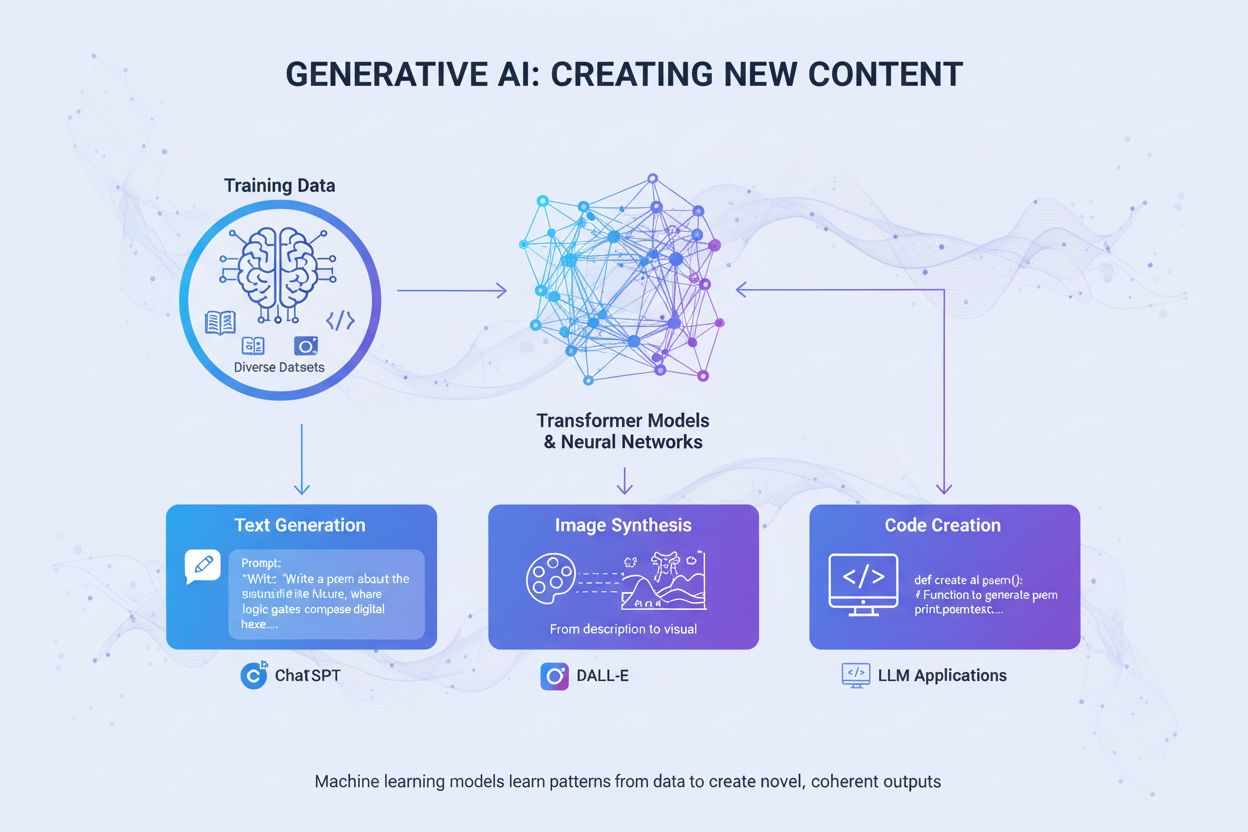
Generativ AI
Generativ AI skaber nyt indhold ud fra træningsdata ved hjælp af neurale netværk. Lær hvordan det fungerer, dets anvendelser i ChatGPT og DALL-E, og hvorfor ove...
11 min læsning
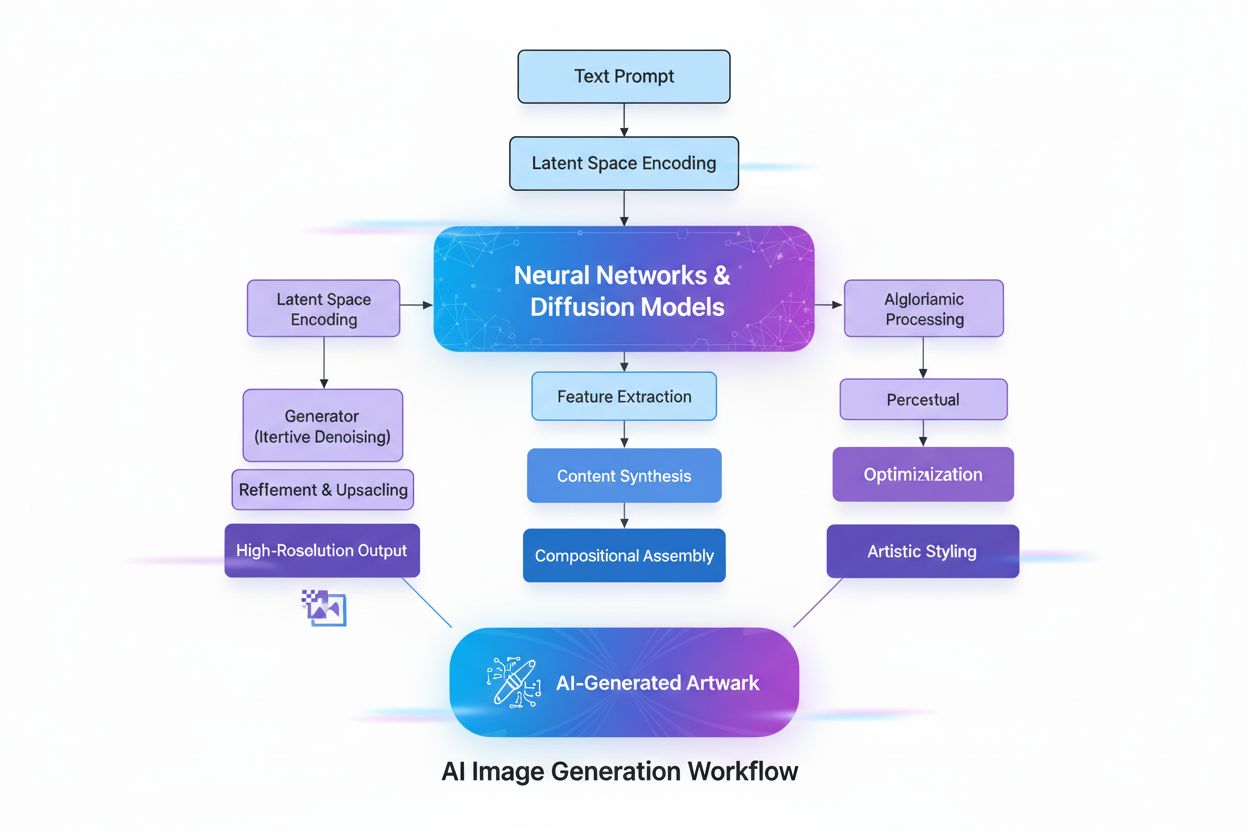
Et AI-genereret billede er et digitalt billede skabt af algoritmer for kunstig intelligens og maskinlæringsmodeller snarere end af menneskelige kunstnere eller fotografer. Disse billeder produceres ved at træne neurale netværk på enorme datasæt af mærkede billeder, hvilket gør det muligt for AI’en at lære visuelle mønstre og skabe originale, realistiske visuelle udtryk ud fra tekstprompter, skitser eller andre inputdata.
Et AI-genereret billede er et digitalt billede skabt af algoritmer for kunstig intelligens og maskinlæringsmodeller snarere end af menneskelige kunstnere eller fotografer. Disse billeder produceres ved at træne neurale netværk på enorme datasæt af mærkede billeder, hvilket gør det muligt for AI'en at lære visuelle mønstre og skabe originale, realistiske visuelle udtryk ud fra tekstprompter, skitser eller andre inputdata.
Et AI-genereret billede er et digitalt billede skabt af algoritmer for kunstig intelligens og maskinlæringsmodeller snarere end af menneskelige kunstnere eller fotografer. Disse billeder produceres gennem avancerede neurale netværk, der er trænet på store datasæt af mærkede billeder, hvilket gør det muligt for AI’en at lære visuelle mønstre, stilarter og relationer mellem begreber. Teknologien gør det muligt for AI-systemer at skabe originale, realistiske visuelle udtryk ud fra forskellige input—oftest tekstprompter, men også fra skitser, referencebilleder eller andre datakilder. I modsætning til traditionel fotografering eller manuelt kunstværk kan AI-genererede billeder fremstille alt tænkeligt, herunder umulige scenarier, fantasiverdener og abstrakte begreber, der aldrig har eksisteret i fysisk virkelighed. Processen er bemærkelsesværdig hurtig og producerer ofte billeder i høj kvalitet på få sekunder, hvilket gør det til en transformerende teknologi for kreative industrier, markedsføring, produktdesign og indholdsskabelse.
Rejsen for AI-billedgenerering begyndte med grundlæggende forskning i deep learning og neurale netværk, men teknologien blev først mainstream i begyndelsen af 2020’erne. Generative Adversarial Networks (GANs), introduceret af Ian Goodfellow i 2014, var blandt de første succesfulde tilgange og brugte to konkurrerende neurale netværk til at generere realistiske billeder. Det virkelige gennembrud kom dog med fremkomsten af diffusionsmodeller og transformer-baserede arkitekturer, som viste sig mere stabile og i stand til at producere resultater i højere kvalitet. I 2022 blev Stable Diffusion frigivet som en open source-model, hvilket demokratiserede adgangen til AI-billedgenerering og satte gang i udbredt adoption. Kort efter fik DALL-E 2 fra OpenAI og Midjourney betydelig opmærksomhed og bragte AI-billedgenerering ind i offentlighedens bevidsthed. Ifølge aktuelle statistikker er 71% af billeder på sociale medier nu AI-genererede, og det globale marked for AI-billedgeneratorer blev vurderet til 299,2 millioner dollars i 2023, med forventning om en årlig vækst på 17,4% frem til 2030. Denne eksplosive vækst afspejler både teknologisk modning og udbredt erhvervsadoption på tværs af brancher.
Skabelsen af AI-genererede billeder involverer flere avancerede tekniske processer, der arbejder sammen for at omsætte abstrakte begreber til visuel virkelighed. Processen begynder med tekstanalyse ved hjælp af Natural Language Processing (NLP), hvor AI’en konverterer menneskesprog til numeriske repræsentationer kaldet indlejringer. Modeller som CLIP (Contrastive Language-Image Pre-training) koder tekstprompter til højdimensionelle vektorer, der indfanger semantisk betydning og kontekst. Når en bruger for eksempel indtaster “et rødt æble på et træ,” nedbryder NLP-modellen dette til numeriske koordinater, der repræsenterer “rød,” “æble,” “træ” og deres rumlige relationer. Dette numeriske kort styrer så billedgenereringsprocessen og fungerer som et regelsæt, der fortæller AI’en, hvilke komponenter der skal indgå og hvordan de skal interagere.
Diffusionsmodeller, som driver mange moderne AI-billedgeneratorer, herunder DALL-E 2 og Stable Diffusion, arbejder gennem en elegant iterativ proces. Modellen starter med ren tilfældig støj—dybest set et kaotisk mønster af pixels—og forfiner det gradvist gennem flere afstøjningsskridt. Under træning lærer modellen at vende processen med at tilføje støj til billeder, altså at “afstøje” korrupte versioner tilbage til deres oprindelige form. Når der genereres nye billeder, anvender modellen denne indlærte afstøjningsproces omvendt, og starter med tilfældig støj, som gradvist omdannes til et sammenhængende billede. Tekstprompten guider denne transformation i hvert trin og sikrer, at det endelige resultat matcher brugerens beskrivelse. Denne trin-for-trin forfining muliggør exceptionel kontrol og skaber bemærkelsesværdigt detaljerede billeder i høj kvalitet.
Generative Adversarial Networks (GANs) benytter en grundlæggende anderledes tilgang baseret på spilteori. En GAN består af to konkurrerende neurale netværk: en generator, der skaber falske billeder ud fra tilfældig input, og en diskriminator, der forsøger at skelne mellem ægte og falske billeder. Disse netværk deltager i et modspil, hvor generatoren hele tiden forbedres for at narre diskriminatoren, mens diskriminatoren bliver bedre til at opdage falsknerier. Denne konkurrence driver begge netværk mod ekspertise og resulterer til sidst i billeder, der næsten ikke kan skelnes fra rigtige fotografier. GANs er særligt effektive til at generere fotorealistiske menneskeansigter og til stiloverførsel, selvom de kan være mindre stabile at træne end diffusionsmodeller.
Transformer-baserede modeller repræsenterer en anden stor arkitektur og tilpasser den transformer-teknologi, der oprindeligt blev udviklet til naturlig sprogbehandling. Disse modeller er fremragende til at forstå komplekse relationer inden for tekstprompter og kortlægge sprog til visuelle træk. De bruger selvopmærksomhedsmekanismer til at indfange kontekst og relevans, hvilket gør dem i stand til at håndtere nuancerede, flerledede prompts med høj præcision. Transformere kan generere billeder, der meget nøje matcher detaljerede tekstbeskrivelser, hvilket gør dem ideelle til applikationer, der kræver præcis kontrol over outputkarakteristika.
| Teknologi | Sådan fungerer det | Styrker | Svagheder | Bedste anvendelser | Eksempelværktøjer |
|---|---|---|---|---|---|
| Diffusionsmodeller | Iterativt afstøje tilfældig støj til strukturerede billeder guidet af tekstprompter | Høj-kvalitets detaljerede resultater, fremragende tekstoverensstemmelse, stabil træning, fin kontrol med forfining | Langsommere genereringsproces, kræver flere computerressourcer | Tekst-til-billede-generering, højtopløselig kunst, videnskabelige visualiseringer | Stable Diffusion, DALL-E 2, Midjourney |
| GANs | To konkurrerende neurale netværk (generator og diskriminator) skaber realistiske billeder gennem modspil | Hurtig generering, fremragende til fotorealisme, god til stiloverførsel og billedforbedring | Ustabil træning, mode collapse-problemer, mindre præcis tekstkontrol | Fotorealistiske ansigter, stiloverførsel, billedopskalering | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformere | Omdanner tekstprompter til billeder via selvopmærksomhed og token-indlejringer | Enestående tekst-til-billede-syntese, håndterer komplekse prompts godt, stærk semantisk forståelse | Kræver betydelige computerressourcer, nyere teknologi med mindre optimering | Kreativ billedgenerering fra detaljeret tekst, design og reklame, fantasifuld konceptkunst | DALL-E 2, Runway ML, Imagen |
| Neural stiloverførsel | Sammenfletter indhold fra et billede med kunstnerisk stil fra et andet | Kunstnerisk kontrol, bevarer indhold men overfører stil, fortolkelig proces | Begrænset til stiloverførsel, kræver referencebilleder, mindre fleksibel end andre metoder | Kunstnerisk billedskabelse, stilovertagelse, kreativ forbedring | DeepDream, Prisma, Artbreeder |
Adoptionen af AI-genererede billeder på tværs af erhvervssektorer har været bemærkelsesværdigt hurtig og omvæltende. Inden for e-handel og detailhandel bruger virksomheder AI-billedgenerering til at skabe produktfotografering i stor skala og eliminerer behovet for dyre fotosessions. Ifølge nyere data forventer 80% af detailchefer, at deres virksomheder vil bruge AI-automatisering inden 2025, og detailvirksomheder brugte 19,71 milliarder dollars på AI-værktøjer i 2023, hvor billedgenerering udgør en betydelig andel. Markedet for AI-billedredigering vurderes til 88,7 milliarder dollars i 2025 og forventes at nå 8,9 milliarder dollars i 2034, hvor erhvervsbrugere står for ca. 42% af alle udgifter.
Inden for markedsføring og reklame bruger 62% af marketingfolk AI til at skabe nye billedaktiver, og virksomheder, der bruger AI til indholdsskabelse på sociale medier, rapporterer om 15-25% stigning i engagementrater. Muligheden for hurtigt at generere mange kreative variationer muliggør A/B-testning i hidtil uset skala og giver marketingfolk mulighed for at optimere kampagner med datadrevet præcision. Cosmopolitan-magasin vakte opsigt i juni 2022 ved at udgive et cover skabt udelukkende af DALL-E 2—første gang et større medie brugte AI-genereret billedmateriale som forside. Prompten, der blev brugt, lød: “A wide angle shot from below of a female astronaut with an athletic female body walking with swagger on Mars in an infinite universe, synthwave, digital art.”
Inden for medicinsk billeddannelse udforskes AI-genererede billeder til diagnostiske formål og syntetisk datagenerering. Forskning har vist, at DALL-E 2 kan generere realistiske røntgenbilleder ud fra tekstprompter og endda rekonstruere manglende elementer i radiologiske billeder. Denne evne har stor betydning for medicinsk uddannelse, datasikker deling mellem institutioner og udvikling af nye diagnostiske værktøjer. Markedet for AI-drevne sociale medier forventes at nå 12 milliarder dollars i 2031, op fra 2,1 milliarder dollars i 2021, hvilket afspejler teknologiens centrale rolle i indholdsskabelse på digitale platforme.
Den hurtige udbredelse af AI-genererede billeder har givet anledning til betydelige etiske og juridiske bekymringer, som branchen og myndigheder stadig kæmper med. Ophavsret og immaterielle rettigheder er måske den mest omstridte udfordring. De fleste AI-billedgeneratorer trænes på store datasæt af billeder hentet fra internettet, hvoraf mange er ophavsretligt beskyttede værker skabt af kunstnere og fotografer. I januar 2023 anlagde tre kunstnere et banebrydende søgsmål mod Stability AI, Midjourney og DeviantArt og hævdede, at virksomhederne brugte ophavsretligt beskyttede billeder til at træne deres algoritmer uden samtykke eller kompensation. Denne sag eksemplificerer den bredere konflikt mellem teknologisk innovation og kunstnerrettigheder.
Spørgsmålet om ejerskab og rettigheder til AI-genererede billeder er stadig juridisk uklart. Da et AI-genereret kunstværk vandt førsteprisen ved Colorado State Fairs kunstkonkurrence i 2022, indsendt af Jason Allen via Midjourney, opstod der stor debat. Mange mente, at da AI havde skabt værket, skulle det ikke kvalificere som original menneskelig skabelse. Det amerikanske ophavsretskontor har angivet, at værker skabt udelukkende af AI uden menneskelig kreativ indgriben måske ikke kvalificerer sig til ophavsret, men dette er et område under udvikling med verserende retssager og regulering.
Deepfakes og misinformation udgør en anden væsentlig bekymring. AI-billedgeneratorer kan skabe meget realistiske billeder af begivenheder, der aldrig har fundet sted, og dermed muliggøre spredning af falske informationer. I marts 2023 spredte AI-genererede deepfake-billeder, der viste en falsk anholdelse af tidligere præsident Donald Trump, sig på sociale medier, skabt med Midjourney. Disse billeder blev i første omgang opfattet som ægte af nogle brugere, hvilket demonstrerer teknologiens potentiale for ondsindet misbrug. Den voksende sofistikering af AI-genererede billeder gør det sværere at afsløre dem, hvilket skaber udfordringer for sociale medier og nyhedsmedier i kampen for at bevare indholdsautenticitet.
Bias i træningsdata er endnu et betydeligt etisk problem. AI-modeller lærer af datasæt, der kan indeholde kulturelle, kønsmæssige og racemæssige skævheder. Gender Shades-projektet, ledet af Joy Buolamwini ved MIT Media Lab, afslørede betydelige skævheder i kommercielle AI-systemer til kønsklassificering, hvor fejlprocenter for mørkhudede kvinder var væsentligt højere end for lyshudede mænd. Tilsvarende bias kan forekomme i billedgenerering og potentielt videreføre skadelige stereotyper eller underrepræsentere visse grupper. At adressere denne bias kræver omhyggelig kuratering af datasæt, diversitet i træningsdata og løbende evaluering af output.
Kvaliteten af AI-genererede billeder afhænger i høj grad af kvaliteten og præcisionen i inputprompten. Prompt engineering—kunsten at udforme effektive tekstbeskrivelser—er blevet en afgørende færdighed for brugere, der ønsker optimale resultater. Effektive prompts har flere fællestræk: de er specifikke og detaljerede frem for vage, inkluderer stil- eller mediebeskrivelser (såsom “digitalt maleri”, “akvarel” eller “fotorealistisk”), indeholder atmosfære- og lysinformation (f.eks. “gyldent time”, “cinematisk belysning” eller “dramatiske skygger”) og fastlægger klare relationer mellem elementerne.
I stedet for blot at bede om “en kat” kan en mere effektiv prompt for eksempel lyde: “en fluffy orange tabbykat, der sidder på en vindueskarm ved solnedgang, varmt gyldent lys strømmer ind gennem vinduet, fotorealistisk, professionel fotografering.” Dette detaljeringsniveau giver AI’en specifik vejledning om udseende, miljø, lys og ønsket æstetik. Forskning viser, at strukturerede prompts med tydelige informationshierarkier giver mere konsistente og tilfredsstillende resultater. Brugere benytter ofte teknikker som at specificere kunstneriske stilarter, tilføje beskrivende adjektiver, inkludere tekniske fotografiske termer og endda referere til specifikke kunstnere eller kunstretninger for at guide AI’en mod det ønskede output.
Forskellige AI-billedgenereringsplatforme har forskellige egenskaber, styrker og anvendelser. DALL-E 2, udviklet af OpenAI, genererer detaljerede billeder ud fra tekstprompter med avancerede inpainting- og redigeringsmuligheder. Den fungerer efter et kreditbaseret system, hvor brugere køber credits til billedgenereringer. DALL-E 2 er kendt for sin alsidighed og evne til at håndtere komplekse, nuancerede prompts, hvilket gør den populær blandt professionelle og kreative.
Midjourney fokuserer på kunstnerisk og stiliseret billedskabelse og foretrækkes af designere og kunstnere for dets unikke æstetiske udtryk. Platformen fungerer via en Discord-bot, hvor brugerne indtaster prompts gennem kommandoen /imagine. Midjourney er især kendt for at skabe visuelt tiltalende, maleriske billeder med komplementære farver, balanceret belysning og skarpe detaljer. Platformen tilbyder abonnementer fra $10 til $120 pr. måned, hvor højere niveauer giver flere billedgenereringer.
Stable Diffusion, udviklet i samarbejde mellem Stability AI, EleutherAI og LAION, er en open source-model, der demokratiserer AI-billedgenerering. Dens open source-karakter gør det muligt for udviklere og forskere at tilpasse og implementere modellen, hvilket gør den ideel til eksperimentelle projekter og virksomhedsbrug. Stable Diffusion bygger på en latent diffusionsmodelarkitektur, der muliggør effektiv generering på forbrugergrafikkort. Platformen er konkurrencedygtigt prissat til $0,0023 pr. billede med gratis prøveperioder til nye brugere.
Googles Imagen er endnu en betydelig aktør, der tilbyder tekst-til-billede-diffusionsmodeller med hidtil uset fotorealisme og dyb sprogforståelse. Disse platforme illustrerer tilsammen mangfoldigheden af tilgange og forretningsmodeller i AI-billedgenereringsmarkedet, hvor hver især opfylder forskellige brugerbehov og anvendelser.
Landskabet for AI-billedgenerering udvikler sig hurtigt, med flere fremtrædende trends, der former teknologiens fremtid. Modelforbedringer og effektivitet fortsætter i et hæsblæsende tempo, hvor nyere modeller skaber billeder i højere opløsning, bedre tekstoverensstemmelse og hurtigere genereringstider. Markedet for AI-billedgeneratorer forventes at vokse med 17,4% årligt frem til 2030, hvilket indikerer vedvarende investeringer og innovation. Fremvoksende trends inkluderer videogenerering ud fra tekst, hvor AI-systemer udvider billedgenereringsmuligheder til korte videoklip; 3D-model-generering, hvor AI skaber tredimensionelle aktiver direkte; og real-time billedgenerering, der mindsker ventetid og muliggør interaktive kreative arbejdsgange.
Regulatoriske rammer er begyndt at opstå globalt, hvor myndigheder og brancheorganer udvikler standarder for gennemsigtighed, ophavsret og etisk brug. NO FAKES Act og lignende lovgivning foreslår krav om vandmærkning af AI-genereret indhold og oplysning om brug af AI ved skabelse. 62% af globale marketingfolk mener, at påkrævede mærkater for AI-genereret indhold vil have en positiv effekt på sociale mediers præstationer, hvilket tyder på anerkendelse af gennemsigtighedens betydning.
Integration med andre AI-systemer accelererer, hvor billedgenerering indlejres i bredere AI-platforme og arbejdsgange. Multimodale AI-systemer, der kombinerer tekst, billede, lyd og videogenerering, bliver stadig mere sofistikerede. Teknologien bevæger sig også mod personalisering og tilpasning, hvor AI-modeller kan finjusteres til specifikke kunstneriske stilarter, brandudtryk eller individuelle præferencer. Efterhånden som AI-genererede billeder bliver mere udbredte på digitale platforme, vokser vigtigheden af brandovervågning og citatsporing i AI-svar tilsvarende, hvilket gør værktøjer, der sporer, hvordan brands optræder i AI-genereret indhold, stadig mere værdifulde for virksomheder, der ønsker at opretholde synlighed og autoritet i den generative AI-tidsalder.
AI-genererede billeder skabes udelukkende af maskinlæringsalgoritmer ud fra tekstprompter eller andre input, mens traditionel fotografering indfanger virkelige scener gennem et kameralinse. AI-billeder kan forestille alt tænkeligt, inklusive umulige scenarier, hvorimod fotografering er begrænset til det, der findes eller kan arrangeres fysisk. AI-generering er typisk hurtigere og mere omkostningseffektiv end at arrangere fotoshoots, hvilket gør det ideelt til hurtig indholdsoprettelse og prototyper.
Diffusionsmodeller fungerer ved at starte med ren tilfældig støj og gradvist forfine det gennem iterative afstøjningsskridt. Tekstprompten omdannes til numeriske indlejringer, der guider denne afstøjningsproces, og forvandler støjen til et sammenhængende billede, der matcher beskrivelsen. Denne trin-for-trin tilgang giver præcis kontrol og producerer detaljerede, høj-kvalitetsbilleder med fremragende overensstemmelse med inputteksten.
De tre primære teknologier er Generative Adversarial Networks (GANs), som bruger konkurrerende neurale netværk til at skabe realistiske billeder; Diffusionsmodeller, som iterativt afstøjer tilfældig støj til strukturerede billeder; og Transformere, der omdanner tekstprompter til billeder ved hjælp af selvopmærksomhedsmekanismer. Hver arkitektur har sine styrker: GANs udmærker sig i fotorealisme, diffusionsmodeller producerer meget detaljerede resultater, og transformere håndterer kompleks tekst-til-billede syntese særligt godt.
Ophavsret til AI-genererede billeder er juridisk uklar og varierer fra jurisdiktion til jurisdiktion. I mange tilfælde kan ophavsretten tilhøre personen, der lavede prompten, udvikleren af AI-modellen, eller potentielt ingen, hvis AI'en arbejder autonomt. Det amerikanske ophavsretskontor har angivet, at værker skabt udelukkende af AI uden menneskelig kreativ indgriben måske ikke kvalificerer sig til ophavsretsbeskyttelse, men dette er et område under udvikling med igangværende retssager og regulering.
AI-genererede billeder bruges bredt i e-handel til produktfotografering, i markedsføring til kampagnevisuelle og indhold på sociale medier, i spiludvikling til karakter- og asset-skabelse, i medicinsk billeddannelse til diagnostisk visualisering, og i reklame til hurtig konceptafprøvning. Ifølge nyeste data bruger 62% af marketingfolk AI til at skabe nye billedaktiver, og markedet for AI-billedredigering er vurderet til 88,7 milliarder dollars i 2025, hvilket viser betydelig erhvervsadoption på tværs af brancher.
Nuværende AI-billedgeneratorer har svært ved at skabe anatomisk korrekte menneskehænder og ansigter, og producerer ofte unaturlige træk som ekstra fingre eller asymmetriske ansigtselementer. De er også meget afhængige af kvaliteten af træningsdata, hvilket kan introducere bias og begrænse diversiteten i resultaterne. Derudover kræver opnåelse af specifikke detaljer omhyggelig promptudformning, og teknologien kan nogle gange give resultater, der mangler naturligt udseende eller ikke rammer den ønskede kreative intention.
De fleste AI-billedgeneratorer er trænet på enorme datasæt af billeder indsamlet fra internettet, hvoraf mange er ophavsretligt beskyttede værker. Det har ført til betydelige juridiske udfordringer, hvor kunstnere har anlagt sag mod virksomheder som Stability AI og Midjourney for brug af ophavsretligt beskyttede billeder uden tilladelse eller kompensation. Nogle platforme som Getty Images og Shutterstock har forbudt AI-genererede billedindsendelser på grund af disse uafklarede ophavsretsproblemer, og reguleringer er stadig under udvikling for at adressere datatransparens og fair kompensation.
Det globale marked for AI-billedgeneratorer blev vurderet til 299,2 millioner dollars i 2023 og forventes at vokse med en gennemsnitlig årlig vækst på 17,4% frem til 2030. Det bredere AI-billedredigeringsmarked er vurderet til 88,7 milliarder dollars i 2025 og forventes at nå 8,9 milliarder dollars i 2034. Desuden er 71% af billeder på sociale medier nu AI-genererede, og markedet for AI-drevet sociale medier forventes at nå 12 milliarder dollars i 2031, hvilket viser eksplosiv vækst og udbredt adoption.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Generativ AI skaber nyt indhold ud fra træningsdata ved hjælp af neurale netværk. Lær hvordan det fungerer, dets anvendelser i ChatGPT og DALL-E, og hvorfor ove...
Lær hvad AI-indholdsgenerering er, hvordan det fungerer, dets fordele og udfordringer, og bedste praksis for at bruge AI-værktøjer til at skabe marketingindhold...

Lær om AI-genereret indhold er effektivt for AI-søgesynlighed, herunder bedste praksis for indholdsskabelse, optimeringsstrategier og hvordan du balancerer AI-v...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.