Et teknisk eftersyn af websitetets arkitektur, konfiguration og indholdsstruktur for at afgøre, om AI-crawlere effektivt kan tilgå, forstå og udtrække indhold. Evaluerer robots.txt-konfiguration, XML-sitemaps, sidens crawlbarhed, JavaScript-rendering og evne til indholdsekstraktion for at sikre synlighed på AI-drevne søgeplatforme som ChatGPT, Claude og Perplexity.
AI-tilgængelighedsrevision
Et teknisk eftersyn af websitetets arkitektur, konfiguration og indholdsstruktur for at afgøre, om AI-crawlere effektivt kan tilgå, forstå og udtrække indhold. Evaluerer robots.txt-konfiguration, XML-sitemaps, sidens crawlbarhed, JavaScript-rendering og evne til indholdsekstraktion for at sikre synlighed på AI-drevne søgeplatforme som ChatGPT, Claude og Perplexity.
Hvad er en AI-tilgængelighedsrevision?
En AI-tilgængelighedsrevision er en teknisk gennemgang af din hjemmesides arkitektur, konfiguration og indholdsstruktur for at afgøre, om AI-crawlere effektivt kan tilgå, forstå og udtrække dit indhold. I modsætning til traditionelle SEO-revisioner, der fokuserer på søgeordsrangeringer og backlinks, undersøger AI-tilgængelighedsrevisioner de tekniske fundamenter, der gør det muligt for AI-systemer som ChatGPT, Claude og Perplexity at opdage og citere dit indhold. Revisionen evaluerer vigtige komponenter som robots.txt-konfiguration, XML-sitemaps, sidens crawlbarhed, JavaScript-rendering og evnen til indholdsekstraktion for at sikre, at dit website er fuldt synligt i det AI-drevne søgeøkosystem.
Hvorfor AI-crawlere ikke kan tilgå dit indhold
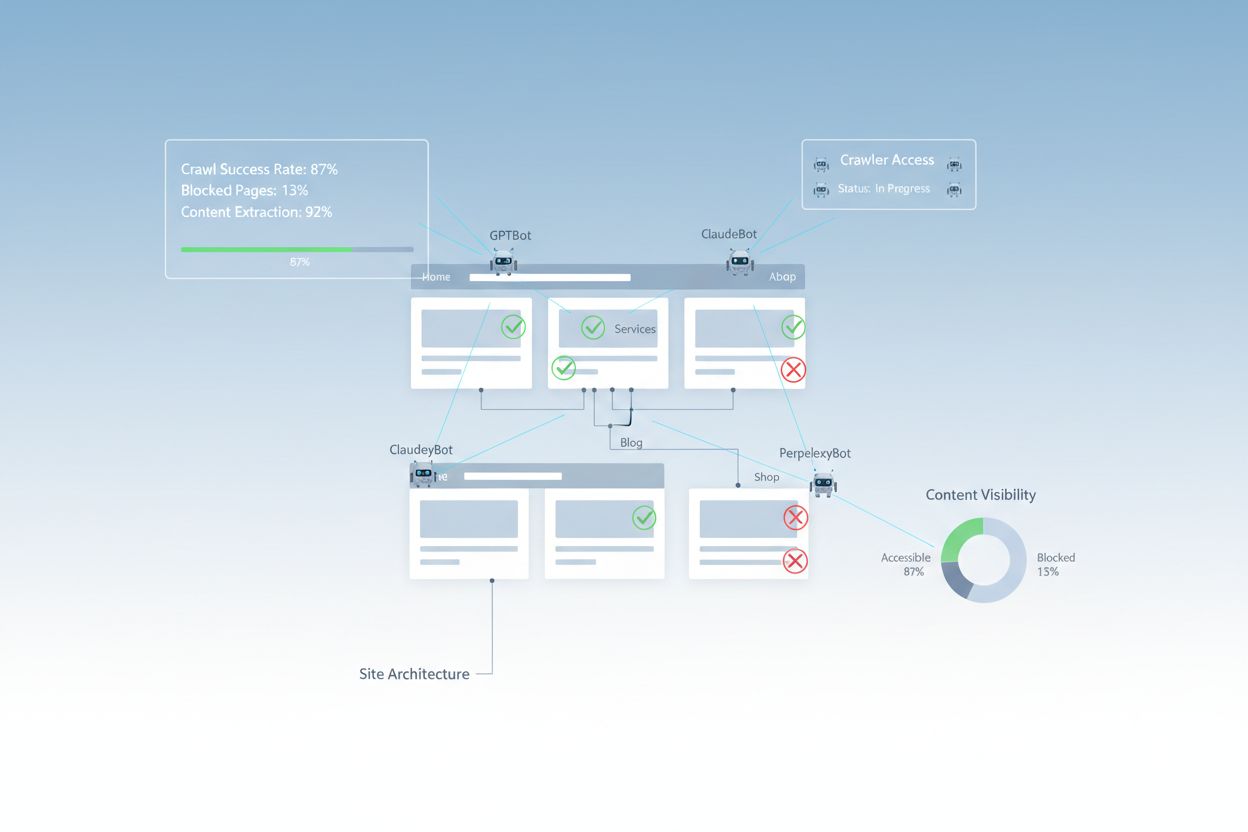
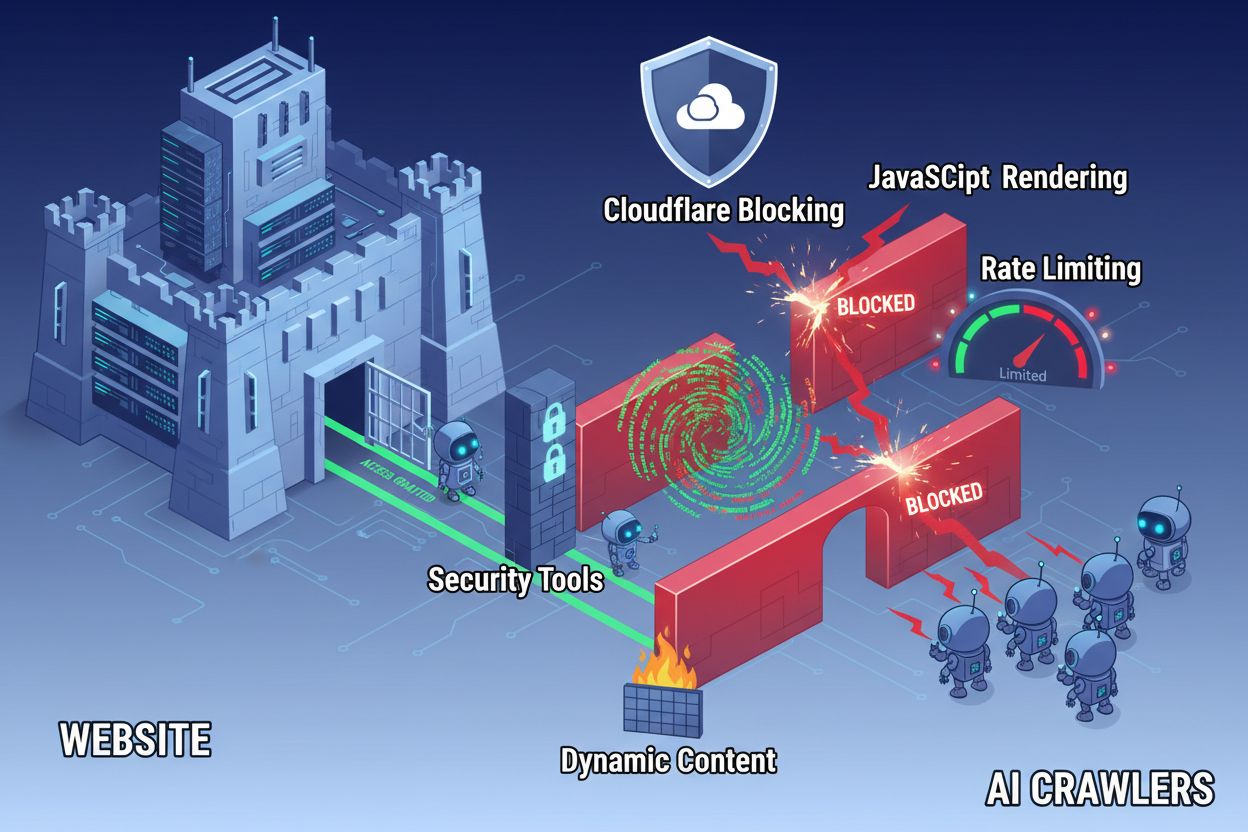
På trods af fremskridt inden for webteknologi står AI-crawlere over for betydelige barrierer, når de forsøger at tilgå moderne websites. Den primære udfordring er, at mange nutidige websites i høj grad er afhængige af JavaScript-rendering til at vise indhold dynamisk, men de fleste AI-crawlere kan ikke udføre JavaScript-kode. Det betyder, at cirka 60-90% af moderne website-indhold forbliver usynligt for AI-systemer, selvom det vises perfekt i brugernes browsere. Derudover blokerer sikkerhedsværktøjer som Cloudflare AI-crawlere som standard og betragter dem som potentielle trusler frem for legitime indekseringsrobotter. Forskning viser, at 35% af virksomhedssites utilsigtet blokerer AI-crawlere, hvilket forhindrer værdifuldt indhold i at blive opdaget og citeret af AI-systemer.
Almindelige barrierer, der forhindrer AI-crawleradgang, omfatter:
JavaScript-renderingbegrænsninger – AI-crawlere kan ikke køre JavaScript og går derfor glip af dynamisk indlæst indhold
Cloudflare og sikkerhedsværktøjsblokering – Standard sikkerhedskonfigurationer behandler AI-bots som trusler
Ratelimitering og crawl-restriktioner – Serverbegrænsninger forhindrer omfattende indeksering af indhold
Kompleks sitearkitektur – Indlejrede URL’er og dårlig intern linkstruktur forvirrer crawlernavigation
Dynamisk indhold og lazy loading – Indhold, der indlæses ved brugerinteraktion, forbliver skjult for crawlere
En omfattende AI-tilgængelighedsrevision undersøger flere tekniske og strukturelle elementer, der påvirker, hvordan AI-systemer interagerer med dit website. Hver komponent spiller en særskilt rolle i forhold til, om dit indhold bliver synligt på AI-drevne søgeplatforme. Revisionsprocessen involverer test af crawlbarhed, verifikation af konfigurationsfiler, vurdering af indholdsstruktur og overvågning af faktisk crawleradfærd. Ved systematisk at evaluere disse komponenter kan du identificere specifikke barrierer og implementere målrettede løsninger for at forbedre din AI-synlighed.
Komponent
Formål
Indvirkning på AI-synlighed
Robots.txt-konfiguration
Styrer, hvilke crawlere der kan tilgå bestemte sections af sitet
Kritisk – Forkert konfiguration kan blokere AI-crawlere fuldstændigt
XML-sitemaps
Vejleder crawlere til vigtige sider og indholdsstruktur
Høj – Hjælper AI-systemer med at prioritere og opdage indhold
Sidens crawlbarhed
Sikrer, at sider er tilgængelige uden login eller kompleks navigation
Kritisk – Blokerede sider er usynlige for AI-systemer
JavaScript-rendering
Bestemmer, om dynamisk indhold er synligt for crawlere
Kritisk – 60-90% af indholdet kan gå tabt uden prerendering
Indholdsekstraktion
Vurderer, hvor let AI-systemer kan analysere og forstå indholdet
Høj – Dårlig struktur mindsker sandsynligheden for citation
Sikkerhedsværktøjskonfiguration
Styrer firewall- og beskyttelsesregler, der påvirker crawleradgang
Kritisk – For restriktive regler blokerer legitime AI-bots
Schema markup-implementering
Giver maskinlæsbar kontekst om indholdet
Medium – Forbedrer AI-forståelse og citationssandsynlighed
Intern linkstruktur
Etablerer semantiske relationer mellem sider
Medium – Hjælper AI med at forstå emneautoritet og relevans
Robots.txt-konfiguration for AI-crawlere
Din robots.txt-fil er det primære værktøj til at styre, hvilke crawlere der kan tilgå dit website. Filen placeres i roden af dit domæne og indeholder simple tekstdirektiver, der fortæller crawlere, om de må tilgå bestemte områder af sitet. For AI-tilgængelighed er korrekt robots.txt-konfiguration afgørende, for forkerte regler kan fuldstændigt blokere store AI-crawlere som GPTBot (OpenAI), ClaudeBot (Anthropic) og PerplexityBot (Perplexity). Nøglen er eksplicit at tillade disse crawlere og samtidig beskytte følsomme områder ved at blokere ondsindede bots.
Eksempel på robots.txt-konfiguration for AI-crawlere:
Denne konfiguration tillader eksplicit de store AI-crawlere at tilgå dit offentlige indhold, mens administrative og private sektioner beskyttes. Sitemap-direktiverne hjælper crawlere med hurtigt at finde dine vigtigste sider.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
XML-sitemaps for AI-opdagelse
Et XML-sitemap fungerer som et kort for crawlere, der oplister de URL’er, du ønsker indekseret, og giver metadata om hver side. For AI-systemer er sitemaps særligt værdifulde, fordi de hjælper crawlere med at forstå dit sites struktur, prioritere vigtigt indhold og opdage sider, der ellers ville blive overset ved almindelig crawling. I modsætning til traditionelle søgemaskiner, der kan udlede site-struktur gennem links, har AI-crawlere stor fordel af eksplicit vejledning til, hvilke sider der er vigtigst. Et veldesignet sitemap med korrekte metadata øger sandsynligheden for, at dit indhold bliver opdaget, forstået og citeret af AI-systemer.
Eksempel på XML-sitemap-struktur for AI-optimering:
<?xml version="1.0" encoding="UTF-8"?><urlsetxmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><!-- High-priority content for AI crawlers --><url><loc>https://yoursite.com/about</loc><lastmod>2025-01-03</lastmod><priority>1.0</priority></url><url><loc>https://yoursite.com/products</loc><lastmod>2025-01-03</lastmod><priority>0.9</priority></url><url><loc>https://yoursite.com/blog/ai-guide</loc><lastmod>2025-01-02</lastmod><priority>0.8</priority></url><url><loc>https://yoursite.com/faq</loc><lastmod>2025-01-01</lastmod><priority>0.7</priority></url></urlset>
Priority-attributten signalerer til AI-crawlere, hvilke sider der er vigtigst, mens lastmod angiver indholdets aktualitet. Det hjælper AI-systemer med at fordele crawl-ressourcer effektivt og forstå din indholdshierarki.
Tekniske barrierer og løsninger
Ud over konfigurationsfiler kan flere tekniske barrierer forhindre AI-crawlere i effektivt at tilgå dit indhold. JavaScript-rendering er fortsat den største udfordring, da moderne webframeworks som React, Vue og Angular dynamisk renderer indhold i browseren, hvilket efterlader AI-crawlere med tom HTML. Cloudflare og lignende sikkerhedsværktøjer blokerer ofte AI-crawlere som standard og betragter deres høje forespørgselsmængde som potentielle angreb. Ratelimitering kan forhindre fuld indeksering, og kompleks sitearkitektur samt dynamisk indholdsindlæsning gør crawleradgang endnu sværere. Heldigvis findes der flere løsninger på disse barrierer.
Løsninger til at forbedre AI-crawleradgang:
Implementér prerendering eller statisk HTML-servering – Generér statiske versioner af JavaScript-renderede sider til crawlere
Konfigurér Cloudflare og sikkerhedsværktøjer korrekt – Whitelist legitime AI-crawlere, mens du beskytter mod ondsindede bots
Optimer sitearkitektur – Gør URL-strukturer enklere og forbedr intern linkning for nemmere navigation
Implementér lazy loading-detektion – Sikr, at dynamisk indlæst indhold er tilgængeligt for crawlere
Brug AI-crawler enablement-platforme – Tjenester som Alli AI opdager og serverer automatisk optimeret indhold til AI-crawlere
Overvåg serverlogs – Spor crawleraktivitet for at identificere og løse adgangsproblemer
Sæt passende crawl delays – Giv tilstrækkelig båndbredde til crawlerforespørgsler uden at overbelaste serveren
Opret AI-specifikke sitemaps – Prioritér værdifuldt indhold til AI-systemer adskilt fra traditionelle sitemaps
Indholdsekstraktion og semantisk struktur
AI-systemer skal ikke blot kunne tilgå dit indhold – de skal også kunne forstå det. Indholdsekstraktion handler om, hvor effektivt AI-crawlere kan analysere, forstå og udtrække meningsfuld information fra dine sider. Denne proces afhænger i høj grad af semantisk HTML-struktur, hvor korrekte overskrifthierarkier, beskrivende tekst og logisk opbygning formidler mening. Når dit indhold er velstruktureret med tydelige overskrifter (H1, H2, H3), beskrivende afsnit og logisk flow, kan AI-systemer lettere identificere nøgledetaljer og forstå konteksten. Derudover giver schema markup maskinlæsbare metadata, der eksplicit fortæller AI-systemer, hvad dit indhold handler om, hvilket markant forbedrer forståelsen og sandsynligheden for at blive citeret.
Korrekt semantisk struktur inkluderer også brugen af semantiske HTML-elementer som <article>, <section>, <nav> og <aside> frem for generiske <div>-tags. Dette hjælper AI-systemer med at forstå formål og vigtighed af forskellige indholdssektioner. Når det kombineres med strukturerede data som FAQ-schema, produktschema eller organisationsschema, bliver dit indhold meget mere tilgængeligt for AI-systemer og øger chancen for at blive inkluderet i AI-genererede svar.
Overvågnings- og verifikationsværktøjer
Når forbedringerne er implementeret, skal du verificere, at AI-crawlere faktisk kan tilgå dit indhold, og løbende overvåge ydeevnen. Serverlogs giver direkte beviser på crawleraktivitet og viser, hvilke bots der har besøgt dit site, hvilke sider de har tilgået, og om de stødte på fejl. Google Search Console giver indblik i, hvordan Googles crawlere interagerer med dit site, mens specialiserede AI-synlighedsovervågningsværktøjer følger med i, hvordan dit indhold vises på tværs af forskellige AI-platforme. AmICited.com overvåger specifikt, hvordan AI-systemer nævner dit brand på ChatGPT, Perplexity og Google AI Overviews, og giver overblik over, hvilke af dine sider der bliver citeret og hvor ofte.
Værktøjer og metoder til overvågning af AI-crawleradgang:
Serverloganalyse – Gennemgå access logs for GPTBot, ClaudeBot, PerplexityBot og andre AI-crawler-brugeragenter
Google Search Console – Følg crawlstatistik, dækning og indekseringsstatus
Robots.txt-testværktøjer – Kontrollér, at din robots.txt-fil er korrekt konfigureret og tilgængelig
Schema markup-valideringsværktøjer – Test implementering af strukturerede data via Schema.org validator
AmICited.com – Spor AI-brandmentions og citater på større AI-platforme
Skræddersyede overvågningsdashboards – Sæt alarmer op for crawleraktivitet og tilgangsanomali
Crawlsimuleringsværktøjer – Test, hvordan bestemte crawlere interagerer med dit site, inden de besøger det
Best practices for AI-tilgængelighed
At optimere dit website for AI-crawleradgang kræver en strategisk og løbende tilgang. I stedet for at behandle AI-tilgængelighed som et engangsprojekt, implementerer de mest succesfulde organisationer kontinuerlig overvågning og forbedring. Den mest effektive strategi kombinerer korrekt teknisk konfiguration med indholdsoptimering, så både din infrastruktur og dit indhold er AI-klart.
Do’s for AI-tilgængelighed:
✅ Tillad eksplicit store AI-crawlere i din robots.txt-fil
✅ Opret og vedligehold opdaterede XML-sitemaps med prioritetsmetadata
✅ Implementér schema markup for nøgleindholdstyper (FAQ, HowTo, Produkt, Organisation)
✅ Brug semantisk HTML med korrekte overskrifthierarkier og logisk struktur
✅ Overvåg serverlogs regelmæssigt for at spore crawleraktivitet og identificere problemer
✅ Test din konfiguration med flere valideringsværktøjer før implementering
✅ Hold indholdet frisk og opdater lastmod-datoer i sitemaps
✅ Implementér prerendering eller statisk HTML-servering for JavaScript-tunge sites
✅ Konfigurér sikkerhedsværktøjer til at whitelist’e legitime AI-crawlere
Don’ts for AI-tilgængelighed:
❌ Bloker ikke alle AI-crawlere uden at forstå forretningskonsekvensen
❌ Stol ikke kun på “User-agent: *"-regler – konfigurer eksplicit de store AI-crawlere
❌ Brug ikke for restriktive robots.txt-regler, der utilsigtet blokerer legitime bots
❌ Ignorér ikke JavaScript-rendering-problemer på moderne webframeworks
❌ Glem ikke at opdatere robots.txt og sitemaps, når din sitearkitektur ændres
❌ Antag ikke, at alle crawlere respekterer robots.txt – nogle ignorerer den
❌ Forsøm ikke sikkerheden – balancér AI-tilgængelighed med beskyttelse mod ondsindede bots
❌ Lav ikke sitemaps med forældet eller duplikeret indhold
Den mest succesfulde AI-tilgængelighedsstrategi betragter crawlere som partnere i indholdsdistribution frem for trusler, der skal blokeres. Ved at sikre, at dit website er teknisk sundt, korrekt konfigureret og semantisk tydeligt, maksimerer du sandsynligheden for, at AI-systemer vil opdage, forstå og citere dit indhold i deres svar til brugerne.
Ofte stillede spørgsmål
Hvad er forskellen på en AI-tilgængelighedsrevision og en traditionel SEO-revision?
AI-tilgængelighedsrevisioner fokuserer på semantisk struktur, maskinlæsbare indhold og citationsværdighed for AI-systemer, hvorimod traditionelle SEO-revisioner lægger vægt på søgeord, backlinks og søgerangeringer. AI-revisioner undersøger, om crawlere kan tilgå og forstå dit indhold, mens SEO-revisioner fokuserer på rangeringsfaktorer for Googles søgeresultater.
Hvordan ved jeg, om AI-crawlere kan tilgå mit website?
Tjek dine serverlogs for AI-crawler-brugeragenter som GPTBot, ClaudeBot og PerplexityBot. Brug Google Search Console til at overvåge crawlaktivitet, test din robots.txt-fil med valideringsværktøjer, og brug specialiserede platforme som AmICited til at følge med i, hvordan AI-systemer nævner dit indhold på tværs af forskellige platforme.
Hvad er de mest almindelige barrierer, der forhindrer AI-crawleradgang?
De mest almindelige barrierer omfatter JavaScript-renderingbegrænsninger (AI-crawlere kan ikke køre JavaScript), Cloudflare og sikkerhedsværktøjsblokering (35% af virksomhedssites blokerer AI-crawlere), ratelimitering, der forhindrer fuld indeksering, kompleks sitearkitektur og dynamisk indlæsning af indhold. Hver barriere kræver forskellige løsninger.
Bør jeg blokere eller tillade AI-crawlere på mit website?
De fleste virksomheder har gavn af at tillade AI-crawlere, da de øger brandsynligheden i AI-drevne søgeresultater og samtalegrænseflader. Beslutningen afhænger dog af din indholdsstrategi, konkurrencemæssige positionering og forretningsmål. Du kan bruge robots.txt til selektivt at tillade visse crawlere, mens du blokerer andre efter dine specifikke behov.
Hvor ofte bør jeg udføre en AI-tilgængelighedsrevision?
Gennemfør en omfattende revision kvartalsvis eller hver gang, du foretager væsentlige ændringer i din sitearkitektur, indholdsstrategi eller sikkerhedskonfiguration. Overvåg crawleraktivitet løbende via serverlogs og specialværktøjer. Opdater din robots.txt og dine sitemaps, hver gang du lancerer nye indholdssektioner eller ændrer URL-strukturer.
Hvad er forholdet mellem robots.txt og AI-crawleradgang?
Robots.txt er din primære mekanisme til at styre AI-crawleradgang. Korrekt konfiguration tillader eksplicit store AI-crawlere (GPTBot, ClaudeBot, PerplexityBot), samtidig med at følsomme områder beskyttes. Forkert konfigureret robots.txt kan fuldstændigt blokere AI-crawlere, så dit indhold bliver usynligt for AI-systemer uanset kvaliteten.
Kan jeg forbedre min AI-synlighed uden tekniske ændringer?
Teknisk optimering er vigtig, men du kan også forbedre AI-synlighed gennem indholdsoptimering—ved at bruge semantisk HTML-struktur, implementere schema markup, forbedre intern linkstruktur og sikre indholdskomplethed. Tekniske barrierer som JavaScript-rendering og sikkerhedsværktøjsblokering kræver dog typisk tekniske løsninger for fuld AI-tilgængelighed.
Hvilke værktøjer kan jeg bruge til at revidere mit websites AI-tilgængelighed?
Brug serverloganalyse til at spore crawleraktivitet, Google Search Console til crawlstatistik, robots.txt-valideringsværktøjer til at kontrollere konfiguration, schema markup-valideringsværktøjer til strukturerede data og specialiserede platforme som AmICited til at overvåge AI-citater. Mange SEO-værktøjer som Screaming Frog tilbyder også crawler-simuleringsfunktioner til test af AI-tilgængelighed.
Overvåg din AI-synlighed på alle platforme
Følg med i, hvordan ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer nævner dit brand med AmICited. Få realtidsindsigt i din AI-søgesynlighed og optimer din indholdsstrategi.
Hvad er et AI-indholdsrevision, og hvorfor har dit brand brug for det?
Lær hvad en AI-indholdsrevision er, hvordan den adskiller sig fra traditionelle indholdsrevisioner, og hvorfor overvågning af dit brands tilstedeværelse i AI-sø...
Er der nogen, der har lavet et AI-indholdsrevision? Hvad lærte du egentlig?
Fællesskabsdiskussion om at udføre AI-indholdsrevisioner. Ægte erfaringer fra indholdsteams om, hvad de lærte om deres indholds AI-synlighed, og hvad man bør gø...
Lær hvad en indholdsrevision er, hvorfor det er vigtigt for SEO og brand-synlighed, og hvordan du systematisk udfører en for at optimere dit websiteindholds yde...
12 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.