Teknikker til at sikre, at AI-crawlere effektivt får adgang til og indekserer det vigtigste indhold på et website inden for deres crawlgrænser. Optimering af crawl-budget styrer balancen mellem crawl-kapacitet (serverressourcer) og crawl-efterspørgsel (bot-forespørgsler) for at maksimere synlighed i AI-genererede svar, samtidig med at driftsomkostninger og serverbelastning kontrolleres.
Optimering af crawl-budget for AI
Teknikker til at sikre, at AI-crawlere effektivt får adgang til og indekserer det vigtigste indhold på et website inden for deres crawlgrænser. Optimering af crawl-budget styrer balancen mellem crawl-kapacitet (serverressourcer) og crawl-efterspørgsel (bot-forespørgsler) for at maksimere synlighed i AI-genererede svar, samtidig med at driftsomkostninger og serverbelastning kontrolleres.
Hvad er crawl-budget i AI-tidsalderen
Crawl-budget refererer til mængden af ressourcer—målt i forespørgsler og båndbredde—som søgemaskiner og AI-bots tildeler til at crawle dit website. Traditionelt har dette koncept primært været anvendt på Googles crawl-adfærd, men fremkomsten af AI-drevne bots har fundamentalt ændret måden, organisationer skal tænke crawl-budget-styring på. Crawl-budget-ligningen består af to centrale variabler: crawl-kapacitet (det maksimale antal sider, en bot kan crawle) og crawl-efterspørgsel (det faktiske antal sider, som botten ønsker at crawle). I AI-tidsalderen er denne dynamik blevet eksponentielt mere kompleks, da bots som GPTBot (OpenAI), Perplexity Bot og ClaudeBot (Anthropic) nu konkurrerer om serverressourcer side om side med traditionelle søgemaskinecrawlere. Disse AI-bots arbejder med andre prioriteter og mønstre end Googlebot, forbruger ofte betydeligt mere båndbredde og har andre indekseringsmål, hvilket gør optimering af crawl-budget ikke længere valgfrit, men essentielt for at opretholde siteperformance og kontrollere driftsomkostninger.
Hvorfor AI-crawlere har ændret spillet
AI-crawlere adskiller sig grundlæggende fra traditionelle søgemaskinebots i deres crawl-mønstre, frekvens og ressourceforbrug. Hvor Googlebot respekterer crawl-budgetgrænser og implementerer avancerede throttling-mekanismer, udviser AI-bots ofte mere aggressiv crawl-adfærd, anmoder nogle gange om det samme indhold flere gange og tager mindre hensyn til serverbelastningssignaler. Forskning viser, at OpenAI’s GPTBot kan bruge 12-15 gange mere båndbredde end Googles crawler på visse websites, især dem med store indholdsbiblioteker eller ofte opdaterede sider. Denne aggressive tilgang stammer fra AI-træningskrav—disse bots skal løbende indtage friskt indhold for at forbedre modelperformance, hvilket skaber en grundlæggende anden crawl-filosofi end søgemaskiner, der fokuserer på indeksering til søgning. Serverpåvirkningen er betydelig: Organisationer rapporterer markante stigninger i båndbreddeomkostninger, CPU-forbrug og serverbelastning direkte forårsaget af AI-bot-trafik. Desuden kan den samlede effekt af flere AI-bots, der crawler samtidigt, forringe brugeroplevelsen, sænke sideindlæsningstider og øge hostingudgifter, hvilket gør forskellen mellem traditionelle og AI-crawlere til en kritisk forretningsmæssig overvejelse snarere end en teknisk kuriositet.
Karakteristik
Traditionelle crawlere (Googlebot)
AI-crawlere (GPTBot, ClaudeBot)
Crawl-frekvens
Adaptiv, respekterer crawl-budget
Aggressiv, kontinuerlig
Båndbreddeforbrug
Moderat, optimeret
Højt, ressourcekrævende
Respekt for robots.txt
Strikt overholdelse
Variabel overholdelse
Cache-adfærd
Avanceret caching
Hyppige genanmodninger
User-Agent-identifikation
Klar, konsistent
Nogle gange obfuskeret
Forretningsmål
Søgeindeksering
Modeltræning/dataindsamling
Omkostningspåvirkning
Minimal
Betydelig (12-15x højere)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Forståelse af crawl-budget kræver, at man mestrer dets to grundlæggende komponenter: crawl-kapacitet og crawl-efterspørgsel. Crawl-kapacitet repræsenterer det maksimale antal URL’er, din server kan håndtere at blive crawlet inden for en given tidsramme, bestemt af flere indbyrdes forbundne faktorer. Denne kapacitet påvirkes af:
Serverressourcer (CPU, RAM, båndbredde)
Responstid (hurtigere svar giver højere crawl-rate)
Infrastrukturkvalitet (brug af CDN, load balancing, cachelag)
Geografisk fordeling (hosting i flere regioner øger kapaciteten)
Crawl-efterspørgsel repræsenterer derimod, hvor mange sider bots faktisk ønsker at crawle, drevet af indholdskarakteristika og bot-prioriteter. Faktorer, der påvirker crawl-efterspørgslen, inkluderer:
Indholdsaktualitet (hyppigt opdaterede sider tiltrækker flere crawls)
Indholdskvalitet og autoritet (højkvalitets-sider får højere crawl-prioritet)
Opdateringsfrekvens (sider opdateret dagligt får mere opmærksomhed end statiske sider)
Sitemap-inklusion (sider i sitemaps får højere crawl-prioritet)
Historiske crawl-mønstre (bots lærer, hvilke sider der ofte ændres)
Optimeringsudfordringen opstår, når crawl-efterspørgslen overstiger crawl-kapaciteten—bots må vælge, hvilke sider de skal crawle, og vigtige opdateringer kan blive overset. Omvendt, hvis crawl-kapaciteten langt overstiger efterspørgslen, spilder du serverressourcer. Målet er at opnå crawl-effektivitet: at maksimere crawl af vigtige sider og minimere spild på indhold med lav værdi. Denne balance bliver stadig mere kompleks i AI-tidsalderen, hvor flere bot-typer med forskellige prioriteter konkurrerer om de samme ressourcer og kræver sofistikerede strategier for at allokere crawl-budgettet effektivt på tværs af alle aktører.
Mål din nuværende crawl-budget-performance
Måling af crawl-budget-performance starter med Google Search Console, der viser crawl-statistik under “Indstillinger”, hvor du kan se daglige crawl-forespørgsler, downloadede bytes og svartider. For at beregne din crawl-effektivitet divideres antallet af succesfulde crawls (HTTP 200-responser) med det samlede antal crawl-forespørgsler; sunde sites opnår typisk 85-95% effektivitet. En formel til basal crawl-effektivitet er: (Succesfulde crawls ÷ samlede crawl-forespørgsler) × 100 = Crawl-effektivitet i %. Ud over Googles data kræver praktisk overvågning:
Analyse af serverlogs med værktøjer som Splunk eller ELK Stack for at finde alt bot-trafik, inklusive AI-crawlere
Overvågning af 4xx- og 5xx-fejl for at identificere sider, der spilder crawl-budget på fejl
Overvågning af crawl-dybde (hvor mange niveauer bots når ned i din sitestruktur)
Måling af responstidstendenser for at identificere performance-fald grundet crawl-belastning
Segmentering af trafik efter user-agent for at forstå, hvilke bots bruger flest ressourcer
For AI-crawler-specifik overvågning giver værktøjer som AmICited.com specialiseret tracking af GPTBot, ClaudeBot og Perplexity Bot-aktivitet og indblik i, hvilke sider disse bots prioriterer, og hvor ofte de vender tilbage. Desuden giver implementering af brugerdefinerede alarmer for usædvanlige crawl-spidser—særligt fra AI-bots—hurtig reaktion på uventet ressourceforbrug. Nøgletal at følge er crawl-omkostning pr. side: del de samlede forbrugte serverressourcer på crawls med antallet af unikke crawlede sider for at se, om du bruger dit crawl-budget effektivt eller spilder ressourcer på sider med lav værdi.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Optimeringsstrategier for AI-crawlere
Optimering af crawl-budget for AI-bots kræver en flerlaget tilgang, der kombinerer teknisk implementering med strategiske beslutninger. De primære optimeringstiltag inkluderer:
Forfining af robots.txt: Bloker AI-bots fra at crawle sider med lav værdi (arkiver, dubletindhold, admin-sektioner) og tillad adgang til kerneindholdet
Dynamiske sitemaps: Opret separate sitemaps for forskellige indholdstyper, prioriter hyppigt opdateret og værdifuldt indhold
Optimering af URL-struktur: Implementér rene, hierarkiske URL-strukturer, der mindsker crawl-dybden og gør vigtige sider nemmere at finde
Selektiv blokering: Brug user-agent-specifikke regler til at tillade Googlebot, mens aggressive AI-crawlere kan begrænses, hvis de forbruger for mange ressourcer
Crawl-delay direktiver: Angiv passende crawl-delay værdier i robots.txt for at drosle bot-forespørgsler (dog kan AI-bots ignorere disse)
Kanonisering: Brug canonical-tags aktivt for at konsolidere dubletindhold og reducere crawl-spild på varianter
Den strategiske beslutning om, hvilke tiltag der vælges, afhænger af din forretningsmodel og indholdsstrategi. E-handelssites kan vælge at blokere AI-crawlere fra produktsider for at forhindre konkurrenters dataindsamling, mens indholdspublishere kan tillade crawling for at opnå synlighed i AI-genererede svar. For sites med reel serverbelastning fra AI-bot-trafik er user-agent specifik blokering i robots.txt den mest direkte løsning: User-agent: GPTBot efterfulgt af Disallow: / blokerer OpenAI’s crawler fuldstændigt. Dette ofrer dog potentiel synlighed i ChatGPT’s svar og andre AI-applikationer. En mere nuanceret strategi er selektiv blokering: tillad AI-crawlere adgang til offentligt indhold, men bloker dem fra følsomme områder, arkiver eller dubletindhold, der spilder crawl-budget uden værdi for botten eller brugerne.
Avancerede teknikker for store sites
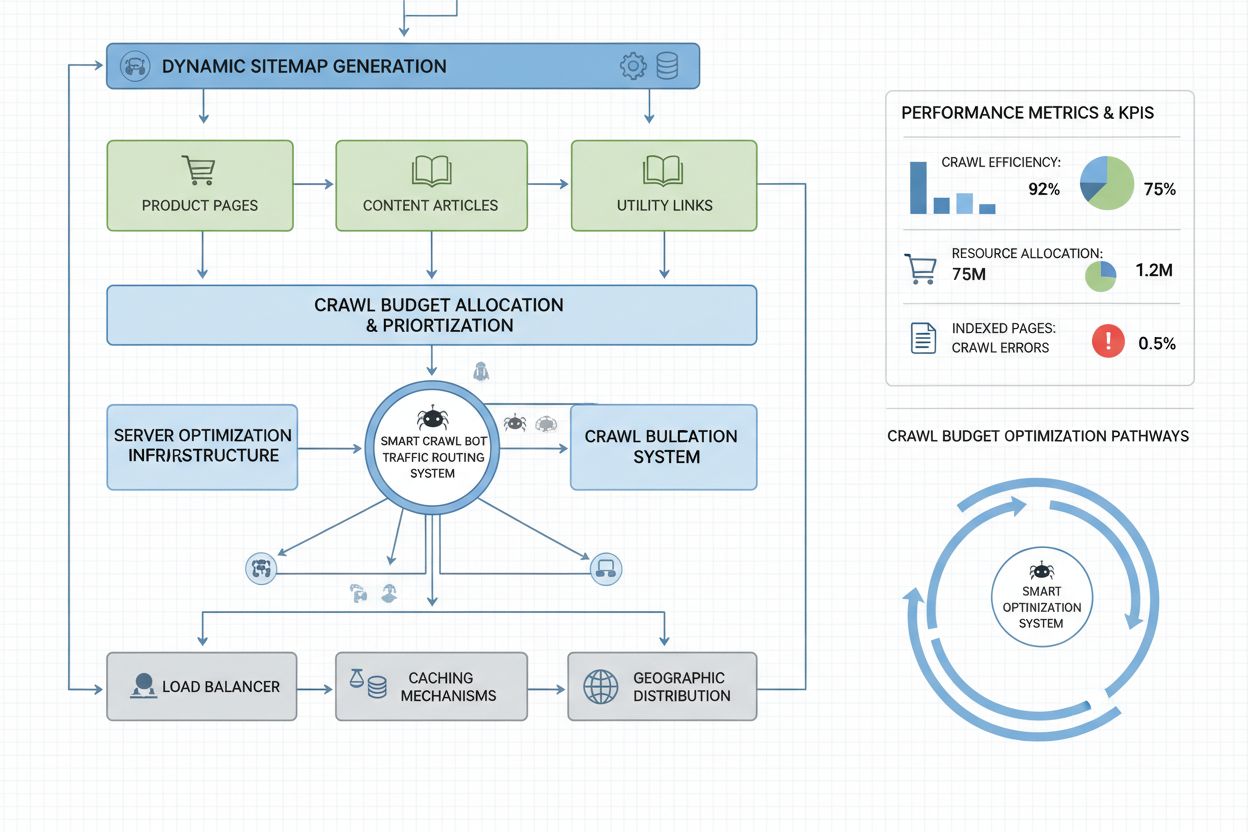
Enterprise-websites med millioner af sider kræver avancerede crawl-budget-optimeringsstrategier ud over basal robots.txt-konfiguration. Dynamiske sitemaps er et afgørende fremskridt, hvor sitemaps genereres i realtid baseret på indholdsaktualitet, vigtighedsscorer og crawl-historik. I stedet for statiske XML-sitemaps med alle sider prioriterer dynamiske sitemaps nyligt opdaterede sider, sider med høj trafik og konverteringspotentiale, så bots fokuserer crawl-budgettet på det mest relevante indhold. URL-segmentering deler sitet op i logiske crawl-zoner med hver deres optimeringsstrategi—nyhedssektioner kan bruge aggressive sitemap-opdateringer for at sikre, at dagligt indhold crawles med det samme, mens evergreen-indhold opdateres sjældnere.
Server-side optimering inkluderer crawl-bevidste caching-strategier, hvor bots får cachede svar, mens brugere får friskt indhold, hvilket reducerer serverbelastningen fra gentagne bot-forespørgsler. Content delivery networks (CDN’er) med bot-specifik routing kan isolere bot-trafik fra brugertrafik og forhindre crawlere i at bruge båndbredde, der ellers var tiltænkt besøgende. Rate limiting per user-agent gør det muligt at drosle AI-bot-forespørgsler, mens Googlebot og brugere får normal hastighed. For virkelig store sites kan distribueret crawl-budget-styring på tværs af flere serverregioner forhindre enkeltpunktsfejl og sikre geografisk load balancing af bot-trafik. Maskinlæringsbaseret crawl-forudsigelse analyserer historiske crawl-mønstre for at forudsige, hvilke sider bots vil anmode om næste gang, så du kan optimere performance og caching proaktivt. Disse enterprise-strategier forvandler crawl-budget fra en begrænsning til en styret ressource, der gør det muligt for store organisationer at betjene milliarder af sider og samtidig opretholde optimal performance for både bots og brugere.
Den strategiske beslutning – blokér eller tillad AI-crawlere
Beslutningen om at blokere eller tillade AI-crawlere er et grundlæggende strategisk valg med betydelige konsekvenser for synlighed, konkurrenceposition og driftsomkostninger. At tillade AI-crawlere giver væsentlige fordele: dit indhold kan blive inkluderet i AI-genererede svar og dermed trække trafik fra ChatGPT, Claude, Perplexity og andre AI-applikationer; dit brand opnår synlighed i en ny distributionskanal; og du får fordel af SEO-signaler fra at blive citeret af AI-systemer. Men disse fordele har en pris: øget serverbelastning og båndbreddeforbrug, mulig træning af konkurrenters AI-modeller på dit indhold og tab af kontrol med, hvordan dit indhold præsenteres og krediteres i AI-svar.
Blokering af AI-crawlere eliminerer disse omkostninger, men ofrer synlighedsfordelene og overlader potentielt markedsandele til konkurrenter, der tillader crawling. Den optimale strategi afhænger af din forretningsmodel: indholdspublishere og nyhedsmedier har ofte fordel af at tillade crawling for at opnå distribution via AI-sammenfatninger; SaaS-virksomheder og e-handelssites kan blokere crawlere for at forhindre konkurrenters indsamling af produktdata; uddannelsesinstitutioner og forskningsorganisationer tillader typisk crawling for at maksimere vidensspredning. En hybrid tilgang er et kompromis: tillad crawling af offentligt indhold, men blokér adgang til følsomme områder, brugergenereret indhold eller fortroligt materiale. Denne strategi maksimerer synlighedsfordelene og beskytter værdifulde aktiver. Desuden viser overvågning med AmICited.com og lignende værktøjer, om dit indhold faktisk bliver citeret af AI-systemer—hvis dit site ikke optræder i AI-svar trods tilladt crawling, kan blokering være mere attraktivt, fordi du bærer crawl-omkostningen uden at opnå synlighed.
Værktøjer og overvågning til crawl-budget-styring
Effektiv crawl-budget-styring kræver specialiserede værktøjer, der giver indblik i bot-adfærd og gør det muligt at træffe databaserede optimeringsbeslutninger. Conductor og Sitebulb tilbyder enterprise-grade crawl-analyse, simulerer hvordan søgemaskiner crawler dit site og finder crawl-ineffektivitet, spildte crawls på fejl-sider og muligheder for bedre budgetallokering. Cloudflare tilbyder bot management på netværksniveau, så du kan styre præcist, hvilke bots der får adgang og implementere rate limiting målrettet AI-crawlere. For AI-crawler-specifik overvågning er AmICited.com den mest omfattende løsning med detaljeret tracking af GPTBot, ClaudeBot, Perplexity Bot og andre AI-crawlere, der viser, hvilke sider bots besøger, hvor ofte de vender tilbage, og om dit indhold optræder i AI-genererede svar.
Analyse af serverlogs er fortsat grundlæggende for crawl-budget-optimering—værktøjer som Splunk, Datadog eller open source ELK Stack gør det muligt at analysere raw access logs og segmentere trafikken efter user-agent, så du kan se, hvilke bots der bruger flest ressourcer, og hvilke sider der får mest crawl-opmærksomhed. Tilpassede dashboards, der viser crawl-tendenser over tid, afslører, om dine optimeringsindsatser virker, og om nye bot-typer dukker op. Google Search Console giver fortsat essentielle data om Googles crawl-adfærd, mens Bing Webmaster Tools tilbyder lignende indsigt for Microsofts crawler. De mest avancerede organisationer implementerer multi-tool-overvågning med Google Search Console til traditionel crawl-data, AmICited.com til AI-crawler-tracking, serverlog-analyse for komplet botsynlighed og specialværktøjer som Conductor til crawl-simulering og effektivitetsanalyse. Denne lagdelte tilgang giver fuldt overblik over, hvordan alle bot-typer interagerer med dit site, så du kan træffe optimeringsbeslutninger baseret på data frem for gæt. Regelmæssig overvågning—helst ugentligt review af crawl-metrics—muliggør hurtig identifikation af problemer som uventede crawl-spidser, stigende fejlrater eller nye aggressive bots, så du kan reagere hurtigt, før crawl-budget-problemer påvirker site-performance eller driftsomkostninger.
Ofte stillede spørgsmål
Hvad er forskellen på crawl-budget for AI-bots vs Googlebot?
AI-bots som GPTBot og ClaudeBot arbejder med andre prioriteter end Googlebot. Hvor Googlebot respekterer crawl-budgetgrænser og implementerer avanceret throttling, udviser AI-bots ofte mere aggressiv crawl-adfærd og bruger 12-15 gange mere båndbredde. AI-bots prioriterer kontinuerlig indholdsindtagelse til modeltræning frem for søgeindeksering, hvilket gør deres crawl-adfærd grundlæggende anderledes og kræver særlige optimeringsstrategier.
Hvor meget crawl-budget bruger AI-bots typisk?
Forskning viser, at OpenAI's GPTBot kan bruge 12-15 gange mere båndbredde end Googles crawler på visse websites, især dem med store indholdsbiblioteker. Det præcise forbrug afhænger af dit sites størrelse, opdateringsfrekvens og hvor mange AI-bots der crawler samtidigt. Flere AI-bots på én gang kan markant øge serverbelastningen og hostingomkostningerne.
Kan jeg blokere specifikke AI-crawlere uden at påvirke SEO?
Ja, du kan blokere specifikke AI-crawlere via robots.txt uden at påvirke traditionel SEO. Dog betyder blokering af AI-crawlere, at du opgiver synlighed i AI-genererede svar fra ChatGPT, Claude, Perplexity og andre AI-applikationer. Beslutningen afhænger af din forretningsmodel—indholdspublishere har typisk fordel af at tillade crawling, mens e-handelssites kan blokere for at forhindre konkurrenters træning.
Hvilken effekt har dårlig styring af crawl-budget på mit site?
Dårlig styring af crawl-budget kan betyde, at vigtige sider ikke bliver crawlet eller indekseret, langsommere indeksering af nyt indhold, øget serverbelastning og båndbreddeomkostninger, forringet brugeroplevelse fordi bottrafik bruger ressourcer, og tabte synlighedsmuligheder både i traditionel søgning og AI-genererede svar. Store sites med millioner af sider er mest udsatte for disse konsekvenser.
Hvor ofte bør jeg overvåge mit crawl-budget?
For optimale resultater bør du overvåge crawl-budget-metrics ugentligt, med daglige tjek under større indholdsudrulninger eller ved uventede trafikstigninger. Brug Google Search Console for traditionel crawl-data, AmICited.com til AI-crawler-tracking og serverlogs for komplet bot-synlighed. Regelmæssig overvågning gør det muligt hurtigt at identificere problemer, før de påvirker siteperformance.
Er robots.txt effektiv til at kontrollere AI-bot-crawling?
Robots.txt har varierende effektivitet over for AI-bots. Hvor Googlebot strengt overholder robots.txt-direktiver, viser AI-bots inkonsekvent efterlevelse—nogle respekterer reglerne, mens andre ignorerer dem. For mere pålidelig kontrol kan du implementere brugeragent-specifik blokering, rate limiting på serverniveau eller bruge CDN-baserede bot-management-værktøjer som Cloudflare for mere detaljeret styring.
Hvad er sammenhængen mellem crawl-budget og AI-synlighed?
Crawl-budget påvirker direkte AI-synlighed, fordi AI-bots ikke kan citere eller referere indhold, de ikke har crawlet. Hvis dine vigtige sider ikke bliver crawlet på grund af budgetbegrænsninger, kommer de ikke med i AI-genererede svar. Optimering af crawl-budget sikrer, at dit bedste indhold bliver opdaget af AI-bots og øger chancen for at blive citeret i ChatGPT-, Claude- og Perplexity-svar.
Hvordan prioriterer jeg, hvilke sider AI-bots skal crawle?
Prioritér sider via dynamiske sitemaps, der fremhæver nyligt opdateret indhold, sider med høj trafik og sider med konverteringspotentiale. Brug robots.txt til at blokere sider med lav værdi, som arkiver og dubletter. Implementér rene URL-strukturer og strategisk intern linkning for at lede bots mod vigtigt indhold. Overvåg hvilke sider AI-bots faktisk crawler med værktøjer som AmICited.com for at finjustere din strategi.
Overvåg dit AI crawl-budget effektivt
Følg, hvordan AI-bots crawler dit site, og optimer din synlighed i AI-genererede svar med AmICited.com's omfattende AI-crawler-overvågningsplatform.
Hvad er Crawl Budget for AI? Forståelse af AI-botters ressourceallokering
Lær hvad crawl budget for AI betyder, hvordan det adskiller sig fra traditionelle søgemaskiners crawl budgetter, og hvorfor det er vigtigt for din brands synlig...
Crawl budget er det antal sider, søgemaskiner crawler på dit website inden for et tidsrum. Lær hvordan du optimerer crawl budget for bedre indeksering og SEO-yd...
Crawlability er søgemaskiners evne til at tilgå og navigere på websider. Lær hvordan crawlere arbejder, hvad der blokerer dem, og hvordan du optimerer dit site ...
11 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.