancerede modeller.
Tidlige rangeringstrin anvender leksikale og embedding-baserede scorere optimeret for hastighed, mens senere trin benytter cross-encoder reranker-modeller, der udfører avanceret semantisk analyse. Hele pipelinen arbejder både på dokument- og subdokumentniveau, hvilket betyder, at systemet kan identificere og udtrække specifikke afsnit, sektioner eller endda sætninger, der direkte besvarer en forespørgsel – i stedet for at brugeren skal gennemgå hele websider. Denne finmaskede indholdsforståelse er afgørende for AI-modeller, hvor hver token i konteksten betyder noget, og irrelevant information kan forringe præstationen. Perplexitys indholdsforståelsesmodul bruger dynamiske regelbaser og AI-drevet selvforbedring til at tolke webens varierede struktur og tilpasser sig løbende nye layout og indholdsmønstre.
Perplexitys Sonar-modeller har vist fremragende resultater i grundige evalueringer mod konkurrerende AI-søgeløsninger. I omfattende benchmarking ved brug af rammer som SimpleQA, FRAMES, BrowseComp og HLE har Sonar-varianterne konsekvent overgået modeller fra Google Gemini 2.0 Flash, OpenAI GPT-4o Search og andre førende AI-systemer. På SimpleQA-benchmarken opnåede Sonar en score på 0,930, hvilket er markant højere end konkurrenter som Brave Search (0,822) og SERP-baserede API’er (0,890). For dybdegående researchopgaver målt ved HLE-benchmarken nåede Sonar 0,288, væsentligt foran alternative udbydere.
Ud over kvalitetsmålinger udmærker Sonar sig i latenstid, en kritisk faktor for brugerrettede applikationer. Perplexitys median søgelatenstid er 358 millisekunder, over 150 millisekunder hurtigere end næstbedste udbyder. 95%-percentilens latenstid forbliver under 800 millisekunder, hvilket sikrer konsekvent ydeevne selv under spidsbelastning. Denne hastighedsforskel skyldes Perplexitys infrastrukturelle investeringer, herunder distribueret indeksering på tværs af hundredvis af terabyte lager, intelligente caching-strategier og optimerede inferens-pipelines. Kombinationen af state-of-the-art kvalitet og branches førende hastighed betyder, at udviklere ikke længere behøver vælge mellem hurtige applikationer og nøjagtige resultater.
Sonar-algoritmer repræsenterer et paradigmeskifte i, hvordan AI-systemer tilgår realtidsinformation – grundlæggende anderledes end traditionelle søgemaskiner og tidligere AI-chatbots. ChatGPT med websøgningsfunktion og Google AI Overviews tilbyder realtidsfunktioner, men Sonars design er specifikt optimeret til AI-brug frem for at tilpasse menneskeorienteret søgning til AI-modeller. Sonar API giver udviklere programmatisk adgang til Perplexitys søgeinfrastruktur, så de kan bygge AI-applikationer, der kræver opdateret information uden selv at skulle håndtere crawling, indeksering og rangering.
Perplexitys søgeinfrastruktur besvarer forespørgsler med realtids websøgningsbaserede svar, der inkluderer detaljerede søgeresultater og citationer, så brugere kan verificere informationskilder. Systemet leverer 5,01 links per svar i gennemsnit, hvilket placerer det mellem ChatGPT (10,42 links) og andre AI-søgeværktøjer. Denne balancerede tilgang giver tilstrækkelig kildemangfoldighed til verifikation uden at overvælde brugeren med for mange citationer. Sonar-algoritmens evne til at citere kilder er især vigtig for brandovervågning og indholdssynlighed, da organisationer kan følge, hvornår deres domæner optræder i AI-genererede svar på tværs af platforme som Perplexity, ChatGPT, Claude og Google AI Overviews ved hjælp af værktøjer som AmICited, der er specialiseret i at overvåge brand- og domænetilstedeværelse i AI-søgeresultater.
Sonar-algoritmer driver alsidige applikationer på tværs af forskning, forretningsanalyse, indholdsskabelse og realtids informationshentning. Forskere bruger Sonar til at udføre omfattende litteraturgennemgange og syntetisere information fra flere kilder med korrekte citater. Forretningsanalytikere anvender Sonar Pro til konkurrentovervågning, markedsundersøgelser og trendanalyse, der kræver aktuelle data. Indholdsskabere benytter Sonar til at faktatjekke, finde nye eksempler og sikre, at deres arbejde afspejler de seneste udviklinger inden for deres felt. Nyhedsorganisationer og faktatjekkere er afhængige af Sonars realtids søgefunktion til at verificere påstande og levere kontekst til aktuelle historier.
Sonar Reasoning-varianterne er særligt værdifulde til teknisk problemløsning, hvor trinvis analyse kombineret med aktuelle oplysninger giver overlegne resultater. Softwareudviklere bruger Sonar Reasoning til fejlfinding ved at tilgå den nyeste dokumentation, Stack Overflow-diskussioner og GitHub-repositorier. Dataforskere benytter Sonar til at følge med i hurtigt udviklende metoder og få adgang til nye forskningsartikler. Finansfolk bruger Sonar Pro til at overvåge markedstendenser, følge regulatoriske ændringer og analysere nye strømninger. Muligheden for at kombinere realtids websøgningsfunktion med avanceret ræsonnement gør Sonar særligt værdifuld i domæner, hvor information hurtigt ændrer sig, og nøjagtighed er afgørende.
Sonar-algoritmen er kun begyndelsen på AI-native søgeinfrastruktur. Perplexitys forskning viser, at ældre søgemaskiner har stabiliseret sig omkring 10 milliarder forespørgsler om dagen, mens næste generation af AI-drevet søgning vil betjene flere størrelsesordener flere forespørgsler, efterhånden som autonome AI-agenter bliver allestedsnærværende. Fremtidige versioner af Sonar skal adressere nye udfordringer, herunder effektiv skalering i takt med eksponentiel forespørgselsvækst, nye kontekstteknikker optimeret til stadig mere avancerede AI-modeller og den evige balance mellem fuldstændighed, aktualitet og latenstid.
Perplexitys infrastruktur er unikt positioneret til at håndtere disse udfordringer ved at kombinere et massivt produktsøgesystem, der betjener millioner af brugere dagligt, med teknisk talent og forskningskapacitet. Virksomhedens selvforbedrende indholdsforståelsesmodul viser, hvordan AI løbende kan forbedre søgekvaliteten uden manuel indblanding. Når AI-agenter bliver mere autonome og kapable, bliver kvaliteten af deres underliggende søgeinfrastruktur stadig mere kritisk. Sonars udvikling vil sandsynligvis inkludere dybere integration med agentiske arbejdsgange, mere sofistikeret kontekstkuratering til specifikke AI-modelarkitekturer og forbedrede kildeverificeringsfunktioner for at bekæmpe misinformation. Organisationer, der ønsker at fastholde synlighed i dette udviklende landskab, bør overvåge deres brandfremtræden på tværs af AI-søgeplatforme med specialiserede værktøjer og sikre, at deres indhold forbliver autoritativt og korrekt citeret, efterhånden som AI-systemer bliver den primære grænseflade for informationssøgning.
Følg med i, hvornår dit domæne optræder i Perplexity Sonar-svar og andre AI-søgeresultater. Sikr, at dit indhold citeres som en autoritativ kilde på alle større AI-platforme.
Sonar-algoritmen er Perplexitys proprietære RAG-rangeringssystem, der kombinerer hybrid retrieval, neural gen-rangering og realtids-citationsgenerering. Lær hvo...

Lær hvad SearchGPT er, hvordan det fungerer, og dets indflydelse på søgning, SEO og digital markedsføring. Udforsk funktioner, begrænsninger og fremtiden for AI...

Perplexity AI er en AI-drevet svarmotor, der kombinerer realtidssøgning på nettet med LLM'er for at levere citerede, præcise svar. Lær hvordan den fungerer og d...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.