
Meta AI-optimering: Facebooks og Instagrams AI-assistent
Opdag hvordan Meta AI-optimering transformerer Facebook- og Instagram-annoncering med AI-drevet automatisering, realtidsbudgivning og intelligent målretning af ...
6 min læsning
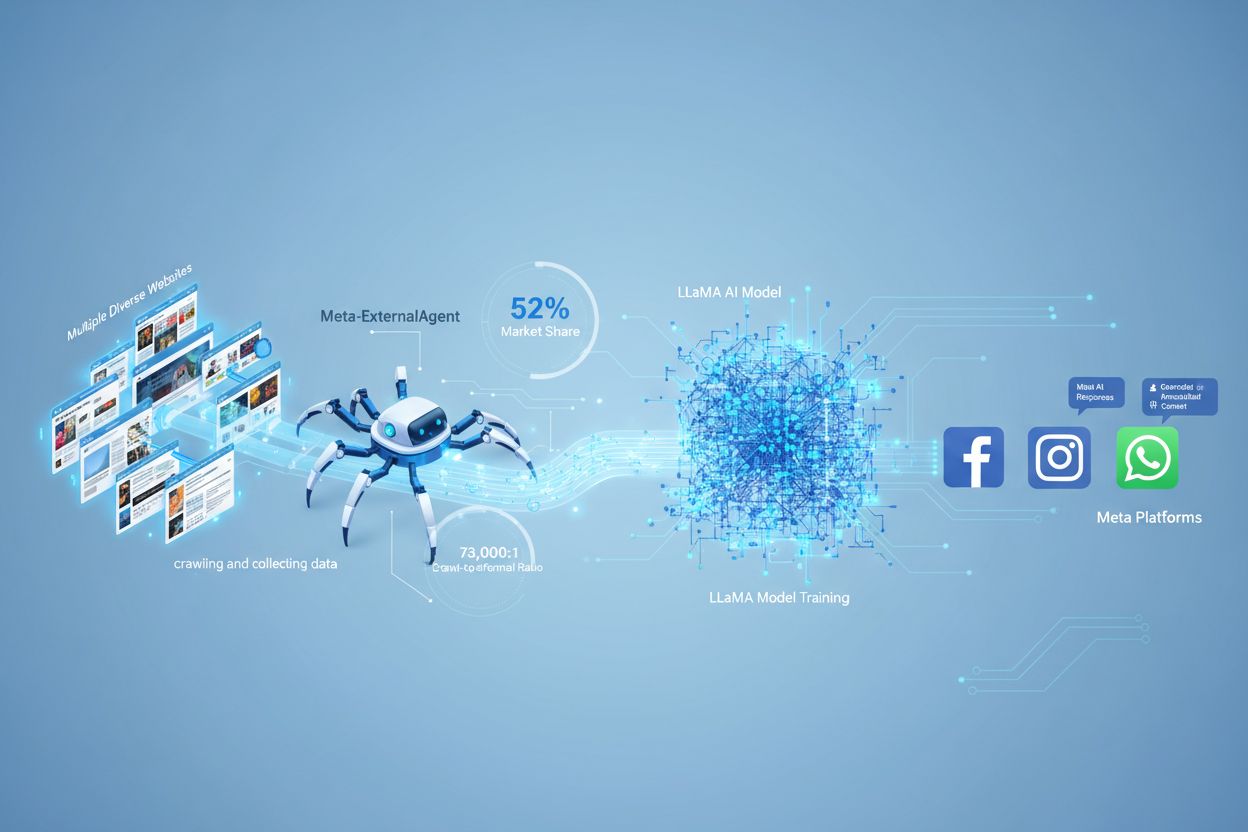
Meta-ExternalAgent er Metas webcrawler-bot, der blev lanceret i juli 2024 for at indsamle offentligt tilgængeligt indhold til træning af AI-modeller som LLaMA. Den identificerer sig selv med User-Agent-strengen meta-externalagent/1.1 og styrer, om indhold vises i Meta AI-svar på tværs af Facebook, Instagram og WhatsApp. Udgivere kan blokere den via robots.txt eller serverkonfigurationer, selvom overholdelse er frivillig og ikke juridisk bindende.
Meta-ExternalAgent er Metas webcrawler-bot, der blev lanceret i juli 2024 for at indsamle offentligt tilgængeligt indhold til træning af AI-modeller som LLaMA. Den identificerer sig selv med User-Agent-strengen meta-externalagent/1.1 og styrer, om indhold vises i Meta AI-svar på tværs af Facebook, Instagram og WhatsApp. Udgivere kan blokere den via robots.txt eller serverkonfigurationer, selvom overholdelse er frivillig og ikke juridisk bindende.
Meta-ExternalAgent er en webcrawler drevet af Meta Platforms, der blev lanceret i juli 2024 for at indsamle data til træning af kunstige intelligensmodeller. Identificeret ved User-Agent-strengen meta-externalagent/1.1 adskiller denne crawler sig fra Metas ældre facebookexternalhit-crawler, som primært blev brugt til linkforhåndsvisninger og delingsfunktioner på sociale medier. Meta-ExternalAgent markerer et betydeligt skifte i, hvordan Meta indsamler træningsdata til sine AI-initiativer, herunder LLaMA-sprogsmodellerne og Meta AI-chatbotten, som er integreret på tværs af Facebook, Instagram og WhatsApp. I modsætning til tidligere Meta-crawlere opererer denne agent med minimal gennemsigtighed og blev implementeret uden formel offentliggørelse.

Meta-ExternalAgent fungerer som en automatiseret bot, der systematisk crawler websites på internettet for at udtrække tekst og indhold til AI-modeltræningsformål. Crawleren opererer ved at sende HTTP-forespørgsler til webservere, identificere sig via den unikke User-Agent-header og downloade sideindhold til behandling. Når indholdet er indsamlet, analyseres og tokeniseres teksten af Metas systemer, så den kan bruges som træningsdata til at forbedre deres store sprogmodeller. Crawleren respekterer robots.txt-filen på frivillig basis, men det er et æressystem og ikke et juridisk krav. Ifølge Cloudflare står Meta-ExternalAgent for cirka 52% af al AI-crawlertrafik på internettet, hvilket gør den til en af de mest aggressive datainhentningsoperationer i AI-branchen. Crawleren kører kontinuerligt, og nogle udgivere rapporterer crawl-frekvenser, der antyder, at Meta prioriterer fuldstændig dækning af webindhold frem for selektiv, målrettet indsamling.
| Crawler-navn | User-Agent-streng | Primært formål | Lancering | Dataanvendelse |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AI-modeltræning (LLaMA, Meta AI) | Juli 2024 | Træningsdata til generativ AI |
| facebookexternalhit | facebookexternalhit/1.1 | Linkforhåndsvisninger og social deling | ~2010 | Open Graph-metadata, thumbnails |
| Facebot | facebot/1.0 | Indholdsvalidering til Facebook-apps | ~2015 | Indholdsvalidering til mobilapps |
| Applebot | Applebot/0.1 | Apple Siri og søgeindeks | ~2015 | Søgeindeks og stemmeassistent |
| Googlebot | Googlebot/2.1 | Google Search-indeksering | ~1998 | Søgemaskineindeks-opbygning |
Meta-ExternalAgent udgør en væsentlig bekymring for indholdsskabere og udgivere, fordi den opererer i et hidtil uset omfang og giver minimal indsigt i, hvordan indhold bliver brugt. Ifølge Cloudflare-forskning står Meta-ExternalAgent for 52% af al AI-crawlertrafik, hvilket langt overgår konkurrenter som OpenAI’s GPTBot og Googles AI-crawlere. Denne dominans betyder, at Meta indsamler mere træningsdata end nogen anden AI-virksomhed, men udgivere får ingen kompensation eller kildeangivelse, når deres indhold bruges til at træne Metas AI-modeller. 73.000:1 crawl-to-referral-forholdet viser, at Meta udtrækker enorme mængder indhold uden at sende nævneværdig trafik tilbage til kildesiderne—en grundlæggende ubalance i værdibyttet. På trods af dette blokerer kun 2% af websites aktivt Meta-ExternalAgent, sammenlignet med 25% der blokerer GPTBot, hvilket antyder, at mange udgivere ikke er opmærksomme på crawlerens tilstedeværelse eller konsekvenser. Med Meta’s investering på 40 milliarder dollars i AI-infrastruktur forventes selskabets aggressive datainhentning kun at stige, hvilket gør det væsentligt for udgivere at forstå og aktivt administrere forholdet til denne crawler.
Udgivere kan styre Meta-ExternalAgents adgang via robots.txt-filen, men det er vigtigt at forstå, at denne mekanisme er frivillig og ikke juridisk håndhævelig. For at blokere Meta-ExternalAgent skal du tilføje følgende direktiv til din robots.txt-fil:
User-agent: meta-externalagent
Disallow: /
Alternativt, hvis du vil tillade crawleren, men begrænse den til specifikke kataloger, kan du bruge:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Dog har nogle udgivere oplevet, at Meta-ExternalAgent fortsætter med at crawle deres sider selv efter implementering af robots.txt-blokeringer, hvilket antyder, at Meta ikke altid respekterer disse direktiver. For mere omfattende beskyttelse kan udgivere implementere HTTP-header-baseret blokering eller bruge Content Delivery Network (CDN)-regler til at identificere og afvise forespørgsler fra Meta-ExternalAgent baseret på User-Agent-strengen. Udgivere kan desuden overvåge deres serverlogs for User-Agent-strengen meta-externalagent/1.1 for at verificere, om crawleren tilgår deres indhold. Værktøjer som AmICited.com kan hjælpe udgivere med at spore, om deres indhold bliver citeret eller refereret i Meta AI-svar, og give indsigt i, hvordan deres arbejde anvendes af Metas AI-systemer.

Når brugere interagerer med Meta AI-chatbots på Facebook, Instagram eller WhatsApp, er de genererede svar delvist baseret på indhold indsamlet af Meta-ExternalAgent. Meta AI-svar indeholder dog typisk ikke synlige kilder eller kildeangivelser til websites, hvilket betyder, at brugerne ikke ved, hvilke udgiveres indhold der har bidraget til svaret. Denne mangel på gennemsigtighed skaber en væsentlig udfordring for indholdsskabere, der ønsker at forstå værdien af deres arbejde for Metas AI-systemer. I modsætning til nogle konkurrenter, der inkluderer kildeangivelser i AI-genererede svar, prioriterer Metas tilgang brugeroplevelse frem for kildeangivelse. Fraværet af synlige kilder betyder også, at udgivere ikke let kan følge, hvor ofte deres indhold påvirker Meta AI-svar, hvilket gør det svært at vurdere forretningsværdien af indhold, der bruges til AI-træning. Dette synlighedsgab er en af hovedårsagerne til, at overvågningsløsninger bliver stadig vigtigere for udgivere, som ønsker at forstå deres rolle i AI-økosystemet.
Udgivere kan verificere aktivitet fra Meta-ExternalAgent gennem analyse af serverlogs, som afslører crawlerens IP-adresser, forespørgselsmønstre og adgangsfrekvens til indhold. Ved at undersøge adgangslogs kan udgivere identificere forespørgsler med User-Agent-strengen meta-externalagent/1.1 og se, hvilke sider der crawles hyppigst. Avancerede overvågningsværktøjer kan spore crawl-mønstre over tid og vise, om Meta prioriterer bestemte indholdstyper eller sektioner af et website. Udgivere bør også overvåge deres båndbreddeforbrug, da aggressiv crawling fra Meta-ExternalAgent kan forbruge betydelige serverressourcer, især for sites med store indholdsbiblioteker. Derudover kan udgivere bruge værktøjer som AmICited.com til at overvåge, om deres indhold optræder i Meta AI-svar og følge citeringsmønstre på tværs af Metas platforme. Opsætning af alarmer for usædvanlig crawleraktivitet kan hjælpe udgivere med at opdage ændringer i Metas datainhentningsadfærd og reagere proaktivt. Løbende audit af serverlogs bør være en del af enhver udgivers AI-crawlerstrategi for at sikre, at de bevarer overblik over, hvordan deres indhold tilgås og bruges.
Meta-ExternalAgents juridiske status er fortsat omstridt, og der verserer løbende retssager fra indholdsskabere, kunstnere og udgivere, der udfordrer Metas ret til at bruge deres arbejde til AI-træning uden udtrykkeligt samtykke eller kompensation. Mens Meta argumenterer for, at webcrawling falder ind under fair use-doktrinen, mener kritikere, at omfanget og den kommercielle karakter af datainhentningen, kombineret med manglende kildeangivelse, udgør ophavsretskrænkelse. robots.txt-filen respekteres bredt som industristandard, men har ingen juridisk gyldighed, hvilket betyder, at Meta ikke er juridisk forpligtet til at følge blokeringer. Flere jurisdiktioner udvikler reguleringer om indsamling af AI-træningsdata, og EU’s AI Act samt lovforslag i andre regioner kan pålægge skærpede krav til virksomheder som Meta. Etisk set handler det grundlæggende spørgsmål om, hvorvidt indholdsskabere bør have ret til at kontrollere, hvordan deres arbejde bruges til kommerciel AI-træning, og om det nuværende system tilstrækkeligt kompenserer dem for værdien af deres indhold. Udgivere bør holde sig opdateret om lovgivningen og overveje at søge juridisk rådgivning om deres rettigheder og forpligtelser vedrørende AI-crawleradgang. Balancen mellem at fremme AI-innovation og beskytte skaberrettigheder er endnu ikke afklaret, hvilket gør dette til et område med løbende juridisk og regulatorisk udvikling.
Landskabet for håndtering af AI-crawlere udvikler sig hurtigt, efterhånden som udgivere, regulatorer og AI-virksomheder forhandler vilkårene for dataindsamling og brug. Metas aggressive implementering af Meta-ExternalAgent signalerer, at de store teknologivirksomheder ser webindhold som essentielt træningsmateriale til konkurrenceprægede AI-systemer, og denne tendens forventes at accelerere, efterhånden som AI bliver stadig mere central i forretningsstrategien. Fremtidige udviklinger kan omfatte stærkere juridisk beskyttelse af skabere, obligatoriske licensordninger for AI-træningsdata og tekniske standarder, der gør det lettere for udgivere at kontrollere og tjene penge på brugen af deres indhold i AI-systemer. Fremkomsten af værktøjer som AmICited.com afspejler en stigende efterspørgsel efter gennemsigtighed og ansvarlighed i AI-systemers brug af publiceret indhold, hvilket antyder, at overvågning og verifikation vil blive standard for indholdsskabere. Efterhånden som AI-branchen modnes, kan vi forvente mere sofistikerede forhandlinger mellem indholdsskabere og AI-virksomheder, hvilket potentielt fører til nye forretningsmodeller, hvor udgivere kompenseres retfærdigt for deres bidrag til AI-træning.
Meta-ExternalAgent er Metas dedikerede AI-træningscrawler lanceret i juli 2024, identificeret ved User-Agent-strengen meta-externalagent/1.1. Den adskiller sig fra facebookexternalhit, som genererer linkforhåndsvisninger til deling på sociale medier. Meta-ExternalAgent indsamler specifikt indhold til træning af LLaMA-modeller og Meta AI, mens facebookexternalhit har været brugt til sociale funktioner siden omkring 2010.
Du kan blokere Meta-ExternalAgent ved at tilføje direktiver til din robots.txt-fil. Tilføj 'User-agent: meta-externalagent' efterfulgt af 'Disallow: /' for at blokere den helt. For mere omfattende beskyttelse kan du implementere blokering på serverniveau ved hjælp af .htaccess (Apache) eller Nginx-konfigurationsregler. Bemærk dog, at robots.txt er frivillig og ikke juridisk bindende, så nogle udgivere oplever fortsat crawling trods blokering.
Nej, blokering af Meta-ExternalAgent påvirker ikke Facebook-linkforhåndsvisninger. Crawleren facebookexternalhit håndterer forhåndsvisninger og sociale delingsfunktioner. Du kan blokere meta-externalagent, mens facebookexternalhit fortsat kan generere attraktive previews, når dit indhold deles på Meta-platforme.
Meta-ExternalAgent har et crawl-to-referral-forhold på cirka 73.000:1, hvilket betyder, at Meta udtrækker indhold i enorm skala, men sender stort set ingen trafik tilbage til kildewebsites. Dette repræsenterer en grundlæggende ubalance sammenlignet med traditionelle søgemaskiner, som crawler indhold i bytte for at generere trafik.
robots.txt er et æressystem og ikke juridisk bindende. Mens mange crawlere respekterer robots.txt-direktiver, har nogle udgivere rapporteret, at Meta-ExternalAgent fortsætter med at crawle deres sider trods eksplicitte robots.txt-blokeringer. For garanteret beskyttelse implementér blokering på serverniveau ved brug af HTTP-headere, CDN-regler eller firewall-konfigurationer.
Tjek dine serveradgangslogs for forespørgsler med User-Agent-strengen 'meta-externalagent/1.1'. Du kan også bruge overvågningsværktøjer som AmICited.com til at følge, om dit indhold vises i Meta AI-svar. Værktøjer som Dark Visitors og Cloudflare Analytics giver yderligere indsigt i AI-crawleraktivitet på dit website.
Ifølge Cloudflare-data står Meta-ExternalAgent for cirka 52% af al AI-crawlertrafik på internettet og er dermed den mest aggressive AI-datainhentningsoperation. Dette overstiger langt konkurrenter som OpenAI's GPTBot og Googles AI-crawlere og indikerer Metas dominerende position i webindhentning til AI-træning.
Beslutningen afhænger af dine forretningsprioriteter. Hvis Meta AI-trafik er værdifuld for dit publikum, kan du tillade det. Overvej dog, at Meta ikke giver kompensation eller kildeangivelse for indhold brugt til AI-træning. Mange udgivere implementerer selektive blokeringer, der stopper AI-træning, men bevarer linkpreview-funktionalitet til sociale delinger.
Følg hvordan dit indhold vises i Meta AI-svar på tværs af Facebook, Instagram og WhatsApp. Få indsigt i AI-kilder og forstå dit brands tilstedeværelse i AI-genererede svar.
Opdag hvordan Meta AI-optimering transformerer Facebook- og Instagram-annoncering med AI-drevet automatisering, realtidsbudgivning og intelligent målretning af ...
Meta AI er Metas AI-assistent integreret i Facebook, Instagram, WhatsApp og Messenger. Lær hvordan den fungerer, dens muligheder og dens rolle i AI-overvågning ...

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.