Definition af Opmærksomhedsmekanisme
Opmærksomhedsmekanisme er en maskinlæringsteknik, der leder dybe læringsmodeller til at prioritere (eller “fokusere på”) de mest relevante dele af inputdata ved forudsigelser. I stedet for at behandle alle inputelementer ens, beregner opmærksomhedsmekanismer opmærksomhedsvægte, der afspejler den relative betydning af hvert element for den aktuelle opgave, og anvender derefter disse vægte til dynamisk at fremhæve eller nedtone specifikke input. Denne grundlæggende innovation er blevet hjørnestenen i moderne transformerarkitekturer og store sprogmodeller (LLM’er) som ChatGPT, Claude og Perplexity, der gør det muligt for dem at behandle sekventielle data med hidtil uset effektivitet og nøjagtighed. Mekanismen er inspireret af menneskelig kognitiv opmærksomhed—evnen til selektivt at fokusere på fremtrædende detaljer, mens uvedkommende information filtreres fra—og oversætter dette biologiske princip til en matematisk stringent og lærbar komponent i neurale netværk.
Historisk Kontekst og Udvikling
Konceptet opmærksomhedsmekanismer blev først introduceret af Bahdanau og kollegaer i 2014 for at adressere kritiske begrænsninger i rekursive neurale netværk (RNN’er) brugt til maskinoversættelse. Før opmærksomhed blev introduceret, var Seq2Seq-modeller afhængige af en enkelt kontekstvektor til at indkode hele kildesætninger, hvilket skabte en informationsflaskehals, der alvorligt begrænsede præstationen på længere sekvenser. Den oprindelige opmærksomhedsmekanisme gjorde det muligt for dekoderen at tilgå alle skjulte encoder-tilstande frem for kun den sidste, og dynamisk vælge hvilke dele af inputtet, der var mest relevante ved hvert dekoderingstrin. Dette gennembrud forbedrede oversættelseskvaliteten dramatisk, især for længere sætninger. I 2015 introducerede Luong og kollegaer dot-produkt-opmærksomhed, som erstattede den beregningsmæssigt tunge additive opmærksomhed med effektiv matrixmultiplikation. Det afgørende øjeblik kom i 2017 med udgivelsen af “Attention is All You Need”, der introducerede transformerarkitekturen, som helt fravalgte rekursion til fordel for rene opmærksomhedsmekanismer. Denne artikel revolutionerede dyb læring og muliggjorde udviklingen af BERT, GPT-modeller og hele det moderne generative AI-økosystem. I dag er opmærksomhedsmekanismer allestedsnærværende inden for naturlig sprogbehandling, computer vision og multimodale AI-systemer, og over 85% af state-of-the-art-modeller inkorporerer en eller anden form for opmærksomhedsbaseret arkitektur.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Teknisk Arkitektur og Komponenter
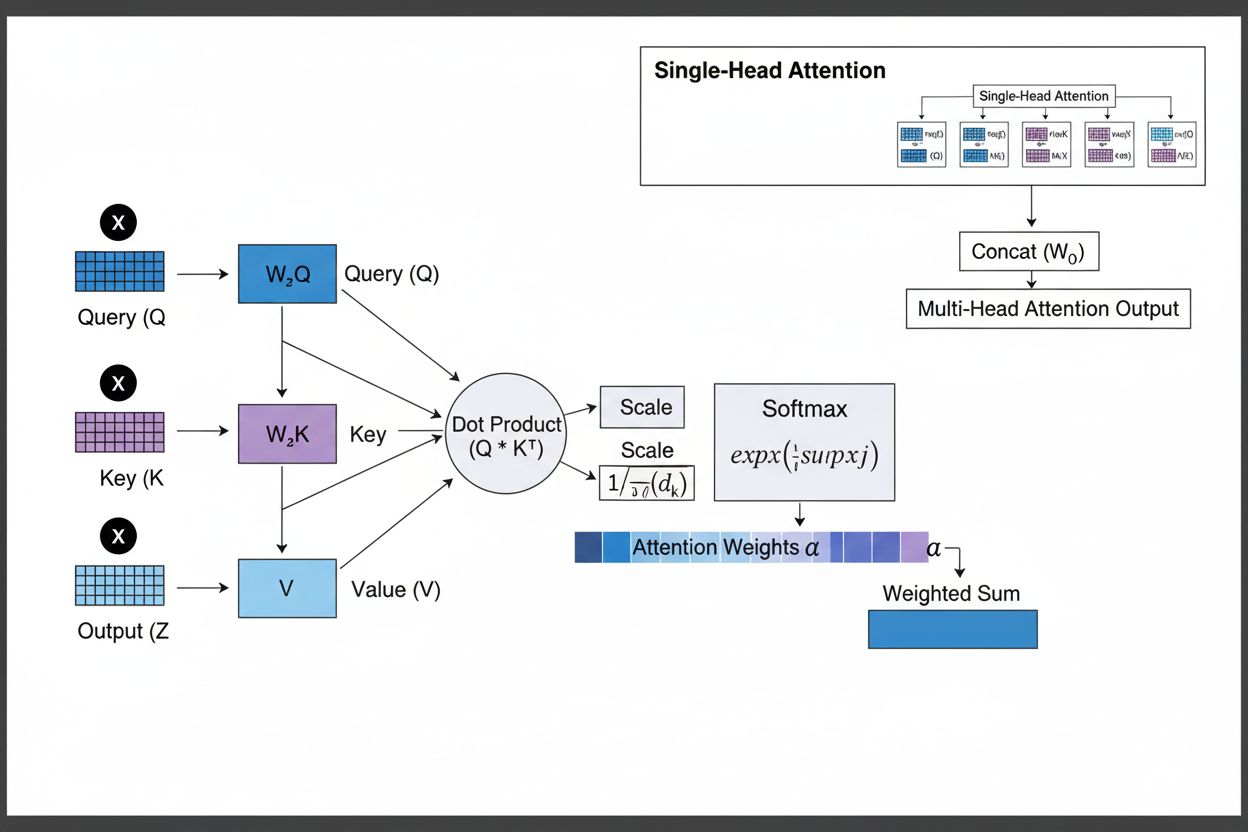
Opmærksomhedsmekanismen fungerer gennem et sofistikeret samspil mellem tre centrale matematiske komponenter: forespørgsler (Q), nøgler (K) og værdier (V). Hvert inputelement transformeres til disse tre repræsentationer gennem lærte lineære projektioner, hvilket skaber en relationsdatabase-lignende struktur, hvor nøgler fungerer som identifikatorer, og værdier indeholder den faktiske information. Mekanismen beregner tilpasningsscorer ved at måle ligheden mellem en forespørgsel og alle nøgler, typisk ved brug af skaleret dot-produkt-opmærksomhed, hvor scoren beregnes som QK^T/√d_k. Disse rå scorer normaliseres derefter med softmax-funktionen, der omdanner dem til en sandsynlighedsfordeling, så alle vægte summer til 1, hvilket sikrer, at hvert element får en vægt mellem 0 og 1. Det sidste trin indebærer at beregne en vægtet sum af værdivektorerne ved hjælp af opmærksomhedsvægtene, hvilket producerer en kontekstvektor, der repræsenterer den mest relevante information fra hele inputsekvensen. Denne kontekstvektor kombineres derefter med det oprindelige input via residualforbindelser og føres gennem feedforward-lag, hvilket gør det muligt for modellen løbende at forfine sin forståelse af inputtet. Den matematiske elegance i dette design—kombinationen af lærbare transformationer, lighedsberegninger og probabilistisk vægtning—gør det muligt for opmærksomhedsmekanismer at opfange komplekse afhængigheder og samtidig forblive fuldt differentierbare for gradientbaseret optimering.
Sammenligning af Opmærksomhedsmekanisme-varianter
| Opmærksomhedstype | Beregningmetode | Beregningkompleksitet | Bedste Anvendelse | Nøglefordel |
|---|
| Additiv Opmærksomhed | Feedforward-netværk + tanh-aktivering | O(n·d) pr. forespørgsel | Kortere sekvenser, variable dimensioner | Håndterer forskellige forespørgsel/nøgle-dimensioner |
| Dot-produkt-opmærksomhed | Simpel matrixmultiplikation | O(n·d) pr. forespørgsel | Standardsekvenser | Beregningsmæssigt effektiv |
| Skaleret dot-produkt | QK^T/√d_k + softmax | O(n·d) pr. forespørgsel | Moderne transformere | Forhindrer gradientforsvinden |
| Multi-head-opmærksomhed | Flere parallelle opmærksomhedshoveder | O(h·n·d), hvor h=hoveder | Komplekse relationer | Opfanger forskellige semantiske aspekter |
| Selv-opmærksomhed | Forespørgsler, nøgler, værdier fra samme sekvens | O(n²·d) | Intra-sekvens-relationer | Muliggør parallel behandling |
| Kryds-opmærksomhed | Forespørgsler fra én sekvens, nøgler/værdier fra en anden | O(n·m·d) | Encoder-decoder, multimodal | Tilpasser forskellige modaliteter |
| Grouped Query Attention | Deler nøgler/værdier mellem forespørgselshoveder | O(n·d) | Effektiv inferens | Mindsker hukommelse og beregning |
| Sparsom opmærksomhed | Begrænset opmærksomhed til lokale/stridede positioner | O(n·√n·d) | Meget lange sekvenser | Håndterer ekstreme sekvenslængder |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Sådan Fungerer Opmærksomhedsmekanismer i Praksis
Opmærksomhedsmekanismen fungerer gennem en nøje orkestreret sekvens af matematiske transformationer, der gør det muligt for neurale netværk dynamisk at fokusere på relevant information. Når en inputsekvens behandles, indlejres hvert element først i et højdimensionelt vektorrum, der indfanger semantisk og syntaktisk information. Disse indlejringer projiceres derefter ind i tre separate rum gennem lærte vægtmatricer: forespørgselsrummet (repræsenterer, hvilken information der søges), nøglerummet (repræsenterer, hvad information hvert element indeholder), og værdirummet (indeholder den faktiske information, der skal aggregeres). For hver forespørgselsposition beregner mekanismen en lighedsscore med hver nøgle ved at tage deres dot-produkt, hvilket producerer en vektor af rå tilpasningsscorer. Disse scorer skaleres ved at dividere med kvadratroden af nøgle-dimensionen (√d_k)—et kritisk trin, der forhindrer dot-produkterne i at blive for store, når dimensionerne er høje, hvilket ellers ville få gradienterne til at forsvinde under backpropagation. De skalerede scorer sendes derefter gennem en softmax-funktion, der opløfter hver score og normaliserer dem, så de summer til 1, hvilket skaber en sandsynlighedsfordeling over alle inputpositioner. Endelig bruges disse opmærksomhedsvægte til at beregne et vægtet gennemsnit af værdivektorerne, hvor positioner med højere opmærksomhedsvægt bidrager stærkere til den endelige kontekstvektor. Denne kontekstvektor kombineres derefter med det oprindelige input via residualforbindelser og behandles gennem feedforward-lag, så modellen løbende kan forfine sine repræsentationer. Hele processen er differentierbar, hvilket gør det muligt for modellen at lære optimale opmærksomhedsmønstre gennem gradientnedstigning under træning.
Opmærksomhedsmekanismer udgør det fundamentale byggesten i transformerarkitekturer, som er blevet den dominerende tilgang inden for dyb læring. I modsætning til RNN’er, der behandler sekvenser sekventielt, og CNN’er, der arbejder med faste lokale vinduer, bruger transformere selv-opmærksomhed til at lade hver position direkte fokusere på alle andre positioner samtidigt, hvilket muliggør massiv parallelisering på tværs af GPU’er og TPU’er. Transformerarkitekturen består af skiftende lag af multi-head selv-opmærksomhed og feedforward-netværk, hvor hvert opmærksomhedslag gør det muligt for modellen at forfine sin forståelse af inputtet ved selektivt at fokusere på forskellige aspekter. Multi-head-opmærksomhed kører flere opmærksomhedsmekanismer parallelt, hvor hvert hoved lærer at fokusere på forskellige typer af relationer—ét hoved kan specialisere sig i grammatiske afhængigheder, et andet i semantiske relationer, og et tredje i langdistance-koreference. Outputtene fra alle hoveder samles og projiceres, så modellen kan bevare opmærksomhed på flere sproglige fænomener samtidigt. Denne arkitektur har vist sig ekstremt effektiv for store sprogmodeller som GPT-4, Claude 3 og Gemini, der bruger dekoder-only transformerarkitektur, hvor hvert token kun kan fokusere på tidligere tokens (kausal maskering) for at opretholde den autoregressive genereringsegenskab. Opmærksomhedsmekanismens evne til at opfange langtrækkende afhængigheder uden de gradientforsvindingsproblemer, der plager RNN’er, har været afgørende for at gøre det muligt for disse modeller at behandle kontekstvinduer på 100.000+ tokens og bevare sammenhæng og konsistens gennem store tekstmængder. Forskning viser, at cirka 92% af state-of-the-art NLP-modeller nu er afhængige af transformerarkitekturer drevet af opmærksomhedsmekanismer, hvilket understreger deres fundamentale betydning for moderne AI-systemer.
Opmærksomhedsmekanismer i AI-søgning og Overvågning
I konteksten af AI-søgeplatforme som ChatGPT, Perplexity, Claude og Google AI Overviews spiller opmærksomhedsmekanismer en afgørende rolle i at bestemme, hvilke dele af hentede dokumenter og vidensbaser der er mest relevante for brugerforespørgsler. Når disse systemer genererer svar, vægter deres opmærksomhedsmekanismer dynamisk forskellige kilder og passager baseret på relevans, hvilket gør dem i stand til at syntetisere sammenhængende svar fra flere kilder og samtidig opretholde faktuel nøjagtighed. Opmærksomhedsvægtene, der beregnes under generering, kan analyseres for at forstå, hvilken information modellen prioriterede, og giver indsigt i, hvordan AI-systemer fortolker og besvarer forespørgsler. For brandovervågning og GEO (Generative Engine Optimization) er forståelse af opmærksomhedsmekanismer essentielt, fordi de afgør, hvilket indhold og hvilke kilder der får vægt i AI-genererede svar. Indhold, der er struktureret til at matche, hvordan opmærksomhedsmekanismer vægter information—gennem klare entitetsdefinitioner, autoritative kilder og kontekstuel relevans—har større sandsynlighed for at blive citeret og fremhævet i AI-svar. AmICited udnytter indsigt i opmærksomhedsmekanismer til at spore, hvordan brands og domæner fremgår på tværs af AI-platforme, idet de anerkender, at opmærksomhedsvægtede citationer repræsenterer de mest indflydelsesrige omtaler i AI-genereret indhold. Efterhånden som virksomheder i stigende grad overvåger deres tilstedeværelse i AI-svar, bliver forståelse af, at opmærksomhedsmekanismer driver citationsmønstre, afgørende for at optimere indholdsstrategi og sikre brandsynlighed i den generative AI-tidsalder.
Nøgleaspekter og Implementeringsovervejelser
- Beregningseffektivitet: Skaleret dot-produkt-opmærksomhed muliggør O(n²)-kompleksitet med massiv parallelisering, hvilket gør det praktisk for sekvenser på tusindvis af tokens på moderne GPU’er
- Gradientflow: Skaleringsfaktoren (1/√d_k) forhindrer gradientforsvinden og muliggør stabil træning af meget dybe netværk med mange opmærksomhedslag
- Fortolkelighed: Opmærksomhedsvægte giver fortolkelige visualiseringer, der viser, hvilke inputelementer der påvirkede specifikke forudsigelser og øger modellens gennemsigtighed
- Positionskodning: Transformere kræver eksplicit positionsinformation via sinusbølge- eller roterende kodning, da opmærksomhed ikke i sig selv bevarer sekvensrækkefølge
- Kausal maskering: Autoregressive modeller som GPT bruger kausal maskering for at forhindre tokens i at fokusere på fremtidige positioner og opretholder genereringsegenskaben
- Hukommelseseffektivitet: Varianter som grouped query attention og sparsom opmærksomhed reducerer hukommelseskravene fra O(n²) til O(n·√n) for meget lange sekvenser
- Multi-skala opmærksomhed: Forskellige opmærksomhedshoveder lærer at fokusere på forskellige kontekstskalaer, fra lokale ordrelationer til temaer på dokumentniveau
- Kryds-modal tilpasning: Kryds-opmærksomhed gør det muligt for modeller som Stable Diffusion at tilpasse tekstprompter til billedgenerering og for vision-language-modeller at forankre sprog i visuel information
Udvikling og Fremtidige Retninger
Feltet opmærksomhedsmekanismer udvikler sig fortsat hurtigt, hvor forskere udvikler stadig mere sofistikerede varianter for at tackle beregningsmæssige begrænsninger og forbedre ydeevne. Sparsomme opmærksomhedsmønstre begrænser opmærksomheden til lokale nabolag eller stride positioner, hvilket reducerer kompleksiteten fra O(n²) til O(n·√n) og samtidig opretholder ydeevnen på meget lange sekvenser. Effektive opmærksomhedsmekanismer som FlashAttention optimerer hukommelsesadgangen i opmærksomhedsberegningen og opnår 2-4x hastighedsforbedringer gennem bedre GPU-udnyttelse. Grouped query attention og multi-query attention reducerer antallet af nøgle-værdi-hoveder, mens ydeevnen bibeholdes, hvilket markant mindsker hukommelseskravet under inferens—en kritisk overvejelse ved implementering af store modeller i produktion. Mixture of Experts-arkitekturer kombinerer opmærksomhed med sparsom routing, hvilket gør det muligt for modeller at skalere til billioner af parametre og samtidig opretholde beregningseffektivitet. Fremspirende forskning udforsker lærte opmærksomhedsmønstre, der tilpasser sig dynamisk baseret på inputkarakteristika, og hierarkisk opmærksomhed, der arbejder på flere abstraktionsniveauer. Integration af opmærksomhedsmekanismer med retrieval-augmented generation (RAG) gør det muligt for modeller dynamisk at fokusere på relevant ekstern viden, hvilket forbedrer faktualitet og mindsker hallucinationer. Efterhånden som AI-systemer i stigende grad implementeres i kritiske applikationer, forbedres opmærksomhedsmekanismer med forklaringsfunktioner, der giver klarere indsigt i modelbeslutninger. Fremtiden indebærer sandsynligvis hybride arkitekturer, der kombinerer opmærksomhed med alternative mekanismer som state-space-modeller (eksemplificeret ved Mamba), som tilbyder lineær kompleksitet og stadig konkurrencedygtig ydeevne. Forståelse af disse udviklende opmærksomhedsmekanismer er essentielt for praktikere, der bygger næste generations AI-systemer, og for organisationer, der overvåger deres tilstedeværelse i AI-genereret indhold, da de mekanismer, der bestemmer citationsmønstre og indholdsdominans, fortsætter med at udvikle sig.
Opmærksomhedsmekanismer og AI-citationsmønstre
For organisationer, der bruger AmICited til at overvåge brandsynlighed i AI-svar, giver forståelse af opmærksomhedsmekanismer afgørende kontekst for at tolke citationsmønstre. Når ChatGPT, Claude eller Perplexity citerer dit domæne i deres svar, bestemte de opmærksomhedsvægte, der blev beregnet under genereringen, at dit indhold var mest relevant for brugerens forespørgsel. Indhold af høj kvalitet, der er velstruktureret, klart definerer entiteter og leverer autoritativ information, modtager naturligt højere opmærksomhedsvægte og har dermed større sandsynlighed for at blive udvalgt til citation. Opmærksomhedsvisualiseringsfunktioner på nogle AI-platforme afslører, hvilke kilder der fik mest fokus under svargenerering, og viser reelt, hvilke citationer der var mest indflydelsesrige. Denne indsigt gør det muligt for organisationer at optimere deres indholdsstrategi ved at forstå, at opmærksomhedsmekanismer belønner klarhed, relevans og autoritativ kildeangivelse. Efterhånden som AI-søgning vokser—med over 60% af virksomheder, der nu investerer i generative AI-initiativer—bliver evnen til at forstå og optimere for opmærksomhedsmekanismer stadig mere værdifuld for at bevare brandsynlighed og sikre korrekt repræsentation i AI-genereret indhold. Skæringspunktet mellem opmærksomhedsmekanismer og brandovervågning udgør en frontlinje i GEO, hvor forståelse af de matematiske grundlag for, hvordan AI-systemer vægter og citerer information, direkte omsættes til forbedret synlighed og indflydelse i det generative AI-økosystem.