JSON-LD: Komplet guide til implementering og SEO-fordele
Lær hvad JSON-LD er, og hvordan du implementerer det til SEO. Opdag fordele ved struktureret data markup for Google, ChatGPT, Perplexity og synlighed i AI-søgni...
14 min læsning
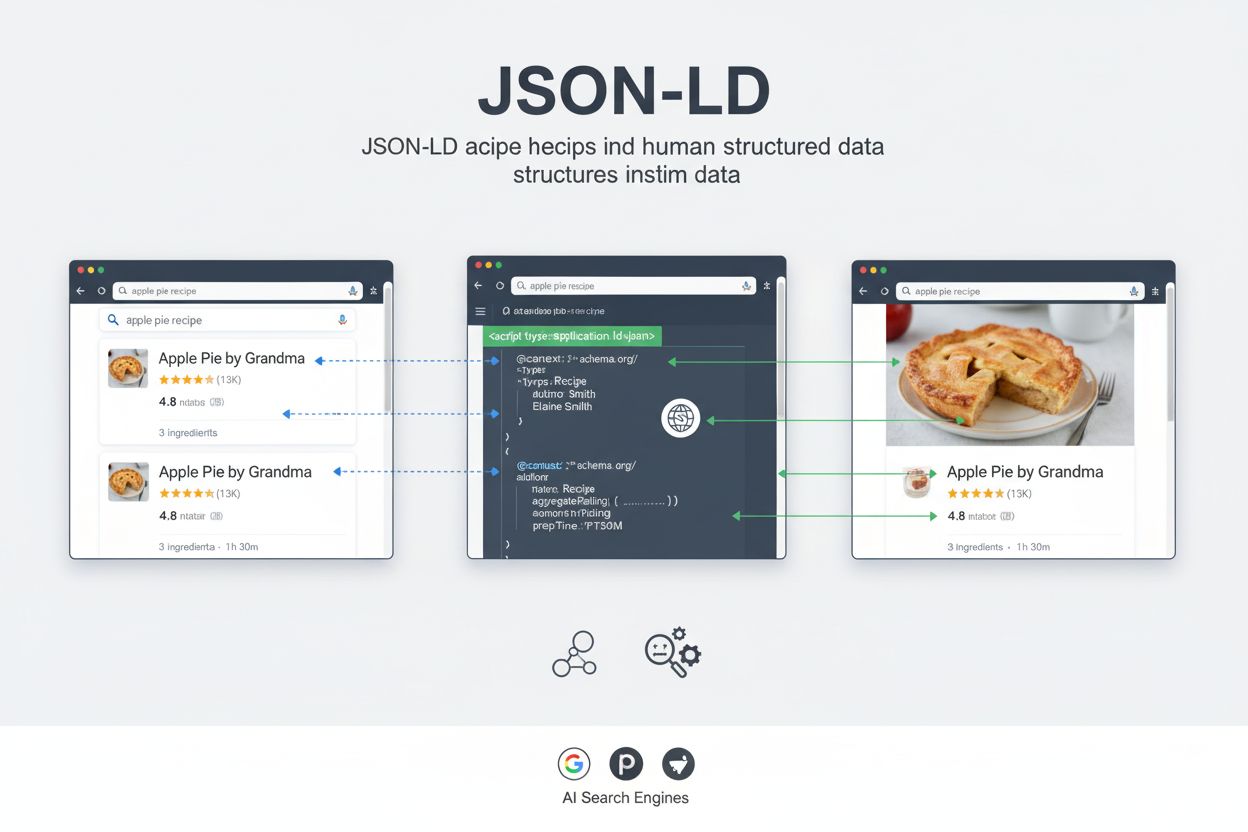
JSON-LD (JavaScript Object Notation for Linked Data) er et letvægtsformat, standardiseret af W3C, til at udtrykke strukturerede data ved hjælp af JSON-syntaks, hvilket gør det muligt for søgemaskiner og AI-systemer at forstå webindhold gennem schema.org-vokabular. Det indlejres i websider som maskinlæsbar markup, der hjælper søgemaskiner med at vise rige resultater og forbedrer indholdsopdagelse på tværs af AI-drevne platforme.
JSON-LD (JavaScript Object Notation for Linked Data) er et letvægtsformat, standardiseret af W3C, til at udtrykke strukturerede data ved hjælp af JSON-syntaks, hvilket gør det muligt for søgemaskiner og AI-systemer at forstå webindhold gennem schema.org-vokabular. Det indlejres i websider som maskinlæsbar markup, der hjælper søgemaskiner med at vise rige resultater og forbedrer indholdsopdagelse på tværs af AI-drevne platforme.
JSON-LD står for JavaScript Object Notation for Linked Data og repræsenterer et letvægts, standardiseret format til at udtrykke strukturerede data på websider. Etableret som en W3C-anbefaling siden januar 2014, kombinerer JSON-LD enkelheden fra JSON-syntaks med den semantiske styrke fra linked data-vokabularer, især schema.org. I modsætning til andre formater for strukturerede data, der blander markup med HTML-indhold, indlejres JSON-LD som et separat <script>-tag i sidens header eller body, hvilket holder data adskilt fra præsentationsmarkuppen. Denne adskillelse gør JSON-LD usædvanligt let at implementere, vedligeholde og skalere på tværs af store websites og content management-systemer.
Hovedformålet med JSON-LD er at give maskinlæsbar kontekst, der hjælper søgemaskiner, AI-systemer og andre webapplikationer med at forstå betydningen og relationerne i websidens indhold. Når det er korrekt implementeret, gør JSON-LD det muligt for søgemaskiner at vise rige resultater – forbedrede søgeresultater, der inkluderer vurderinger, priser, billeder, begivenhedsdetaljer og andre strukturerede informationer. For AI-drevne søgeplatforme som ChatGPT, Perplexity, Google AI Overviews og Claude fungerer JSON-LD som en vigtig bro mellem menneskelæsbart indhold og maskinfortolkelige data, hvilket forbedrer nøjagtigheden og relevansen af AI-genererede svar og citater.
JSON-LD er blevet det anbefalede format for strukturerede data af Google og andre store søgemaskiner, fordi det minimerer implementeringsfejl og fungerer problemfrit med moderne webteknologier, herunder JavaScript-frameworks og dynamisk indholdsgenerering. Formatets fleksibilitet gør det muligt at udtrykke komplekse, indlejrede datastrukturer, hvilket gør det velegnet til forskellige indholdstyper – fra simple produktinformationer til indviklede organisationshierarkier og begivenhedsdetaljer.
JSON-LD opstod ud fra behovet for at bygge bro mellem traditionelle JSON-dataformater og semantiske webstandarder. Før JSON-LD brugte udviklere, der arbejdede med linked data, typisk RDF/XML eller Turtle-formater, som var kraftfulde, men komplekse og ikke naturligt tilpasset webudviklingspraksis. Udviklingen af JSON-LD begyndte i de tidlige 2010’ere som en del af W3C JSON-LD Community Group, idet man erkendte, at JSON var blevet den de facto-standard for web-API’er og dataudveksling. Formatet blev officielt standardiseret af W3C i 2014, med efterfølgende forbedringer, der førte til, at JSON-LD 1.1 blev en fuld W3C-anbefaling i 2020.
Brugen af JSON-LD tog kraftigt fart, efter at Google og andre store søgemaskiner begyndte at anbefale det som det foretrukne format for schema.org-markup i 2013. Denne anbefaling var skelsættende, fordi den signalerede til webudviklingsmiljøet, at JSON-LD ikke blot var en akademisk øvelse, men en praktisk og produktionsklar løsning på virkelige SEO- og indholdsopdagelsesudfordringer. Gennem det sidste årti er JSON-LD-adoptionen vokset eksplosivt, og de nyeste tal viser, at 41% af alle websites nu bruger JSON-LD til strukturering af data, op fra blot 34% i 2022. Blandt websites, der implementerer en eller anden form for strukturerede data, bruges JSON-LD af cirka 70%, hvilket gør det til det dominerende format i landskabet for strukturerede data.
Udviklingen af JSON-LD er også blevet påvirket af fremkomsten af AI-drevne søgemaskiner og store sprogmodeller. Efterhånden som platforme som ChatGPT, Perplexity og Google AI Overviews blev almindelige, voksede betydningen af JSON-LD, fordi disse systemer i høj grad er afhængige af strukturerede data for at udtrække præcis og kontekstuel information fra websider. Formatets evne til tydeligt at definere entity-typer, relationer og egenskaber gør det uvurderligt for træning og drift af AI-systemer, der skal forstå webindhold i stor skala.
JSON-LD-dokumenter følger standard JSON-syntaks, men inkorporerer særlige reserverede nøgleord med @-præfiks, der giver semantisk betydning. De mest grundlæggende af disse nøgleord er @context, @type og @id. @context-egenskaben angiver vokabular-namespace – typisk https://schema.org – der definerer betydningen af alle egenskaber og typer i markuppen. Denne kontekst fungerer som en namespace-erklæring, svarende til XML-namespaces, og sikrer, at egenskabsnavne fortolkes ensartet på tværs af forskellige systemer og platforme.
@type-egenskaben angiver skematype for den beskrevne entity, såsom Product, Article, Event, Organization eller LocalBusiness. Hver type i schema.org har et tilhørende sæt egenskaber, der kan bruges til at beskrive instanser af den type. For eksempel kan en Product-type inkludere egenskaber som name, description, price, image, aggregateRating og offers. @id-egenskaben giver en unik identifikator for entiteten, typisk en URL, der fører til mere information om denne entity.
Ud over disse kerne-nøgleord indeholder JSON-LD-dokumenter tilpassede egenskaber, der direkte kortlægges til schema.org-vokabular. Disse egenskaber kan indeholde simple værdier (strenge, tal, datoer) eller komplekse, indlejrede objekter, der repræsenterer relaterede entiteter. For eksempel kan en Product-entity have en offers-egenskab, der indeholder et indlejret Offer-objekt med sit eget @type og egenskaber som price og priceCurrency. Denne indlejringsmulighed gør det muligt for JSON-LD at udtrykke sofistikerede datarelationer og hierarkier, som ville være besværlige at repræsentere i fladere formater som Microdata.
| Aspekt | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Implementeringsplacering | Separat <script>-tag i <head> eller <body> | Indlejret i HTML-attributter | Indlejret i HTML-attributter |
| Implementeringseffektivitet | Meget let; minimale HTML-ændringer kræves | Moderat; kræver tilføjelse af HTML-attributter | Moderat til kompleks; kræver namespace-erklæringer |
| Vedligeholdelseskompleksitet | Lav; data adskilt fra præsentation | Mellem; markup blandet med indhold | Mellem til høj; flere vokabularer mulige |
| Support for dynamisk indhold | Fremragende; fungerer med JavaScript-injektion | Begrænset; kræver server-side rendering | Begrænset; kræver server-side rendering |
| Google-anbefaling | Anbefalet | Understøttet | Understøttet |
| Adoptionsrate (2024) | 41% af alle websites; 70% af sites med strukturerede data | ~20% af sites med strukturerede data | ~15% af sites med strukturerede data |
| Vokabularfleksibilitet | Ét vokabular pr. dokument (typisk schema.org) | Ét vokabular pr. dokument | Flere vokabularer understøttet |
| Indlejringskompleksitet | Fremragende; naturligt JSON-hierarki | God; kræver flere itemscope-deklarationer | God; understøtter komplekse relationer |
| AI-søgemaskinekompatibilitet | Fremragende; foretrækkes af ChatGPT, Perplexity, Claude | God; understøttet men mindre foretrukket | God; understøttet men mindre foretrukket |
Når en søgemaskine-crawler eller et AI-system støder på en webside med JSON-LD-markup, parser det <script type="application/ld+json">-tagget og udtrækker de strukturerede data. Crawleren bruger @context til at forstå det anvendte vokabular og fortolker derefter hver egenskab i henhold til schema.org-definitioner. Denne proces gør det muligt for søgemaskinen at udtrække specifikke, maskinlæsbare informationer om sidens indhold uden at være afhængig af naturlig sprogbehandling eller heuristik.
For Google Search muliggør JSON-LD-markup visning af rige resultater – forbedrede søgeresultater, der inkluderer visuelle elementer som vurderinger, priser, billeder og begivenhedsdetaljer. Når Google crawler en produktside med korrekt implementeret JSON-LD-markup, kan den udtrække produktnavn, pris, tilgængelighed, anmeldelser og billeder direkte fra de strukturerede data. Disse informationer bruges derefter til at generere et rigt resultat, der vises i søgeresultaterne, typisk med en højere klikrate end standard blå links. Undersøgelser fra store websites viser effekten: Rotten Tomatoes oplevede en 25% højere klikrate på sider med strukturerede data, mens Nestlé målte en 82% højere klikrate på sider, der blev vist som rige resultater.
For AI-søgemaskiner som Perplexity, ChatGPT og Google AI Overviews har JSON-LD en anden, men lige så vigtig funktion. Disse systemer bruger strukturerede data til at forstå det semantiske indhold, identificere nøgleenheder og relationer samt udtrække præcis information til brug i AI-genererede svar. Når et AI-system støder på JSON-LD-markup, kan det sikkert identificere, hvilken type entity, der beskrives, hvilke egenskaber denne entity har, og hvordan den relaterer sig til andre entities. Denne strukturerede forståelse hjælper AI-systemer med at levere mere præcise, kontekstuelle svar og korrekt tilskrive information til kildesider.
Effektiv implementering af JSON-LD kræver forståelse for flere nøgleprincipper og best practices. For det første bør JSON-LD placeres i <head>-sektionen af HTML-dokumentet, men det kan også placeres i <body>. Placeringen i <head> foretrækkes generelt, fordi det sikrer, at de strukturerede data parses før sideindholdet, selvom moderne søgemaskiner og AI-systemer kan parse JSON-LD fra hele siden.
For det andet bør @context altid angives eksplicit, typisk som "@context": "https://schema.org". Dette sikrer, at alle egenskabsnavne og typer fortolkes i henhold til schema.org-definitioner. Selvom det teknisk er muligt at bruge flere kontekster eller brugerdefinerede vokabularer, anvender langt de fleste webimplementeringer udelukkende schema.org.
For det tredje bør JSON-LD-markup nøjagtigt afspejle det synlige indhold på siden. Søgemaskiner og AI-systemer forventer, at de strukturerede data matcher det, brugeren ser på siden. Tilføjelse af JSON-LD-markup om information, der ikke er synlig for brugeren – eller som modsiger det synlige indhold – kan føre til sanktioner eller at markuppen negligeres. Dette princip er afgørende for at opretholde tillid hos søgemaskiner og sikre, at AI-systemer citerer dit indhold korrekt.
For det fjerde bør alle krævede egenskaber for en bestemt skematype inkluderes. Selvom schema.org definerer mange valgfrie egenskaber, sikrer inklusion af de obligatoriske egenskaber, at søgemaskiner kan validere og vise markuppen korrekt. For eksempel kræver et Product-skema mindst egenskaberne name, description og offers for at være berettiget til rich result-visning.
For det femte bør JSON-LD valideres med værktøjer som Googles Rich Results Test eller Schema.orgs Validator før udrulning. Disse værktøjer tjekker for syntaksfejl, manglende obligatoriske egenskaber og andre problemer, der kan forhindre, at markuppen bliver genkendt. Test i udviklingsfasen forhindrer problemer i produktion og sikrer, at markuppen fungerer som tiltænkt.
Implementering af JSON-LD-strukturerede data giver målbare fordele på flere områder. Fra et SEO-perspektiv muliggør JSON-LD rige resultater, der markant forbedrer klikraten. Food Network konverterede 80% af deres sider til at bruge strukturerede data og målte en 35% stigning i besøg. Rakuten fandt, at brugerne tilbragte 1,5x mere tid på sider med strukturerede data end på sider uden, og oplevede en 3,6x højere interaktionsrate på AMP-sider med søgefunktioner.
Fra et AI-søgesynlighedsperspektiv bliver JSON-LD stadig vigtigere, efterhånden som AI-drevne søgemaskiner bliver almindelige. Websites, der implementerer JSON-LD-markup, har større sandsynlighed for, at deres indhold forstås, citeres og fremhæves korrekt i AI-genererede svar. Dette er især vigtigt for AmICited-brugere, der ønsker at overvåge, hvordan deres brand, domæne og URL’er optræder i AI-søgeresultater på platforme som ChatGPT, Perplexity, Google AI Overviews og Claude. Korrekt implementering af JSON-LD sikrer, at AI-systemerne har den strukturerede kontekst, der skal til for præcist at tilskrive og citere dit indhold.
Fra et teknisk perspektiv reducerer JSON-LD implementeringskompleksitet og vedligeholdelsesbyrde. Fordi markuppen er adskilt fra HTML-indholdet, kan udviklere håndtere strukturerede data uafhængigt af ændringer i sideopsætning. Denne adskillelse er særligt værdifuld for store organisationer med komplekse content management-systemer, hvor flere teams kan have ansvar for både indhold og teknisk implementering.
Fra et brugeroplevelsesperspektiv forbedrer JSON-LD indirekte brugerengagementet ved at muliggøre rigere og mere informative søgeresultater. Brugere er mere tilbøjelige til at klikke på søgeresultater, der inkluderer vurderinger, priser, billeder og andre strukturerede informationer, hvilket fører til højere trafik og bedre konverteringsrater for websites, der implementerer JSON-LD effektivt.
JSON-LD integreres problemfrit med moderne webudviklingspraksis og teknologier. I modsætning til Microdata og RDFa, der kræver server-side rendering for at blive korrekt tolket af søgemaskiner, kan JSON-LD dynamisk indsættes på sider med JavaScript. Denne egenskab er afgørende for single-page applications (SPA’er), progressive web apps (PWA’er) og andre JavaScript-tunge websites, hvor indhold genereres dynamisk.
Content management-systemer (CMS) som WordPress, Shopify, Wix og Drupal tilbyder i stigende grad indbygget understøttelse af JSON-LD-generering, enten direkte eller gennem plugins. Denne demokratisering af JSON-LD-implementering betyder, at selv ikke-tekniske brugere kan tilføje strukturerede data til deres sider uden at skrive kode. Mange CMS-platforme genererer automatisk JSON-LD-markup på baggrund af sidens metadata og indhold, hvilket mindsker byrden for udviklere og indholdsproducenter.
JSON-LD fungerer også godt med headless CMS-arkitekturer, hvor indhold styres adskilt fra præsentation. I disse systemer kan JSON-LD genereres server-side og leveres som en del af sideresponsen, eller det kan genereres client-side med JavaScript-frameworks som React, Vue eller Angular. Denne fleksibilitet gør JSON-LD velegnet til stort set enhver moderne webarkitektur.
https://schema.org for at sikre ensartet vokabularfortolkningDen fremtidige betydning af JSON-LD forventes at stige snarere end at falde. Efterhånden som AI-drevne søgemaskiner og store sprogmodeller bliver mere sofistikerede, vokser behovet for høj-kvalitets, maskinlæsbare strukturerede data. Søgemaskiner og AI-systemer bruger i stigende grad strukturerede data ikke kun til visning, men som en central del af deres forståelses- og rangeringsalgoritmer.
Nye udviklinger i JSON-LD inkluderer JSON-LD-star, som udvider formatet til at understøtte mere komplekse knowledge graph-relationer, og CBOR-LD, som giver en mere kompakt binær repræsentation af JSON-LD-data. Disse udvidelser antyder, at JSON-LD-økosystemet fortsat vil udvikle sig for at imødekomme behovene i stadig mere avancerede webapplikationer og AI-systemer.
Fremkomsten af AI-søgemaskiner repræsenterer et paradigmeskifte i brugen af strukturerede data. Traditionelle søgemaskiner bruger primært strukturerede data til visning – for at generere rige resultater. AI-søgemaskiner bruger derimod strukturerede data som et fundamentalt input til deres forståelses- og ræsonnementprocesser. Denne ændring betyder, at websites, der implementerer JSON-LD effektivt, får en betydelig fordel i forhold til synlighed og citeringsfrekvens i AI-søgning.
Derudover, efterhånden som privatlivs- og datastyringsspørgsmål bliver mere væsentlige, kan JSON-LD spille en stadig vigtigere rolle i at udtrykke dataproveniens, licensforhold og brugsrettigheder. Formatets fleksibilitet og udvidelsesmuligheder gør det velegnet til at udtrykke komplekse metadata om datakilder og -restriktioner, hvilket bliver stadig vigtigere, efterhånden som organisationer ønsker kontrol over, hvordan deres data bruges af AI-systemer.
For organisationer, der bruger platforme som AmICited til at overvåge deres fremtræden i AI-søgeresultater, er implementering af omfattende JSON-LD-markup en strategisk investering. Ved at give AI-systemerne klar, struktureret kontekst om dit indhold øger du sandsynligheden for, at dit brand, domæne og dine URL’er bliver forstået, citeret og fremhævet korrekt i AI-genererede svar. Efterhånden som AI-søgning vinder frem, bliver JSON-LD en uundværlig del af enhver omfattende SEO- og synlighedsstrategi.
JSON-LD og Microdata er begge strukturerede dataformater, men de adskiller sig i implementering. JSON-LD indlejres i et separat <script>-tag og er ikke blandet med HTML-indholdet, hvilket gør det lettere at vedligeholde og implementere i stor skala. Microdata bruger HTML-attributter direkte i sideindholdet. Google anbefaler JSON-LD til de fleste implementeringer, fordi det er mindre tilbøjeligt til brugerfejl og fungerer problemfrit med dynamisk indhold fra JavaScript-frameworks og content management-systemer.
JSON-LD gør det muligt for søgemaskiner bedre at forstå sideindhold, hvilket kan resultere i rige resultater — forbedrede søgeresultater med vurderinger, priser, billeder og andre strukturerede informationer. Undersøgelser viser, at sider med struktureret data markup oplever markant højere klikrater. For eksempel målte Nestlé en 82% højere klikrate på sider, der blev vist som rige resultater sammenlignet med sider uden, hvilket viser JSON-LD's direkte indvirkning på søgeresultater og brugerengagement.
@context i JSON-LD angiver vokabular-namespace (typisk schema.org), der definerer betydningen af de egenskaber og typer, der bruges i markuppen. Det fungerer som et XML-namespace og fortæller søgemaskiner og AI-systemer, hvordan dataene skal fortolkes. For eksempel angiver @context: 'https://schema.org', at @type-værdier som 'Product' eller 'Article' henviser til schema.org-definitioner, hvilket sikrer ensartet fortolkning på tværs af forskellige platforme og systemer.
Ja, JSON-LD-strukturerede data bliver stadig vigtigere for AI-søgemaskiner. Platforme som ChatGPT, Perplexity og Google AI Overviews bruger strukturerede data til bedre at forstå og udtrække information fra websider. JSON-LD giver maskinlæsbar kontekst, der hjælper disse AI-systemer med at identificere nøgleenheder, relationer og indholdstyper, hvilket øger sandsynligheden for, at dit indhold bliver citeret og fremhævet i AI-genererede svar.
Vigtige JSON-LD-egenskaber inkluderer @context (definerer vokabularet), @type (specificerer skematype som Product eller Article), @id (unik identifikator for entiteten) og tilpassede egenskaber baseret på skematypen. For et Product-skema kan man inkludere name, description, price, image og aggregateRating. Hver egenskab kortlægges til schema.org-definitioner, hvilket gør det muligt for søgemaskiner at udtrække og forstå specifik information om dit indhold.
Brugen af JSON-LD er vokset markant og nåede 41% af alle websites i 2024, op fra 34% i 2022. Blandt websites, der bruger struktureret data markup, er JSON-LD det mest udbredte format, brugt af cirka 70% af sider med strukturerede data. Denne vækst afspejler Googles anbefaling af JSON-LD som det foretrukne format og dets nemme implementering sammenlignet med alternativer som Microdata og RDFa.
JSON-LD har flere fordele i forhold til RDFa: det er lettere at implementere og vedligeholde, kræver ikke sammenblanding med HTML-indhold, fungerer problemfrit med JavaScript-genereret indhold og er mindre udsat for fejl. Mens RDFa giver mulighed for at kombinere flere vokabularer til komplekse behov, gør JSON-LD's enkelhed og Googles klare anbefaling det til det foretrukne valg for de fleste websites, der ønsker at implementere strukturerede data for synlighed i søgning og AI.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvad JSON-LD er, og hvordan du implementerer det til SEO. Opdag fordele ved struktureret data markup for Google, ChatGPT, Perplexity og synlighed i AI-søgni...
Fællesskabsdiskussion om implementering af JSON-LD for synlighed i AI-søgning. Udviklere og SEO-eksperter deler, hvordan strukturerede data påvirker AI-citater ...
Lær hvordan du implementerer Organization schema markup for AI-synlighed. Trin-for-trin guide til at tilføje JSON-LD-strukturerede data, forbedre AI-citater og ...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.