Definition af AI-indholdsdetektion
AI-indholdsdetektion er processen med at bruge specialiserede algoritmer, maskinlæringsmodeller og teknikker til naturlig sprogbehandling til at analysere digitalt indhold og afgøre, om det er skabt af kunstige intelligenssystemer eller skrevet af mennesker. Disse detektionsværktøjer undersøger sproglige mønstre, statistiske egenskaber og semantiske karakteristika ved tekst, billeder og video for at klassificere indhold som AI-genereret, menneskeskrevet eller en hybrid kombination af begge. Teknologien er blevet stadig mere kritisk, efterhånden som generative AI-systemer som ChatGPT, Claude, Gemini og Perplexity producerer stadig mere sofistikeret indhold, der tæt efterligner menneskelig skrivning. AI-indholdsdetektion tjener flere brancher, herunder uddannelse, forlagsvirksomhed, rekruttering, content marketing og brandovervågningsplatforme, der har behov for at verificere indholdets ægthed og følge, hvordan brands fremstår på tværs af AI-drevne søge- og svarsystemer.
Kontekst og baggrund
Fremkomsten af avancerede generative AI-modeller i 2022-2023 skabte et akut behov for pålidelige detektionsmekanismer. Som forskere ved Stanford HAI rapporterede, brugte 78% af organisationerne AI i 2024, op fra 55% året før, hvilket skabte massive mængder AI-genereret indhold på internettet. I 2026 anslår eksperter, at 90% af onlineindholdet kan være AI-genereret, hvilket gør detektionsevner essentielle for at opretholde indholdsintegritet og ægthedsverifikation. AI-detektormarkedet oplever eksplosiv vækst, værdisat til 583,6 milliarder USD i 2025 og forventes at vokse med en årlig vækstrate på 27,9% til 3.267,5 milliarder USD i 2032. Denne markedsudvidelse afspejler stigende efterspørgsel fra uddannelsesinstitutioner, der er bekymrede for akademisk integritet, forlag, der ønsker at opretholde kvalitetsstandarder, og virksomheder, der kræver verifikation af indholdets ægthed. Udviklingen af AI-indholdsdetektionsværktøjer repræsenterer et kritisk våbenkapløb mellem detektionsteknologi og stadig mere sofistikerede AI-modeller, der er designet til at undgå detektion gennem mere menneskelignende skrivemønstre.
Sådan fungerer AI-indholdsdetektion
AI-indholdsdetektion fungerer gennem en sofistikeret kombination af maskinlæring og teknikker til naturlig sprogbehandling. Den grundlæggende tilgang involverer træning af klassifikatorer—maskinlæringsmodeller, der kategoriserer tekst i forudbestemte kategorier som “AI-skrevet” og “menneske-skrevet”. Disse klassifikatorer trænes på enorme datasæt, der indeholder millioner af dokumenter mærket som enten AI-genereret eller menneskeskabt, så de kan lære de karakteristiske mønstre, der adskiller de to kategorier. Detektionsprocessen analyserer flere sproglige træk, herunder ordhyppighed, sætningslængde, grammatisk kompleksitet og semantisk sammenhæng. Embeddings spiller en afgørende rolle i denne proces ved at konvertere ord og sætninger til numeriske vektorer, der fanger betydning, kontekst og relationer mellem begreber. Denne matematiske repræsentation gør det muligt for AI-systemer at forstå semantiske relationer—f.eks. at genkende, at “konge” og “dronning” deler konceptuel nærhed, selvom de er forskellige ord.
To nøglemetrikker, som AI-indholdsdetektionsværktøjer måler, er perplexity og burstiness. Perplexity fungerer som et “overraskelsesmåler”, der vurderer, hvor forudsigelig en tekst er; AI-genereret indhold udviser typisk lav perplexity, fordi sprogmodeller er trænet til at producere statistisk sandsynlige ordsekvenser, hvilket resulterer i forudsigelige og ensartede skrivemønstre. Til sammenligning indeholder menneskelig skrivning flere uventede ordvalg og kreative udtryk, hvilket giver højere perplexity-score. Burstiness måler variationen i sætningslængde og strukturel kompleksitet gennem et dokument. Menneskelige skribenter veksler naturligt mellem korte, slagkraftige sætninger og længere, mere komplekse konstruktioner, hvilket skaber høj burstiness. AI-systemer, der er begrænset af deres forudsigelsesalgoritmer, har en tendens til at generere mere ensartede sætningsstrukturer med lavere burstiness. Førende detektionsplatforme som GPTZero er gået videre end disse to metrikker og anvender multilagede systemer med syv eller flere komponenter til at bestemme AI-sandsynlighed, herunder klassifikation på sætningniveau, internettekst-søgeverifikation og forsvar mod detektionsundvigelsesteknikker.
| Detektionsmetode | Sådan fungerer det | Styrker | Begrænsninger |
|---|
| Perplexity & Burstiness-analyse | Måler forudsigelighed og variationsmønstre i sætninger | Hurtig, computer-effektiv, grundlæggende tilgang | Kan give falske positiver ved formel skrivning; begrænset nøjagtighed ved korte tekster |
| Maskinlæringsklassifikatorer | Trænet på mærkede datasæt til at kategorisere AI vs. mennesketekst | Meget nøjagtig på træningsdata, tilpasselig til nye modeller | Kræver løbende gen-træning; har svært ved nye AI-arkitekturer |
| Embeddings & Semantisk analyse | Konverterer tekst til numeriske vektorer for at analysere betydning og relationer | Fanger nuancerede semantiske mønstre, forstår kontekst | Computerkraftkrævende; kræver store træningsdatasæt |
| Vandmærkningsmetode | Indlejrer skjulte signaler i AI-genereret tekst under skabelsen | Teoretisk ufejlbarlig hvis implementeret ved generering | Let fjernet ved redigering; ikke branchestandard; kræver AI-modellens samarbejde |
| Multimodal detektion | Analyserer tekst, billeder og video samtidigt for AI-signaturer | Omfattende dækning på tværs af indholdstyper | Kompleks implementering; kræver specialtræning for hver modalitet |
| Internettekst-søgning | Sammenligner indhold mod databaser af kendte AI-output og internetarkiver | Identificerer plagieret eller genbrugt AI-indhold | Begrænset til tidligere indekseret indhold; overser nye AI-generationer |
Teknisk arkitektur af AI-detekteringssystemer
Det tekniske fundament for AI-indholdsdetektion bygger på deep learning-arkitekturer, der bearbejder tekst gennem flere lag af analyse. Moderne detektionssystemer anvender transformer-baserede neurale netværk svarende til dem, der bruges i generative AI-modeller, hvilket gør dem i stand til at forstå komplekse sproglige mønstre og kontekstuelle relationer. Detektionsprocessen starter typisk med forbehandling af tekst, hvor indholdet opdeles i individuelle ord eller delord-enheder. Disse tokens konverteres derefter til embeddings—tætte numeriske repræsentationer, der indfanger semantisk betydning. Embeddings strømmer gennem flere neurale netværkslag, der udtrækker stadigt mere abstrakte træk, fra simple ordniveau-mønstre til komplekse dokumentniveau-karakteristika. Et afsluttende klassifikationslag producerer en sandsynlighedsscore, der angiver, hvor sandsynligt det er, at indholdet er AI-genereret. Avancerede systemer som GPTZero implementerer klassifikation på sætningsniveau, hvor hver sætning analyseres individuelt for at identificere, hvilke dele af et dokument der udviser AI-karakteristika. Denne detaljerede tilgang giver brugerne feedback om, hvilke specifikke afsnit der sandsynligvis er AI-genererede, i stedet for blot en binær klassifikation af hele dokumentet.
Udfordringen med at opretholde detektionsnøjagtighed i takt med, at AI-modeller udvikler sig, har ført til udviklingen af dynamiske detektionsmodeller, der kan tilpasse sig i realtid til nye AI-systemer. I stedet for at stole på statiske benchmarks, der hurtigt forældes, inkorporerer disse systemer løbende output fra de nyeste AI-modeller—herunder GPT-4o, Claude 3, Gemini 1.5 og fremspirende systemer—i deres træningspipeline. Denne tilgang stemmer overens med nye gennemsigtighedsretningslinjer fra OECD og UNESCO om ansvarlig AI-udvikling. De mest avancerede detektionsplatforme opretholder 1.300+ lærerambassadør-fællesskaber og samarbejder med uddannelsesinstitutioner for at forfine detektionsalgoritmer i virkelige anvendelser, så værktøjerne forbliver effektive, efterhånden som både AI-generering og detektionsteknikker udvikler sig.
Nøjagtighed, pålidelighed og begrænsninger
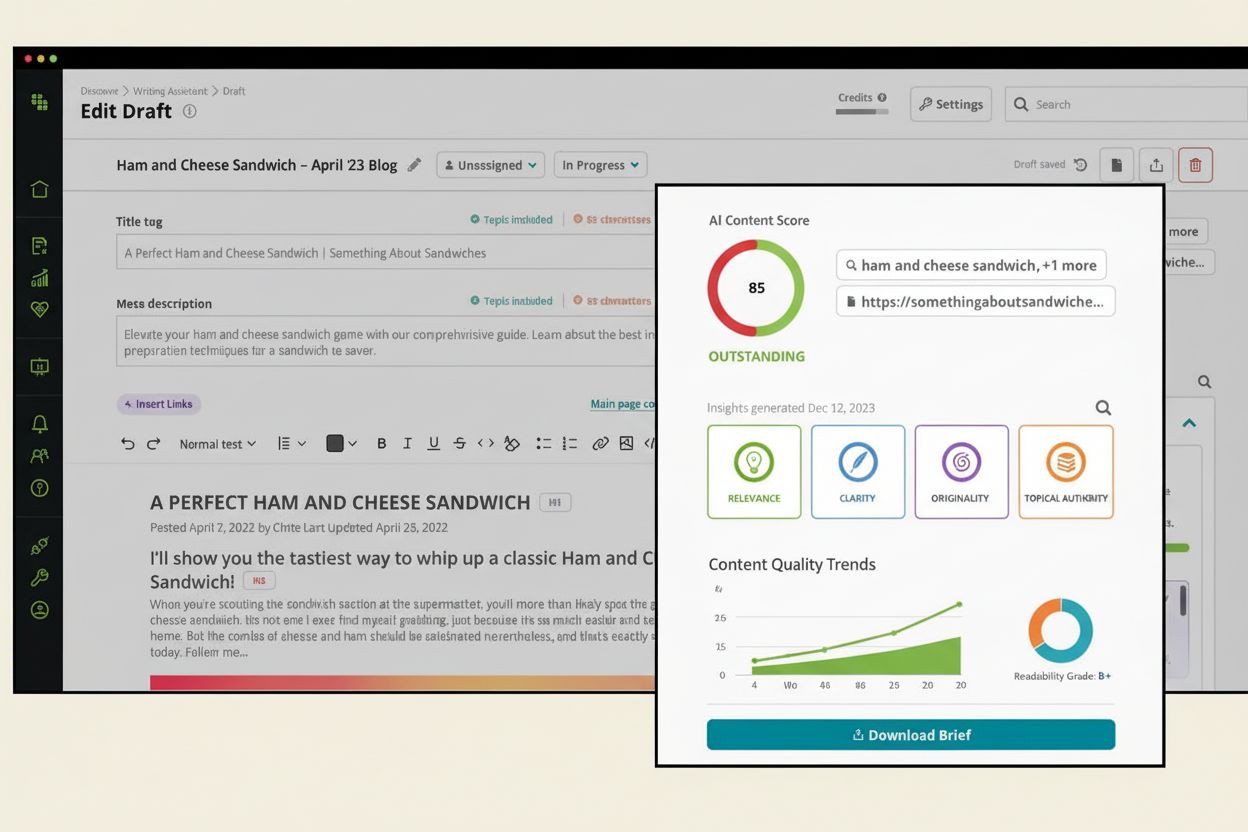
AI-indholdsdetektionsværktøjer har opnået imponerende nøjagtighedsrater i kontrollerede testmiljøer. Førende platforme rapporterer 99% nøjagtighedsrater med falsk positive rater så lave som 1%, hvilket betyder, at de korrekt identificerer AI-genereret indhold og minimerer risikoen for fejlagtigt at markere menneskeskabt materiale. Uafhængige tredjepartsbenchmarks som RAID-datasættet—bestående af 672.000 tekster på tværs af 11 domæner, 12 sprogmodeller og 12 modangreb—har valideret disse påstande, hvor topdetektorer opnår 95,7% nøjagtighed i identifikation af AI-skrevet tekst og kun fejlklassificerer 1% af menneskelig skrivning. Dog kommer disse imponerende statistikker med vigtige forbehold. Ingen AI-detektor er 100% nøjagtig, og præstationen i virkeligheden adskiller sig ofte fra kontrollerede testscenarier. Pålideligheden varierer betydeligt afhængigt af tekstlængde, indholdsområde, sprog og om det AI-genererede indhold er blevet redigeret eller omformuleret.
Korte tekster udgør en særlig udfordring for AI-indholdsdetektion, da de indeholder færre sproglige mønstre at analysere. En enkelt sætning eller et kort afsnit kan mangle nok karakteristiske træk til pålideligt at skelne AI fra menneskelig forfatterskab. Forskning har vist, at omformulering af AI-genereret indhold via værktøjer som GPT-3.5 kan reducere detektionsnøjagtigheden med 54,83%, hvilket demonstrerer, at redigeret eller raffineret AI-indhold bliver væsentligt sværere at identificere. Flersproget indhold og tekst fra ikke-indfødte engelsktalende udgør en anden betydelig begrænsning, da de fleste detektionsværktøjer primært er trænet på engelsksprogede datasæt. Dette kan føre til bias mod ikke-indfødte brugere, hvis skrivemønstre kan afvige fra indfødte engelske konventioner og udløse falske positiver. Derudover, efterhånden som AI-modeller bliver stadig mere sofistikerede og trænet på alsidig, høj-kvalitets mennesketekst, mindskes de sproglige forskelle mellem AI og menneskelig skrivning, hvilket gør detektion gradvist sværere.
AI-indholdsdetektion er blevet uundværlig på tværs af mange sektorer og brugsscenarier. Inden for uddannelse bruger institutioner detektionsværktøjer til at opretholde akademisk integritet ved at identificere elevarbejde, der kan være genereret eller kraftigt assisteret af AI-systemer. En Pew Research-undersøgelse viste, at 26% af amerikanske teenagere rapporterede at have brugt ChatGPT til skolearbejde i 2024, dobbelt så mange som året før, hvilket gør detektionsevner kritiske for undervisere. Forlag og medieorganisationer anvender detektionsværktøjer for at sikre redaktionel kvalitet og overholde Googles 2025 Search Quality Rater Guidelines, der kræver gennemsigtighed om AI-genereret indhold. Rekrutteringsfolk bruger detektion til at verificere, at ansøgningsmateriale, ansøgninger og personlige udtalelser faktisk er skrevet af kandidaterne selv og ikke genereret af AI. Indholdsskabere og tekstforfattere gennemgår deres arbejde med detektionsværktøjer før udgivelse for at undgå at blive markeret af søgemaskiner eller algoritmer og sikre, at deres indhold anerkendes som menneskeskabt og originalt.
For brandovervågnings- og AI-trackingplatforme som AmICited spiller AI-indholdsdetektion en specialiseret, men kritisk rolle. Disse platforme overvåger, hvordan brands fremstår i svar fra ChatGPT, Perplexity, Google AI Overviews og Claude, og følger citater og omtaler på tværs af AI-systemer. Detektionsevner hjælper med at verificere, om brandreferencer er autentisk menneskeskabt indhold eller AI-syntetiseret materiale, hvilket sikrer korrekt brandomdømmeovervågning. Forensiske analytikere og juridiske fagfolk bruger detektionsværktøjer til at verificere ophavet til omstridte dokumenter i undersøgelser og retssager. AI-forskere og udviklere anvender detektionssystemer til at undersøge, hvordan detektion fungerer og til at træne fremtidige AI-modeller mere ansvarligt, idet de forstår, hvad der gør skrivning detekterbar, så de kan designe systemer, der fremmer gennemsigtighed og etisk AI-udvikling.
Centrale detektionsindikatorer og mønstre
AI-indholdsdetektionssystemer identificerer flere karakteristiske mønstre, der kendetegner AI-genereret skrivning. Gentagelse og redundans optræder ofte i AI-tekst, hvor de samme ord, vendinger eller ideer gentages flere gange på lidt forskellige måder. Overdrevent høfligt og formelt sprog er almindeligt, fordi generative AI-systemer er designet til at være “venlige assistenter” og som udgangspunkt bruger formelle, høflige vendinger, medmindre andet er angivet. AI-genereret indhold mangler ofte samtaletone og naturlige talemåder, der kendetegner ægte menneskelig kommunikation. Usikker sprogbrug forekommer ofte, idet AI har tendens til at bruge passive konstruktioner og forbeholdne vendinger som “Det er vigtigt at bemærke, at”, “Nogle vil måske sige” eller “X anses ofte for at være”, i stedet for at komme med dristige, selvsikre udsagn. Inkonsistens i stemme og tone kan opstå, når AI forsøger at efterligne en bestemt forfatters stil uden tilstrækkelig kontekst eller træningsdata. Underbrug af stilistiske elementer som metaforer, sammenligninger og analogier er karakteristisk for AI-skrivning, som tenderer mod bogstaveligt, forudsigeligt sprog. Logiske eller faktuelle fejl og “hallucinationer”—hvor AI genererer troværdigt lydende men falsk information—kan indikere AI-forfatterskab, selvom menneskelige forfattere også laver fejl.
- Perplexity-analyse: Vurderer forudsigeligheden af ordvalg og sætningsstrukturer
- Burstiness-måling: Vurderer variationen i sætningslængde og kompleksitet
- Semantisk sammenhængsevaluering: Analyserer logisk flow og konceptuelle relationer
- Sprogligt mønstergenkendelse: Identificerer karakteristiske ordhyppigheder og grammatiske strukturer
- Embeddings-baseret analyse: Konverterer tekst til numeriske vektorer for mønstergenkendelse
- Klassifikation på sætningsniveau: Marker individuelle sætninger eller afsnit som AI-sandsynlige
- Internettekst-søgning: Sammenligner indhold mod databaser af kendte AI-output
- Modstandsdygtighed mod modangreb: Tester detektionsrobusthed mod omformulering og synonymudskiftning
- Multimodal analyse: Undersøger billeder og video for AI-generationssignaturer
- Realtidsmodel-tilpasning: Opdaterer detektionsalgoritmer, efterhånden som nye AI-systemer opstår
Skelnen mellem AI-detektion og plagiatkontrol
Der er en vigtig forskel mellem AI-indholdsdetektion og plagiatkontrol, selvom begge tjener formålet at sikre indholdsintegritet. AI-indholdsdetektion fokuserer på at bestemme hvordan indholdet blev skabt—specifikt om det blev genereret af kunstig intelligens eller skrevet af mennesker. Analysen undersøger tekstens struktur, ordvalg, sproglige mønstre og overordnede stil for at vurdere, om det matcher mønstre lært fra AI-genererede eller menneskeskabte eksempler. Plagiatkontroller derimod fokuserer på at afgøre hvor indholdet stammer fra—om teksten er kopieret fra eksisterende kilder uden kildeangivelse. Plagiatdetektion sammenligner indsendt indhold med store databaser af publicerede værker, akademiske artikler, hjemmesider og andre kilder for at identificere matchende eller lignende passager. International Center for Academic Integritys retningslinjer fra 2024 anbefaler at bruge begge værktøjer sammen for omfattende indholdsverifikation. En tekst kan være helt menneskeskabt, men plagieret fra en anden kilde, eller den kan være AI-genereret og original. Intet værktøj alene giver fuldstændig information om indholdets ægthed og originalitet; sammen skaber de et mere komplet billede af, hvordan indholdet blev skabt, og om det repræsenterer originalt arbejde.
Udvikling og fremtid for AI-detektionsteknologi
Udviklingen af AI-indholdsdetektion fortsætter med at gå hurtigt fremad, i takt med at både detektions- og unddragelsesteknikker forbedres. Vandmærkningsmetoder—at indlejre skjulte signaler i AI-genereret tekst under skabelsesprocessen—er fortsat teoretisk lovende, men står over for betydelige praktiske udfordringer. Vandmærker kan fjernes gennem redigering, omformulering eller oversættelse, og de kræver samarbejde fra AI-modeludviklere for at blive implementeret ved genereringen. Hverken OpenAI eller Anthropic har taget vandmærkning i brug som standardpraksis, hvilket begrænser den praktiske anvendelse. Fremtiden for detektion ligger sandsynligvis i multimodale systemer, der analyserer tekst, billeder og video samtidigt, i erkendelse af at AI-generering i stigende grad spænder over flere indholdstyper. Forskere udvikler dynamiske detektionsmodeller, der tilpasser sig i realtid til nye AI-arkitekturer i stedet for at stole på statiske benchmarks, der hurtigt forældes. Disse systemer vil indarbejde løbende læring fra det nyeste AI-output og sikre, at detektionsevnerne følger med den generative AI-udvikling.
Den mest lovende retning involverer at bygge gennemsigtighed og attribuering ind i AI-systemer fra starten i stedet for udelukkende at stole på efterfølgende detektion. Denne tilgang ville indlejre metadata, oprindelsesinformation og klar mærkning af AI-genereret indhold allerede ved skabelsen, hvilket gør detektion unødvendig. Indtil sådanne standarder bliver universelle, vil AI-indholdsdetektionsværktøjer dog forblive afgørende for at opretholde indholdsintegritet i uddannelse, forlagsvirksomhed, rekruttering og brandovervågning. Konvergensen mellem detektionsteknologi og brandovervågningsplatforme som AmICited repræsenterer en ny grænse, hvor detektionsevner muliggør præcis sporing af, hvordan brands fremstår i AI-genererede svar på tværs af flere platforme. Efterhånden som AI-systemer bliver mere udbredte i søgning, indholdsgenerering og informationslevering, vil evnen til pålideligt at detektere og overvåge AI-genereret indhold blive stadig mere værdifuld for organisationer, der ønsker at forstå deres tilstedeværelse i det AI-drevne informationsøkosystem.
Best practice for brug af AI-detekteringsværktøjer
Effektiv brug af AI-indholdsdetektion kræver forståelse for både kapaciteter og begrænsninger ved disse værktøjer. Organisationer bør anerkende begrænsningerne ved enhver enkelt detektor og erkende, at intet værktøj er ufejlbarligt, og at detektionsresultater bør betragtes som et enkelt bevis frem for endegyldigt bevis. Krydskontrol med flere værktøjer giver et mere pålideligt billede, da forskellige detektionssystemer kan give varierende resultater afhængig af deres træningsdata og algoritmer. At lære at genkende AI-skrivemønstre manuelt—forstå perplexity, burstiness, gentagelse og andre karakteristiske træk—muliggør en mere informeret fortolkning af detektorresultater. At tage hensyn til kontekst og hensigt er afgørende; et markeret resultat bør føre til nærmere undersøgelse af skrivestil, overensstemmelse med forfatterens kendte stemme og overensstemmelse med indholdets formål. Gennemsigtighed om detektion i akademiske og professionelle sammenhænge styrker tilliden og forhindrer overdreven afhængighed af automatisering. Brug af AI-detektion som del af en bredere originalitetskontrol, der også inkluderer plagiatkontroller, kildevalidering og kritisk menneskelig vurdering, giver den mest omfattende vurdering af indholdets ægthed. Den ansvarlige tilgang ser detektionsværktøjer som værdifulde assistenter, der supplerer menneskelig dømmekraft frem for at erstatte den, især i sammenhænge hvor falske positive eller negative kan have alvorlige konsekvenser for enkeltpersoner eller organisationer.
+++