
Forespørgselsforfining
Forespørgselsforfining er den iterative proces med at optimere søgeforespørgsler for bedre resultater i AI-søgemaskiner. Lær hvordan det fungerer på tværs af Ch...
13 min læsning
Forespørgselsreformulering er processen, hvor AI-systemer fortolker, omstrukturerer og forbedrer brugerforespørgsler for at øge nøjagtigheden og relevansen af informationssøgning. Det omdanner simple eller tvetydige brugerinput til mere detaljerede, kontekstrige versioner, der stemmer overens med AI-systemets forståelse og muliggør mere præcise og dækkende svar.
Forespørgselsreformulering er processen, hvor AI-systemer fortolker, omstrukturerer og forbedrer brugerforespørgsler for at øge nøjagtigheden og relevansen af informationssøgning. Det omdanner simple eller tvetydige brugerinput til mere detaljerede, kontekstrige versioner, der stemmer overens med AI-systemets forståelse og muliggør mere præcise og dækkende svar.
Forespørgselsreformulering er processen med at omdanne, udvide eller omskrive en brugers oprindelige søgeforespørgsel, så den bedre tilpasses informationssøgningssystemets egenskaber og brugerens egentlige intention. I sammenhæng med kunstig intelligens og naturlig sprogbehandling (NLP) bygger forespørgselsreformulering bro over det kritiske hul mellem, hvordan brugere naturligt udtrykker deres informationsbehov, og hvordan AI-systemer fortolker og behandler disse anmodninger. Denne teknik er essentiel i moderne AI-systemer, da brugere ofte formulerer forespørgsler upræcist, bruger domænespecifik terminologi inkonsekvent eller undlader at inkludere kontekst, der kunne forbedre nøjagtigheden af søgningen. Forespørgselsreformulering opererer i krydsfeltet mellem informationssøgning, semantisk forståelse og maskinlæring og gør det muligt for systemer at generere mere relevante resultater ved at genfortolke forespørgsler gennem flere linser—uanset om det er via synonymer, kontekstuel berigelse eller strukturel omorganisering. Ved intelligent reformulering af forespørgsler kan AI-systemer markant forbedre svarenes kvalitet, reducere tvetydighed og sikre, at hentet information stemmer bedre overens med brugerens hensigt.
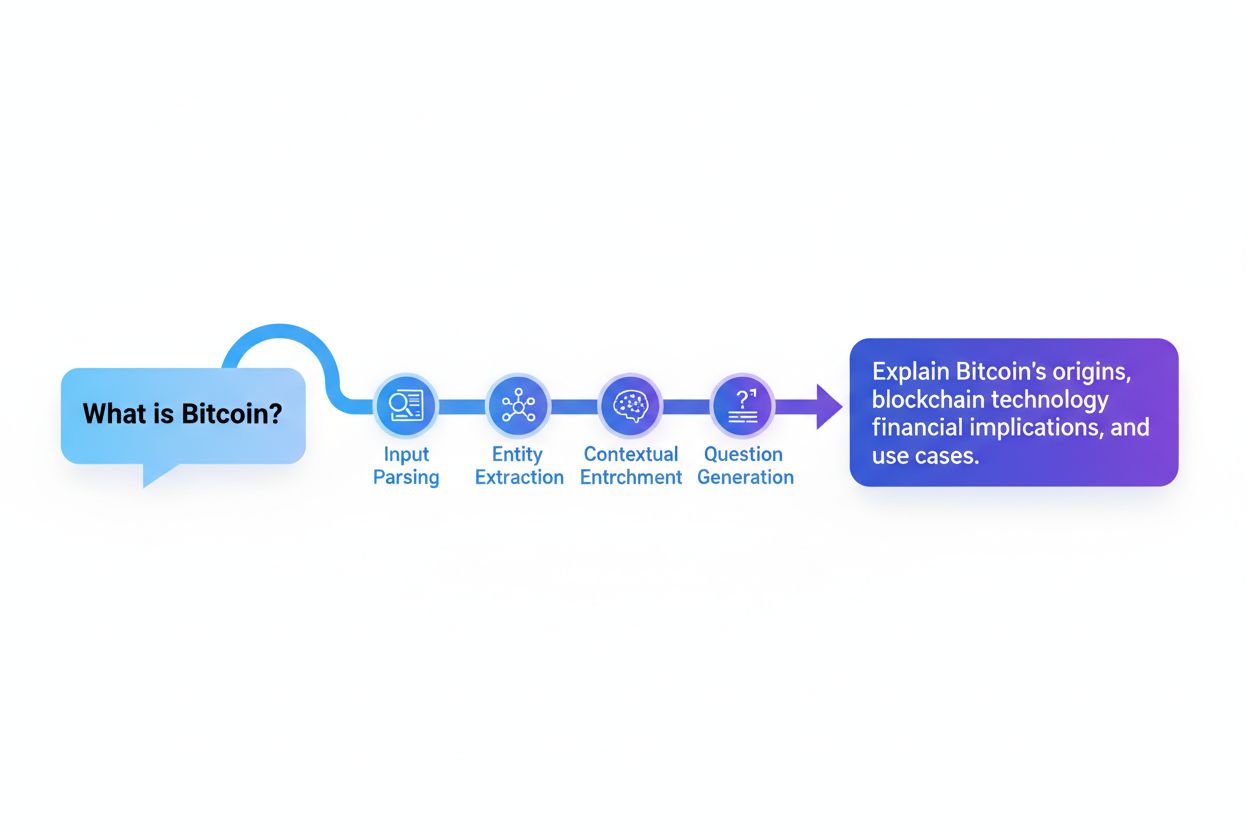
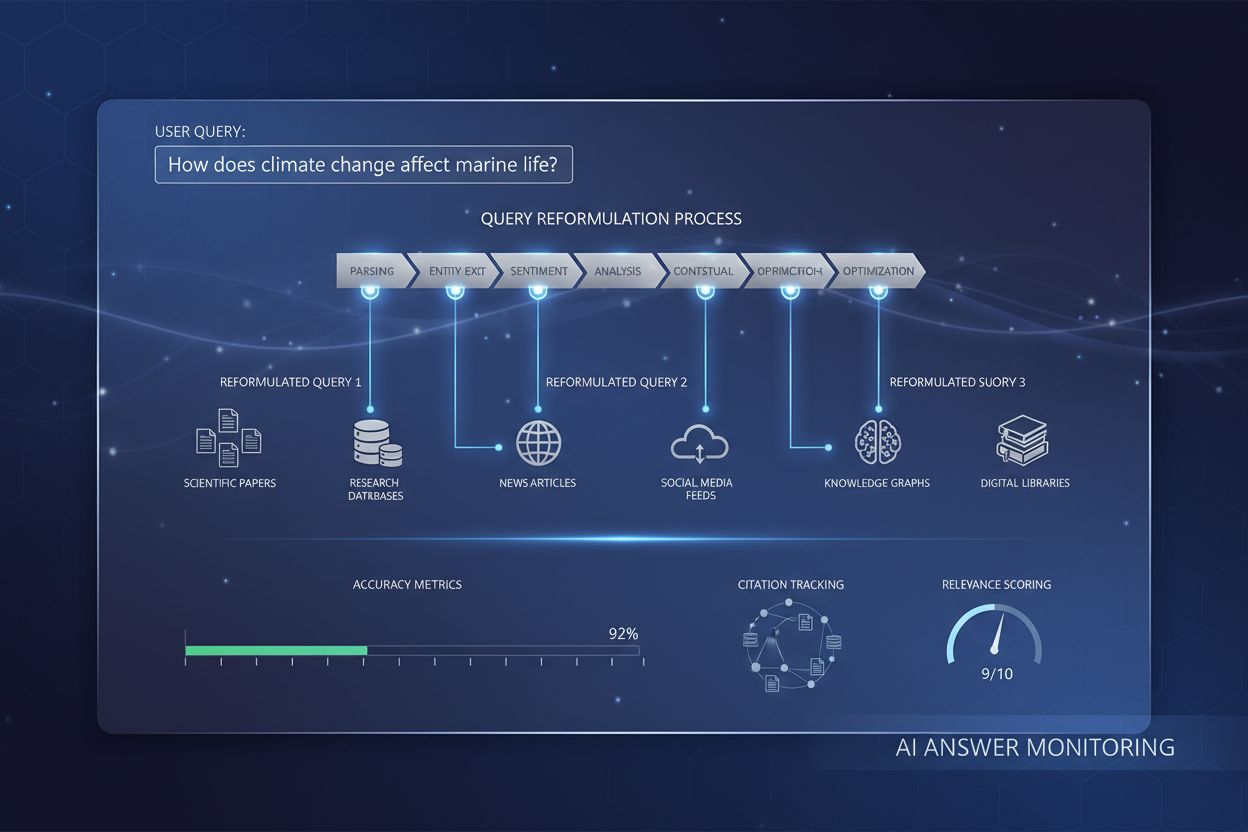
Forespørgselsreformuleringssystemer arbejder typisk gennem fem indbyrdes forbundne komponenter, der sammen omdanner råt brugerinput til optimerede søgeforespørgsler. Input-parsing opdeler den oprindelige forespørgsel i dens bestanddele og identificerer nøgleord, sætninger og strukturelle elementer. Entitetsudtræk identificerer navngivne enheder (personer, steder, organisationer, produkter) og domænespecifikke begreber med semantisk vægt. Sentimentanalyse bevarer den følelsesmæssige tone eller vurderende holdning i den oprindelige forespørgsel, så reformulerede versioner fastholder brugerens oprindelige perspektiv. Kontekstuel analyse inddrager sessionshistorik, brugerprofildata og domæneviden for at berige forespørgslen med implicit betydning. Spørgsmålsgenerering omdanner deklarative udsagn eller fragmenter til velstrukturerede spørgsmål, som søgesystemer bedre kan behandle.
| Komponent | Formål | Eksempel |
|---|---|---|
| Input-parsing | Deler og segmenterer forespørgslen i meningsfulde enheder | “bedste Python-biblioteker” → [“bedste”, “Python”, “biblioteker”] |
| Entitetsudtræk | Identificerer navngivne enheder og domænebegreber | “Apples nyeste iPhone” → Enhed: Apple (firma), iPhone (produkt) |
| Sentimentanalyse | Bevarer vurderende tone og brugerperspektiv | “forfærdelig kundeservice” → Bevarer negativt sentiment i reformuleringen |
| Kontekstuel analyse | Inddrager sessionshistorik og domæneviden | Tidligere forespørgsel om “maskinlæring” informerer nuværende “neurale netværk”-forespørgsel |
| Spørgsmålsgenerering | Omdanner fragmenter til strukturerede spørgsmål | “Python debugging” → “Hvordan debugger jeg Python-kode?” |
Forespørgselsreformulering følger en systematisk seks-trins metode, der gradvist forbedrer forespørgslens kvalitet og relevans:
Input-parsing og normalisering
Entitets- og begrebsudtræk
Bevarelse af sentiment og intention
Kontekstuel berigelse
Forespørgselsekspansion og synonymgenerering
Optimering og evaluering
Forespørgselsreformulering anvender en bred vifte af teknikker fra traditionelle leksikale metoder til avancerede neurale metoder. Synonymbaseret ekspansion udnytter etablerede ressourcer som WordNet, ordbogsindlejringer som Word2Vec og GloVe samt kontekstuelle modeller som BERT til at identificere semantisk lignende termer. Forespørgselsafslapning løsner gradvist forespørgselskrav for at øge recall, hvis de oprindelige resultater er utilstrækkelige—for eksempel ved at fjerne sjældne termer eller udvide datointervaller. Brugerfeedback og sessionskontekst giver systemerne mulighed for at lære af brugerinteraktioner og forfine reformuleringer baseret på, hvilke resultater brugerne faktisk finder relevante. Transformerbaserede omformuleringer som T5 (Text-to-Text Transfer Transformer) og GPT-modeller genererer helt nye forespørgselsformuleringer ved at lære mønstre fra store træningssæt af forespørgselspar. Hybride tilgange kombinerer flere teknikker—f.eks. ved at bruge regelbaseret synonymekspansion for højtsikre termer og neurale modeller for tvetydige fraser. Virkelige implementeringer bruger ofte ensemblemetoder, der genererer flere reformuleringer og rangerer dem via lærte relevansmodeller. For eksempel kan e-handelsplatforme kombinere domænespecifikke synonymordbøger med BERT-indlejringer for både at håndtere standardiseret produktterminologi og brugernes dagligsprog, mens medicinske søgesystemer bruger specialiserede ontologier sammen med transformer-modeller for at sikre klinisk nøjagtighed.
Forespørgselsreformulering giver markante forbedringer på tværs af flere dimensioner af AI-systemers ydeevne og brugeroplevelse:
Forbedret søgenøjagtighed: Reformulerede forespørgsler fanger brugerens intention mere præcist, hvilket resulterer i bedre hentede dokumenter og mere relevante AI-genererede svar. Ved at udvide forespørgsler med synonymer og relaterede begreber finder systemerne dokumenter, der måske bruger anden terminologi end den oprindelige forespørgsel, hvilket dramatisk øger sandsynligheden for at finde virkelig relevant information.
Øget recall og dækning: Forespørgselsekspansion øger antallet af relevante dokumenter ved at udforske semantiske variationer og relaterede begreber. Dette er især værdifuldt i specialiserede domæner, hvor terminologien varierer betydeligt, så brugerne ikke går glip af relevant information pga. ordvalg.
Reduceret tvetydighed og afklaring: Reformuleringsprocesser fjerner tvetydighed i uklare forespørgsler ved at inddrage kontekst og generere flere fortolkninger. Det gør det muligt for systemer at håndtere forespørgsler som “apple” (frugt vs. firma) ved at skabe kontekstsensitive reformuleringer, der henter relevante resultater.
Bedre brugeroplevelse og tilfredshed: Brugerne får hurtigere mere relevante resultater, hvilket mindsker behovet for gentagne søgninger. Færre fejlsøgninger og mere præcise førstegangshits fører direkte til højere bruger-tilfredshed og mindre kognitiv belastning.
Skalerbarhed og effektivitet: Reformulering gør systemer i stand til at håndtere forskellige brugergrupper med varierende ordforråd, ekspertiseniveau og sproglig baggrund. Én reformuleringsmotor kan betjene brugere på tværs af domæner og sprog, hvilket øger systemets skalerbarhed uden tilsvarende infrastrukturforøgelse.
Løbende forbedring og læring: Reformuleringssystemer kan trænes på brugerinteraktioner og hele tiden forbedre deres strategier baseret på, hvilke reformuleringer der fører til succes. Dette skaber en positiv spiral, hvor præstationen forbedres over tid, efterhånden som mere brugerdata akkumuleres.
Domænetilpasning og specialisering: Reformuleringsteknikker kan finjusteres til specifikke domæner (medicin, jura, teknik) ved træning på domænespecifikke forespørgselspar og inddragelse af domæneontologier. Dette gør det muligt for specialiserede systemer at håndtere domæneterminologi med større præcision end generiske metoder.
Robusthed over for forespørgselsvariationer: Systemerne bliver robuste over for stavefejl, grammatiske fejl og dagligdags sprogbrug ved at reformulere forespørgsler til standardiserede former. Denne robusthed er særlig værdifuld for stemmebaserede grænseflader og mobilsøgning, hvor inputkvaliteten varierer meget.
Forespørgselsreformulering spiller en afgørende rolle for nøjagtigheden og pålideligheden af AI-genererede svar og er derfor essentiel for AI-svar-overvågningsplatforme som AmICited.com. Når AI-systemer reformulerer forespørgsler, før de genererer svar, har kvaliteten af disse reformuleringer direkte indflydelse på, om AI’en henter passende kildemateriale og genererer nøjagtige, veldokumenterede svar. Dårligt reformulerede forespørgsler kan få AI-systemer til at hente irrelevante dokumenter, hvilket fører til svar uden korrekt forankring eller upassende kildeangivelser. I AI-overvågning og citatsporing er forståelsen af, hvordan forespørgsler reformuleres, afgørende for at verificere, at AI-systemer faktisk besvarer brugerens tiltænkte spørgsmål og ikke en forvredet fortolkning. AmICited.com sporer, hvordan AI-systemer reformulerer forespørgsler for at sikre, at de kilder, der citeres i AI-genererede svar, reelt er relevante for det oprindelige brugerspørgsmål og ikke kun for en misfortolket reformulering. Denne overvågningskapacitet er særlig vigtig, fordi forespørgselsreformulering sker usynligt for slutbrugeren—de ser kun det endelige svar og citater uden at vide, hvordan den underliggende forespørgsel er blevet transformeret. Ved at analysere reformuleringsmønstre kan AI-overvågningsplatforme identificere, når AI-systemer genererer svar baseret på reformuleringer, der afviger væsentligt fra brugerens hensigt, og derved markere potentielle nøjagtighedsproblemer, før de når brugeren. Derudover hjælper forståelsen af reformulering platformene med at vurdere, om AI-systemer håndterer tvetydige forespørgsler korrekt ved at generere flere reformuleringer og sammenfatte information på tværs af dem, eller om de antager noget om brugerens hensigt uden grund.
Forespørgselsreformulering er blevet uundværlig på tværs af mange AI-drevne applikationer og brancher. Inden for sundhedspleje og medicinsk forskning håndterer forespørgselsreformulering kompleksiteten i medicinsk terminologi, hvor patienter kan søge efter “hjerteanfald”, mens den kliniske litteratur bruger “myokardieinfarkt”—reformulering bygger bro over dette ordvalg og sikrer klinisk præcis information. Analyse af juridiske dokumenter bruger reformulering til at håndtere det præcise, arkaiske sprog i juridiske tekster, samtidig med at moderne søgetermer imødekommes, så advokater kan finde relevante præcedenser, uanset hvordan de formulerer deres forespørgsler. Teknisk supportsystemer reformulerer brugerforespørgsler, så de matcher vidensbaseartikler, og omdanner dagligdags beskrivelser af problemer (“min computer er langsom”) til tekniske termer (“systempræstationsforringelse”) for at finde passende vejledninger. E-handelssøgeoptimering anvender reformulering til at håndtere produktsøgninger, hvor brugere måske søger efter “løbesko”, mens kataloget bruger “sportssko” eller specifikke mærkenavne, så kunderne finder de ønskede produkter trods terminologiforskelle. Samtale-AI og chatbots bruger reformulering til at fastholde kontekst i flersidede samtaler og reformulerer opfølgende spørgsmål, så implicit kontekst fra tidligere udvekslinger inkluderes. Retrieval-Augmented Generation (RAG)-systemer er stærkt afhængige af reformulering for at sikre, at de hentede kontekstdokumenter faktisk er relevante for brugerens spørgsmål og dermed direkte forbedrer kvaliteten af de genererede svar. For eksempel kan et RAG-system, der besvarer “Hvordan optimerer jeg databaseforespørgsler?” reformulere dette til flere varianter som “databaseforespørgsels performance tuning,” “SQL-optimeringsteknikker” og “forespørgselseksekveringsplaner” for at hente omfattende kontekst, før der genereres et detaljeret svar.
På trods af fordelene byder forespørgselsreformulering på betydelige udfordringer, som praktikere må navigere omhyggeligt. Beregningsteknisk kompleksitet stiger markant, når der genereres og rangeres flere reformuleringer—hver reformulering kræver behandling, og systemerne må afveje kvalitetsgevinster mod svartidskrav, især i realtidsapplikationer. Træningsdatas kvalitet er afgørende for reformuleringens effektivitet; systemer trænet på dårlige forespørgselspar eller biasprægede datasæt vil videreføre disse problemer og i værste fald forstærke dem. Risiko for over-reformulering opstår, når systemer genererer så mange varianter, at fokus på den oprindelige intention går tabt, og resultaterne bliver for perifere. Domænespecifik tilpasning kræver betydelig indsats—modeller trænet på generelle web-forespørgsler klarer sig ofte dårligt i specialiserede domæner som medicin eller jura uden omfattende gen-træning og domænespecifik tuning. Afvejning mellem præcision og recall er en grundlæggende udfordring: Aggressiv ekspansion øger recall, men kan sænke præcisionen ved at hente irrelevante resultater, mens konservativ reformulering bevarer præcision, men overser relevante dokumenter. Potentiel biasintroduktion kan opstå, hvis reformuleringssystemer indkoder samfundsmæssige fordomme fra træningsdata, hvilket kan føre til diskrimination i søgeresultater og AI-svar—for eksempel hvis reformuleringer af “sygeplejerske”-forespørgsler uforholdsmæssigt ofte henter resultater forbundet med kvinder, hvis træningsdataene afspejler historisk kønsbias.
Forespørgselsreformulering udvikler sig hurtigt i takt med AI-fremskridt og nye metoder. Fremskridt i LLM-baseret reformulering muliggør mere sofistikerede, kontekstbevidste transformationer, da store sprogmodeller bliver bedre til at forstå nuancerede intentioner og generere naturlige, semantisk rige reformuleringer. Integration af multimodal AI udvider reformulering fra tekst til også at håndtere billeder, lyd og video, hvor visuelle søgninger reformuleres til tekstbeskrivelser, som søgesystemer kan behandle. Personalisering og læring gør det muligt for reformuleringssystemer at tilpasse sig den enkelte brugers præferencer, ordforråd og søgemønstre, så reformuleringerne bliver stadig mere personlige. Real-time adaptiv reformulering gør det muligt for systemer løbende at reformulere forespørgsler baseret på mellemliggende søgeresultater, så indledende reformuleringer informerer senere forbedringer. Vidensgraf-integration gør det muligt at anvende struktureret viden om entiteter og relationer, så reformuleringer bliver mere semantisk præcise og funderet i eksplicit viden. Fremvoksende standarder for evaluering og benchmarking af reformulering vil lette sammenligning på tværs af systemer og drive brancheforbedringer i kvalitet og konsistens.
Forespørgselsreformulering er den bredere proces med at omdanne en forespørgsel for at forbedre søgning, mens forespørgselsekspansion er en specifik teknik inden for reformulering, hvor der tilføjes synonymer og relaterede termer. Forespørgselsekspansion fokuserer på at udvide søgeområdet, mens reformulering omfatter flere teknikker, herunder parsing, entitetsudtræk, sentimentanalyse og kontekstuel berigelse for grundlæggende at forbedre forespørgslens kvalitet.
Forespørgselsreformulering hjælper AI-systemer med bedre at forstå brugerintentioner ved at afklare tvetydige termer, tilføje kontekst og generere flere fortolkninger af den oprindelige forespørgsel. Dette fører til søgning af mere relevante kildedokumenter, hvilket gør det muligt for AI at generere mere nøjagtige, veldokumenterede svar med korrekte henvisninger.
Ja, forespørgselsreformulering kan fungere som et sikkerhedslag ved at standardisere og rense brugerinput, før de når hoved-AI-systemet. En specialiseret reformuleringsagent kan opdage og neutralisere potentielt skadelige input, filtrere mistænkelige mønstre og omdanne forespørgsler til sikre, standardiserede formater, der mindsker sårbarheden over for prompt injection-angreb.
I Retrieval-Augmented Generation (RAG)-systemer er forespørgselsreformulering afgørende for at sikre, at de hentede kontekstdokumenter faktisk er relevante for brugerens spørgsmål. Ved at reformulere forespørgsler i flere varianter kan RAG-systemer hente mere omfattende og varieret kontekst, hvilket direkte forbedrer kvaliteten og nøjagtigheden af de genererede svar.
Implementeringen involverer typisk at vælge passende teknikker til din brugssag: brug synonymbaseret ekspansion med BERT eller Word2Vec for semantisk lighed, anvend transformer-modeller som T5 eller GPT til neurale reformuleringer, inddrag domænespecifikke ontologier til specialiserede felter, og implementer feedbacksløjfer for løbende at forbedre reformuleringer baseret på brugerinteraktioner og søgesucceskriterier.
De beregningsmæssige omkostninger varierer afhængigt af teknik: simpel synonymekspansion er let, mens transformerbaseret reformulering kræver betydelige GPU-ressourcer. Ved at bruge mindre specialiserede modeller til reformulering og større modeller kun til den endelige svargenerering kan omkostningerne optimeres. Mange systemer anvender caching og batchbehandling for at fordele beregningsudgifterne over flere forespørgsler.
Forespørgselsreformulering påvirker direkte nøjagtigheden af citater, da den reformulerede forespørgsel afgør, hvilke dokumenter der hentes og citeres. Hvis reformuleringen afviger væsentligt fra den oprindelige brugerintention, kan AI'en citere kilder, der er relevante for den reformulerede forespørgsel frem for det oprindelige spørgsmål. AI-overvågningsplatforme som AmICited sporer disse transformationer for at sikre, at citater faktisk er relevante i forhold til det, brugerne faktisk har spurgt om.
Ja, forespørgselsreformulering kan forstærke eksisterende bias, hvis træningsdataene afspejler samfundsmæssige fordomme. For eksempel kan reformulering af visse forespørgsler uforholdsmæssigt ofte hente resultater, der er forbundet med bestemte demografiske grupper. For at imødegå dette kræves omhyggelig datasætudvælgelse, mekanismer til biasdetektion, varierede træningseksempler og løbende overvågning af reformuleringsoutput for retfærdighed og repræsentativitet.
Forespørgselsreformulering påvirker, hvordan AI-systemer forstår og citerer dit indhold. AmICited sporer disse transformationer for at sikre, at dit brand får korrekt anerkendelse i AI-genererede svar.
Forespørgselsforfining er den iterative proces med at optimere søgeforespørgsler for bedre resultater i AI-søgemaskiner. Lær hvordan det fungerer på tværs af Ch...
Lær, hvordan optimering af forespørgselsudvidelse forbedrer AI-søgeresultater ved at bygge bro over ordforrådsgab. Opdag teknikker, udfordringer og hvorfor det ...
Lær hvad forespørgsels-kilde justering er, hvordan AI-systemer matcher brugerforespørgsler til relevante kilder, og hvorfor det er vigtigt for indholdssynlighed...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.