
Hvad er MUM, og hvordan påvirker det AI-søgning?
Lær om Googles Multitask Unified Model (MUM) og dens indvirkning på AI-søgeresultater. Forstå hvordan MUM behandler komplekse forespørgsler på tværs af flere fo...
8 min læsning
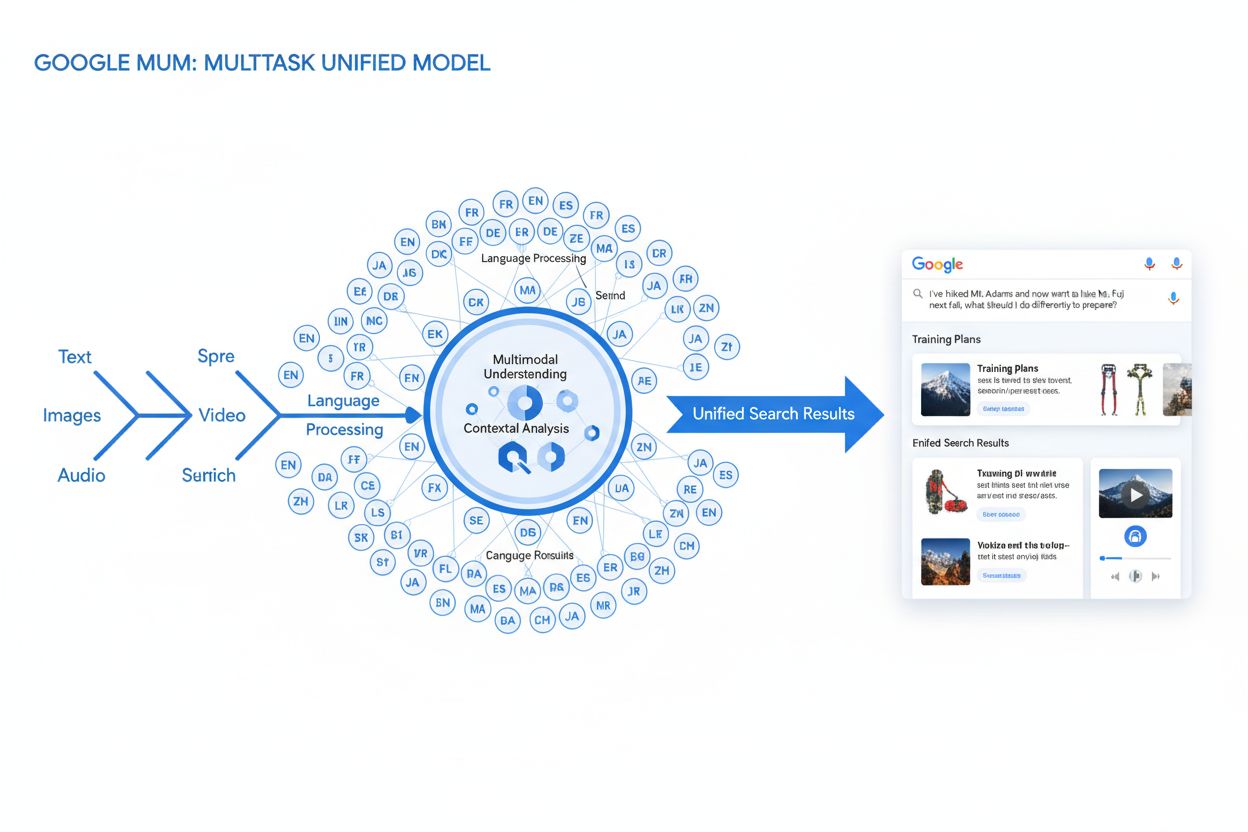
MUM (Multitask Unified Model) er Googles avancerede multimodale AI-model, der behandler tekst, billeder, video og lyd samtidigt på tværs af 75+ sprog for at levere mere omfattende og kontekstuelle søgeresultater. Lanceringen i 2021 gjorde MUM 1.000 gange mere kraftfuld end BERT og markerer et fundamentalt skift i, hvordan søgemaskiner forstår og reagerer på komplekse brugerforespørgsler.
MUM (Multitask Unified Model) er Googles avancerede multimodale AI-model, der behandler tekst, billeder, video og lyd samtidigt på tværs af 75+ sprog for at levere mere omfattende og kontekstuelle søgeresultater. Lanceringen i 2021 gjorde MUM 1.000 gange mere kraftfuld end BERT og markerer et fundamentalt skift i, hvordan søgemaskiner forstår og reagerer på komplekse brugerforespørgsler.
MUM (Multitask Unified Model) er Googles avancerede multimodale kunstige intelligensmodel, der er designet til at revolutionere, hvordan søgemaskiner forstår og reagerer på komplekse brugerforespørgsler. Annonceret i maj 2021 af Pandu Nayak, Google Fellow og Vice President of Search, repræsenterer MUM et fundamentalt skift i informationssøgningsteknologi. Bygget på T5 text-to-text-frameworket og bestående af cirka 110 milliarder parametre, er MUM 1.000 gange mere kraftfuld end BERT, Googles tidligere gennembrud inden for naturlig sprogforståelse. I modsætning til traditionelle søgealgoritmer, der behandler tekst isoleret, behandler MUM tekst, billeder, video og lyd samtidigt, mens den forstår information på tværs af 75+ sprog indbygget. Denne multimodale og flersprogede evne gør det muligt for MUM at forstå komplekse forespørgsler, der tidligere krævede, at brugere lavede flere søgninger, og forvandler søgning fra en simpel øvelse i nøgleords-matchning til et intelligent, kontekstbevidst informationssystem. MUM forstår ikke kun sprog, men genererer det også, hvilket gør den i stand til at syntetisere information fra forskellige kilder og formater for at levere omfattende, nuancerede svar, der adresserer hele brugerens hensigt.
Googles rejse mod MUM repræsenterer mange års gradvis innovation inden for naturlig sprogforståelse og maskinlæring. Udviklingen begyndte med Hummingbird (2013), der introducerede semantisk forståelse for at fortolke betydningen bag søgeforespørgsler fremfor blot at matche nøgleord. Dette blev fulgt af RankBrain (2015), der brugte maskinlæring til at forstå long-tail nøgleord og nye søgemønstre. Neural Matching (2018) tog dette skridt videre ved at anvende neurale netværk til at matche forespørgsler med relevant indhold på et dybere semantisk niveau. BERT (Bidirectional Encoder Representations from Transformers), lanceret i 2019, markerede et stort fremskridt ved at forstå kontekst i sætninger og afsnit, hvilket forbedrede Googles evne til at tolke nuanceret sprog. Dog havde BERT betydelige begrænsninger—den behandlede kun tekst, havde begrænset flersproget støtte og kunne ikke håndtere kompleksiteten i forespørgsler, der krævede informationssyntese på tværs af flere formater. Ifølge Googles forskning stiller brugere gennemsnitligt otte separate forespørgsler for at besvare komplekse spørgsmål, såsom at sammenligne to vandredestinationer eller vurdere produktvalg. Denne statistik fremhævede et kritisk hul i søgeteknologi, som MUM specifikt blev designet til at udfylde. Helpful Content Update (2022) og E-E-A-T framework (2023) raffinerede yderligere, hvordan Google prioriterer autoritativt og troværdigt indhold. MUM bygger på alle disse innovationer og introducerer evner, der overstiger tidligere begrænsninger, hvilket ikke kun er en inkrementel forbedring, men et paradigmeskift i, hvordan søgemaskiner behandler og leverer information.
MUMs tekniske fundament bygger på Transformer-arkitekturen, specifikt T5 (Text-to-Text Transfer Transformer) frameworket, som Google tidligere udviklede. T5-frameworket behandler alle naturlige sprogopgaver som text-to-text-problemer og konverterer input og output til samlede tekstrepræsentationer. MUM udvider denne tilgang ved at inkorporere multimodal behandling, hvilket gør det muligt at håndtere tekst, billeder, video og lyd samtidigt i én samlet model. Dette arkitektoniske valg er væsentligt, fordi det giver MUM mulighed for at forstå relationer og kontekst på tværs af forskellige medietyper på måder, tidligere modeller ikke kunne. For eksempel, når der behandles en forespørgsel om at vandre på Mt. Fuji kombineret med et billede af specifikke vandrestøvler, analyserer MUM ikke teksten og billedet separat—den behandler dem sammen og forstår, hvordan støvlens egenskaber relaterer til forespørgslens kontekst. Modellens 110 milliarder parametre giver den kapacitet til at lagre og behandle enorme mængder viden om sprog, visuelle begreber og deres relationer. MUM er trænet på tværs af 75 forskellige sprog og mange forskellige opgaver samtidigt, hvilket gør det muligt at udvikle en mere omfattende forståelse af information og verdensviden end modeller, der kun er trænet på ét sprog eller én opgave. Denne multitask-læring betyder, at MUM lærer at genkende mønstre og relationer, der kan overføres på tværs af sprog og domæner, hvilket gør den mere robust og generaliserbar end tidligere modeller. Samtidig behandling af flere sprog under træningen gør, at MUM kan udføre vidensoverførsel mellem sprog, hvilket betyder, at den kan forstå information skrevet på ét sprog og anvende denne forståelse på forespørgsler på et andet sprog og dermed reelt nedbryde sproglige barrierer, der tidligere begrænsede søgeresultater.
| Attribut | MUM (2021) | BERT (2019) | RankBrain (2015) | T5 Framework |
|---|---|---|---|---|
| Primær funktion | Multimodal forespørgselsforståelse og svarsyntese | Tekstbaseret kontekstforståelse | Long-tail nøgleordstolkning | Text-to-text transfer learning |
| Inputmodaliteter | Tekst, billeder, video, lyd | Kun tekst | Kun tekst | Kun tekst |
| Sprogunderstøttelse | 75+ sprog indbygget | Begrænset flersproget støtte | Primært engelsk | Primært engelsk |
| Modelparametre | ~110 milliarder | ~340 millioner | Ikke offentliggjort | ~220 millioner |
| Effekt-sammenligning | 1.000x kraftigere end BERT | Udgangspunkt | Forgænger til BERT | Fundament for MUM |
| Kapaciteter | Forståelse + generering | Kun forståelse | Mønstergenkendelse | Teksttransformation |
| SERP-påvirkning | Berigede resultater i flere formater | Bedre uddrag og kontekst | Forbedret relevans | Grundlæggende teknologi |
| Håndtering af kompleksitet | Komplekse flertrinsforespørgsler | Enkelt-forespørgsels-kontekst | Long-tail variationer | Teksttransformation |
| Vidensoverførsel | På tværs af sprog og modaliteter | Kun inden for sprog | Begrænset overførsel | Opgaveoverførsel |
| Reel anvendelse | Google Søgning, AI Overviews | Google Søgning ranking | Google Søgning ranking | MUMs tekniske fundament |
MUMs forespørgselsbehandling involverer flere avancerede trin, der arbejder sammen for at levere omfattende, kontekstuelle svar. Når en bruger indsender en søgeforespørgsel, starter MUM med sproguafhængig forbehandling og forstår forespørgslen på ethvert af de 75+ understøttede sprog uden at kræve oversættelse. Denne indfødte sprogforståelse bevarer sproglige nuancer og regionale kontekster, der ellers kunne gå tabt i oversættelse. Dernæst anvender MUM sekvens-til-sekvens-matchning og analyserer hele forespørgslen som en meningssekvens frem for isolerede nøgleord. Denne tilgang gør det muligt for MUM at forstå relationer mellem begreber—for eksempel at genkende, at en forespørgsel om “forberedelse til Mt. Fuji efter at have besteget Mt. Adams” involverer sammenligning, forberedelse og kontekstuel tilpasning. Samtidig udfører MUM multimodal inputanalyse og behandler billeder, videoer eller andet medieindhold, der er inkluderet i forespørgslen. Modellen udfører derefter simultan forespørgselsbehandling og vurderer flere mulige brugerhensigter parallelt i stedet for at indsnævre til én fortolkning. Det betyder, at MUM kan genkende, at en forespørgsel om at vandre Mt. Fuji kan relatere sig til fysisk forberedelse, valg af udstyr, kulturelle oplevelser eller rejseplanlægning—og den viser relevant information for alle disse fortolkninger. Vektorbaseret semantisk forståelse konverterer forespørgslen og det indekserede indhold til højdimensionelle vektorer, der repræsenterer semantisk mening, hvilket muliggør søgning baseret på konceptuel lighed fremfor nøgleords-matchning. MUM anvender derefter indholdsfiltrering via vidensoverførsel og bruger maskinlæring, trænet på søgelogs, browserdata og brugeradfærd, til at prioritere kvalitetskilder. Til sidst genererer MUM en multimedieberiget SERP-sammensætning, der kombinerer tekstuddrag, billeder, videoer, relaterede spørgsmål og interaktive elementer til en samlet, visuelt lagdelt søgeoplevelse. Hele denne proces sker på millisekunder og gør det muligt for MUM at levere resultater, der adresserer ikke kun den eksplicitte forespørgsel, men også forventede opfølgende spørgsmål og relaterede informationsbehov.
MUMs multimodale egenskaber repræsenterer et grundlæggende brud med tekstbaserede søgesystemer. Modellen kan samtidigt behandle og forstå information fra tekst, billeder, video og lyd og udtrække mening fra hver modalitet og syntetisere det til sammenhængende svar. Denne evne er særlig stærk ved forespørgsler, der drager fordel af visuel kontekst. For eksempel, hvis en bruger spørger “Kan jeg bruge disse vandrestøvler til Mt. Fuji?” og samtidig viser et billede af sine støvler, forstår MUM støvlens egenskaber ud fra billedet—materiale, sålmønster, højde, farve—og forbinder denne visuelle forståelse med viden om Mt. Fujis terræn, klima og krav til fodtøj for at give et kontekstuelt svar. Den flersprogede dimension af MUM er lige så transformerende. Med indfødt støtte til 75+ sprog kan MUM udføre vidensoverførsel mellem sprog, hvilket betyder, at den lærer fra kilder på ét sprog og anvender denne viden på forespørgsler på et andet. Dette nedbryder en væsentlig barriere, der tidligere begrænsede søgeresultater til brugerens modersmål. Hvis omfattende information om Mt. Fuji primært findes i japanske kilder—herunder lokale vandreguides, sæsonvejrmønstre og kulturelle indsigter—kan MUM forstå dette japansksprogede indhold og vise relevant information til engelsktalende brugere. Ifølge Googles test var MUM i stand til at opliste 800 varianter af COVID-19-vacciner på over 50 sprog inden for få sekunder, hvilket viser skalaen og hastigheden af dens flersprogede behandling. Denne flersprogede forståelse er særlig værdifuld for brugere i ikke-engelsktalende markeder og for forespørgsler om emner med rigt informationsindhold på flere sprog. Kombinationen af multimodal og flersproget behandling betyder, at MUM kan fremhæve det mest relevante indhold uanset formatet eller det oprindelige sprog, hvilket skaber en virkelig global søgeoplevelse.
MUM forandrer grundlæggende, hvordan søgeresultater vises og opleves af brugere. I stedet for den traditionelle liste med blå links, der har domineret søgning i årtier, skaber MUM berigede, interaktive SERPs, der kombinerer flere indholdsformater på én side. Brugere kan nu se tekstuddrag, højopløste billeder, videokarusseller, relaterede spørgsmål og interaktive elementer—alt sammen uden at forlade søgeresultatsiden. Dette medfører store ændringer i, hvordan brugere interagerer med søgning. I stedet for at udføre flere søgninger for at indsamle information om et komplekst emne, kan brugerne undersøge forskellige vinkler og underemner direkte i SERP’en. For eksempel kan en forespørgsel om “forberedelse til Mt. Fuji om efteråret” vise højde-sammenligninger, vejrudsigter, udstyrsanbefalinger, videoguides og brugeranmeldelser—alt sammen organiseret kontekstuelt på én side. Google Lens-integration drevet af MUM gør det muligt at søge med billeder i stedet for nøgleord, hvilket gør visuelle elementer i fotos til interaktive opdagelsesværktøjer. “Ting at vide”-paneler opdeler komplekse forespørgsler i fordøjelige underemner og guider brugerne gennem forskellige aspekter med relevante uddrag. Zoomable, højopløste billeder vises direkte i søgeresultaterne, hvilket muliggør visuel sammenligning og reducerer friktionen i de tidlige beslutningsfaser. “Forfin og udvid”-funktionalitet foreslår relaterede begreber for at hjælpe brugerne med enten at dykke dybere ned i bestemte aspekter eller udforske nærliggende emner. Disse ændringer flytter søgning fra at være en simpel hentemekanisme til at blive en interaktiv, udforskende oplevelse, der forudser brugerbehov og leverer omfattende information direkte i søgegrænsefladen. Forskning viser, at denne rigere SERP-oplevelse reducerer det gennemsnitlige antal søgninger, der kræves for at besvare komplekse spørgsmål, men det betyder også, at brugere kan konsumere information direkte i søgeresultaterne uden at klikke videre til websites.
For organisationer, der overvåger deres tilstedeværelse på tværs af AI-systemer, repræsenterer MUM en kritisk udvikling i, hvordan information opdages og vises. Efterhånden som MUM i stigende grad integreres i Google Search og påvirker andre AI-systemer, bliver forståelsen af, hvordan brands og domæner vises i MUM-drevne resultater, afgørende for at opretholde synlighed. MUMs multimodale behandling betyder, at brands skal optimere på tværs af flere indholdsformater, ikke kun tekst. Et brand, der tidligere stolede på at rangere på bestemte nøgleord, skal nu sikre, at dets indhold kan opdages gennem billeder, videoer og strukturerede data. Modellens evne til at syntetisere information fra forskellige kilder betyder, at en brands synlighed afhænger ikke kun af dets eget website, men også af, hvordan dets information optræder i hele web-økosystemet. MUMs flersprogede evner skaber nye muligheder og udfordringer for globale brands. Indhold udgivet på ét sprog kan nu opdages af brugere, der søger på andre sprog, hvilket udvider den potentielle rækkevidde. Men det betyder også, at brands skal sikre, at deres information er korrekt og konsistent på tværs af sprog, da MUM kan fremhæve information fra flere sprogkilder til én forespørgsel. For AI-overvågningsplatforme som AmICited er det afgørende at spore MUMs indflydelse, fordi den repræsenterer, hvordan moderne AI-systemer henter og præsenterer information. Når man overvåger, hvor et brand optræder i AI-svar—uanset om det er i Google AI Overviews, Perplexity, ChatGPT eller Claude—hjælper forståelsen af MUMs underliggende teknologi med at forklare, hvorfor bestemt indhold fremhæves, og hvordan det kan optimeres for synlighed. Overgangen til multimodal og flersproget søgning betyder, at brands har brug for omfattende overvågning, der sporer deres tilstedeværelse på tværs af forskellige formater og sprog—ikke kun traditionelle nøgleordsplaceringer. Organisationer, der forstår MUMs muligheder, kan bedre optimere deres indholdsstrategi for at sikre synlighed i dette nye søgelandskab.
Selvom MUM repræsenterer et stort fremskridt, introducerer den også nye udfordringer og begrænsninger, som organisationer skal håndtere. Lavere klikrater er en væsentlig bekymring for udgivere og indholdsskabere, da brugere nu kan konsumere omfattende information direkte i søgeresultaterne uden at klikke videre. Denne ændring betyder, at traditionelle trafikmålinger bliver mindre pålidelige indikatorer for indholdssucces. Øgede tekniske SEO-krav betyder, at indhold skal være velstruktureret med passende schema markup, semantisk HTML og klare entitetsrelationer for at blive korrekt forstået af MUM. Indhold, der mangler dette tekniske fundament, kan blive dårligt indekseret eller misforstået af MUMs multimodale behandling. SERP-mætning skaber udfordringer for synlighed, da flere indholdsformater konkurrerer om opmærksomhed på én side. Selv stærkt indhold kan få færre eller ingen klik, hvis brugere finder tilstrækkelig information direkte i SERP’en. Potentiel for vildledende resultater opstår, når MUM viser information fra flere kilder, der kan modstride hinanden, eller når kontekst går tabt i syntesen. Afhængighed af strukturerede data betyder, at ustruktureret eller dårligt formateret indhold måske ikke forstås eller vises korrekt af MUM. Sprog- og kulturfordrejninger kan opstå, når MUM overfører viden på tværs af sprog og muligvis overser kulturel kontekst eller regionale betydningsvariationer. Krav til beregningsressourcer for at køre MUM i stor skala er betydelige, selvom Google har investeret i effektivitetsforbedringer for at reducere CO2-aftryk. Bias og fairness-problematikker kræver løbende opmærksomhed for at sikre, at MUM ikke viderefører bias fra træningsdata eller udelukker bestemte perspektiver eller samfund.
Fremkomsten af MUM kræver grundlæggende ændringer i, hvordan organisationer arbejder med SEO og indholdsstrategi. Traditionel, nøgleordsfokuseret optimering bliver mindre effektiv, når MUM kan forstå hensigt og kontekst ud over eksakte nøgleord. Emnebaseret indholdsstrategi bliver vigtigere end nøgleordsbaseret strategi, og organisationer skal skabe omfattende indholdsklynger, der dækker emner fra flere vinkler. Multimedieindhold er ikke længere valgfrit—organisationer skal investere i billeder, videoer og interaktivt indhold af høj kvalitet, der supplerer tekstindhold. Implementering af strukturerede data bliver kritisk, da schema markup hjælper MUM med at forstå indholdsstruktur og relationer. Entitetsopbygning og semantisk optimering styrker tematisk autoritet og forbedrer MUMs forståelse af indholdsrelationer. Flersproget indholdsstrategi får større betydning, da MUMs sprogtransfer-muligheder betyder, at indhold kan opdages på tværs af sprogområder. Kortlægning af brugerhensigt bliver mere avanceret og kræver, at organisationer forstår ikke kun primær hensigt, men også relaterede spørgsmål og underemner, brugere kan udforske. Indholdets aktualitet og nøjagtighed bliver vigtigere, da MUM syntetiserer information fra flere kilder—forældet eller upræcist indhold kan blive nedprioriteret. Optimering på tværs af platforme omfatter nu ikke kun Google Search, men også AI-systemer som Google AI Overviews, Perplexity og andre AI-drevne søgeflader. E-E-A-T-signaler (Experience, Expertise, Authoritativeness, Trustworthiness) bliver stadig vigtigere, da MUM prioriterer indhold fra autoritative kilder. Organisationer, der tilpasser deres strategier til MUMs muligheder—med fokus på omfattende, multimodalt, velstruktureret indhold, der demonstrerer ekspertise og autoritet—vil bevare synligheden i dette udviklende søgelandskab.
MUM er ikke en endestation, men et skridt på vejen i udviklingen af AI-drevet søgning. Google har signaleret, at MUM løbende vil udvide sine evner, hvor video- og lydbehandling bliver stadig mere sofistikeret. Virksomheden forsker aktivt i at reducere MUMs beregningsmæssige fodaftryk uden at gå på kompromis med ydeevnen for at imødekomme bæredygtighedsbekymringer omkring store AI-modeller. Integration af MUM med andre Google-teknologier peger på fremtidige udviklinger, hvor MUMs forståelse driver ikke kun søgning, men også Google Assistant, Google Lens og andre produkter. Konkurrencepres fra andre AI-systemer som OpenAI’s ChatGPT, Anthropic’s Claude og Perplexitys AI-søgemaskine betyder, at MUM sandsynligvis vil udvikle sig løbende for at bevare Googles fordel. Regulatorisk opmærksomhed på AI-systemer kan påvirke, hvordan MUM udvikles, især hvad angår bias, fairness og gennemsigtighed. Brugeradfærdsændringer vil forme MUMs udvikling—efterhånden som brugere vænner sig til rigere, mere interaktive søgeoplevelser, vil forventningerne til søgekvalitet og omfang stige. Stigningen i generativ AI betyder, at MUMs evner til at syntetisere og generere information sandsynligvis vil blive endnu mere fremtrædende og måske gøre det muligt for MUM at skabe originalt indhold, ikke kun hente og organisere eksisterende. Multimodal AI som standard antyder, at MUMs tilgang med samtidig behandling af flere formater vil blive normen på tværs af AI-systemer. Privatlivs- og dataspørgsmål vil påvirke, hvordan MUM bruger brugerdata og adfærdssignaler til at personalisere og forbedre resultater. Organisationer bør forberede sig på fortsat udvikling ved at bygge fleksible, tilpasningsdygtige indholdsstrategier, der prioriterer kvalitet, omfang og teknisk excellence, fremfor at stole på specifikke taktikker, der kan blive forældede efterhånden som MUM udvikler sig. Det grundlæggende princip—at skabe indhold, der reelt opfylder brugerhensigt på tværs af formater og sprog—vil forblive aktuelt uanset, hvordan MUMs specifikke evner udvikler sig.
Mens BERT (2019) fokuserede på at forstå naturligt sprog i tekstbaserede forespørgsler, repræsenterer MUM en markant udvikling. MUM er bygget på T5 text-to-text framework og er 1.000 gange mere kraftfuld end BERT. I modsætning til BERTs tekstbaserede behandling er MUM multimodal—den behandler tekst, billeder, video og lyd samtidigt. Derudover understøtter MUM 75+ sprog indbygget, hvor BERT kun havde begrænset flersproget støtte ved lanceringen. MUM kan både forstå og generere sprog, hvilket gør den i stand til at håndtere komplekse, flertrinsforespørgsler, som BERT ikke effektivt kunne adressere.
Multimodal refererer til MUMs evne til at behandle og forstå information fra flere typer inputformater samtidigt. I stedet for at analysere tekst separat fra billeder eller video, behandler MUM alle disse formater samlet på en integreret måde. Det betyder, at når du søger efter noget som 'vandrestøvler til Mt. Fuji', kan MUM forstå din tekstforespørgsel, analysere billeder af støvler, se videoreviews og udtrække lyd-beskrivelser—alt sammen på én gang. Denne integrerede tilgang giver MUM mulighed for at levere rigere, mere kontekstuelle svar, der tager højde for information på tværs af alle disse medietyper.
MUM er trænet på tværs af 75+ sprog, hvilket er et stort fremskridt for global søgeadgang. Denne flersprogede kapacitet betyder, at MUM kan overføre viden mellem sprog—hvis nyttig information om et emne findes på japansk, kan MUM forstå det og vise relevante resultater til engelsktalende brugere. Dette nedbryder sproglige barrierer, der tidligere begrænsede søgeresultater til indhold på brugerens modersmål. For brands og indholdsskabere betyder det, at deres indhold har potentiel synlighed på tværs af flere sprogmarkeder, og brugere over hele verden kan få adgang til information uanset oprindeligt udgivelsessprog.
T5 (Text-to-Text Transfer Transformer) er Googles tidligere transformerbaserede model, som MUM er bygget på. T5-frameworket betragter alle NLP-opgaver som text-to-text-problemer, hvilket betyder, at det konverterer input og output til tekstformat for en samlet behandling. MUM udvider T5's evner ved at inkorporere multimodal behandling (håndtering af billeder, video og lyd) og skalerer det til cirka 110 milliarder parametre. Dette fundament gør det muligt for MUM både at forstå og generere sprog, samtidig med at den bevarer den effektivitet og fleksibilitet, der gjorde T5 succesfuld.
MUM ændrer grundlæggende, hvordan indhold opdages og vises i søgeresultater. I stedet for traditionelle blå linklister skaber MUM berigede SERPs med flere indholdsformater—billeder, videoer, tekstuddrag og interaktive elementer—alt sammen på én side. Det betyder, at brands skal optimere på tværs af flere formater, ikke kun tekst. Indhold, der tidligere krævede, at brugere klikkede gennem flere sider, kan nu vises direkte i søgeresultaterne. Dette betyder dog også lavere klikrater for noget indhold, da brugerne kan konsumere information inden for selve SERP'en. Brands skal nu fokusere på synlighed i søgeresultaterne og sikre, at deres indhold er struktureret med schema markup for at blive korrekt forstået af MUM.
MUM er kritisk for AI-overvågningsplatforme, fordi den repræsenterer, hvordan moderne AI-systemer forstår og henter information. Efterhånden som MUM bliver mere udbredt i Google Search og påvirker andre AI-systemer, bliver det essentielt at overvåge, hvor brands og domæner vises i MUM-drevne resultater. AmICited sporer, hvordan brands nævnes og vises på tværs af AI-systemer, herunder Googles MUM-forstærkede søgning. Forståelse af MUMs multimodale og flersprogede egenskaber hjælper organisationer med at optimere deres tilstedeværelse på tværs af forskellige indholdsformater og sprog og sikrer, at de er synlige, når AI-systemer som MUM henter og viser deres information til brugere.
Ja, MUM kan behandle billeder og video med sofistikeret forståelse. Når du uploader et billede eller inkluderer video i en forespørgsel, genkender MUM ikke kun objekter—den udtrækker kontekst, betydning og relationer. For eksempel, hvis du viser MUM et foto af vandrestøvler og spørger 'kan jeg bruge disse til Mt. Fuji?', forstår MUM støvlens egenskaber ud fra billedet og forbinder denne forståelse med dit spørgsmål for at give et kontekstuelt svar. Denne multimodale forståelse er en af MUMs stærkeste egenskaber, der gør det muligt at besvare spørgsmål, der kræver visuel forståelse kombineret med tekstuel viden.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær om Googles Multitask Unified Model (MUM) og dens indvirkning på AI-søgeresultater. Forstå hvordan MUM behandler komplekse forespørgsler på tværs af flere fo...
Fællesskabsdiskussion, der forklarer Google MUM og dets indflydelse på AI-søgning. Eksperter deler, hvordan denne multimodale AI-model påvirker optimering af in...

Bliv ekspert i optimering af multimodal AI-søgning. Lær, hvordan du optimerer billeder og stemmeforespørgsler til AI-drevne søgeresultater, med strategier til G...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.