
Hvad er en Knowledge Graph, og Hvorfor Er Den Vigtig? | AI Overvågnings FAQ
Opdag hvad knowledge graphs er, hvordan de fungerer, og hvorfor de er essentielle for moderne datastyring, AI-applikationer og forretningsintelligens.
8 min læsning
En knowledge graph er en database med sammenkædede informationer, der repræsenterer virkelige enheder—såsom personer, steder, organisationer og begreber—og illustrerer de semantiske relationer mellem dem. Søgemaskiner som Google bruger knowledge graphs til at forstå brugerens hensigt, levere mere relevante resultater og drive AI-baserede funktioner som knowledge panels og AI Overviews.
En knowledge graph er en database med sammenkædede informationer, der repræsenterer virkelige enheder—såsom personer, steder, organisationer og begreber—og illustrerer de semantiske relationer mellem dem. Søgemaskiner som Google bruger knowledge graphs til at forstå brugerens hensigt, levere mere relevante resultater og drive AI-baserede funktioner som knowledge panels og AI Overviews.
En knowledge graph er en database med sammenkædede informationer, der repræsenterer virkelige enheder—såsom personer, steder, organisationer og begreber—og illustrerer de semantiske relationer mellem dem. I modsætning til traditionelle databaser, der organiserer information i stive, tabelformater, strukturerer knowledge graphs data som netværk af noder (enheder) og kanter (relationer), hvilket gør det muligt for systemer at forstå betydning og kontekst frem for blot at matche nøgleord. Googles Knowledge Graph, lanceret i 2012, revolutionerede søgning ved at indføre entitetsbaseret forståelse, så søgemaskinen kunne besvare faktuelle spørgsmål som “Hvor høj er Eiffeltårnet?” eller “Hvor blev sommer-OL 2016 afholdt?” ved at forstå, hvad brugeren faktisk leder efter, ikke kun de ord de bruger. Per maj 2024 indeholder Googles Knowledge Graph over 1,6 billioner fakta om 54 milliarder enheder, hvilket repræsenterer en enorm udvidelse fra 500 milliarder fakta om 5 milliarder enheder i 2020. Denne vækst afspejler den stigende betydning af struktureret, semantisk viden i at drive moderne søgning, AI-systemer og intelligente applikationer på tværs af brancher.
Konceptet knowledge graphs udspringer af årtiers forskning i kunstig intelligens, semantiske webteknologier og vidensrepræsentation. Begrebet fik dog bred anerkendelse, da Google introducerede sin Knowledge Graph i 2012, hvilket grundlæggende ændrede, hvordan søgemaskiner leverer resultater. Før Knowledge Graph brugte søgemaskiner primært nøgleordsmatchning—hvis du søgte efter “seal”, ville Google vise resultater for alle mulige betydninger af ordet uden at forstå, hvilken enhed du faktisk ville lære om. Knowledge Graph ændrede dette paradigme ved at anvende principperne for ontologi—et formelt rammeværk til at definere enheder, deres attributter og relationer—i stor skala. Dette skift fra “strings to things” repræsenterede et grundlæggende fremskridt i søgeteknologi, der gjorde det muligt for algoritmer at forstå, at “seal” kan referere til et havpattedyr, en musiker, en militærenhed eller et sikkerhedsapparat, og at afgøre, hvilken betydning der er mest relevant baseret på kontekst. Det globale marked for knowledge graphs afspejler denne betydning, med prognoser, der viser en vækst fra 1,49 milliarder dollars i 2024 til 6,94 milliarder dollars i 2030, svarende til en årlig vækstrate på ca. 35%. Denne eksplosive vækst drives af virksomheders adoption på tværs af finans, sundhed, detailhandel og forsyningskæde, hvor organisationer i stigende grad erkender, at forståelse af entitetsrelationer er afgørende for beslutningstagning, bedrageridetektion og operationel effektivitet.
Knowledge graphs fungerer gennem en sofistikeret kombination af datastrukturer, semantiske teknologier og maskinlæringsalgoritmer. I sin kerne bruger knowledge graphs en grafstruktureret datamodel bestående af tre fundamentale komponenter: noder (der repræsenterer enheder som personer, organisationer eller begreber), kanter (der repræsenterer relationer mellem enheder) og labels (der beskriver relationernes karakter). For eksempel kan “Seal” i en simpel knowledge graph være en node, “er-en” kan være en kant-label, og “Musiker” kan være en anden node, hvilket skaber den semantiske relation “Seal er-en Musiker”. Denne struktur adskiller sig fundamentalt fra relationelle databaser, der tvinger data ind i rækker og kolonner med foruddefinerede skemaer. Knowledge graphs bygges enten som labeled property graphs (hvor egenskaber lagres direkte på noder og kanter) eller RDF (Resource Description Framework) triple stores (der repræsenterer al information som subjekt-predikat-objekt-triple). Knowledge graphs’ styrke ligger i deres evne til at integrere data fra flere kilder med forskellige strukturer og formater. Når data indlæses i en knowledge graph, bruger semantisk berigelse processer naturlig sprogbehandling (NLP) og maskinlæring til at identificere enheder, udtrække relationer og forstå kontekst. Dette gør det muligt for knowledge graphs automatisk at genkende, at “IBM”, “International Business Machines” og “Big Blue” alle refererer til den samme enhed, og at forstå, hvordan den enhed relaterer til andre som “Watson”, “Cloud Computing” og “Kunstig Intelligens”. Den resulterende sammenkædede struktur muliggør sofistikerede forespørgsler og ræsonnementer, som ville være umulige i traditionelle databaser, så systemer kan besvare komplekse spørgsmål ved at traversere relationer og udlede ny viden fra eksisterende forbindelser.
| Aspekt | Knowledge Graph | Traditionel relationel database | Grafdatabase |
|---|---|---|---|
| Datastruktur | Noder, kanter og labels, der repræsenterer enheder og relationer | Tabeller, rækker og kolonner med foruddefinerede skemaer | Noder og kanter optimeret til relationstraversering |
| Skemafleksibilitet | Meget fleksibel; udvikler sig efterhånden som ny information opdages | Stiv; kræver skemadefinition før dataindtastning | Fleksibel; understøtter dynamisk schemaudvikling |
| Relationshåndtering | Indbygget understøttelse af komplekse, multi-hop-relationer | Kræver joins på tværs af flere tabeller; beregningsmæssigt tungt | Optimeret til effektive relationsforespørgsler |
| Forespørgselssprog | SPARQL (for RDF), Cypher (for property graphs), eller brugerdefinerede API’er | SQL | Cypher, Gremlin eller SPARQL |
| Semantisk forståelse | Fremhæver betydning og kontekst gennem ontologier | Fokuserer på datalagring og -hentning | Fokuserer på effektiv traversering og mønstermatchning |
| Anvendelsesområder | Semantisk søgning, vidensopdagelse, AI-systemer, entitetsopløsning | Forretningstransaktioner, rapportering, OLTP-systemer | Anbefalingsmotorer, bedrageridetektion, netværksanalyse |
| Dataintegration | Fremragende til integration af heterogene data fra flere kilder | Kræver omfattende ETL og datatransformation | God til forbundet data, men mindre semantisk fokus |
| Skalerbarhed | Skalerer til milliarder af enheder og billioner af fakta | Skalerer godt for struktureret, transaktionel data | Skalerer godt for relations-tunge forespørgsler |
| Inferensmuligheder | Avanceret ræsonnement og videnudledning via ontologier | Begrænset; kræver eksplicit programmering | Begrænset; fokuserer på mønstermatchning |
Knowledge graphs er blevet centrale i moderne SEO- og AI-synlighedsstrategier, fordi de grundlæggende bestemmer, hvordan information præsenteres i søgeresultater og AI-genererede svar. Når Google behandler en søgeforespørgsel, er en af dens primære opgaver at identificere den entitet, brugeren søger efter, og derefter hente relevant information fra Knowledge Graph for at udfylde SERP-funktioner. Denne entitetsbaserede tilgang har ført til fremkomsten af semantisk søgning—Googles evne til at forstå betydningen og konteksten af forespørgsler frem for blot at matche nøgleord. Knowledge Graph driver flere SERP-funktioner med høj synlighed, der direkte påvirker klikrater og brandsynlighed. Knowledge panels vises fremtrædende på desktop- og mobilsøgninger og viser kuraterede fakta om den søgte entitet hentet fra Knowledge Graph. AI Overviews (tidligere Search Generative Experience) sammensætter information fra flere kilder identificeret via Knowledge Graph-relationer og leverer omfattende svar, der ofte skubber traditionelle organiske resultater længere ned på siden. People Also Ask-bokse udnytter entitetsrelationer til at foreslå relaterede søgninger og emner. For brands er det afgørende at forstå disse funktioner, fordi de repræsenterer den mest værdifulde plads i søgeresultater, ofte over de organiske lister. For organisationer, der overvåger deres tilstedeværelse i AI-systemer som Perplexity, ChatGPT, Claude og Google AI Overviews, bliver knowledge graph-optimering essentiel. Disse AI-systemer er i stigende grad afhængige af struktureret entitetsinformation og semantiske relationer for at generere præcise, kontekstuelle svar. Et brand, der har optimeret sin entitetstilstedeværelse i knowledge graphs—gennem struktureret datamarkup, krævede knowledge panels og konsistent information på tværs af kilder—har større sandsynlighed for at optræde i AI-genererede svar om relevante emner. Omvendt kan brands med ufuldstændig eller inkonsistent entitetsinformation blive overset eller fejlagtigt repræsenteret i AI-systemer, hvilket direkte påvirker deres synlighed og omdømme.
Googles Knowledge Graph henter data fra et bredt økosystem af kilder, der hver især bidrager med forskellige typer information og tjener forskellige formål. Åbne data og fællesskabsprojekter som Wikipedia og Wikidata udgør fundamentet for meget indhold i Knowledge Graph. Wikipedia leverer narrative beskrivelser og resumeinformation, der ofte vises i knowledge panels, mens Wikidata—en struktureret vidensbase, der understøtter Wikipedia—giver maskinlæsbare entitetsdata og relationer. Google brugte tidligere Freebase, sin egen fællesskabsredigerede database, men skiftede til Wikidata efter at have lukket Freebase i 2016. Officielle datakilder bidrager med autoritativ information, især til faktuelle forespørgsler. CIA World Factbook leverer information om lande, geografiske områder og organisationer. Data Commons, Googles strukturerede offentlige dataprojekt, samler data fra regerings- og multinationale organisationer som FN og EU og leverer statistik og demografiske oplysninger. Vejr- og luftkvalitetsdata kommer fra nationale og internationale meteorologiske agenturer, hvilket muliggør Googles “nowcast”-vejrfunktioner. Licenserede private data supplerer Knowledge Graph med information, der ændrer sig hyppigt eller kræver specialiseret ekspertise. Google licenserer finansielle markedsdata fra udbydere som Morningstar, S&P Global og Intercontinental Exchange for at understøtte aktiepris- og markedsinformationsfunktioner. Sportsdata kommer fra partnerskaber med ligaer, hold og aggregatorer som Stats Perform og leverer realtidsresultater og historiske statistikker. Strukturerede data fra websites bidrager væsentligt til berigelse af Knowledge Graph. Når websites implementerer Schema.org-markup, stiller de eksplicit semantisk information til rådighed, som Google kan udtrække og inkorporere. Derfor er korrekt implementering af strukturerede data—Organization-schema, LocalBusiness-schema, FAQPage-schema og anden relevant markup—afgørende for brands, der vil påvirke deres Knowledge Graph-repræsentation. Google Books-data fra over 40 millioner scannede og digitaliserede bøger giver historisk kontekst, biografisk information og detaljerede beskrivelser, der forbedrer entitetsviden. Brugerfeedback og krævede knowledge panels giver enkeltpersoner og organisationer mulighed for direkte at påvirke Knowledge Graph-information. Når brugere sender feedback om knowledge panels, eller når autoriserede repræsentanter kræver og opdaterer panels, behandles denne information og kan føre til opdateringer i Knowledge Graph. Denne menneske-i-løkken-tilgang sikrer, at Knowledge Graph forbliver nøjagtig og repræsentativ, selvom Googles automatiserede systemer træffer den endelige beslutning om, hvilke informationer der vises.
Google har udtrykkeligt sagt, at de prioriterer information fra kilder, der udviser høj E-E-A-T (Experience, Expertise, Authoritativeness og Trustworthiness), når de bygger og opdaterer Knowledge Graph. Denne sammenhæng mellem E-E-A-T og Knowledge Graph-inklusion er ikke tilfældig—den afspejler Googles bredere engagement i at fremhæve pålidelig, autoritativ information. Hvis dit websites indhold trækkes ind i SERP-funktioner, der drives af Knowledge Graph, er det ofte et stærkt signal om, at Google anerkender dit site som autoritativt på det pågældende emne. Omvendt, hvis dit indhold ikke vises i Knowledge Graph-baserede funktioner, kan det pege på E-E-A-T-udfordringer, der skal adresseres. At opbygge E-E-A-T for Knowledge Graph-synlighed kræver en mangesidet tilgang. Experience betyder at vise, at du eller dine bidragydere har reel erfaring med emnet. For et sundhedssite kan det betyde at have indhold fra autoriserede sundhedspersoner med mange års klinisk erfaring. For et teknologifirma betyder det at fremhæve ekspertisen hos ingeniører og forskere, der har bygget de produkter, du omtaler. Expertise indebærer at skabe dybtgående, velfunderet indhold, der dækker emnerne grundigt og korrekt. Det går ud over overfladiske forklaringer og demonstrerer reel forståelse for nuancer, særtilfælde og avancerede koncepter. Authoritativeness kræver anerkendelse inden for dit felt. Det kan komme fra priser, certificeringer, medieomtale, oplæg og at blive citeret af andre autoritative kilder. For organisationer handler det om at etablere dit brand som en anerkendt leder i branchen. Trustworthiness bygger på de tre øvrige elementer og vises gennem gennemsigtighed, nøjagtighed, korrekte kilder, tydelig forfatterskab og imødekommende kundeservice. Organisationer, der excellerer i E-E-A-T-signaler, har større sandsynlighed for at få deres information inkluderet i Knowledge Graph og vises i AI-genererede svar, hvilket skaber en positiv spiral, hvor autoritet fører til synlighed, der yderligere styrker autoriteten.
Fremkomsten af store sprogmodeller (LLM’er) og generativ AI har skabt ny betydning for knowledge graphs i AI-økosystemet. Selvom LLM’er som ChatGPT, Claude og Perplexity ikke er direkte trænet på Googles proprietære Knowledge Graph, er de i stigende grad afhængige af tilsvarende struktureret viden og semantisk forståelse. Mange AI-systemer benytter retrieval-augmented generation (RAG)-tilgange, hvor modellen forespørger knowledge graphs eller strukturerede databaser ved inferenstid for at forankre svar i faktuelle data og reducere hallucinationer. Offentligt tilgængelige knowledge graphs som Wikidata bruges til at finjustere modeller eller indsætte struktureret viden, hvilket forbedrer deres evne til at forstå entitetsrelationer og levere præcis information. For brands og organisationer betyder dette, at knowledge graph-optimering har konsekvenser ud over traditionel Google Search. Når brugere spørger AI-systemer om din branche, dine produkter eller din organisation, afhænger AI-systemets evne til at give præcis information delvist af, hvor godt din entitet er repræsenteret i strukturerede videnskilder. En organisation med en velvedligeholdt Wikidata-post, krævet Google knowledge panel og konsistent struktureret data på sit website vil med større sandsynlighed blive korrekt repræsenteret i AI-genererede svar. Omvendt kan organisationer med ufuldstændig eller modstridende information på tværs af kilder opleve at blive fejlagtigt repræsenteret eller overset i AI-svar. Dette skaber en ny dimension af AI-synlighedsovervågning—ikke kun at spore, hvordan dit brand fremstår i traditionelle søgeresultater, men hvordan det repræsenteres i AI-genererede svar på tværs af flere platforme. Værktøjer og platforme, der overvåger brands tilstedeværelse i AI-systemer, fokuserer i stigende grad på forståelse af entitetsrelationer og knowledge graph-repræsentation, idet de anerkender, at disse faktorer direkte påvirker AI-synlighed.
Organisationer, der ønsker at optimere deres tilstedeværelse i knowledge graphs, bør følge en systematisk tilgang, der bygger på SEO-grundprincipper og tilføjer entitetsspecifikke strategier. Første skridt er at implementere struktureret datamarkup med Schema.org-vokabular. Det betyder at tilføje JSON-LD, Microdata eller RDFa-markup på dit website, der eksplicit beskriver din organisation, produkter, personer og andre relevante enheder. Centrale schema-typer inkluderer Organization (til virksomhedsoplysninger), LocalBusiness (til lokationsspecifik information), Person (til individuelle profiler), Product (til produktinformation) og FAQPage (til ofte stillede spørgsmål). Efter implementering af schema er det vigtigt at teste og validere din markup med Googles Structured Data Testing Tool for at sikre, at den er korrekt formateret og genkendt. Andet skridt er at revidere og optimere Wikidata- og Wikipedia-information. Hvis din organisation eller nøgleenheder har Wikipedia-sider, skal de være nøjagtige, dækkende og veldokumenterede. For Wikidata skal du verificere, at din entitet eksisterer, og at dens egenskaber og relationer er korrekt repræsenteret. Dog kræver redigering af Wikipedia eller Wikidata omhyggelig opmærksomhed på deres politikker og fællesskabsnormer—direkte selvpromovering eller skjulte interessekonflikter kan føre til, at redigeringer tilbagerulles og skade dit omdømme. Tredje skridt er at kræve og optimere din Google Business Profile (for lokale virksomheder) og knowledge panels (for personer og organisationer). Et krævet knowledge panel giver dig større kontrol over, hvordan din entitet vises i søgeresultater, og gør det muligt at foreslå rettelser hurtigere. Fjerde skridt er at sikre konsistens på tværs af alle platforme—dit website, Google Business Profile, sociale medieprofiler og tredjepartsvirksomhedsregistre. Modstridende information på tværs af kilder forvirrer Googles systemer og kan forhindre korrekt Knowledge Graph-repræsentation. Femte skridt er at skabe entitetsfokuseret indhold frem for traditionelt nøgleordsfokuseret indhold. I stedet for at skrive artikler baseret på nøgleord, bør du organisere din indholdsstrategi omkring enheder og deres relationer. For eksempel, i stedet for separate artikler om “bedste CRM-software”, “Salesforce-funktioner” og “HubSpot-priser”, bør du skabe en omfattende indholdsklynge, der etablerer klare entitetsrelationer: Salesforce er en CRM-platform, den konkurrerer med HubSpot, den integrerer med Slack osv. Denne entitetsbaserede tilgang hjælper knowledge graphs med at forstå dit indholds semantiske betydning og relationer.
Knowledge graphs udvikler sig hurtigt som reaktion på fremskridt inden for kunstig intelligens, ændringer i søgeadfærd og fremkomst af nye platforme og teknologier. En betydelig tendens er udvidelsen af multimodale knowledge graphs, der integrerer tekst, billeder, lyd og video. Efterhånden som stemmesøgning og visuel søgning bliver mere udbredt, tilpasses knowledge graphs til at forstå og repræsentere information på tværs af flere modaliteter. Googles arbejde med multimodal søgning med produkter som Google Lens demonstrerer denne udvikling—systemet skal ikke kun forstå tekstforespørgsler, men også visuelle input, hvilket kræver knowledge graphs, der kan repræsentere og forbinde information på tværs af forskellige medietyper. En anden vigtig udvikling er den stigende sofistikering af semantisk berigelse og naturlig sprogbehandling i konstruktionen af knowledge graphs. Efterhånden som NLP-kapaciteter forbedres, kan knowledge graphs udtrække mere nuancerede semantiske relationer fra ustruktureret tekst og dermed mindske behovet for manuelt kuraterede eller eksplicit markerede data. Det betyder, at organisationer med indhold af høj kvalitet og god sproglig fremstilling kan få deres information indarbejdet i knowledge graphs, selv uden eksplicit struktureret datamarkup, selvom markup fortsat er vigtig for at sikre korrekt repræsentation. Integrationen af knowledge graphs med store sprogmodeller og generativ AI udgør muligvis den mest markante udvikling. I takt med at AI-systemer bliver mere centrale for, hvordan folk opdager information, udvides vigtigheden af knowledge graph-optimering ud over den traditionelle søgning til også at omfatte AI-synlighed på tværs af flere platforme. Organisationer, der forstår og optimerer til knowledge graphs, vil have fordele både i traditionel søgning og i AI-genererede svar. Derudover afspejler fremkomsten af enterprise knowledge graphs en voksende erkendelse af, at knowledge graph-principper også gælder for intern organisatorisk videnshåndtering. Virksomheder bygger interne knowledge graphs for at bryde datasiloer ned, forbedre beslutningstagning og muliggøre bedre AI-applikationer. Denne tendens peger på, at viden om knowledge graphs vil blive stadig vigtigere for erhvervsledere, data scientists og marketingfolk. Endelig får de regulerende og etiske dimensioner af knowledge graphs større opmærksomhed. Efterhånden som knowledge graphs påvirker, hvordan information præsenteres for milliarder af brugere, bliver spørgsmål om nøjagtighed, bias, repræsentation og kontrol over knowledge graph-information mere centrale. Organisationer bør være opmærksomme på, at deres entitetsrepræsentation i knowledge graphs har reelle konsekvenser for synlighed, omdømme og forretningsresultater og bør gribe knowledge graph-optimering an med samme omhu og etik, som de anvender på andre aspekter af deres digitale tilstedeværelse.
En traditionel database lagrer data i stive tabelformater med foruddefinerede skemaer, mens en knowledge graph organiserer information som sammenkædede noder og kanter, der repræsenterer enheder og deres semantiske relationer. Knowledge graphs er mere fleksible, selvbeskrivende og bedre egnede til at forstå komplekse relationer mellem forskellige datatyper. De gør det muligt for systemer at forstå betydning og kontekst, ikke kun matche nøgleord, hvilket gør dem ideelle til AI og semantiske søgeapplikationer.
Google bruger sin Knowledge Graph til at drive flere SERP-funktioner, herunder knowledge panels, AI Overviews, People Also Ask-bokse og relaterede entitetsforslag. Per maj 2024 indeholder Googles Knowledge Graph over 1,6 billioner fakta om 54 milliarder enheder. Når en bruger søger, identificerer Google den entitet, de leder efter, og viser relevant, sammenkædet information fra Knowledge Graph, så brugerne kan finde 'ting, ikke strenge', som Google beskriver det.
Knowledge graphs samler data fra flere kilder, herunder open source-projekter som Wikipedia og Wikidata, regeringsdatabaser som CIA World Factbook, licenserede private data til finans- og sportsinformation, struktureret datamarkup fra websites via Schema.org, Google Books-data samt brugerfeedback gennem rettelser af knowledge panels. Denne multisource-tilgang sikrer omfattende og nøjagtig entitetsinformation på tværs af milliarder af fakta.
Knowledge graphs påvirker direkte, hvordan brands vises i søgeresultater og AI-systemer ved at etablere entitetsrelationer og forbindelser. Brands, der optimerer deres entitetsnærvær gennem strukturerede data, krævede knowledge panels og konsistent information på tværs af kilder, opnår bedre synlighed i AI-genererede svar. Forståelse af knowledge graph-relationer hjælper brands med at overvåge deres tilstedeværelse i AI-systemer som ChatGPT, Perplexity og Claude, der i stigende grad er afhængige af struktureret entitetsinformation.
Semantisk berigelse er processen, hvor maskinlæring og naturlig sprogbehandling (NLP) analyserer data for at identificere individuelle objekter og forstå relationerne mellem dem. Denne proces gør det muligt for knowledge graphs at gå ud over simpel nøgleordsmatchning for at forstå betydning og kontekst. Når data indlæses, genkender semantisk berigelse automatisk enheder, deres attributter og hvordan de relaterer til andre enheder, hvilket muliggør mere intelligent søgning og spørgsmål-svar-funktionalitet.
Organisationer kan optimere til knowledge graphs ved at implementere struktureret datamarkup med Schema.org, opretholde konsistent information på alle platforme (website, Google Business Profile, sociale medier), kræve og opdatere knowledge panels, opbygge stærk E-E-A-T gennem autoritativt indhold og sikre datanøjagtighed på tværs af kilder. At skabe entitetsfokuserede indholdsklynger fremfor traditionelle nøgleordsklynger hjælper også med at etablere stærkere entitetsrelationer, som knowledge graphs kan genkende og udnytte.
Knowledge graphs giver det semantiske fundament for AI Overviews ved at hjælpe AI-systemer med at forstå entitetsrelationer og kontekst. Når AI-systemer genererer søgeoversigter, bruger de knowledge graph-data til at identificere relevante enheder, forstå deres forbindelser og syntetisere information fra flere kilder. Dette muliggør mere præcise, kontekstuelle svar, der går ud over simpel nøgleordsmatchning, hvilket gør knowledge graphs til en essentiel infrastruktur for moderne generativ søgning.
En knowledge graph er et designmønster og et semantisk lag, der definerer, hvordan enheder og relationer modelleres og forstås, mens en grafdatabase er den teknologiske infrastruktur, der bruges til at lagre og forespørge dataene. Knowledge graphs fokuserer på betydning og semantiske relationer, mens grafdatabaser fokuserer på effektiv lagring og hentning. En knowledge graph kan implementeres med forskellige grafdatabaser som Neo4j, Amazon Neptune eller RDF triple stores, men selve knowledge graphen er den konceptuelle model.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Opdag hvad knowledge graphs er, hvordan de fungerer, og hvorfor de er essentielle for moderne datastyring, AI-applikationer og forretningsintelligens.
Fællesskabsdiskussion, der forklarer Knowledge Graphs og deres betydning for synlighed i AI-søgning. Eksperter deler, hvordan entiteter og relationer påvirker A...
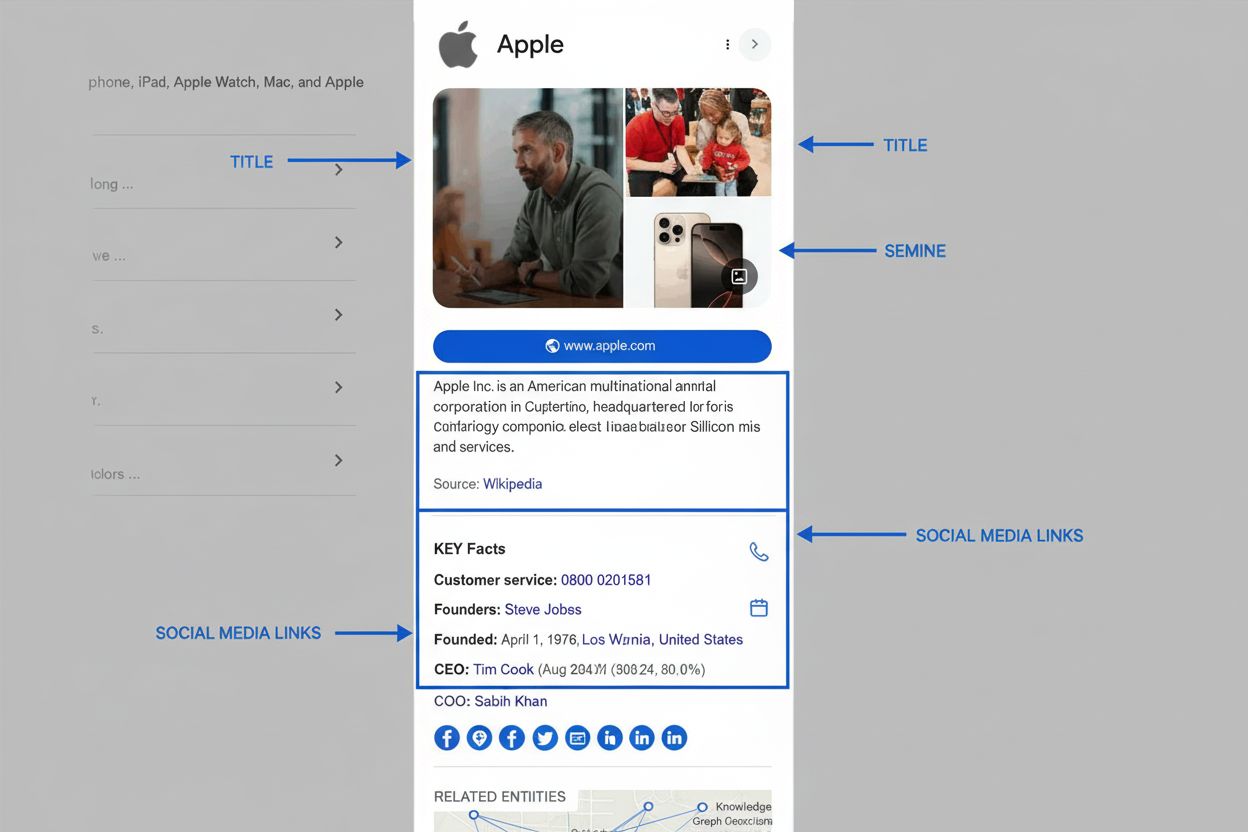
Lær hvad en Knowledge Panel er, hvordan den fungerer, hvorfor den er vigtig for SEO og AI-overvågning, og hvordan du kan gøre krav på eller optimere en for dit ...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.