Query Fanout: Hvordan LLM'er genererer flere søgninger bag kulisserne
Opdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT opdeler enkeltforespørgsler i flere søgninger. Lær om query fanout-mekanismer, konsekvenser for ...
8 min læsning
Query Fanout er AI-processen, hvor en enkelt brugerforespørgsel automatisk udvides til flere relaterede underforespørgsler for at indsamle omfattende information fra forskellige vinkler. Denne teknik hjælper AI-systemer med at forstå brugerens egentlige hensigt og levere mere præcise, kontekstuelt relevante svar ved at udforske forskellige fortolkninger og aspekter af det oprindelige spørgsmål.
Query Fanout er AI-processen, hvor en enkelt brugerforespørgsel automatisk udvides til flere relaterede underforespørgsler for at indsamle omfattende information fra forskellige vinkler. Denne teknik hjælper AI-systemer med at forstå brugerens egentlige hensigt og levere mere præcise, kontekstuelt relevante svar ved at udforske forskellige fortolkninger og aspekter af det oprindelige spørgsmål.
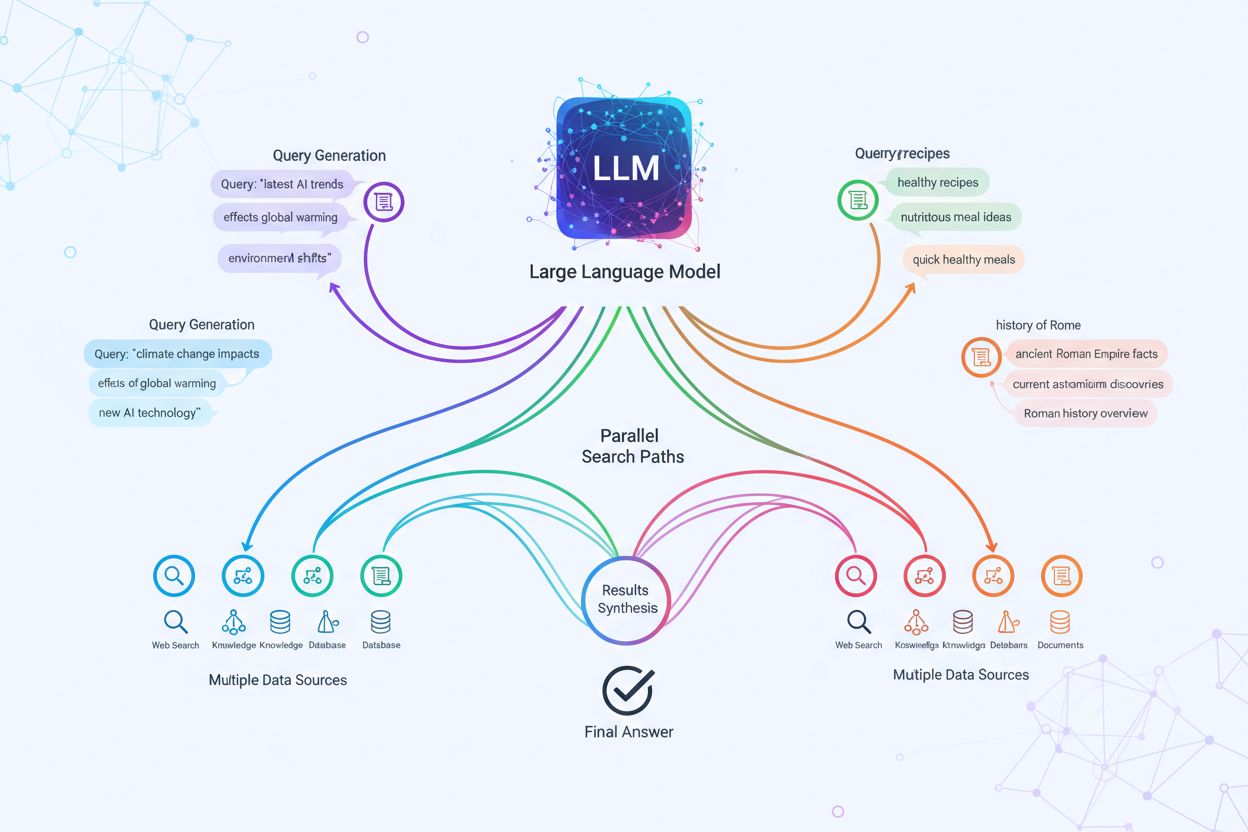
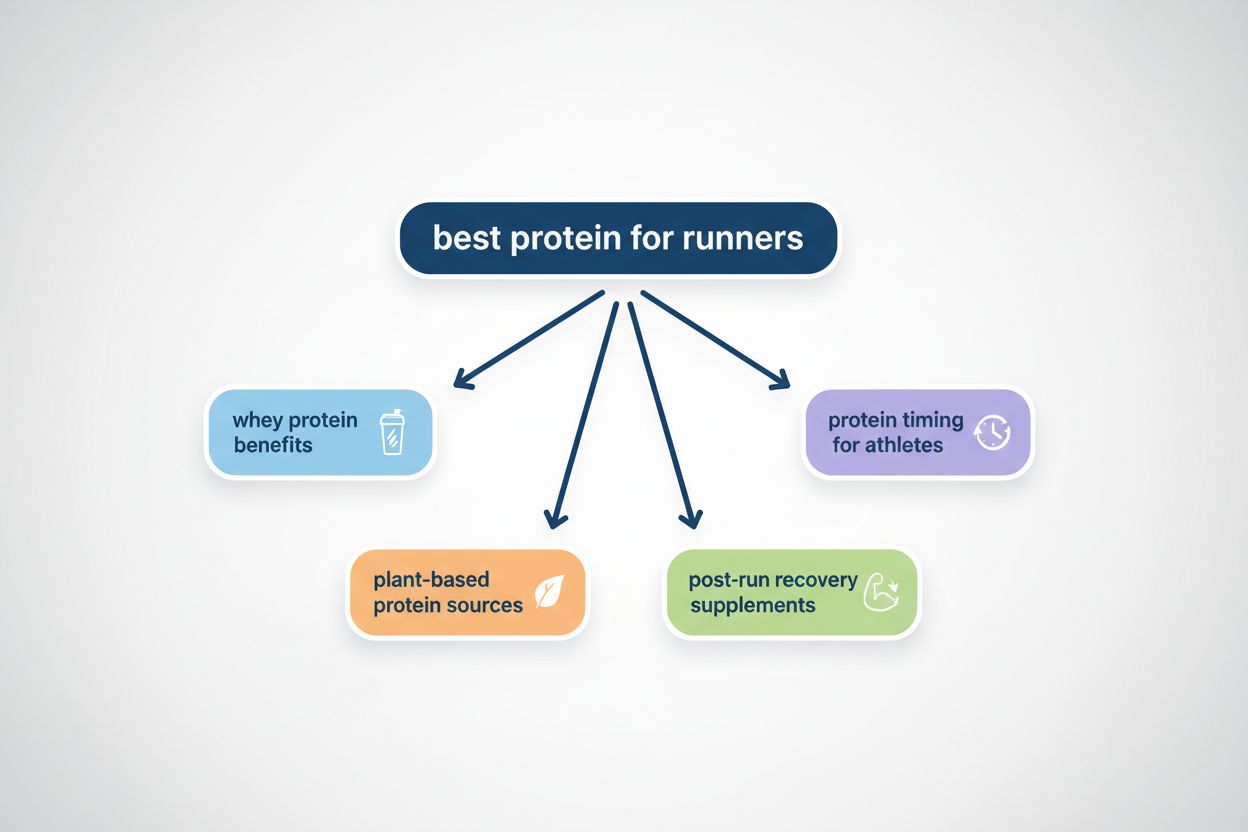
Query Fanout er processen, hvor AI-systemer automatisk udvider en enkelt brugerforespørgsel til flere relaterede underforespørgsler for at indsamle omfattende information fra forskellige vinkler. I stedet for blot at matche nøgleord som traditionelle søgemaskiner muliggør query fanout, at AI forstår den egentlige hensigt bag et spørgsmål ved at udforske forskellige fortolkninger og relaterede emner. For eksempel, når en bruger søger efter “bedste protein til løbere”, kan et AI-system med query fanout automatisk generere underforespørgsler som “fordele ved valleprotein”, “plantebaserede proteinkilder” og “kosttilskud til restitution efter løb”. Denne teknik er grundlæggende for hvordan moderne AI-søgesystemer som Google AI Mode, ChatGPT, Perplexity og Gemini leverer mere præcise og kontekstuelt relevante svar. Ved at opdele komplekse forespørgsler i enklere, mere fokuserede under-spørgsmål kan AI-systemer hente mere målrettet information og syntetisere det til omfattende svar, der adresserer flere dimensioner af det, brugerne faktisk søger.
Den tekniske mekanisme bag query fanout følger en systematisk femtrinsproces, der omdanner en enkelt forespørgsel til brugbar intelligens. Først fortolker AI-systemet den oprindelige forespørgsel for at identificere dens kernehensigt og eventuelle uklarheder. Derefter genererer det flere underforespørgsler baseret på afledte temaer, emner og relaterede koncepter, der kan hjælpe med at besvare det oprindelige spørgsmål mere fuldstændigt. Disse underforespørgsler udføres så parallelt på søgeinfrastrukturen, hvor Googles tilgang bruger sin egen version af Gemini til at opdele spørgsmål i forskellige underemner og sende flere forespørgsler ud samtidig på brugerens vegne. Systemet klynger og grupperer derefter de indhentede resultater efter emne, entitetstype og hensigt, og lagrer citater tilsvarende, så forskellige aspekter af svaret er korrekt kildeangivet. Til sidst syntetiserer AI al denne information til et samlet, sammenhængende svar, der adresserer den oprindelige forespørgsel fra flere vinkler. I praksis kan Googles AI Mode udføre otte eller flere baggrundssøgninger for en moderat kompleks forespørgsel, mens den mere avancerede Deep Search-funktion kan udsende dusinvis eller endda hundredvis af forespørgsler over flere minutter for at levere særligt grundig research på komplekse emner som købsbeslutninger.
| Trin | Beskrivelse | Eksempel |
|---|---|---|
| 1. Fortolkning | AI analyserer oprindelig forespørgsel for hensigt | “bedste CRM til små virksomheder” |
| 2. Underforespørgselsgenerering | Systemet laver relaterede variationer | “gratis CRM-værktøjer”, “CRM med e-mailautomatisering” |
| 3. Parallel udførelse | Flere søgninger udføres samtidig | Alle underforespørgsler søges på én gang |
| 4. Resultatklyngning | Resultater grupperes efter emne/entitet | Gruppe 1: Gratis værktøjer, Gruppe 2: Betalte løsninger |
| 5. Syntese | AI sammenfatter resultater til et sammenhængende svar | Én samlet svar med kildeangivelser |
AI-systemer anvender query fanout af flere strategiske grunde, der grundlæggende forbedrer svarenes kvalitet og pålidelighed:
Afklaring af tvetydighed - En enkelt forespørgsel som “Jaguar hastighed” kan henvise til enten bilproducentens ydeevne eller dyrets jagthastighed, og query fanout hjælper systemet med at teste flere fortolkninger for at identificere den mest sandsynlige brugerhensigt.
Faktuel forankring og reduktion af hallucinationer - Ved at indsamle beviser fra flere uafhængige kilder for hver gren af forespørgslen kan AI krydstjekke udsagn og verificere information, hvilket betydeligt mindsker risikoen for selvsikre men forkerte svar.
Perspektivdiversitet - Query fanout indsamler information på tværs af forskellige indholdstyper—kliniske studier, køberguides, forumdiskussioner og brandwebsites—og sikrer, at svar balancerer autoritet og praktisk anvendelighed.
Håndtering af komplekse forespørgsler - Teknikken udmærker sig ved at håndtere komplekse, lagdelte forespørgsler, der kræver syntese af information fra flere domæner.
Generering af nye svar - Query fanout gør det muligt for AI-systemer at besvare spørgsmål, som ikke tidligere er blevet klart besvaret online, ved at kombinere flere informationsstykker og drage nye konklusioner, som ingen enkelt kilde eksplicit dækker.
Forskellen på query fanout og traditionel søgning repræsenterer et grundlæggende skifte i, hvordan informationssøgning fungerer. Traditionelle søgemaskiner arbejder primært med nøgleords-matchning og returnerer en rangeret liste over resultater baseret på, hvor godt enkelte sider matcher de præcise termer i en forespørgsel—brugere skal selv forfine deres søgninger, hvis de oprindelige resultater ikke er tilfredsstillende. Query fanout fokuserer i stedet på forståelse af hensigt frem for nøgleords-matchning, hvor systemet automatisk udforsker flere vinkler og fortolkninger uden at kræve brugerindgriben. I traditionel søgning må brugerne ofte foretage flere opfølgende søgninger for at få det fulde billede—søge efter “bedste CRM software”, så “gratis CRM-værktøjer”, så “CRM med e-mailautomatisering”—mens query fanout automatiserer denne udforskning i én interaktion. Dette skifte har dybtgående konsekvenser for indholdsskabere og marketingfolk, der ikke længere kun kan nøjes med optimering af enkelte nøgleord, men i stedet skal sikre, at indholdet dækker hele klyngen af relaterede emner og hensigter, som AI-systemerne vil undersøge. Skiftet ændrer også grundlæggende SEO-strategien, så fokus flyttes fra rangering på specifikke søgeord til synlighed på tværs af flere relaterede forespørgsler og opbygning af emnemæssig autoritet, der positionerer indholdet som relevant for bredere emneklynger.
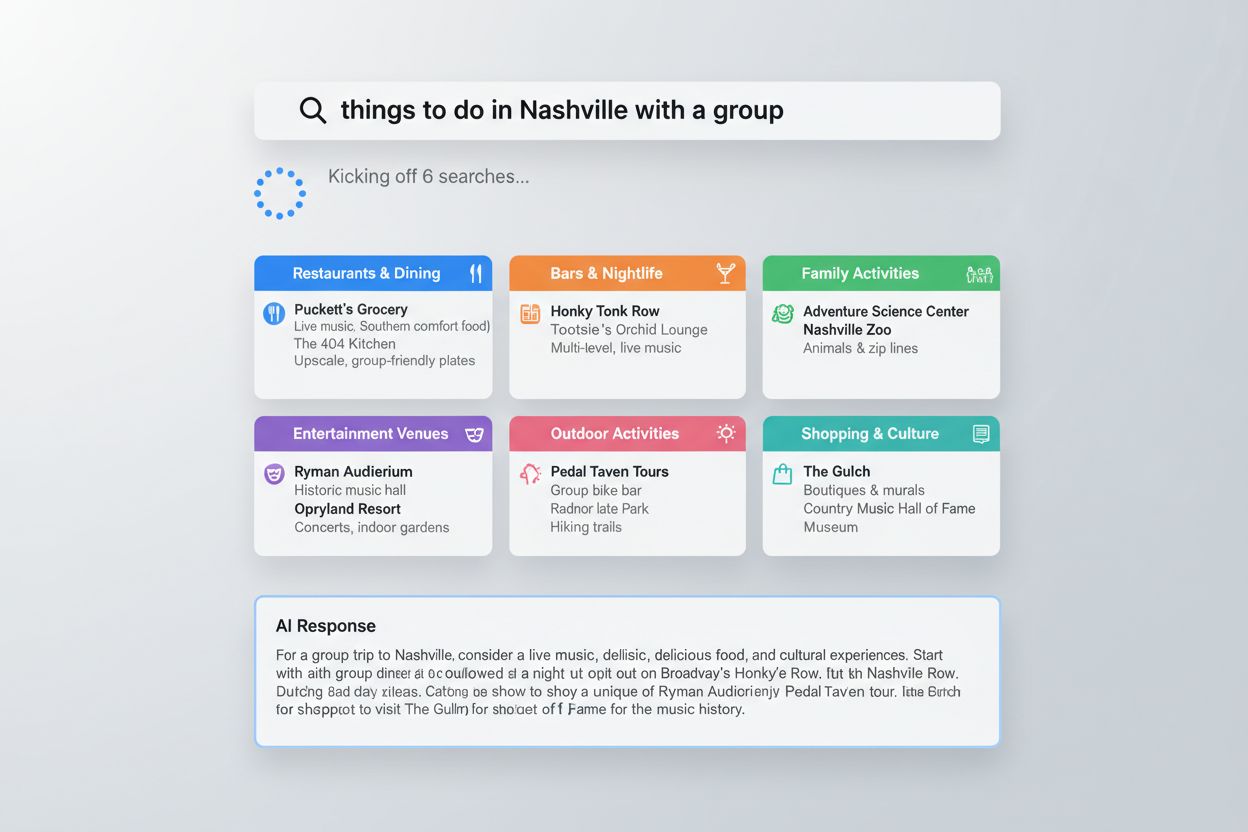
Query fanout manifesterer sig på praktiske, observerbare måder på tværs af store AI-platforme. Når en bruger spørger Google AI Mode “ting at lave i Nashville med en gruppe”, udvider systemet automatisk forespørgslen til underforespørgsler om gode restauranter, barer, familievenlige aktiviteter og underholdningssteder, og syntetiserer derefter resultaterne til en omfattende guide skræddersyet til gruppeaktiviteter. ChatGPT udviser lignende adfærd, når den håndterer “bedste X”-forespørgsler, hvor der i et enkelt svar adresseres flere vinkler såsom “bedst til budget”, “bedst for funktioner” og “bedst til specifikke anvendelser”. Deep Search-funktionaliteten demonstrerer teknikkens styrke ved komplekse beslutninger—når man undersøger pengeskabe til hjemmet, kan systemet bruge flere minutter på at udføre dusinvis af forespørgsler om brandmodstand, forsikringsforhold, specifikke produktmodeller og brugeranmeldelser, og leverer i sidste ende et utroligt grundigt svar med links til specifikke produkter og detaljerede sammenligninger. Ud over disse eksempler driver query fanout købsanbefalinger, restaurantforslag og aktiesammenligninger, hvor forskellige AI-platforme implementerer teknikken via integration med interne værktøjer som Google Finance og Shopping Graph, som opdateres 2 milliarder gange i timen for at sikre realtidsnøjagtighed. Denne evne til realtidsdata-integration betyder, at query fanout ikke er begrænset til statisk information, men kan inkorporere aktuelle priser, tilgængelighed, markedsdata og anden dynamisk information, der konstant ændrer sig.
Query fanout ændrer grundlæggende måden, brands opnår synlighed i AI-genererede svar på, og skaber både muligheder og udfordringer for organisationer, der ønsker at påvirke, hvordan de præsenteres i AI-svar. Fordi query fanout får AI-systemer til at udforske flere underforespørgsler, skal brands nu fremgå i resultaterne på tværs af flere relaterede søgninger—ikke kun den primære forespørgsel—hvilket betyder, at en virksomhed, der kun er optimeret til “CRM software”, kan miste muligheder for at vises i resultater for “gratis CRM-værktøjer” eller “CRM med e-mailautomatisering”. Vigtigheden af at blive fremhævet positivt i AI-svar er steget markant, da disse svar direkte påvirker forbrugerbeslutninger og ofte reducerer behovet for at konsultere andre informationskilder. Det er afgørende at forstå forskellen mellem AI-omtaler (ulinkede referencer til dit brand i AI-svar) og AI-citater (linkede referencer til dit indhold), da citater giver både synlighed og troværdighed, mens omtaler øger bevidstheden uden direkte trafik. Her bliver overvågningsværktøjer som AmICited.com essentielle—de sporer, hvordan dit brand fremgår på tværs af flere AI-platforme (Google AI Mode, ChatGPT, Perplexity, Gemini og andre), og viser ikke kun, om du nævnes, men hvor du fremgår i svarhierarkiet, hvor ofte du bliver citeret, og hvilken stemning der omgiver dine brandomtaler. Organisationer, der forstår query fanout og aktivt optimerer til det, opnår betydelige konkurrencefordele i AI-synlighed, da de har større sandsynlighed for at fremgå i de mange underforespørgselsresultater, der samlet afgør den samlede kvalitet af AI-svaret.
Optimering til query fanout kræver en grundlæggende anderledes tilgang end traditionel nøgleordsfokuseret SEO. Første skridt er at identificere kerneemner direkte relateret til din virksomhed og ekspertise, da disse områder er der, hvor du mest troværdigt og autoritativt kan adressere de mange vinkler, query fanout udforsker. Dernæst bør du oprette emneklynger bestående af en central søjleside, der giver et bredt overblik over et kerneemne, omgivet af klyngesider, der adresserer specifikke underemner—denne struktur hjælper AI-systemer med at genkende dit indhold som en omfattende ressource på tværs af flere relaterede forespørgsler. Planlæg omfattende indhold, der dækker ikke kun hovedemnet men også alle underemner, sammenligninger og spørgsmål, AI-systemer kan udforske, når de udvider en forespørgsel, så hver side fungerer som et knudepunkt, der tilfredsstiller flere hensigter samtidigt. Skriv til NLP (naturlig sprogforståelse) ved at bruge klare definitioner, hele sætninger og selvstændige sektioner, som AI-systemer let kan fortolke og udtrække information fra, i stedet for at fokusere på nøgleordsdensitet eller andre traditionelle SEO-taktikker. Implementer schema markup for at tilføje maskinlæsbare etiketter til forskellige datatyper på dine sider, så AI-systemer kan tolke dit indhold mere præcist—for eksempel ved at bruge Product schema til produktnavne og billeder eller Offer schema til pris- og tilgængelighedsoplysninger. Fokusér på semantisk fuldstændighed ved at sikre, at dit indhold tydeligt refererer til relaterede entiteter, koncepter og relationer, der fremgår på tværs af fanout-grenene, og opbyg en stærk intern linkstruktur med kontekstuelle ankertekster for at signalere emnedybde og hjælpe AI-systemer med at forstå, hvordan dine indholdsstykker relaterer til hinanden.
Måden, du strukturerer og formaterer indhold på, påvirker direkte, hvor effektivt AI-systemer kan udtrække og anvende information til query fanout-svar. Skriv i blokke—selvstændige, meningsfulde sektioner, der kan stå alene og let behandles, hentes og opsummeres af AI-systemer—brug hele sætninger og gentag kontekst, hvor det er nyttigt, i stedet for at stole på fragmenterede punktlister eller nøgleordstung tekst. Giv klare definitioner, når du introducerer nye begreber, da AI-systemer ofte leder efter definitioner under query fanout-processen og vil prioritere sider, der eksplicit definerer termer. Brug beskrivende underoverskrifter til at opdele indhold i logiske sektioner og anvend korrekt overskriftshierarki (H2, H3, H4) for at vise relationer mellem emner, hvilket hjælper AI-systemer med at finde indhold relateret til meget specifikke forespørgsler. Strukturer indhold med tabeller og lister for at skabe letlæselig information, AI-systemer kan udtrække og omorganisere, og brug klart, samtalebetonet sprog, der undgår jargon, for komplekse sætningsstrukturer og unødvendigt fyld. Stripes hjemmeside er et forbillede for disse best practices, med løsningssider tilpasset forskellige forretningsstadier og anvendelser, underafsnit med direkte og detaljeret information om relevante underemner og omfattende dækning på tværs af blogindlæg, kundehistorier, supportdokumentation og andre ressourcer. Denne multiformats, dybt strukturerede tilgang hjælper AI-systemer med at genkende Stripes relevans for forskellige hensigter og udtrække nyttig information til udvidede forespørgsler, hvilket bidrager til deres fremragende AI-synlighed på platforme som Google AI Mode, SearchGPT, ChatGPT, Perplexity og Gemini.
Måling af succes med query fanout-optimering kræver specialiserede værktøjer og metrikker, der rækker ud over traditionel SEO-analyse. Værktøjer som Semrush’s AI Visibility Toolkit og AmICited giver indsigt i dit brands præstation på tværs af flere AI-platforme og viser din share of voice for ikke-brandede forespørgsler på Google AI Mode, SearchGPT, ChatGPT, Perplexity, Gemini og andre systemer. Disse platforme viser ikke bare, om dit brand nævnes, men hvor det fremgår i svarhierarkiet—om du er citeret først, næst eller længere nede—hvilket har direkte indflydelse på synlighed og indflydelse. Sporing af omtaler versus citater separat er afgørende, da citater både giver synlighed og trafik, mens omtaler øger bevidstheden; forståelsen af denne forskel hjælper dig med at prioritere optimeringsindsatsen. Sentimentanalyse i AI-svar viser, hvordan dit brand præsenteres—om AI-systemer fremhæver dine styrker eller svagheder—så du kan identificere forbedringsområder i den måde, du omtales på. Konkurrentbenchmarking afslører huller i din AI-synlighedsstrategi og muligheder for at overgå konkurrenterne i bestemte forespørgselsklynger. Vigtigheden af kontinuerlig overvågning kan ikke overvurderes, da AI-systemer udvikler sig hurtigt, nye platforme opstår, og forespørgselsmønstre ændrer sig; løbende opfølgning sikrer, at du kan tilpasse din strategi og bevare synligheden i takt med at landskabet ændrer sig.
Udviklingen for query fanout peger mod stadig mere sofistikeret forståelse af forespørgsler og mere komplekse AI-reasoning-processer. Efterhånden som AI-systemer udvikler sig, vil de sandsynligvis udvikle endnu mere nuancerede evner til at opdele forespørgsler i under-spørgsmål, forstå implicit kontekst og syntetisere information på tværs af stadig mere forskelligartede kilder. Grænserne mellem traditionel og AI-søgning vil fortsætte med at udviskes, da traditionelle søgemaskiner inkorporerer mere AI-drevet forståelse af forespørgsler, mens AI-systemer i stigende grad integrerer realtidssøgefunktioner, hvilket skaber et hybridlandskab, hvor optimeringsstrategier skal omfatte begge paradigmer. Denne udvikling nødvendiggør et grundlæggende skift i, hvordan organisationer griber søgeoptimering an, væk fra nøgleordsrangering mod kontekstuel synlighed og sikring af, at indholdet vises på tværs af hele spektret af relaterede forespørgsler, AI-systemer undersøger. Emnemæssig autoritet—at etablere dyb, omfattende ekspertise inden for relaterede emner—bliver stadig vigtigere, da AI-systemer belønner indhold, der demonstrerer mestring af hele emneklynger frem for enkelte nøgleord. Emerging best practices for query fanout-optimering lægger vægt på semantisk fuldstændighed, entitetsrelationer, indholdsstruktur og tværplatforms synlighedsmonitorering, hvilket kræver, at organisationer tænker holistisk over, hvordan deres indholdsøkosystem adresserer de mange vinkler og fortolkninger, AI-systemer vil udforske, når de besvarer brugerens spørgsmål.
Query Fanout er den automatiske proces, hvor AI-systemer opdeler en enkelt forespørgsel i flere underforespørgsler for at forstå den egentlige hensigt og indsamle omfattende information. Query Expansion er derimod en teknik til at tilføje relaterede termer for at forbedre søgning, hvilket kan være enten manuelt eller automatisk. Query Fanout er mere sofistikeret og hensigtsfokuseret, mens query expansion primært fokuserer på nøgleord.
Antallet varierer afhængigt af forespørgslens kompleksitet. Enkle forespørgsler kan generere 1-3 underforespørgsler, mens moderat komplekse forespørgsler typisk producerer 5-8 underforespørgsler. Avancerede funktioner som Googles Deep Search kan udføre dusinvis eller endda hundredvis af baggrundsforespørgsler over flere minutter for særligt grundig research på komplekse emner.
Ja, indirekte. Indhold optimeret til Query Fanout har tendens til også at klare sig bedre i traditionel søgning, fordi optimeringsprocessen kræver omfattende emnedækning, klar struktur og semantisk fuldstændighed—alle faktorer, som søgemaskiner belønner. Den primære fordel er dog forbedret synlighed i AI-genererede svar frem for traditionelle søgeresultater.
De største AI-platforme, der implementerer Query Fanout, inkluderer Google AI Mode, ChatGPT, Perplexity, Gemini og andre LLM-baserede søgesystemer. Hver platform implementerer teknikken en smule forskelligt, men alle bruger en form for forespørgselsopdeling for at forbedre svarenes kvalitet og relevans.
Opret emneklynger med søjle- og klynge-sider, skriv omfattende indhold der dækker underemner og relaterede spørgsmål, implementer schema markup for strukturerede data, brug klare overskrifter og formatering, byg stærk intern linkstruktur og fokusér på semantisk fuldstændighed. Skriv til naturlig sprogforståelse ved at bruge klare definitioner og selvstændige sektioner, som AI-systemer let kan fortolke.
Query Fanout øger mulighederne for AI-citater ved at sikre, at dit indhold vises i resultaterne for flere relaterede underforespørgsler. Når AI-systemer undersøger forskellige vinkler af et spørgsmål, er de mere tilbøjelige til at opdage og citere dit indhold, hvis det omfattende adresserer de forskellige perspektiver.
Query Fanout forbedrer brugeroplevelsen markant ved at gøre det muligt for AI-systemer at levere mere præcise og omfattende svar uden at brugeren skal omformulere sine forespørgsler flere gange. Brugere får bedre målrettede svar, der adresserer flere dimensioner af deres spørgsmål i én interaktion.
Ja, Query Fanout hjælper med at reducere hallucinationer ved at krydstjekke information på tværs af flere kilder. Når AI-systemer henter beviser fra forskellige kilder for hver gren af en udvidet forespørgsel, kan de verificere udsagn og identificere afvigelser, hvilket betydeligt mindsker risikoen for selvsikre men forkerte svar.
Følg med i, hvordan dit indhold vises på tværs af AI-platforme, når forespørgsler udvides. Forstå din AI-synlighed og citater med AmICiteds omfattende overvågningsplatform.
Opdag hvordan moderne AI-systemer som Google AI Mode og ChatGPT opdeler enkeltforespørgsler i flere søgninger. Lær om query fanout-mekanismer, konsekvenser for ...

Lær de essentielle første skridt til at optimere dit indhold til AI-søgemaskiner som ChatGPT, Perplexity og Google AI Overviews. Opdag hvordan du strukturerer i...
Lær hvordan du opretter TOFU-indhold optimeret til AI-søgning. Mestre strategier for bevidsthedsstadiet til ChatGPT, Perplexity, Google AI Overviews og Claude....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.