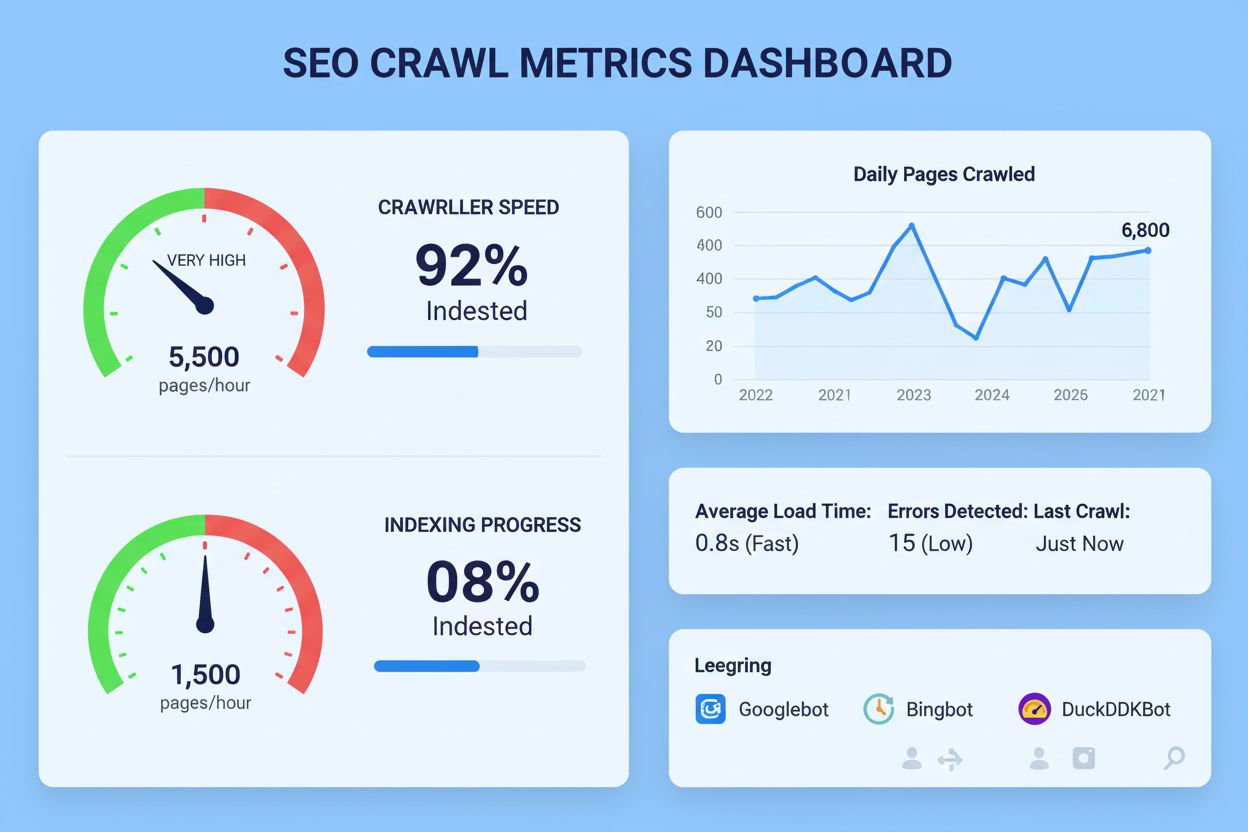
Crawl Rate
Crawl-hastighed er den hastighed, hvormed søgemaskiner crawler dit website. Lær, hvordan det påvirker indeksering, SEO-ydeevne, og hvordan du optimerer det for ...
9 min læsning
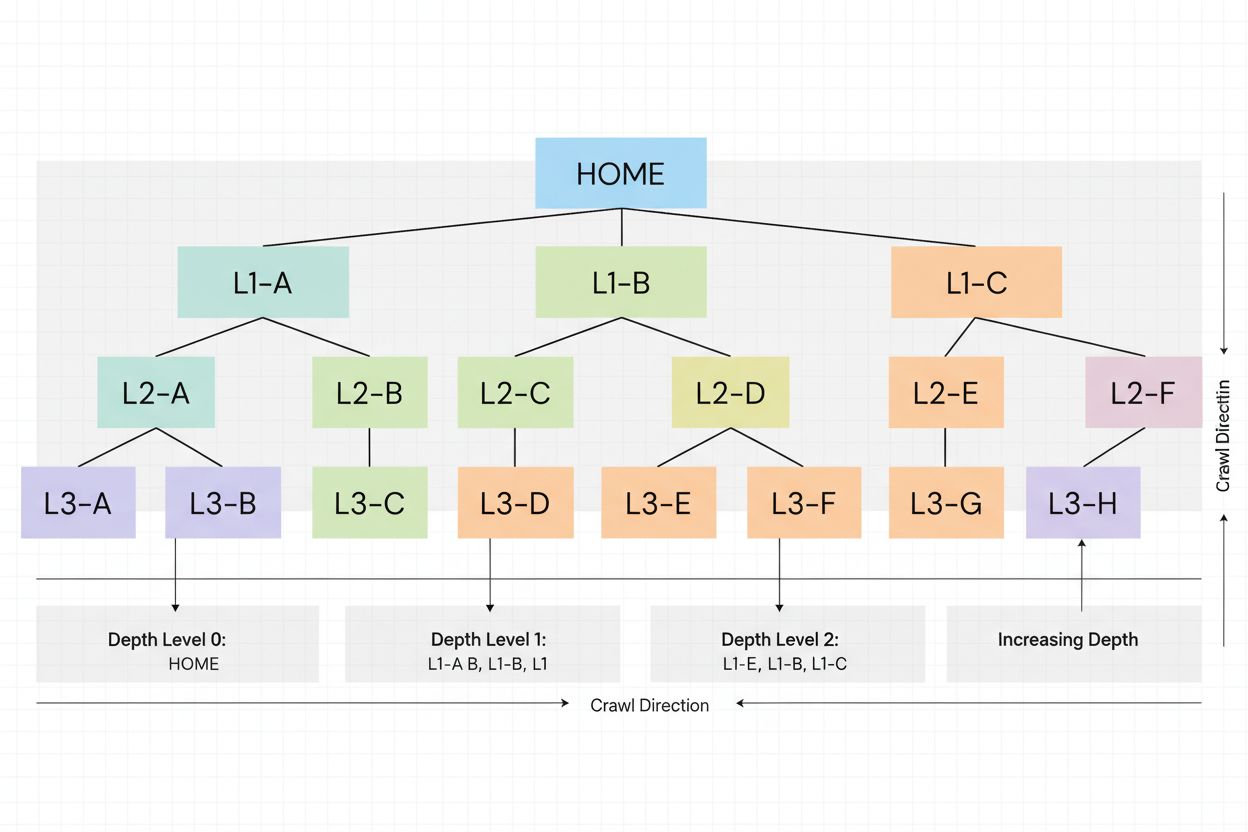
Crawl-dybde refererer til, hvor langt ned i en hjemmesides hierarkiske struktur søgemaskinernes crawlere kan nå under en enkelt crawl-session. Det måler antallet af klik eller trin fra forsiden, der kræves for at nå en bestemt side, hvilket direkte påvirker, hvilke sider der bliver indekseret, og hvor ofte de bliver crawlet inden for sidens tildelte crawl-budget.
Crawl-dybde refererer til, hvor langt ned i en hjemmesides hierarkiske struktur søgemaskinernes crawlere kan nå under en enkelt crawl-session. Det måler antallet af klik eller trin fra forsiden, der kræves for at nå en bestemt side, hvilket direkte påvirker, hvilke sider der bliver indekseret, og hvor ofte de bliver crawlet inden for sidens tildelte crawl-budget.
Crawl-dybde er et grundlæggende teknisk SEO-begreb, der refererer til, hvor langt ned i en hjemmesides hierarkiske struktur søgemaskinernes crawlere kan navigere under en enkelt crawl-session. Mere specifikt måler det antallet af klik eller trin, der kræves fra forsiden for at nå en bestemt side i din hjemmesides interne linkstruktur. En hjemmeside med høj crawl-dybde betyder, at søgemaskinens bots kan få adgang til og indeksere mange sider på hele sitet, mens en hjemmeside med lav crawl-dybde indikerer, at crawlere måske ikke når de dybere sider, før de har brugt deres tildelte ressourcer. Dette begreb er kritisk, fordi det direkte bestemmer, hvilke sider der bliver indekseret, hvor ofte de bliver crawlet, og i sidste ende deres synlighed i søgeresultaterne (SERPs).
Vigtigheden af crawl-dybde er steget i de senere år på grund af den eksplosive vækst i webindhold. Med Googles indeks, der indeholder over 400 milliarder dokumenter, og den stigende mængde AI-genereret indhold, oplever søgemaskiner hidtil usete begrænsninger på crawl-ressourcer. Det betyder, at hjemmesider med dårlig crawl-dybdeoptimering risikerer, at vigtige sider ikke bliver indekseret eller kun sjældent bliver crawlet, hvilket har en betydelig indvirkning på deres organiske synlighed. At forstå og optimere crawl-dybde er derfor afgørende for enhver hjemmeside, der ønsker at maksimere sin tilstedeværelse i søgemaskinerne.
Begrebet crawl-dybde stammer fra, hvordan søgemaskinernes crawlere (også kaldet webspidere eller bots) arbejder. Når Googles Googlebot eller andre søgemaskinens bots besøger en hjemmeside, følger de en systematisk proces: de starter på forsiden og følger interne links for at opdage flere sider. Crawleren tildeler en begrænset mængde tid og ressourcer til hver hjemmeside, kendt som crawl-budget. Dette budget bestemmes af to faktorer: crawl-kapacitetsgrænse (hvor meget crawleren kan håndtere uden at overbelaste serveren) og crawl-efterspørgsel (hvor vigtig og hyppigt opdateret siden er). Jo dybere siderne er begravet i din hjemmesides struktur, desto mindre sandsynligt er det, at crawlere når dem, før crawl-budgettet er opbrugt.
Historisk set var hjemmesidestrukturer relativt enkle, hvor det meste vigtige indhold var inden for 2-3 klik fra forsiden. Men efterhånden som e-handelssider, nyhedsportaler og indholdstunge hjemmesider voksede eksplosivt, skabte mange organisationer dybt indlejrede strukturer med sider 5, 6 eller endda 10+ niveauer dybe. Forskning fra seoClarity og andre SEO-platforme har vist, at sider på dybde 3 og derunder generelt klarer sig dårligere i organiske søgeresultater sammenlignet med sider tættere på forsiden. Denne præstationsforskel findes, fordi crawlere prioriterer sider tættere på roden, og disse sider også opsamler mere linkautoritet (rankingkraft) gennem intern linking. Forholdet mellem crawl-dybde og indekseringsrater er særligt udtalt på store hjemmesider med tusinder eller millioner af sider, hvor crawl-budget bliver en kritisk begrænsende faktor.
Fremkomsten af AI-søgemaskiner som Perplexity, ChatGPT og Google AI Overviews har tilføjet en ny dimension til optimering af crawl-dybde. Disse AI-systemer bruger deres egne specialiserede crawlere (såsom PerplexityBot og GPTBot), der kan have andre crawl-mønstre og prioriteter end traditionelle søgemaskiner. Men det grundlæggende princip er det samme: sider, der er let tilgængelige og godt integreret i hjemmesidens struktur, er mere tilbøjelige til at blive opdaget, crawlet og citeret som kilder i AI-genererede svar. Dette gør crawl-dybdeoptimering relevant ikke kun for traditionel SEO, men også for AI-søgesynlighed og generative engine optimization (GEO).
| Begreb | Definition | Perspektiv | Måling | Indvirkning på SEO |
|---|---|---|---|---|
| Crawl-dybde | Hvor langt ned i sidens hierarki crawlere navigerer baseret på interne links og URL-struktur | Søgemaskinens crawlers syn | Antal klik/trin fra forsiden | Påvirker indekseringsfrekvens og dækning |
| Klik-dybde | Antal brugerklik der kræves for at nå en side fra forsiden via korteste vej | Brugerens perspektiv | Faktiske klik, der kræves | Påvirker brugeroplevelse og navigation |
| Side-dybde | Positionen af en side i hjemmesidens hierarkiske struktur | Strukturelt perspektiv | URL-indlejringsniveau | Påvirker fordeling af linkautoritet |
| Crawl-budget | Samlede ressourcer (tid/båndbredde) tildelt til at crawle en hjemmeside | Ressourcetildeling | Sider crawlet pr. dag | Bestemmer hvor mange sider der bliver indekseret |
| Crawl-effektivitet | Hvor effektivt crawlere navigerer og indekserer hjemmesidens indhold | Optimeringsperspektiv | Sider indekseret vs. brugt crawl-budget | Maksimerer indeksering inden for budgetgrænser |
For at forstå hvordan crawl-dybde fungerer, skal man se på mekanikken bag, hvordan søgemaskinens crawlere navigerer på hjemmesider. Når Googlebot eller en anden crawler besøger dit site, starter den på forsiden (dybde 0) og følger interne links for at opdage flere sider. Hver side, der linkes fra forsiden, er på dybde 1, sider der linkes fra disse sider er på dybde 2 osv. Crawleren følger dog ikke nødvendigvis en lineær sti; den opdager flere sider på hvert niveau, før den går dybere. Men crawlerens rejse er begrænset af crawl-budgettet, som sætter grænser for, hvor mange sider den kan besøge inden for en given tidsramme.
Det tekniske forhold mellem crawl-dybde og indeksering styres af flere faktorer. For det første spiller crawl-prioritering en central rolle—søgemaskiner crawler ikke alle sider lige meget. De prioriterer sider baseret på opfattet vigtighed, aktualitet og relevans. Sider med flere interne links, højere autoritet og nylige opdateringer bliver crawlet oftere. For det andet påvirker URL-strukturen selv crawl-dybden. En side på /kategori/underkategori/produkt/ har en højere crawl-dybde end en side på /produkt/, selvom begge er linket fra forsiden. For det tredje fungerer redirect-kæder og døde links som forhindringer, der spilder crawl-budget. En redirect-kæde tvinger crawleren til at følge flere redirects, før den når den endelige side og bruger ressourcer, der kunne have været brugt på andet indhold.
Den tekniske implementering af crawl-dybdeoptimering involverer flere nøglestrategier. Intern linkarkitektur er afgørende—ved strategisk at linke vigtige sider fra forsiden og sider med høj autoritet reducerer du deres effektive crawl-dybde og øger sandsynligheden for hyppig crawling. XML-sitemaps giver crawlere et direkte kort over din hjemmesides struktur, så de kan opdage sider mere effektivt uden kun at være afhængige af links. Hastigheden på sitet er også kritisk; hurtigere sider indlæses hurtigere, hvilket gør det muligt for crawlere at nå flere sider inden for deres tildelte budget. Endelig giver robots.txt og noindex-tags dig mulighed for at styre, hvilke sider crawlere skal prioritere, og forhindrer dem i at spilde budget på sider af lav værdi som duplikeret indhold eller admin-sider.
De praktiske konsekvenser af crawl-dybde rækker langt ud over tekniske SEO-målinger—de har direkte indvirkning på forretningsresultater. For e-handelswebsites betyder dårlig crawl-dybdeoptimering, at produktsider, der ligger dybt i kategorihierarkier, måske ikke bliver indekseret eller kun sjældent. Det resulterer i reduceret organisk synlighed, færre produktvisninger i søgeresultater og i sidste ende tabt salg. En undersøgelse fra seoClarity viste, at sider med højere crawl-dybde havde markant lavere indekseringsrater, hvor sider på dybde 4+ blev crawlet op til 50% mindre hyppigt end sider på dybde 1-2. For store detailhandlere med tusindvis af produkter kan dette betyde millioner af kroner i tabt organisk omsætning.
For indholdstunge hjemmesider som nyhedssider, blogs og vidensbaser påvirker crawl-dybdeoptimering direkte indholdsopdagelse. Artikler, der udgives dybt i kategoristrukturen, når måske aldrig Googles indeks, hvilket betyder, at de genererer nul organisk trafik uanset kvalitet eller relevans. Dette er særligt problematisk for nyhedssider, hvor aktualitet er afgørende—hvis nye artikler ikke bliver crawlet og indekseret hurtigt nok, mister de muligheden for at rangere på aktuelle emner. Udgivere, der optimerer crawl-dybde ved at flade strukturen ud og forbedre intern linking, oplever markante stigninger i indekserede sider og organisk trafik.
Forholdet mellem crawl-dybde og fordeling af linkautoritet har stor forretningsmæssig betydning. Linkautoritet (også kaldet PageRank eller rankingkraft) flyder gennem interne links fra forsiden og udad. Sider tættere på forsiden opsamler mere linkautoritet, hvilket gør dem mere tilbøjelige til at rangere på konkurrencedygtige søgeord. Ved at optimere crawl-dybde og sikre, at vigtige sider er inden for 2-3 klik fra forsiden, kan virksomheder koncentrere linkautoriteten på deres mest værdifulde sider—typisk produktsider, servicesider eller hjørnestenindhold. Denne strategiske fordeling af linkautoritet kan markant forbedre placeringer på værdifulde søgeord.
Derudover påvirker crawl-dybdeoptimering crawl-budgeteffektiviteten, hvilket bliver stadig vigtigere, efterhånden som hjemmesider vokser. Store websites med millioner af sider står over for alvorlige crawl-budgetbegrænsninger. Ved at optimere crawl-dybden, fjerne duplikeret indhold, fikse døde links og eliminere redirect-kæder kan hjemmesider sikre, at crawlere bruger deres budget på værdifuldt, unikt indhold i stedet for at spilde ressourcer på sider af lav værdi. Dette er især kritisk for virksomhedshjemmesider og store e-handelsplatforme, hvor crawl-budgetstyring kan betyde forskellen på, om 80% eller kun 40% af siderne bliver indekseret.
Fremkomsten af AI-søgemaskiner og generative AI-systemer har introduceret nye dimensioner til crawl-dybdeoptimering. ChatGPT, drevet af OpenAI, bruger GPTBot-crawleren til at opdage og indeksere webindhold. Perplexity, en førende AI-søgemaskine, benytter PerplexityBot til at crawle nettet efter kilder. Google AI Overviews (tidligere SGE) anvender Googles egne crawlere til at indsamle information til AI-genererede sammendrag. Claude, Anthropic’s AI-assistent, crawler også webindhold til træning og søgning. Hver af disse systemer har forskellige crawl-mønstre, prioriteter og ressourcebegrænsninger sammenlignet med traditionelle søgemaskiner.
Det vigtigste er, at crawl-dybdeprincipper gælder også for AI-søgemaskiner. Sider, der er let tilgængelige, godt linket og strukturelt fremtrædende, er mere tilbøjelige til at blive opdaget af AI-crawlere og citeret som kilder i AI-genererede svar. Forskning fra AmICited og andre AI-overvågningsplatforme viser, at hjemmesider med optimeret crawl-dybde får flere citationer i AI-søgeresultater. Det skyldes, at AI-systemer prioriterer kilder, der er autoritative, tilgængelige og hyppigt opdateret—alle egenskaber, der hænger sammen med lav crawl-dybde og god intern linkstruktur.
Der er dog nogle forskelle i, hvordan AI-crawlere opfører sig i forhold til Googlebot. AI-crawlere kan være mere aggressive i deres crawl-mønstre og kan potentielt bruge mere båndbredde. De kan også have andre præferencer for indholdstyper og aktualitet. Nogle AI-systemer prioriterer nyligt opdateret indhold tungere end traditionelle søgemaskiner, hvilket gør crawl-dybdeoptimering endnu vigtigere for at opretholde synlighed i AI-søgeresultater. Derudover respekterer AI-crawlere måske ikke visse direktiver som robots.txt eller noindex-tags på samme måde som traditionelle søgemaskiner, selvom dette er under udvikling, efterhånden som AI-virksomheder arbejder på at tilpasse sig SEO-best practices.
For virksomheder, der fokuserer på AI-søgesynlighed og generative engine optimization (GEO), tjener optimering af crawl-dybde et dobbelt formål: det forbedrer traditionel SEO og øger samtidig sandsynligheden for, at AI-systemer opdager, crawler og citerer dit indhold. Det gør crawl-dybdeoptimering til en grundlæggende strategi for enhver organisation, der ønsker synlighed på både traditionelle og AI-drevne søgeplatforme.
Optimering af crawl-dybde kræver en systematisk tilgang, der adresserer både strukturelle og tekniske aspekter af din hjemmeside. Følgende best practices har vist sig effektive på tværs af tusindvis af websites:
For store virksomhedshjemmesider med tusindvis eller millioner af sider bliver crawl-dybdeoptimering stadig mere kompleks og kritisk. Virksomhedssites står ofte over for alvorlige crawl-budgetbegrænsninger, hvilket gør det essentielt at implementere avancerede strategier. En tilgang er crawl-budgetallokering, hvor du strategisk beslutter, hvilke sider der fortjener crawl-ressourcer baseret på forretningsværdi. Sider med høj værdi (produktsider, servicesider, hjørnestenindhold) bør holdes på lavere dybder og ofte linkes til, mens sider med lav værdi (arkivindhold, duplikerede sider, tyndt indhold) bør noindexeres eller nedprioriteres.
En anden avanceret strategi er dynamisk intern linking, hvor du bruger datadrevne indsigter til at identificere, hvilke sider der har brug for flere interne links for at forbedre deres crawl-dybde. Værktøjer som seoClarity’s Internal Link Analysis kan identificere sider på for stor dybde med få interne links og derved afsløre muligheder for at forbedre crawl-effektiviteten. Derudover giver logfilanalyse dig mulighed for at se præcis, hvordan crawlere navigerer på dit site, og afslører flaskehalse og ineffektivitet i din crawl-dybdestruktur. Ved at analysere crawleradfærd kan du identificere sider, der bliver crawlet ineffektivt og optimere deres tilgængelighed.
For flersprogede hjemmesider og internationale sites bliver crawl-dybdeoptimering endnu vigtigere. Hreflang-tags og korrekt URL-struktur for forskellige sprogversioner kan påvirke crawl-effektiviteten. Ved at sikre, at hver sprogversion har en optimeret crawl-dybdestruktur, maksimerer du indekseringen på alle markeder. Tilsvarende betyder mobile-first indeksering, at crawl-dybdeoptimering skal tage højde for både desktop- og mobilversioner af dit site, så vigtigt indhold er tilgængeligt på begge platforme.
Vigtigheden af crawl-dybde udvikler sig i takt med søgeteknologiens fremskridt. Med fremkomsten af AI-søgemaskiner og generative AI-systemer bliver crawl-dybdeoptimering relevant for en bredere målgruppe end traditionelle SEO-specialister. Efterhånden som AI-systemer bliver mere avancerede, kan de udvikle andre crawl-mønstre og prioriteter, hvilket potentielt gør crawl-dybdeoptimering endnu mere kritisk. Derudover lægger den stigende mængde AI-genereret indhold pres på Googles indeks, hvilket gør crawl-budgetstyring mere vigtigt end nogensinde.
Fremadrettet kan vi forvente, at flere tendenser former crawl-dybdeoptimering. For det første vil AI-drevet crawl-optimering blive mere sofistikeret og bruge maskinlæring til at identificere optimale crawl-dybdestrukturer for forskellige typer hjemmesider. For det andet vil real-time crawl-overvågning blive standard, så hjemmesideejere kan se præcis, hvordan crawlere navigerer på deres sites og foretage øjeblikkelige justeringer. For det tredje vil crawl-dybdemålinger blive mere integreret i SEO-platforme og analysetools, hvilket gør det lettere for ikke-tekniske markedsførere at forstå og optimere denne kritiske faktor.
Forholdet mellem crawl-dybde og AI-søgesynlighed vil sandsynligvis blive et hovedfokusområde for SEO-specialister. Efterhånden som flere brugere benytter AI-søgemaskiner til informationssøgning, skal virksomheder optimere ikke kun til traditionel søgning, men også til AI-opdagelighed. Det betyder, at crawl-dybdeoptimering bliver en del af en bredere generative engine optimization (GEO)-strategi, der omfatter både traditionel SEO og AI-søgesynlighed. Organisationer, der mestrer crawl-dybdeoptimering tidligt, vil have en konkurrencefordel i det AI-drevne søgelandskab.
Endelig kan begrebet crawl-dybde udvikle sig i takt med, at søgeteknologien bliver mere avanceret. Fremtidige søgemaskiner kan bruge andre metoder til at opdage og indeksere indhold, hvilket potentielt mindsker betydningen af traditionel crawl-dybde. Det underliggende princip—at let tilgængeligt, velstruktureret indhold har større sandsynlighed for at blive opdaget og rangeret—vil dog sandsynligvis forblive relevant, uanset hvordan søgeteknologien udvikler sig. Derfor er investering i crawl-dybdeoptimering i dag en solid langsigtet strategi for at opretholde søgesynlighed på tværs af nuværende og fremtidige søgeplatforme.
Crawl-dybde måler, hvor langt søgemaskinens bots navigerer gennem dit hjemmesides hierarki baseret på interne links og URL-struktur, mens klik-dybde måler, hvor mange brugerklik der kræves for at nå en side fra forsiden. En side kan have en klik-dybde på 1 (linket i footeren), men en crawl-dybde på 3 (indlejret i URL-strukturen). Crawl-dybde er fra søgemaskinens perspektiv, mens klik-dybde er fra brugerens perspektiv.
Crawl-dybde påvirker ikke direkte placeringer, men det har stor indflydelse på, om sider overhovedet bliver indekseret. Sider, der er begravet dybt i din hjemmesides struktur, er mindre tilbøjelige til at blive crawlet inden for det tildelte crawl-budget, hvilket betyder, at de måske ikke bliver indekseret eller opdateret ofte. Denne reducerede indeksering og aktualitet kan indirekte skade placeringerne. Sider tættere på forsiden får typisk mere crawl-opmærksomhed og linkautoritet, hvilket giver dem bedre rankingpotentiale.
De fleste SEO-eksperter anbefaler, at vigtige sider holdes inden for 3 klik fra forsiden. Det sikrer, at de let kan opdages af både søgemaskiner og brugere. For større hjemmesider med tusindvis af sider er en vis dybde nødvendig, men målet bør være at holde kritiske sider så overfladiske som muligt. Sider på dybde 3 og derover klarer sig generelt dårligere i søgeresultaterne på grund af reduceret crawl-frekvens og fordeling af linkautoritet.
Crawl-dybde påvirker direkte, hvor effektivt du bruger dit crawl-budget. Google tildeler et specifikt crawl-budget til hver hjemmeside baseret på crawl-kapacitetsgrænse og crawl-efterspørgsel. Hvis din hjemmeside har overdreven crawl-dybde med mange sider begravet dybt, kan crawlere opbruge deres budget, før alle vigtige sider nås. Ved at optimere crawl-dybden og reducere unødvendige sidelags sikrer du, at dit mest værdifulde indhold bliver crawlet og indekseret inden for det tildelte budget.
Ja, du kan forbedre crawl-effektiviteten uden at omstrukturere hele din hjemmeside. Strategisk intern linking er den mest effektive tilgang—link vigtige dybe sider fra forsiden, kategorisider eller indhold med høj autoritet. Opdatering af dit XML-sitemap regelmæssigt, reparation af døde links og reduktion af redirect-kæder hjælper også crawlere med at nå sider mere effektivt. Disse taktikker forbedrer crawl-dybden uden at kræve arkitektoniske ændringer.
AI-søgemaskiner som Perplexity, ChatGPT og Google AI Overviews bruger deres egne specialiserede crawlere (PerplexityBot, GPTBot osv.), der kan have andre crawl-mønstre end Googlebot. Disse AI-crawlere respekterer stadig principperne om crawl-dybde—sider, der er let tilgængelige og godt linket, er mere tilbøjelige til at blive opdaget og brugt som kilder. Optimering af crawl-dybde gavner både traditionelle søgemaskiner og AI-systemer og forbedrer din synlighed på alle søgeplatforme.
Værktøjer som Google Search Console, Screaming Frog SEO Spider, seoClarity og Hike SEO tilbyder analyse og visualisering af crawl-dybde. Google Search Console viser crawl-statistikker og frekvens, mens specialiserede SEO-crawlere visualiserer din hjemmesides hierarkiske struktur og identificerer sider med overdreven dybde. Disse værktøjer hjælper dig med at finde muligheder for optimering og følge forbedringer i crawl-effektiviteten over tid.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Crawl-hastighed er den hastighed, hvormed søgemaskiner crawler dit website. Lær, hvordan det påvirker indeksering, SEO-ydeevne, og hvordan du optimerer det for ...

Crawlability er søgemaskiners evne til at tilgå og navigere på websider. Lær hvordan crawlere arbejder, hvad der blokerer dem, og hvordan du optimerer dit site ...

Crawl-frekvens er, hvor ofte søgemaskiner og AI-crawlere besøger dit site. Lær, hvad der påvirker crawl-hastigheder, hvorfor det betyder noget for SEO og AI-syn...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.