
Prompt-biblioteker til manuel AI-synlighedstest
Lær hvordan du bygger og bruger prompt-biblioteker til manuel AI-synlighedstest. Gør-det-selv guide til at teste, hvordan AI-systemer henviser til dit brand på ...
10 min læsning
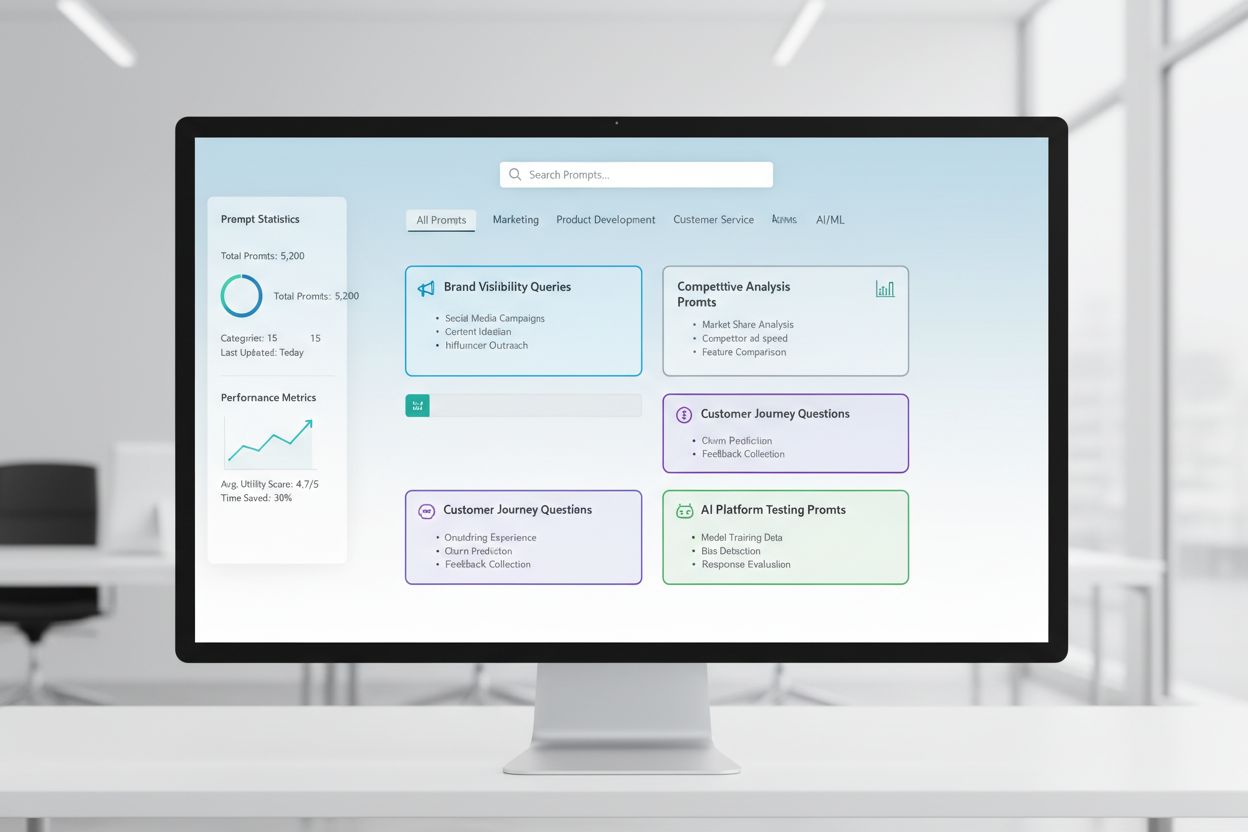
Udvikling af Promptbibliotek er den systematiske proces, hvor man opbygger og organiserer omfattende samlinger af forespørgsler, der er designet til at teste og overvåge, hvordan brands fremstår på AI-drevne platforme. Det etablerer en standardiseret ramme for at vurdere brandets synlighed på tværs af flere AI-systemer, hvilket gør det muligt for organisationer at følge den konkurrencemæssige positionering og identificere synlighedshuller i AI-drevet søgning.
Udvikling af Promptbibliotek er den systematiske proces, hvor man opbygger og organiserer omfattende samlinger af forespørgsler, der er designet til at teste og overvåge, hvordan brands fremstår på AI-drevne platforme. Det etablerer en standardiseret ramme for at vurdere brandets synlighed på tværs af flere AI-systemer, hvilket gør det muligt for organisationer at følge den konkurrencemæssige positionering og identificere synlighedshuller i AI-drevet søgning.
Udvikling af Promptbibliotek er den systematiske proces, hvor man opbygger og organiserer omfattende samlinger af forespørgsler, der er designet til at teste og overvåge, hvordan brands fremstår på AI-drevne platforme. Et promptbibliotek fungerer som et struktureret arkiv af nøje udformede spørgsmål, søgetermer og samtaleprompts, der simulerer reelle brugerinteraktioner med AI-systemer som ChatGPT, Claude, Gemini og Perplexity. Begrebet “bibliotek” afspejler den organiserede, katalogiserede karakter af disse samlinger—på samme måde som traditionelle biblioteker organiserer information efter emne, kategori og relevans. I modsætning til ad hoc-testning etablerer udvikling af promptbibliotek en standardiseret ramme for vurdering af brandets synlighed, hvilket sikrer ensartet måling på tværs af flere AI-platforme og tidsperioder. Denne tilgang anerkender, at AI-systemer reagerer forskelligt på forskellige formuleringer, kontekster og intentsignaler, hvilket gør det essentielt at teste en bred vifte af prompts i stedet for at stole på enkeltforespørgsler. Biblioteket fungerer både som testinstrument og historisk arkiv, så organisationer kan følge, hvordan deres brandets synlighed udvikler sig, efterhånden som AI-modeller opdateres og brugeradfærd ændres. Ved at behandle prompttestning som en styret disciplin frem for en lejlighedsvis aktivitet opnår virksomheder anvendelig indsigt i deres konkurrencemæssige position i det AI-drevne søgelandskab.
| Aspect | Traditionel SEO-overvågning | Promptbibliotekstilgang |
|---|---|---|
| Testomfang | Begrænset til søgemaskine-søgeord | Omfattende test på tværs af flere AI-platforme med varierede formuleringer |
| Forespørgselsvariation | Faste søgeordslister | Dynamiske, intent-baserede prompts, der afspejler naturlig samtale |
| Målingshyppighed | Månedlige eller kvartalsvise øjebliksbilleder | Kontinuerlig eller ugentlig overvågning med detaljeret trendanalyse |
| Konkurrenceindsigt | Søgeordsplaceringer | Frekvens af brandomtaler, kontekstkvalitet og positioneringsnøjagtighed |
Overgangen til AI-drevet informationssøgning har fundamentalt ændret, hvordan brands bør overvåge deres synlighed. Traditionel SEO-overvågning fokuserer på søgeordsplaceringer på søgeresultatsider, men denne metode fanger ikke, hvordan brands fremstår, når brugere interagerer samtalebaseret med AI-systemer. Promptbiblioteker afhjælper dette hul ved at give organisationer mulighed for at forstå deres tilstedeværelse på en helt ny kategori af opdagelsesplatforme. Forretningsværdien er betydelig: Virksomheder, der systematisk overvåger deres AI-synlighed, opnår konkurrencefordel ved at identificere mangler i brandrepræsentation, opdage hvilke emner eller kontekster, der udløser brandomtaler, og forstå, hvordan AI-systemer karakteriserer deres produkter i forhold til konkurrenterne. Denne indsigt informerer direkte indholdsstrategi, produktpositionering og markedsføringsbudskaber. Organisationer, der bruger promptbiblioteker, kan opdage nye konkurrencetrusler hurtigere end dem, der udelukkende benytter traditionelle SEO-målinger, da AI-systemer ofte fremhæver andre konkurrentsæt end søgemaskiner. Derudover afslører test af promptbiblioteker nuanceret indsigt i brandopfattelse—ikke blot om et brand optræder, men hvordan det beskrives, hvilke attributter der tilknyttes, og om AI-systemets karakteristik stemmer overens med brandets ønskede positionering.
At skabe et effektivt promptbibliotek kræver en struktureret metode, der kombinerer kundeundersøgelser, konkurrenceanalyse og strategisk planlægning:
Udfør Kundeundersøgelser: Interview målgrupper, analyser supporthenvendelser og gennemgå sociale medier for at identificere de faktiske spørgsmål og sprogmønstre, brugere benytter, når de søger information om din kategori. Det sikrer, at dine prompts afspejler reel brugerintention frem for interne antagelser.
Kortlæg Kunderejsen: Identificér nøglebeslutningspunkter og informationsbehov på tværs af opmærksomhed, overvejelse og beslutningsstadier. Udarbejd prompts, der matcher hvert stadie og afspejler, hvordan kunder søger information i købsprocessen.
Definér Intentkategorier: Organisér prompts efter intenttype—information (lære om en kategori), sammenligning (vurdere muligheder), transaktion (klar til køb) og brand-specifik (direkte søgning på din virksomhed). Denne struktur sikrer omfattende dækning af, hvordan brugere kan opdage dit brand.
Skab Promptvariationer: Udarbejd flere formuleringer for hvert kerne-spørgsmål for at tage højde for, hvordan forskellige brugere kan formulere det samme behov. Inkludér variationer i formalitet, specificitet og kontekst for at afspejle den virkelige diversitet i, hvordan folk interagerer med AI-systemer.
Etabler Baseline-prompts: Udarbejd et kerne-sæt på 20-50 essentielle prompts, der repræsenterer dine vigtigste synlighedsmuligheder. Disse danner grundlag for løbende overvågning og sammenligning over tid.
Dokumentér Promptmetadata: For hver prompt registreres intentkategori, stadie i kunderejsen, prioritetsniveau og forventet brandrelevans. Disse metadata muliggør avanceret analyse og hjælper med at identificere mønstre for, hvor dit brand optræder eller mangler.
Valider med Interessenter: Gennemgå dit promptbibliotek med salgs-, marketing- og produktteams for at sikre, at det dækker de spørgsmål og scenarier, der er mest relevante for forretningsmålene.
Et omfattende promptbibliotek er struktureret omkring flere dimensioner, der sikrer grundig dækning af muligheder for brandets synlighed. Biblioteket omfatter typisk tragtniveau-prompts, der matcher kunderejsen: TOFU (Top of Funnel)-prompts adresserer brede informationsspørgsmål, hvor brugeren undersøger en kategori eller et problem, såsom “Hvad er de bedste projektstyringsværktøjer?” eller “Hvordan forbedrer jeg teamsamarbejdet?” MOFU (Middle of Funnel)-prompts fokuserer på sammenlignende og vurderende spørgsmål, hvor brugeren aktivt overvejer løsninger, f.eks. “Sammenlign projektstyringssoftware til fjernteams” eller “Hvilke funktioner bør jeg se efter i en samarbejdsplatform?” BOFU (Bottom of Funnel)-prompts retter sig mod beslutningsstadiet, hvor brugeren er klar til at købe eller implementere, såsom “Hvorfor skal jeg vælge [Brand] frem for konkurrenter?” eller “Hvad er [Brand]s prismodel?” Ud over tragtniveauer organiserer effektive biblioteker prompts efter intentkategorier—information, navigation, sammenligning og transaktion—så synligheden måles på tværs af forskellige brugertyper. Biblioteker inkluderer også kontekstuelle variationer, der tester, hvordan brandets synlighed ændres afhængigt af branche, anvendelsestilfælde, virksomhedsstørrelse eller geografisk placering. Derudover inkorporerer velfungerende biblioteker konkurrenceprompts, der viser, hvordan dit brand optræder i direkte sammenligning med specifikke konkurrenter, og attributbaserede prompts, der tester synlighed for specifikke produktegenskaber, fordele eller differentieringspunkter. Denne multidimensionelle struktur sikrer, at overvågningen fanger hele spektret af måder, potentielle kunder kan opdage og vurdere dit brand gennem AI-systemer.
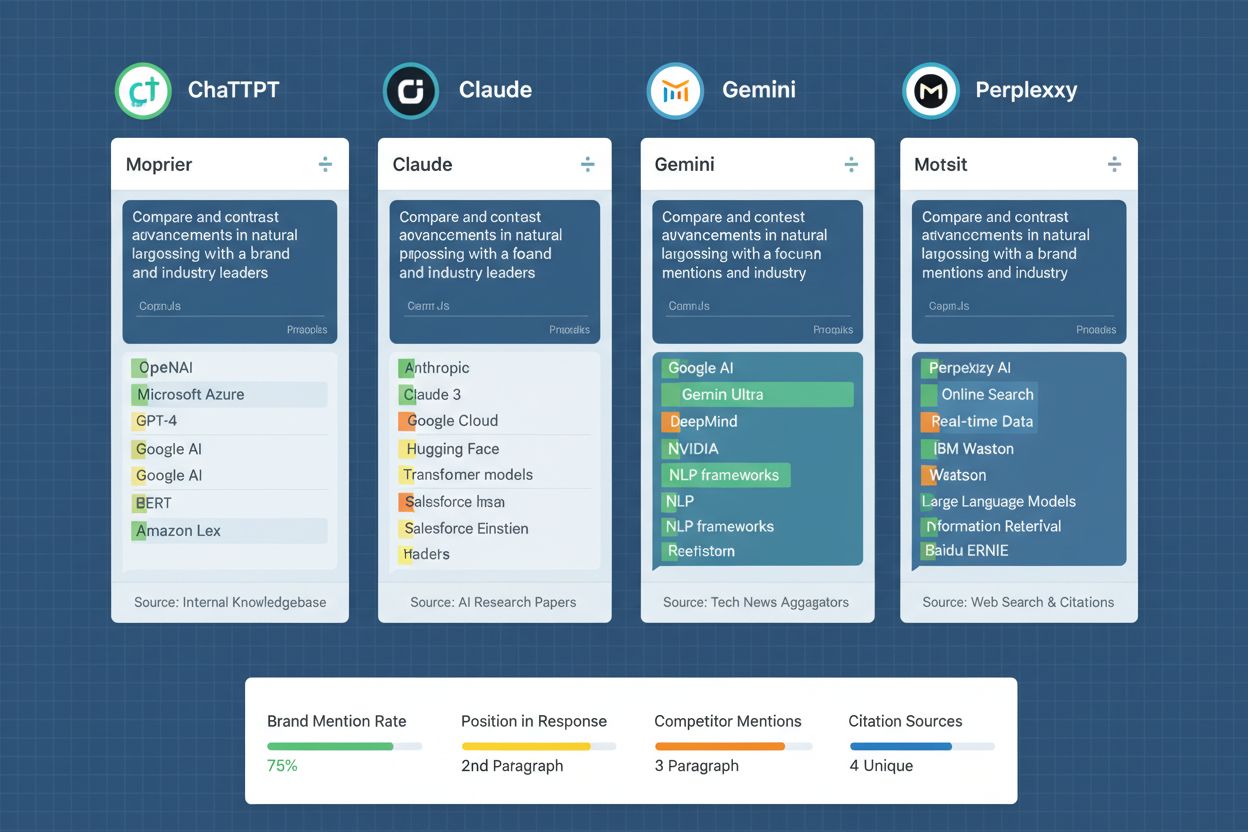
Gennemførsel af et promptbibliotek på tværs af flere AI-platforme kræver systematiske processer for dataindsamling, analyse og fortolkning. Organisationer tester typisk deres promptbibliotek mod ChatGPT (det mest anvendte AI-system), Claude (kendt for detaljerede og nuancerede svar), Gemini (Googles AI med integrerede søgefunktioner) og Perplexity (en AI-søgemaskine med citationsfunktioner). Testhyppigheden afhænger af forretningsprioriteter og tilgængelige ressourcer—mange organisationer gennemfører ugentlige eller to-ugentlige testcyklusser for at opdage ændringer i brandets synlighed, mens andre implementerer kontinuerlig overvågning via automatiserede værktøjer. For hver prompt registrerer testere, om brandet nævnes, konteksten og positioneringen af omtalen, nøjagtigheden af informationen og hvor fremtrædende omtalen er sammenlignet med konkurrenterne. Dataindsamlingen går ud over simple ja/nej-brandomtaler og inkluderer kvalitativ vurdering af, hvordan brandet karakteriseres—om beskrivelserne er korrekte, om vigtige differentieringspunkter fremhæves, og om AI-systemets respons stemmer overens med brandets ønskede positionering. Analysen indebærer at følge tendenser over tid for at identificere, om brandets synlighed forbedres eller forværres, korrelere synlighedsændringer med indholdsopdateringer eller konkurrencehandlinger og identificere mønstre i, hvilke prompts der genererer brandomtaler, og hvilke der resulterer i fravær af brandet. Organisationer opretter ofte dashboards, der visualiserer disse data, så interessenter hurtigt kan forstå tendenser i brandets synlighed og identificere områder, der kræver justering af indhold eller strategi. Testhyppighed og dybde bør tilpasses AI-modellernes opdateringshastighed og konkurrenceaktiviteten i din branche.
| Værktøjsnavn | Bedst til | Nøglefunktioner | Startpris |
|---|---|---|---|
| AmICited.com | Omfattende overvågning af AI-brand synlighed | Test på tværs af platforme, automatiseret promptudførelse, konkurrencebenchmarking, detaljerede analysetavler, sporing af brandomtaler | Tilpasset pris |
| FlowHunt.io | Organisering og test af promptbibliotek | Promptversionering, A/B-testfunktioner, præstationsanalyse, teamsamarbejde, integration med større AI-platforme | Tilpasset pris |
| Braintrust | Evaluering og optimering af prompts | Automatiseret test, præstationsscoring, omkostningssporing på tværs af modeller, detaljeret logning og analyse | Gratis version tilgængelig |
| LangSmith | Udvikling og overvågning af LLM-applikationer | Promptversionering, kørselssporing, præstationsmålinger, fejlfinding, integration med LangChain-økosystemet | Gratis version tilgængelig |
| Promptfoo | Open-source prompttest og evaluering | Lokal test, understøttelse af flere modeller, assertionsbaseret test, detaljeret rapportering, tilpasselige evalueringsmålinger | Open source (gratis) |
| Weights & Biases | Eksperimentsporing og modelevaluering | Omfattende logning, visualisering, sammenligningsværktøjer, teamsamarbejde, integration med ML-arbejdsgange | Gratis version tilgængelig |
Styring af promptbiblioteker i stor skala kræver specialiserede værktøjer, der er designet til at håndtere test på tværs af flere AI-platforme, følge resultater over tid og muliggøre teamsamarbejde. AmICited.com skiller sig ud som den førende platform, der specifikt er designet til overvågning af brandets synlighed på tværs af AI-systemer og tilbyder automatiseret promptudførelse, konkurrencebenchmarking og detaljeret analyse, der direkte adresserer behovene hos organisationer, der følger brandets tilstedeværelse i AI-genererede svar. FlowHunt.io er det bedste valg til organisering og optimering af promptbiblioteker og tilbyder avanceret versionering, A/B-test og præstationsanalyse, så teams løbende kan forbedre deres promptsamlinger. Braintrust udmærker sig ved automatiseret evaluering og scoring af promptpræstation og er værdifuldt for organisationer, der ønsker systematisk at måle, hvilke prompts der genererer mest relevant brandets synlighed. LangSmith, udviklet af LangChain, giver omfattende sporing og fejlfinding, hvilket især er nyttigt for teams, der bygger AI-applikationer med brandovervågning. Promptfoo tilbyder et open-source alternativ til organisationer, der foretrækker lokal kontrol og tilpasning med stærke assertionsbaserede testmuligheder. Weights & Biases leverer enterprise-grade eksperimentsporing og visualisering, nyttigt for teams, der håndterer store prompttestinitiativer. Valget afhænger af, om din organisation prioriterer brugervenlighed og brand-specifikke funktioner (AmICited.com, FlowHunt.io), omkostningseffektivitet (open-source muligheder) eller integration med eksisterende udviklingsarbejdsgange (LangSmith, Weights & Biases).
Vedligeholdelse af et effektivt promptbibliotek kræver løbende forfining og systematisk optimering. Organisationer bør etablere en regelmæssig gennemgangscyklus—typisk kvartalsvis—for at vurdere, om prompts fortsat er relevante for forretningsprioriteter, om nye kundespørgsmål eller markedsudviklinger kræver nye prompts, og om eksisterende prompts bør fjernes eller tilpasses. Testhyppighed skal balancere grundighed med ressourcer; de fleste organisationer finder, at ugentlige eller to-ugentlige testcyklusser giver tilstrækkelige data til at opdage meningsfulde ændringer i brandets synlighed uden at skabe uholdbar driftsbelastning. Præstationsmåling bør gå ud over blot optælling af brandomtaler til at inkludere kvalitative målinger som omtale-kvalitet, positioneringsnøjagtighed og konkurrencekontekst. Teams bør dokumentere baseline-præstation for hver prompt og etablere klare benchmarks, som forbedring eller forværring måles imod. Når brandets synlighed falder for specifikke prompts, bør undersøgelsen afgøre, om årsagen er ekstern (AI-modelopdateringer, konkurrencehandlinger, markedsændringer) eller intern (forældet indhold, misalignment i budskaber, tekniske problemer). Iterativ optimering indebærer at teste promptvariationer for at identificere, hvilke formuleringer der giver de mest præcise eller fremtrædende brandomtaler, og derefter opdatere biblioteket baseret på disse resultater. Organisationer bør også implementere et feedback-loop, hvor indsigt fra prompttestning direkte informerer indholdsstrategien, så synlighedshuller identificeret gennem test bliver adresseret med indholdsudvikling eller optimering. Dokumentation af promptpræstation, testmetodologi og optimeringsbeslutninger skaber institutionel viden, der muliggør ensartet udførelse og løbende forbedring over tid.
Udvikling af promptbibliotek fungerer som et kritisk element i den bredere AI-synligheds- og indholdsstrategi og informerer direkte, hvordan brands positionerer sig i et AI-drevet informationslandskab. Den indsigt, der genereres gennem systematisk prompttestning, afslører forskelle mellem, hvordan et brand ønsker at blive opfattet, og hvordan AI-systemer faktisk karakteriserer det, hvilket gør det muligt at målrette indhold og budskaber. Når test viser, at et brand mangler i AI-svar på relevante forespørgsler, signalerer det en indholdsmulighed—organisationen bør udvikle indhold, der adresserer disse specifikke informationsbehov og kontekster. Omvendt, når test viser, at et brand optræder, men er fejlagtigt karakteriseret eller positioneret ugunstigt i forhold til konkurrenterne, indikerer det behov for indhold, der retter misforståelser eller styrker nøgleforskelle. Promptbiblioteksdata understøtter direkte konkurrenceintelligens ved at afsløre, hvilke konkurrenter der oftest nævnes i AI-svar, hvordan konkurrencemæssig positionering varierer på tværs af platforme, og hvilke attributter eller fordele konkurrenterne fremhæver. Denne indsigt informerer produktpositionering, budskabsstrategi og indholdsprioriteter. ROI for udvikling af promptbibliotek viser sig gennem forbedret brandets synlighed i AI-systemer, mere korrekt repræsentation af brandets attributter og fordele samt hurtigere identifikation af konkurrencetrusler eller markedsændringer. Organisationer, der systematisk overvåger og optimerer deres AI-synlighed med promptbiblioteker, opnår strategisk fordel ved at sikre, at deres brand optræder i relevante AI-genererede svar, at informationen er korrekt og positiv, og at positioneringen matcher markedsmulighederne. Integration af promptbiblioteksindsigt i indholdsstrategi, produktudvikling og konkurrencemæssig positionering skaber et feedback-loop, hvor synlighedsovervågning direkte driver forretningsstrategisk forfinelse.
Et promptbibliotek fokuserer på at teste, hvordan brands fremstår på tværs af AI-platforme via samtalebaserede forespørgsler, mens traditionel søgeordsanalyse retter sig mod placeringer i søgemaskiner. Promptbiblioteker indfanger, hvordan AI-systemer fortolker og reagerer på forskellige formuleringer, intentsignaler og kontekstuelle variationer—og giver indsigt i brandets synlighed i AI-genererede svar frem for søgeplaceringer.
De fleste organisationer gennemfører ugentlige eller to-ugentlige testcyklusser for at opdage betydningsfulde ændringer i brandets synlighed. Hyppigheden afhænger af din branches forandringshastighed, konkurrenceaktivitet og AI-modellernes opdateringscyklus. Ugentlig testning giver tilstrækkelige data til at identificere tendenser uden at skabe uholdbar operationel belastning.
Effektive promptbiblioteker indeholder typisk 50-150 prompts, organiseret efter tragtniveauer (TOFU, MOFU, BOFU) og intentkategorier. Start med 20-50 kerneprompts, der repræsenterer dine vigtigste synlighedsmuligheder, og udvid derefter baseret på forretningsprioriteter, konkurrencebillede og kundeindsigter.
Test mod ChatGPT (mest udbredte), Claude (detaljerede svar), Gemini (integreret søgning) og Perplexity (AI-søgemaskine). Disse fire platforme dækker størstedelen af AI-drevet opdagelse. Inkludér yderligere platforme som Google AI Overviews eller specialiserede AI-systemer, der er relevante for din branche.
Effektiviteten måles gennem frekvensen af brandomtaler, nøjagtigheden af positionering, konkurrencekontekst og overensstemmelse med forretningsmål. Følg med i, om dit brand optræder i relevante AI-svar, om karakteriseringen er korrekt, og om synlighedstendenser forbedres over tid, efterhånden som du optimerer indhold og strategi.
Ja. Platforme som AmICited.com, Braintrust og LangSmith muliggør automatiseret testning på tværs af flere AI-platforme. Automatisering håndterer udførelse, dataindsamling og basal analyse, så dit team kan fokusere på strategisk fortolkning og optimeringsbeslutninger.
Test af promptbibliotek afslører synlighedshuller og fejlagtige karakteriseringer, som direkte informerer indholdsprioriteter. Når test viser, at dit brand mangler i relevante AI-svar, signalerer det en indholdsmulighed. Når test afslører fejlagtig karakterisering, indikerer det behov for korrigerende indhold.
ROI viser sig gennem forbedret brandets synlighed i AI-systemer, mere præcis brandrepræsentation, hurtigere opdagelse af konkurrencetrusler og datadrevet indholdsstrategi. Organisationer opnår strategisk fordel ved at sikre korrekt brandpositionering i AI-genererede svar, som i stigende grad påvirker kunders opdagelse og beslutningstagning.
Følg hvordan dit brand fremstår i ChatGPT, Claude, Gemini, Perplexity og Google AI Overviews med AmICited's omfattende platform til overvågning af AI-brand synlighed.
Lær hvordan du bygger og bruger prompt-biblioteker til manuel AI-synlighedstest. Gør-det-selv guide til at teste, hvordan AI-systemer henviser til dit brand på ...

Lær hvordan du opretter og organiserer et effektivt prompt-bibliotek for at spore dit brand på tværs af ChatGPT, Perplexity og Google AI. Trin-for-trin guide me...
Opdag de bedste AI prompt forskningsværktøjer og opdagelsesplatforme til overvågning af brandomtaler på tværs af ChatGPT, Perplexity, Claude og Gemini. Sammenli...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.