
Kanonisk strategi for AI-søgning: Optimer dit indhold til AI-motorer
Lær, hvordan kanoniske tags hjælper dit indhold med at rangere i AI-søgemaskiner. Opdag bedste praksis for kanonisk strategi til ChatGPT, Perplexity og Google A...
13 min læsning

En kanonisk URL er den foretrukne version af en webside, som søgemaskiner bør crawle, indeksere og rangere, når flere URL’er indeholder identisk eller lignende indhold. Den angives ved hjælp af rel=“canonical” HTML-tagget for at samle rangeringssignaler og forhindre problemer med dubleret indhold.
En kanonisk URL er den foretrukne version af en webside, som søgemaskiner bør crawle, indeksere og rangere, når flere URL'er indeholder identisk eller lignende indhold. Den angives ved hjælp af rel="canonical" HTML-tagget for at samle rangeringssignaler og forhindre problemer med dubleret indhold.
En kanonisk URL er den primære, foretrukne eller autoritative version af en webside, som du angiver til søgemaskiner for at crawle, indeksere og rangere, når flere URL’er indeholder identisk eller væsentligt lignende indhold. Udtrykket “kanonisk” stammer fra idéen om at etablere en enkelt autoritativ kilde blandt flere variationer. I konteksten af søgemaskineoptimering og webarkitektur fungerer en kanonisk URL som hovedkopien, der samler rangeringssignaler, linkværdi og indekseringsautoritet fra alle duplikerede eller næsten identiske versioner af det samme indhold. Denne skelnen er vigtig, fordi søgemaskiner som Google, Bing og i stigende grad AI-søgesystemer som ChatGPT, Perplexity og Claude behandler hver unik URL som en separat side, selv når indholdet er identisk. Ved eksplicit at angive en kanonisk URL via rel="canonical" HTML-tagget eller andre kanoniseringsmetoder kommunikerer webmasters deres præference til søgemaskinerne, så den korrekte version får indekseringsprioritet og rangeringsfordele.
Konceptet med kanoniske URL’er opstod, efterhånden som webteknologier udviklede sig, og websites blev mere komplekse. I internettets tidlige dage havde de fleste websites enkle URL-strukturer med minimal dublering. Men efterhånden som content management systemer (CMS), e-handelsplatforme og dynamiske webapplikationer blev udbredt, blev problemet med utilsigtet dubleret indhold omfattende. Ifølge forskning fra store SEO-platforme indeholder over 30 % af websites betydelige problemer med dubleret indhold, ofte uden webmasterens viden. Denne dublering opstår gennem forskellige mekanismer: URL-parametre brugt til sporing og filtrering, flere protokolversioner (HTTP vs HTTPS), domænevariationer (www vs ikke-www), mobil-specifikke URL’er, sessions-ID’er og pagineringsparametre. Google’s John Mueller har understreget, at kanoniske tags er essentielle for at kommunikere websitets struktur til søgemaskiner, især når websites genererer flere URL’er for det samme indhold. rel="canonical"-specifikationen blev formelt introduceret af Google, Yahoo og Microsoft i 2009 som en standardiseret metode for webmasters til at angive foretrukne URL’er. Siden da er kanoniske URL’er blevet en grundlæggende del af teknisk SEO, hvor over 78 % af virksomheders websites implementerer kanoniske tags som en del af deres SEO-strategi. Vigtigheden af kanoniske URL’er er kun steget med fremkomsten af AI-søgemaskiner og generative AI-systemer, der er afhængige af korrekt kanonisering for at tilskrive indhold rigtigt og undgå at indeksere dublerede versioner.
Kanoniseringsprocessen fungerer gennem en systematisk arbejdsgang, som søgemaskiner følger, når de støder på flere URL’er med identisk eller lignende indhold. Når en søgemaskinecrawler besøger dit website, identificerer den sider, der indeholder det samme eller næsten identiske indhold på forskellige URL’er. Crawleren leder derefter efter kanoniseringssignaler for at afgøre, hvilken version der skal behandles som den primære side. Disse signaler omfatter rel="canonical" HTML-tagget placeret i sidens <head>-sektion, HTTP-headere med kanonisk information, 301-omdirigeringer, interne linkmønstre, XML-sitemap-indgange og HTTPS-præferencesignaler. Det mest eksplicitte og kraftfulde signal er rel="canonical"-link-elementet, som vises i HTML-kildekoden som: <link rel="canonical" href="https://www.example.com/preferred-url" />. Når søgemaskiner ser dette tag, forstår de, at URL’en i href-attributten er den kanoniske version. Crawleren konsoliderer derefter alle rangeringssignaler – herunder backlinks, interne links, brugerengagement-målinger og indholdsautoritet – til den kanoniske URL. Denne konsolideringsproces er afgørende, fordi den forhindrer opdeling af rangeringskraft på flere dublerede URL’er. F.eks. hvis din produktside er tilgængelig via fem forskellige URL’er på grund af sporingsparametre og domænevariationer, og hver URL modtager backlinks uafhængigt, ville disse links normalt konkurrere mod hinanden. Med korrekt kanonisering flyder al linkværdi til den ene kanoniske URL, hvilket styrker dens rangeringspotentiale betydeligt. Forskning viser, at korrekt kanonisering kan forbedre søgesynligheden med 15-30 % for sites med betydelige dubleringsproblemer.
| Aspekt | Kanonisk URL (rel=“canonical”) | 301-omdirigering | Sitemap-inddragelse | Robots.txt-blokering |
|---|---|---|---|---|
| Formål | Angiver foretrukken version, mens dubletter forbliver tilgængelige | Flytter permanent én URL til en anden | Foreslår kanoniske URL’er til søgemaskiner | Forhindrer crawling af dublerede sider |
| Brugeroplevelse | Brugere kan tilgå både kanonisk og dublet-URL | Brugere omdirigeres automatisk til ny URL | Ingen direkte brugerindvirkning | Brugere kan ikke tilgå blokerede URL’er |
| Søgemaskinesignalstyrke | Stærkt signal; samler rangeringskraft | Stærkeste signal; fuldstændig URL-samling | Svagt signal; kræver at Google identificerer dubletter | Ikke anbefalet til kanonisering |
| Implementeringskompleksitet | Moderat; kræver HTML-ændringer eller CMS-indstillinger | Moderat; kræver serverkonfiguration | Let; tilføj URL’er til sitemap | Let; tilføj regler i robots.txt |
| Bedste anvendelsestilfælde | Dubleret indhold der skal forblive tilgængeligt | Udfasning af gamle URL’er eller site-migrering | Store sites med mange kanoniske URL’er | Blokering af test-/staging-miljøer |
| Linkværdi-samling | Ja; signaler flyder til kanonisk URL | Ja; fuldstændig overførsel til ny URL | Delvis; afhænger af Googles fortolkning | Nej; blokerer crawling helt |
| Reversibilitet | Ja; kan ændres eller fjernes | Vanskelig; kræver ny opsætning af omdirigering | Ja; kan opdateres i sitemap | Ja; kan fjernes fra robots.txt |
| Indvirkning på crawl-budget | Moderat; reducerer spildt crawl på dubletter | Høj; eliminerer crawling af gamle URL’er | Lav; crawler stadig alle URL’er i sitemap | Høj; forhindrer crawling af dubletter |
Implementering af kanoniske URL’er kræver forståelse for de specifikke metoder, der er tilgængelige, og valg af den tilgang, der bedst passer til dit websites arkitektur og CMS. rel="canonical"-link-elementet er den mest almindelige implementeringsmetode og placeres direkte i HTML-<head>-sektionen på dublerede sider. Dette tag skal pege på den absolutte URL (inklusive protokol og domæne) for den kanoniske version. For eksempel, på en produktside, der er tilgængelig via flere URL’er, skal du tilføje: <link rel="canonical" href="https://www.example.com/products/blue-shoes" /> til alle dublet-versioner. Den kanoniske URL bør være en ren, tilgængelig URL uden sporingsparametre, sessions-ID’er eller unødvendige query strings. Selvhenvisende kanoniske tags – hvor en sides kanoniske tag peger på dens egen URL – anbefales i stigende grad som bedste praksis. Dette forstærker over for søgemaskiner, hvilken URL der er kanonisk, selv for unikke sider, og forhindrer utilsigtede kanoniseringsproblemer. For ikke-HTML-indhold som PDF’er, Word-dokumenter eller andre filtyper er rel="canonical" HTTP-header-metoden mere passende. Dette indebærer konfiguration af din server til at sende en Link-header i HTTP-responsen: Link: <https://www.example.com/document.pdf>; rel="canonical". Denne metode er især nyttig for sites, der udgiver indhold i flere formater på forskellige URL’er. Desuden fungerer 301-omdirigeringer som et stærkt kanoniseringssignal, især når du ønsker fuldstændigt at samle URL’er og fjerne den gamle version fra søgeresultaterne. Når Side A omdirigeres med en 301-statuskode til Side B, forstår søgemaskiner, at Side B er den kanoniske version og overfører alle rangeringssignaler tilsvarende. XML-sitemaps giver et svagere, men stadig værdifuldt kanoniseringssignal ved kun at liste de kanoniske URL’er, du vil have indekseret. Endelig er HTTPS-præference et automatisk signal, hvor Google foretrækker HTTPS-versioner over HTTP-ækvivalenter, så det er vigtigt, at dine kanoniske URL’er bruger HTTPS for korrekt kanonisering.
Dubleret indhold udgør en af de største udfordringer i moderne webadministration og påvirker omkring 29 % af alle indekserede websider ifølge brancheundersøgelser. Dubleret indhold opstår fra mange kilder: e-handelssites med produktfiltre og sorteringsmuligheder, der genererer unikke URL’er til det samme produkt, blogs med tag-arkiver og kategorisider, der viser de samme artikler, indholdssyndikering på tværs af flere domæner, mobil-specifikke URL’er sammen med desktop-versioner samt utilsigtede dubletter fra staging-miljøer eller testsider. Uden korrekt kanonisering må søgemaskiner selv afgøre, hvilken version der skal indekseres, hvilket ofte ikke stemmer overens med dine forretningsmål. Dette kan resultere i søgeordskannibalisering, hvor flere versioner af det samme indhold konkurrerer om de samme søgeord, hvilket udvander rangeringskraften og mindsker den samlede synlighed. Kanoniske URL’er løser dette problem ved eksplicit at kommunikere din præference til søgemaskinerne. Når du angiver en kanonisk URL, forstår søgemaskiner, at alle dublet-versioner skal behandles som variationer af ét indhold, hvor rangeringssignaler samles i den kanoniske version. Denne konsolidering er især vigtig for fordeling af linkværdi. Hvis dit website modtager backlinks til forskellige URL-varianter af det samme indhold, ville disse links normalt tælle separat og splitte rangeringskraften. Med kanoniske tags flyder al linkværdi til den kanoniske URL, hvilket skaber et stærkere rangeringssignal. For eksempel, hvis din forside er tilgængelig via https://www.example.com, https://example.com, http://www.example.com og http://example.com, og hver version modtager backlinks uafhængigt, sikrer kanoniske tags, at al linkautoritet samles i din foretrukne version. Denne konsolidering kan føre til 15-30 % forbedring i søgerangeringer for sider med betydelige dubleringsproblemer.
E-handelssites står over for særligt komplekse kanoniseringsudfordringer på grund af produkt- og filtersystemers natur. Ét produkt kan være tilgængeligt via flere URL’er: den direkte produkt-URL, URL’er med farve- eller størrelsesfiltre, URL’er med sorteringsparametre, URL’er med sporingskoder til markedsføringskampagner samt mobil-specifikke URL’er. Uden korrekt kanonisering kan søgemaskiner indeksere adskillige variationer af den samme produktside, hvilket spilder crawl-budget og udvander rangeringskraften. E-handelssites, der implementerer korrekt kanonisering, rapporterer 20-40 % forbedringer i organisk trafik ved at konsolidere rangeringssignaler. Den kanoniske URL for et produkt bør typisk være den rene produkt-URL uden parametre: https://www.example.com/products/blue-running-shoes. Alle filtrerede, sorterede eller sporede varianter bør indeholde et kanonisk tag, der peger på denne rene URL. CMS’er som Magento, Shopify og WooCommerce tilbyder ofte indbyggede kanoniseringsfunktioner, der automatisk genererer passende kanoniske tags. Dog kræver disse systemer til tider konfiguration for at sikre korrekt funktion. For Shopify-butikker tilføjes kanoniske tags automatisk til produkt- og kollektionssider, men tilpassede implementeringer kan kræve manuel opsætning. Magento har indstillinger til at aktivere kanoniske tags for produkter og kategorier, men kategorikanonisering kræver omhyggelig overvejelse for at undgå utilsigtet konsolidering. WordPress-sites med SEO-plugins som Yoast SEO eller Rank Math kan automatisk generere kanoniske tags, med mulighed for at tilpasse dem per side. Det vigtigste princip for kanonisering i e-handel er at sikre, at alle produktvarianter – oprettet via filtre, sortering eller sporingsparametre – peger på én kanonisk produkt-URL, så søgemaskiner korrekt kan indeksere og rangere produktet, mens alle rangeringssignaler samles.
Fremkomsten af AI-søgemaskiner og generative AI-systemer har tilført nye dimensioner til vigtigheden af kanoniske URL’er. Platforme som ChatGPT, Perplexity, Claude og Google AI Overviews er afhængige af webcrawling og indeksering for at indsamle information til genererede svar. Når disse AI-systemer møder flere URL’er med identisk indhold, hjælper korrekt kanonisering dem med at identificere den autoritative kilde, der skal citeres i deres svar. Over 60 % af virksomheder er nu bekymrede for, hvordan deres indhold fremstår i AI-genererede svar, hvilket gør styring af kanoniske URL’er stadig mere afgørende for brandsynlighed og tilskrivning. Når et AI-system crawler dit website og finder flere URL’er med det samme indhold, skal det afgøre, hvilken version der skal citeres som kilde. Uden kanoniske tags kan AI-systemet citere en ikke-kanonisk version, hvilket potentielt sender brugere til en mindre optimal side eller undlader at tilskrive dit brand korrekt. Med korrekt kanonisering sikrer du, at AI-systemer citerer din foretrukne URL, forbedrer brugeroplevelsen og opretholder ensartet brandtilskrivning. Dette er især vigtigt for AI-citatsporing og overvågning, hvor platforme som AmICited hjælper organisationer med at spore, hvordan deres indhold vises i AI-genererede svar. Ved at implementere kanoniske tags korrekt øger du sandsynligheden for, at din foretrukne URL vises i AI-citater, hvilket forbedrer synligheden i det AI-drevne søgelandskab. Derudover hjælper kanoniske URL’er AI-systemer med at forstå din sitestruktur og indholdshierarki, hvilket muliggør mere præcise og relevante citater. Efterhånden som AI-søgning vokser – med Perplexity, der rapporterer over 500 millioner månedlige aktive brugere og ChatGPT’s søgefunktion under udvidelse – bliver korrekt kanonisering essentiel for at opretholde synlighed og tilskrivning i AI-genereret indhold.
Effektiv implementering af kanoniske URL’er kræver overholdelse af etablerede bedste praksisser, så søgemaskiner og AI-systemer korrekt genkender og respekterer dine kanoniseringssignaler. Brug absolutte URL’er i stedet for relative URL’er i dine kanoniske tags, og inkluder altid hele protokollen og domænet: <link rel="canonical" href="https://www.example.com/page" /> i stedet for <link rel="canonical" href="/page" />. Relative URL’er kan give problemer, især hvis dit testmiljø utilsigtet crawles, eller hvis URL-strukturen ændres. Sørg for konsistens på tværs af alle kanoniseringssignaler – dine kanoniske tags, interne links, XML-sitemap-indgange og 301-omdirigeringer skal alle pege på den samme URL. Modstridende signaler forvirrer søgemaskiner og mindsker kanoniseringens effektivitet. Undgå kanoniske tagkæder, hvor Side A peger på Side B, og Side B peger på Side C. Søgemaskiner følger muligvis ikke disse kæder korrekt, hvilket resulterer i ukorrekt kanonisering. Peg aldrig kanoniske tags på omdirigerede URL’er eller på sider blokeret af robots.txt eller markeret med noindex. Dette skaber modstridende signaler, som søgemaskiner har svært ved at tolke. Implementér selvhenvisende kanoniske tags på alle sider, også dine kanoniske sider selv. Dette forstærker over for søgemaskiner, hvilken URL der er kanonisk, og forhindrer utilsigtede kanoniseringsproblemer. Brug HTTPS i dine kanoniske URL’er, hvis dit site understøtter HTTPS, da søgemaskiner foretrækker HTTPS-versioner. Oprethold ensartet URL-formatering med hensyn til skråstreg til sidst, www-præfikser og store og små bogstaver. For eksempel, beslut om dine kanoniske URL’er skal inkludere skråstreg (https://example.com/page/) eller ej (https://example.com/page), og anvend dette konsekvent på hele dit site. Auditer regelmæssigt dine kanoniske tags med værktøjer som Google Search Console, Moz Pro Site Crawl eller Semrush Site Audit for at identificere manglende, ødelagte eller modstridende kanoniske tags. Test din implementering med browserudviklerværktøjer eller SEO-værktøjer for at sikre, at kanoniske tags er korrekt placeret i HTML-head-sektionen og peger på de rigtige URL’er.
På trods af vigtigheden af kanoniske URL’er implementerer mange websites dem forkert, hvilket underminerer deres effektivitet og potentielt skader SEO-ydelsen. En af de mest almindelige fejl er at pege kanoniske tags på ikke-eksisterende eller ødelagte URL’er. Dette skaber en situation, hvor søgemaskiner modtager modstridende signaler – det kanoniske tag foreslår én URL, der skal indekseres, men URL’en returnerer en 404-fejl eller er blokeret for indeksering. Verificer altid, at dine kanoniske URL’er er tilgængelige, returnerer en 200-statuskode og ikke blokeres af robots.txt eller er markeret med noindex. En anden hyppig fejl er at bruge kanoniske tags til ikke-dubleret indhold. Kanoniske tags bør kun bruges til dubleret eller næsten identisk indhold. Nogle SEO-folk forsøger fejlagtigt at bruge kanoniske tags til at samle rangeringskraft fra forskellige sider, såsom at lede autoritet fra udsolgte produktsider til kategorisider. Google fraråder udtrykkeligt denne praksis og ignorerer sandsynligvis sådanne kanoniske tags. Kanoniske tagkæder udgør en anden væsentlig fejl, hvor Side A peger på Side B, Side B peger på Side C, osv. Søgemaskiner følger muligvis ikke disse kæder korrekt, hvilket resulterer i ukorrekt kanonisering. Sørg altid for, at kanoniske tags peger direkte på den endelige kanoniske URL. Modstridende kanoniseringssignaler opstår, når forskellige kanoniseringsmetoder peger på forskellige URL’er. For eksempel, hvis dit kanoniske tag peger på én URL, men din 301-omdirigering peger på en anden, modtager søgemaskiner modstridende information og kan ignorere begge signaler. Sørg for, at alle kanoniseringsmetoder – kanoniske tags, omdirigeringer, sitemaps og interne links – peger på den samme URL. Placering af kanoniske tags uden for HTML-head-sektionen forhindrer søgemaskiner i at finde dem. Kanoniske tags skal være i <head>-sektionen af din HTML. Hvis de placeres i body eller footer, genkender søgemaskiner dem muligvis ikke. Brug af relative URL’er i stedet for absolutte URL’er kan give problemer, især hvis din sitestruktur ændres, eller hvis testmiljøer utilsigtet crawles. Brug altid komplette URL’er inklusive protokol og domæne. At glemme selvhenvisende kanoniske tags på dine kanoniske sider selv kan føre til utilsigtede kanoniseringsproblemer. Hver side, også kanoniske sider, bør have et kanonisk tag, der peger på dens egen URL. Forkert kombination af kanoniske tags med hreflang-tags på flersprogede sites kan skabe forvirring. Hver sprogversion skal have sit eget kanoniske tag, der peger på sig selv, med hreflang-tags, der angiver alle tilgængelige sprogversioner.
Crawl-budgettet – antallet af sider, som søgemaskiner vil crawle på dit website inden for en given tidsramme – er en begrænset ressource, især for store websites. Websites med betydeligt dubleret indhold kan spilde 20-40 % af deres crawl-budget på sider, der ikke behøver at blive indekseret. Kanoniske URL’er hjælper med at optimere crawl-budgettet ved at signalere til søgemaskiner, hvilke sider der er værd at crawle og indeksere. Når du implementerer kanoniske tags korrekt, forstår søgemaskiner, at dublerede sider ikke behøver at blive crawlet grundigt, hvilket giver mulighed for at allokere mere crawl-budget til unikt, værdifuldt indhold. Dette er især vigtigt for store e-handelssites med tusindvis af produktvarianter, nyhedssites med flere artikel-formater og indholdsplatforme med omfattende tag- og kategoriarkiver. Ved at konsolidere dublerede URL’er gennem kanonisering sikrer du, at søgemaskiner bruger crawl-budgettet på de sider, der betyder mest for din virksomhed. Dette kan resultere i hurtigere indeksering af nyt indhold, hyppigere crawling af vigtige sider og forbedret samlet søgesynlighed. Derudover reducerer korrekt kanonisering antallet af URL’er, der vises i din Google Search Console, hvilket gør det lettere at overvåge og administrere dit sites søgepræstation. For sites med begrænsede crawl-budgetter – især mindre websites eller dem i konkurrenceprægede nicher – kan optimering af crawl-budgettet gennem kanonisering have en mærkbar effekt på søgerangeringer og synlighed.
Efterhånden som søgelandskabet fortsætter med at udvikle sig med fremkomsten af AI-drevne søgemaskiner og generative AI-systemer, bliver kanoniske URL’ers rolle stadig vigtigere. Markedet for AI-søgning forventes at vokse fra 5,2 milliarder dollars i 2024 til over 15 milliarder dollars i 2030, med platforme som Perplexity, ChatGPT og Claude, der opnår betydelige markedsandele. Disse AI-systemer er afhængige af webcrawling og indholdsindeksering på samme måde som traditionelle søgemaskiner, hvilket gør kanoniske URL’er essentielle for korrekt indholdstilskrivning og synlighed. Fremtiden for kanoniske URL’er vil sandsynligvis indebære større integration med AI-citatsporings- og overvågningssystemer. Platforme som AmICited er pionerer inden for muligheden for at spore, hvordan indhold vises i AI-genererede svar, og kanoniske URL’er vil spille en central rolle i at sikre korrekt tilskrivning. Efterhånden som AI-systemer bliver mere sofistikerede, kan de udvikle bedre metoder til at identificere kanoniske URL’er og konsolidere information fra flere kilder. Derudover vil fremkomsten af federeret søgning og multi-source AI-systemer, der kombinerer resultater fra flere søgemaskiner og datakilder, gøre kanoniske URL’er endnu vigtigere for at sikre ensartet indholdsrepræsentation på tværs af platforme. Organisationer, der implementerer kanoniske URL’er korrekt i dag, vil være bedre rustet til at opretholde synlighed og tilskrivning, efterhånden som AI-søgning udvikler sig. Ydermere, efterhånden som privatlivsregler og krav til indholdstilskrivning bliver strengere, kan kanoniske URL’er blive et standardkrav for indholdslicensering og syndikeringsaftaler. Integrationen af kanoniske URL’er med struktureret datamarkering og semantiske webteknologier kan også muliggøre mere avancerede mekanismer til indholdskonsolidering og tilskrivning. I sidste ende udgør kanoniske URL’er et grundlæggende element i webarkitektur, der vil forblive relevant og vigtigt, uanset hvordan søgeteknologien udvikler sig.
En kanonisk URL bruger rel="canonical" tagget til at angive en foretrukken version, mens begge URL'er fortsat er tilgængelige for brugere. En 301-omdirigering flytter permanent én URL til en anden og sender automatisk både brugere og søgemaskiner til den nye placering. Brug kanoniske tags, når du har brug for, at dubleret indhold skal forblive tilgængeligt, og 301-omdirigeringer når du ønsker fuldstændigt at samle URL'er og fjerne den gamle version fra søgeresultaterne.
Ja, kanoniske tags på tværs af domæner understøttes af Google og andre søgemaskiner. Dette er nyttigt, når du syndikerer indhold på flere websites eller administrerer relaterede domæner. Brug dog cross-domain kanonikaler strategisk, da de samler al rangeringskraft på ét domæne, hvilket potentielt kan begrænse synligheden på andre ejendomme. Sørg for, at din forretningsstrategi stemmer overens med denne tilgang, før du implementerer cross-domain kanonisering.
Uden kanoniske tags kan søgemaskiner have svært ved at identificere, hvilken version af dubleret indhold der skal indekseres og rangeres. Dette kan resultere i delte rangeringssignaler på flere URL'er, spildt crawl-budget på dublerede sider og potentielt lavere synlighed i søgninger. Google vil forsøge automatisk at bestemme den kanoniske version, men det er ikke sikkert, at de vælger den URL, du foretrækker, hvilket kan føre til suboptimal SEO-ydelse og inkonsekvente søgeresultater.
Selvom det ikke er strengt nødvendigt, betragtes det som bedste praksis at implementere selvhenvisende kanoniske tags på alle sider. Dette forstærker over for søgemaskiner, hvilken URL der er kanonisk, selv for unikke sider. Selvhenvisende kanonikaler er især vigtige for forsider og ofte besøgte sider, som kan tilgås via flere URL-varianter (med/uden www, skråstreg til sidst, HTTP vs HTTPS).
Kanoniske URL'er hjælper AI-søgemaskiner med at forstå din foretrukne indholdsversion, på samme måde som traditionelle søgemaskiner. Når AI-systemer crawler og indekserer dit indhold til citation i svar, signalerer kanoniske tags, hvilken URL der skal tilskrives som den autoritative kilde. Dette er i stigende grad vigtigt for AI-citatsporing og for at sikre, at dit domæne modtager korrekt tilskrivning i AI-genererede svar på platforme som ChatGPT, Perplexity, Claude og Google AI Overviews.
Ja, rel="canonical" HTTP-headeren understøttes af søgemaskiner til ikke-HTML-indhold som PDF'er og dokumenter. Denne metode er nyttig, når du ikke kan ændre HTML-head-sektionen direkte. Dog foretrækkes HTML-kanoniske tags generelt til websider, da de er mere pålidelige og lettere at implementere. For ikke-HTML-filer giver brugen af HTTP-headers et effektivt alternativ til at angive kanoniske URL'er.
Et selvhenvisende kanonisk tag er, når en sides kanoniske tag peger på dens egen URL. For eksempel vil en side på https://example.com/blog/article have et kanonisk tag, der peger på https://example.com/blog/article. Denne praksis forstærker over for søgemaskiner, at siden er dens egen kanoniske version, og hjælper med at forhindre utilsigtede kanoniseringsproblemer, især på sites med komplekse URL-strukturer eller dynamisk indholdsgenerering.
Du kan auditere kanoniske tags ved hjælp af flere metoder: Se sidekildeteksten og søg efter "canonical" i HTML-head-sektionen, brug SEO-værktøjer som Moz Pro Site Crawl eller Semrush Site Audit til at scanne hele dit site for kanoniske problemer, tjek Google Search Console's URL-inspektionsværktøj for at se, hvilken kanonisk URL Google genkender, eller brug browserudvidelser som MozBar til hurtigt at se kanonisk information. Regelmæssige audits hjælper med at identificere manglende, ødelagte eller modstridende kanoniske tags.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær, hvordan kanoniske tags hjælper dit indhold med at rangere i AI-søgemaskiner. Opdag bedste praksis for kanonisk strategi til ChatGPT, Perplexity og Google A...
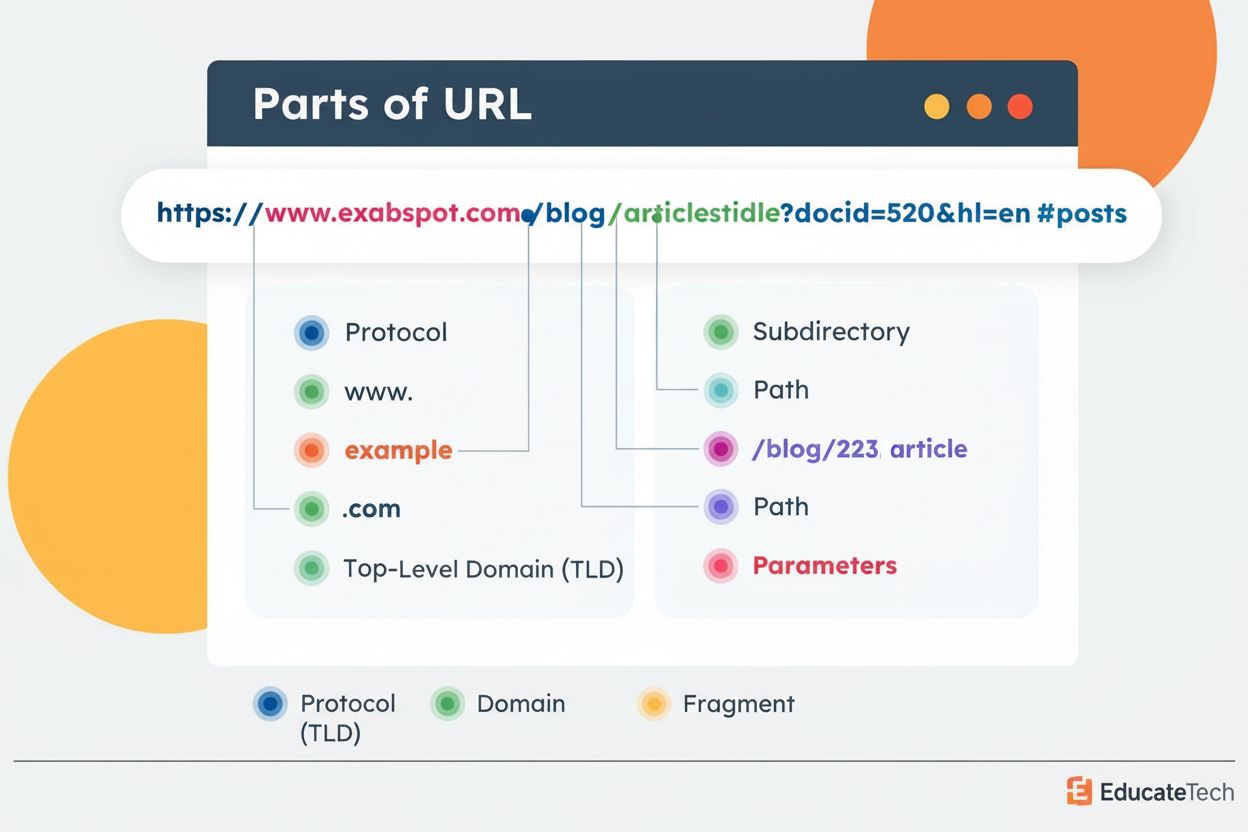
URL-struktur er formatet og organiseringen af websidens adresser inklusive protokol, domæne, sti og parametre. Lær hvordan korrekt URL-struktur påvirker SEO, br...
Fællesskabsdiskussion om, hvordan kanoniske tags påvirker AI-synlighed. Strategier til at forhindre citat-kannibalisering på tværs af ChatGPT, Perplexity og Goo...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.